一种基于残疾人特征的残疾人权威用户推荐方法与流程
本发明属于社交网络中的推荐技术领域,具体涉及一种残疾人权威用户推荐方法。
背景技术:
在线网络社区作为一种基于互联网技术的虚拟社区,为用户提供跨越时间和地点的信息交流平台。在线网络社区对于残疾人用户具有十分重要意义,很大程度上屏蔽了他们在生理上的劣势,帮助残疾人用户突破心灵的封闭,拉近他们与社会之间的距离,成为残疾人用户与世界沟通的最有效途径。残疾人网络社区是专门为残疾人用户服务的网络社区,具有以下几个特点:1)用户行为方式多样;2)用户兴趣特殊且范围有限,主要集中在医疗、教育、就业、政策等方面;3)用户心理脆弱,需要慰藉和引导;4)用户目的性弱,用户兴趣需求与用户心理需求相辅相成。不断涌入的用户给在线网络社区带来严重的信息过载问题,这大大增加了残疾人用户在网络社区中的生活成本。残疾人网络社区面临的信息过载问题,严重影响了残疾人用户的使用。
个性化推荐技术作为解决信息过载问题的主要方法,被广泛应用于各类网络社区中,并获得了不错的效果。目前,常见的推荐技术主要有协同过滤推荐、基于内容推荐、基于知识推荐以及混合式推荐等。但是由于在线网络社区形式多样,不同网络社区的功能特点不同,不同网络社区中的用户行为不同,导致不同网络社区对推荐系统的需求不同。对于残疾人网络社区而言,由于该社区面向用户的特殊性以及新用户问题,现有的传统个性化推荐技术即没有融入残疾人用户的特征,又不能及时的获取新用户的兴趣需求,难以推荐出真正符合残疾人用户兴趣需求的内容,并且推荐出来的内容不够全面的反应社区中的特点,难以帮助残疾人新用户全方位的了解并适应社区。
技术实现要素:
本发明的目的是为解决残疾人网络社区中新用户面临的特殊兴趣需求和心理需求问题,通过扩展现有的推荐技术,提出融合残疾人特征的残疾人权威用户推荐方法。
本发明提供的融合残疾人特征的残疾人权威用户推荐方法,利用残疾人权威用户对社区了解的全面性来帮助新用户适应社区;利用残疾人权威用户的专业性来解决残疾人新用户的有限但特殊的兴趣需求,通过残疾人权威用户的慰藉和引导来提升新用户的心理状态。
本发明提供的融合残疾人特征的残疾人权威用户推荐方法,具体包括如下步骤:
1. 构建残疾人网络社区信息数据库
利用网络爬虫程序获取残疾人网络社区的信息数据:首先在社区中的用户列表中爬取用户的唯一标识数据并存储至数据库;通过遍历已存储的所有用户唯一标识信息,爬取社区中的所有用户个人信息数据,并存储至数据库;利用已存储的用户唯一标识,存储网络爬虫程序所爬取的相应的用户发布内容信息,最终形成完整的残疾人网络社区用户信息数据集。
2. 残疾人网络社区用户分析与建模
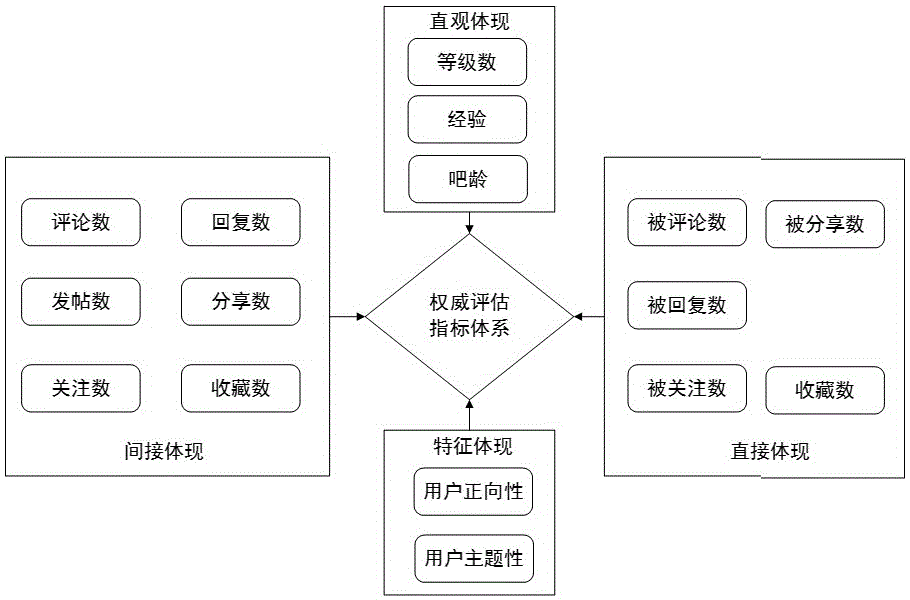
全面分析网络社区中的用户行为及这些行为所反映出的权威性,形成用户行为指标;分析残疾人网络社区中的用户特征,形成用户特征指标;分析用户行为指标和用户特征指标与权威性之间的关系,构建权威评估指标体系。其中:
所述用户在社区中的用户权威性是通过用户在社区中的各种行为的综合体现,用户行为主要包括两个维度:主动维度和被动维度。附图1展示了社区中用户行为之间的关系。
主动维度:包括发表(发帖)、分享、评论、回复、收藏和关注。
被动维度:包括被评论、被回复、被分享、被收藏和被关注。
残疾人网络社区中的残疾人用户需求主要有:有限的兴趣主题需求和心理鼓励需求,因此残疾人权威用户需要拥有一定的特征:主题性和正向性。
正向性:在情感维度上量化用户积极向上的态度和自强不息的精神。
主题性:用户在主题上的擅长程度。
本发明对以上用户行为和用户特征进行权威性分析后,形成用户的权威评估指标体系,如附图2所示。具体而言,包括:
主动维度,包括发表(发帖)、分享、评论、回复、收藏和关注;
被动维度,包括被评论、被回复、被分享、被收藏和被关注;
吧龄、等级和经验;
用户的主题性和正向性;
通过发帖量体现用户的发帖行为,评论数和回复数体现用户的交互行为,关注数体现用户的关注行为,分享数和收藏数体现用户的兴趣行为,这些属于用户权威性和影响力的间接体现。每篇帖子的均收评论数、均收回复数、均收分享数和均收收藏数,体现了用户在发帖内容上受欢迎的程度,体现了用户对其他用户的直接影响,被他人关注数,直接的体现了用户本身的受欢迎程度、用户的权威性和影响力。吧龄、等级和经验,是用户在残疾人吧网络社区中的资历体现,是网络社区对用户所有行为的直接反馈,是用户权威性和影响力的直观体现。用户的主题性和正向性则是残疾人用户权威性的特征体现。
3. 残疾人用户特征量化
分析残疾人用户的特征:用户有限的兴趣主题需求以及残疾人用户的心理需求;针对残疾人用户的心理需求,利用基于情感分析的用户正向性算法来量化用户积极态度和自强不息精神;针对残疾人用户的兴趣需求,通过对网络社区中用户所发内容的主题分类,利用朴素贝叶斯分类器计量用户属于某个主题的程度,计算用户的主题性。
(1)用户正向性
对于在线社区中的用户,用户会在社区中发表帖子来抒发自己的情感思想。通过对用户主动发布内容的正向性情感分析,可以计量出用户的正向性。用户主动发帖和评论回复他人是属于网络社区中两种不同的行为,是对用户在两个维度的考虑,主动分享的纬度和主动交互的纬度,他们在性质上有所不同,因此需要分开讨论。
对于情感正向性计算方法,主要在知网Hownet情感词典的基础上,利用基于规则的情感分析,计算文本的正向性得分。该方法主要是通过对帖中的每个情感单词进行情感正向性的计算,初始化其正向性基数,再结合该单词前后可能会出现的否定前缀,情感程度词进行情感正向性的校正,最后再将所有内容的正向性评分进行归一化处理,从而得到整个文本的整体情感正向性评分。
对于用户user主动发帖的这个纬度的正向性评分只集中在对用户user所有发帖内容的情感正向性分析上,按照公式(1)计算用户user的发帖正向性post_positive(user):
(1)
其中,N代表用户所发表的所有帖子数目,posti代表用户user所发的第i篇帖子,positive(posti)代表帖子posti经过情感分析后所获得的正向性得分。
对于用户user与其他用户交互的评论和回复信息的情感正向性分析只集中在用户user的所有回复和评论内容,按照公式(2)计算用户user的回复和评论内容的正向性reply_positive(user):
(2)
其中,M代表用户user所评论和回复其他用户主题帖的数目,replyi代表用户user所评论或回复的第i篇信息,positive(replyi)代表replyi经过情感分析后所获得的正向性得分。
因此,对于用户user整体的情感正向性评分,需要综合两个纬度上的用户正向性,即主动发帖内容的正向性和交互评论和回复上正向性,从而按照公式(3)得出用户正向性的综合评估得分user_positive(user):
(3)
其中,post_positive(user)代表用户user的发帖正向性得分,reply_positive(user)代表用户user的回复和评论内容的正向性得分。
(2)用户主题性
用户主题性是量化用户在残疾人所关注的有限且特殊的主题上的擅长程度。首先根据网络社区中大致的主题分布进行分类,掌握用户在主题上的偏向程度,再计量用户的主题概率,量化用户的主题性。在主题分类上,本文根据调研得到的有关残疾人用户在网络社区的主要关注点和需求点:工作、教育、健康、政策、激励和生活。
在主题性的量化方法上采用基于朴素贝叶斯分类法来进行用户主题性的计算。评估用户成为主题用户的概率,需要根据用户所发表帖子的主题分布情况,评估他所可能属于主题用户的概率。User在主题Topic={t1,t2,..ti..tn}上的发帖量是postNumber={n1,n2...ni,nn},根据公式(4)计算他属于主题tj用户的概率topic_probability(user,tj):
(4)
4. 残疾人用户权威评估模型的建立
利用矩阵分解模型SVD,结合权威评估指标体系,挖掘用户行为指标和用户特征指标与权威性之间的潜在因素,并结合残疾人用户的主题需求和兴趣需求,构建针对残疾人网络社区的权威用户评估模型。
通过所构建的权威用户评估指标体系,在进行用户权威性评估时,需要了解和掌握评估指标与权威性之间的联系,通过一定方式挖掘各种权威指标与权威性之间的潜在因素,利用指标-因素-权威性的三角关系,同时考虑残疾人网络社区中的残疾人用户的特殊性,从而构建针对残疾人网络社区的权威用户评估模型。
在基于残疾人网络社区的权威用户评估指标体系的基础上,本发明利用LFM(latent factor model,潜在因素模型)中常用的矩阵分解模型寻找到用户与指标的潜在因素关系。在权威用户评估指标体系上构建用户指标矩阵,设用户指标矩阵UImxn如表1所示。
表1:用户-指标矩阵
其中,UIij是用户i在指标j的表现,其中m代表用户个数,n代表基于残疾人网络社区的权威用户评估指标体系中的指标个数。不同的主题下,UI中的数值需要根据主题的变化进行相应的调整,也就是在不同的主题下,在挖掘不同主题的权威用户与指标之间的联系时,构建不同的UI矩阵。
在构建基于残疾人网络社区的权威评估模型时,需要经历两个阶段:训练阶段和构建阶段。训练阶段是指根据预处理的数据和用户训练集挖掘社区行为与权威性之间的关系;构建阶段是指结合残疾人网络社区和用户的特点,融入待评估残疾人用户的特性即用户正向性和用户主题性,构建基于残疾人网络社区的权威用户评估模型。
在训练阶段中,对用户-指标矩阵UI经过公式(5)分解和处理后得到的两个矩阵:UF和IF,即用户因素矩阵UF和指标因素矩阵IF。
R=X∑YT= X∑1/2(∑1/2YT) (5)
其中,UF=X∑1/2,IF = ∑1/2YT。UFij代表因素j对用户i在社区表现的影响程度,IFij代表指标i对因素j的影响程度。
在指标因素矩阵IF中,IFij越大,表明该指标i在因素j上的作用程度越大,整体评估时该指标的作用和影响力越大。
经过归一化处理,SVD分解以及对用户因素的特殊处理之后,可以得到基本的权威评估模型公式(6):
(6)
其中,W是因素-权威性比重向量,IFT是指标-因素的映射矩阵。
在构建阶段中,由于针对的是残疾人网络社区,需要在该评估模型的基础上融合用户正向性和用户主题性的特殊指标。在基础的权威用户评估模型的基础上加入用户正向性user_positive(user)和用户主题性topic_probability(user,tj),即对用户A,经过处理和统计后,得出他在残疾人网络社区中主题topic下的各项指标为a={f1,f2…fi,…fn },那么通过权威用户评估模型得到的权威性评估公式5和用户的残疾人特性得到用户A在主题topic下的权威程度InfluenceU (A,topic)的计算公式(7):
(7)。
5. 残疾人主题权威用户推荐
在进行针对残疾人网络社区中新用户的多样化主题权威用户的推荐时,首先进行新用户特征提取和识别;其次,根据新用户的特征向量与残疾人主题兴趣进行相似度匹配计算,判断和评估他在基于残疾人用户特征上的兴趣主题;最后,结合新用户在基于残疾人用户上的特征,为他进行多样化主题权威用户的推荐。
因此,在进行针对残疾人网络社区中新用户的多样化主题权威用户的推荐时,需要经过几个过程:新用户特征提取、新用户特征识别、主题权威用户评估和多样化主题权威用户的推荐。
(1)残疾人新用户特征提取和识别
在新用户的特征提取和识别上,本技术首先人工从网络中收集具有残疾人用户特征的文本训练集,并对这些训练集进行去噪、分词和特征提取等文本处理,目的是保证训练集中的特征是能够反映出残疾人用户的特征性,例如一些疾病、残疾人的政策以及上文所分析的残疾人用户的兴趣主题等。其次,在通过网络爬虫工具,爬取用户兴趣标签,构成用户的兴趣标签向量Tagu = {tag1,tag2,...tagi,...tagn}。识别结果可能出现两种情况:
用户本身有自己的兴趣主题,即经过特征识别后,得到的最大识别概率的主题是基于残疾人用户的兴趣主题,那么这些主题即可作为用户本身的兴趣主题,从而构建基于用户的兴趣主题向量topicU = {topic1,topic2,...topici,...topicn}。
其中,topici代表根据主题识别概率的大小,得到的概率第i大的topic。
用户本身的兴趣标签没有体现用户的兴趣维度,即经过特征识别后,用户的最大识别概率的类别是在残疾人用户上的,需要利用残疾人网络社区中的主题分布,构建用户的兴趣主题向量topicU = {topic1,topic2,...topici,...topicn}。
其中,topici代表根据残疾人网络社区中主题分布第i大的topici。
(2)主题权威用户的生成
在基于权威用户评估模型的基础上,结合残疾人网络社区中的主题分布情况,挖掘残疾人网络社区中各个主题下的权威用户,即在每个主题下,按照残疾人用户在该主题下的权威性的顺序,构建权威用户列表。这个过程可以定期离线进行,避免大量计算的耗费对在线网络社区的实时性带来影响。
(3)多主题权威用户推荐与评估
在残疾人所主要关注的主题下,评估所有的主题权威用户,分别为实验中所使用的新用户进行权威用户推荐,并利用推荐准确率P作为本方法的效果衡量标准。
推荐准确率P:推荐的权威用户有多少属于新用户最初所评论帖子的作者,计算方法如公式(8)所示。
(8)
其中,Pk代表在各个主题下各推荐k个用户时的准确率,n代表新用户总数,UiCAj 用户Ui最初所参与的前j个帖子的作者,IUk代表推荐的用户列表。
本发明的有益效果是:
1、分析并量化用户特征,并全面分析用户行为和用户特征与权威性之间的关系,所构建出来的权威评估模型能够考虑和衡量的指标和因素更加全面;
2、能够提供一种准确性更高的权威用户推荐方法。
附图说明
图1是用户行为分析示意图。
图2是残疾人网络社区的权威用户评估指标体系示意图。
图3是残疾人多主题权威用户推荐框架示意图。
图4展示了垃圾内容的识别和处理过程。
图5展示了多样化主题权威用户推荐结果图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图3及实施实例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
附图3为本实施例系统结构示意图,主要分为离线预处理和在线推荐两部分。
离线预处理主要包括用户特征量化模块、权威评估指标体系建立模块,权威用户评估模型建立模块和主题权威用户评估模块。
在线实时推荐主要包括用户兴趣标签提取模块,用户兴趣标签识别模块,用户兴趣主题向量匹配模块,多样化主题权威用户推荐模块。
实施例:本技术是在windows环境下开发,数据库使用MySql 5.7,选取JAVA作为主要的开发语言,以MyEclipse 2010作为开发平台,研究开发出了一个针对残疾人网络社区的多主题权威用户推荐系统:Recommendation 1.0,实现了用户行为和用户特征分析,用户权威性评估、权威用户推荐等功能。
具体实施步骤如下:
1. 数据获取
利用基于JAVA的网络爬虫程序获取残疾人网络社区的信息数据,首先在社区中的用户列表中爬取用户的唯一标识数据并存储至Mysql数据库。通过遍历已存储的所有用户唯一标识信息,爬取社区中的所有用户个人信息数据,并存储至Mysql数据库。利用已存储的用户唯一标识,存储网络爬虫程序所爬取的相应的用户发布内容信息,最终形成完整的残疾人网络社区用户信息数据集。
2. 数据预处理
2.1 去噪
在网络社区中,或多或少会存在水军用户,因此需要识别广告信息和垃圾信息。本技术首先在互联网上收集广告信息,并进行自然语言处理和特征提取,在将该信息作为朴素贝叶斯分类器的训练集。在主题分类前进行垃圾内容的识别和处理,采用文本分类和链接相结合的方式进行垃圾内容的识别,从而为水军用户的识别奠定基础。
附图4展示了垃圾识别的处理过程,其具体识别方法如下:
1、剔除内容中的广告贴和水军用户外,同时需要剔除字数较少且难以表达具体信息的帖子,例如有很多是“好呀”,“你好”等没有什么意义的语句,所以本技术剔除帖子字数少于4的,再进行基于残疾人用户需求主题的主题分类;
2、如果有网络社区中的内容被贝叶斯分类器识别到广告主题,那么判断该内容属于垃圾内容,应予以剔除;
3、根据大多数广告贴的特点,广告内容中普遍含有网络链接,通过人工收集网络中的商务网站,如果出现帖子或评论中的内容中含有指向商务网站的链接,那么会认定该帖子属于广告贴。
在对水军的识别上,本技术采用的主要思路是判断网络社区中的用户所发的垃圾内容在其所发的所有内容中的总占比情况。如果识别出的垃圾内容在该用户所有的发表内容中的占比超过一定的阈值F,那么判断该用户是属于水军用户,通过实验发现该阈值定在85%比较合适。在针对残疾人网络社区中的所有处理中,屏蔽该用户的所有内容。
2.2 文本分类
在分类方法上,有KNN,朴素贝叶斯,支持向量机(SVM),决策树DT,神经网络,其中朴素贝叶斯分类器应用最为广泛且简单高效。
本发明选择实现贝叶斯文本分类器作为主题分类的工具。它利用先验信息和样本信息来确定事件的后验概率。简单而言,就是对将要分类的文本,计算它的特征词分属于不同主题下的概率,哪个特征词所在主题类别的概率越大,那么它就属于该特征词所在的主题类别下。
对将要进行主题分类的文本Text分词后,得到特征词数组String[] words=(w1,w2……wn);已知主题的训练集样本training和主题类别C=(c1,c2……cm);
计算words中每个特征词wi在各个主题类别下的条件概率集合P。
根据贝叶斯公式(9),由于p(words)作为分母,对于待分类文本words而言,只需要根据p(words|ci)*p(ci)的结果,便可判断待分类文本words的所属类别,计算p(words)没有太大的意义,所以此处可省略对p(words)的计算,转而简化只需按照公式(10)计算分子。
(9)
(10)
在计算p(wi|cj)的过程中,为了避免在分类和概率求解过程中出现p(wi|cj)=0的情况,而对朴素贝叶斯分类器的分类效果产生影响,此处采用加入Laplace校准的方法,即对所有的特征属性出现次数上加1,而实际上对于p(wi|cj)不等于0的情况下,没有太大的影响,但却可以避免p(wi|cj)=0时对分类器的影响。
按照公式(11)计算文本Text在样本主题类别C={c1,c2……cm}上的概率P={p1,p2……pn}。
(11)
其中,P(Ci)是Ci的先验概率,即类别ci出现的概率。
给定经过分词后的待分类文本words= (w1,w2,...wi,……), 根据贝叶斯最大后验准则,根据公式(12)计算出的概率最大的主题类别作为文本text的主题类别,而ck就是文本words的所属分类。
(12)
文本训练集中,针对主题分类,文本训练集来部分来自于搜狗实验室文本分类语料库,但其主题内容不全面,不包括残疾人政策、激励和生活方面的内容,所以为了保证准确性,人工从互联网搜集残疾人政策、激励、工作、教育、健康和生活的文本各1000篇。在新用户的特征提取和识别上,首先人工从维基百科中收集具有残疾人用户特征的文本训练集,,例如一些疾病、残疾人的政策以及上文所分析的残疾人用户的兴趣主题等。利用Luence对这些训练集进行去噪、分词和特征提取等文本处理,目的是保证训练集中的特征是能够反映出残疾人用户的特征性对广告的识别,首先从淘宝网中人工搜集1000条广告和带有明确广告意味的评论。在广告贴的识别上,加入从ChinaZ.com网站中收集的440个电商网站链接,如果有帖子或评论链接是指向这些电商网站的,那么将其视为广告,从数据集中剔除。利用贝叶斯分类器对各个主题进行训练和测试,训练集取90%的文本,测试集用10%的文本。文本分类测试结果如表2所示,可见本技术所采用的文本分类方法具有很好的可靠性。
表2:文本分类测试结果
。
3. 用户特征量化
3.1 用户主题性
根据对用户所发布内容进行主题分类后,可以统计出用户在各个主题下的内容发布量,User在主题Topic={t1,t2,..ti..tn}上的发帖量是postNumber={n1,n2...ni,nn},那么根据公式4计算他在所发布内容中对主题tj的擅长程度,即用户的主题性;
3.2 用户正向性
在用户正向性的量化过程中,本文在知网Hownet情感词典的基础上,通过它提供的Hownet正向情感词表Positive,Hownet负向情感词表Negative,Hownet否定前缀词表NegativePrefix,Hownet程度词表Degree进行情感分析。先根据基于规则的情感分析技术计算用户每一条所发布内容(评论和发帖)的正向性评分。具体方法如下:
步骤1. 预处理,得到经过去噪、分词处理后的内容String[] words;
步骤2. 对于words中的一个word,若它在Positive表中,该word情感基数为1,即positiveValue(word) = 1;若它在Negative表中,由于负面情感在影响力上比正向情感强,该word情感基数为-1.5,即positiveValue(word) = -1.5;若都不在,说明该word不是情感词,跳过进入下一个word,进入步骤2;
步骤3. 若word是情感词,那么考虑该word向前的两个词,此处按照顺序会有word1, word2, word,判断word1,word2是否在NegativePrefix表。如果word1和word2中仅有一个在NegativePrefix表中,那么将该word的正向性得分按照公式(13)所示乘以否定系数-1。否则不变;
(13)
步骤4. 若word是情感词,那么对该word向前,向后同时移动两个词,此处按照顺序会有word1,word2,word,word3,word4,判断word1,word2,word3和word4是否在Degree表。如果word1,word2,word3和word4中有在Degree表中,那么将word的正向性得分按照公式(14)乘以相对应的程度权重系数degree;
(14)
其中,degree(wordi)代表word的前后词在程度词表Degree中的权重系数;
步骤5. 遍历过words中所有词后,得到words的正向性数组ArrayList[] positiveValue, 那么根据公式(15)可以得到words的正向性。
(15)
其中,N代表词组words中的单词数目,positiveValue(wordsi)代表词组words中第i的单词的正向性得分。
因此,得到用户所发布每一条内容的正向性得分,再根据公式1,2和3计算用户正向性的综合评估得分user_positive(user)。
4. 权威评估指标获取
利用存储至Mysql数据库的用户数据,对用户行为数据进行统计,同时量化用户的行为指标和特征指标。具体指标获取方法如下:
对于权威评估指标体系中的间接表现:发帖数、关注数、评论数、回复数、分享数和收藏数。
发帖数:用户在主题topic下的发帖数量。
关注数:用户关注其他用户的数量。
评论数:用户评论主题topic下内容的数量。
回复数:用户回复主题topic下内容的数量。
分享数:用户分享过的主题topic下的内容数量。
收藏数:用户收藏过的主题topic下的内容数量。
对于权威评估指标体系中的直接表现:被评论数、被回复数、被关注数、被分享数和被收藏数。
被评论数:用户发表属于主题topic下内容的平均收到评论数。
被回复数:用户发表属于主题topic下内容的平均收到回复数。
被关注数:用户被其他用户关注的数量。
被分享数:用户在主题topic下的内容,被其他用户分享过的数量。
被收藏数:用户在主题topic下的内容。
对于权威评估指标体系中的直观表现:等级数、经验。
等级数和经验:用户在残疾人网络社区中的等级数或经验值。
对于权威评估指标体系中的特征表现:用户主题性和用户正向性。
用户主题性:计算用户属于主题topic下的主题用户的概率,通过对用户的发帖内容进行预处理和主题分类,计算用户发帖内容在该主题下的占比情况,从而推导出用户在主题topic下的主题偏向概率。
用户正向性:通过情感分析,分析用户的所有发帖内容和评论回复的内容,通过他在主动分享维度和交互维度中的行为和表现,评估用户的正向性。
5. 建立权威评估模型
5.1 训练
在权威模型的构建上,本技术根据从残疾人社区中挖掘到的用户数据,按照各项权威评估指标分别排序后,总共选取各项权威评估指标下排名靠前的用户20名,构成活跃用户数据集;统计各活跃用户的权威评估指标,根据权威评估指标体系,构成用户-指标矩阵;利用SVD潜在语义挖掘技术,分解和挖掘用户-指标矩阵,得到用户与指标的潜在因素关系,即用户-因素-指标的联系,根据此构建出权威用户评估模型;
5.2 归一
由于本技术构建了基于残疾人网络社区的全面的权威用户评估指标体系,该体系中从各个维度考虑了用户的行为及表现会对用户权威性评估所产生的影响,形成了多种多样的评估指标,但这些指标分属于不同的维度,因此会导致其量化的数值的数量级不一致,所以在对用户-指标矩阵UI进行SVD分解和处理前,需要对矩阵UI进行归一化处理,保证让各指标分布在相同的量级上,即处于[0,1]之间。如此处理之后,便可在整体评估用户权威性时,平等的对待各个指标,以及避免指标量级的不同对用户评估时所带来的数值影响。
6. 评估主题权威用户
在基于权威用户评估模型的基础上,结合残疾人网络社区中的主题分布情况,挖掘残疾人网络社区中各个主题下的权威用户,即在每个主题下,按照残疾人用户在该主题下的权威性的顺序,构建权威用户列表。这个过程可以定期离线进行,避免大量计算的耗费对在线网络社区的实时性带来影响。算法通过残疾人网络社区中的主题分布情况,同时结合权威用户评估模型公式6和公式7,构建残疾人网络社区中各个主题下的权威用户列表。这个过程通过quatz定时框架每一周定期离线进行,避免大量计算的耗费对在线网络社区的实时性带来影响。
7. 多主题残疾人权威用户推荐
7.1 新用户特征识别
在进行针对残疾人网络社区中新用户的多样化主题权威用户的推荐时,首先利用基于朴素贝叶斯的文本分类技术进行新用户特征提取和识别,形成用兴趣向量。topicU = {topic1,topic2,...topici,...topicn};
7.2 多主题权威用户推荐
在主题权威用户列表中,将主题与新用户的兴趣向量进行匹配,根据匹配次序构建主题权威用户推荐列表USERS= {user1, user2,... useri,...usern},并将推荐给相应的用户。
8. 实验评估
在实验中,需要针对残疾人网络社区中的新用户进行多样化主题权威用户推荐,在针对新用户的获取处理上,我们假设2014年1月1日以后的用户作为新用户,2014年1月1日以前的用户作为老用户。通过评估新用户在其他用户所发表内容上的表现,来判断本文所推荐的多样化权威用户的效果,也可以判断和评估本文所提出的基于残疾人网络社区的权威用户评估指标体系及权威用户评估模型的有效性。本发明采用推荐准确率P来评估用户的权威性。
另外,在实验中,本文所采用的基于残疾人社区的多主题权威用户推荐方法为DisabledTopicInfluentialUserRecommendation,DTIR;对比的方法有不考虑残疾人特性的多样化权威用户推荐TopicInfluentialUserRecommendation,TIR;基于用户评论或回复他人的数量,即基于交流数的推荐;基于级别的推荐;基于发帖数的推荐;基于用户收到其他用户评论的数量,即基于评论数的推荐;基于经验值的推荐和基于PageRank的推荐。在实验过程中,k分别赋值1、3,代表着在多样化主题权威用户推荐时,分别推荐各个主题下1个和3个主题权威用户。
基于权威用户的多样化主题推荐,将贴吧中的数据按照主题进行分类,选择每个主题下的Top1用户,再结合成综合的推荐列表,推荐给新用户,考虑新用户在初期1、3、5、10、20个评论贴的准确率,得到的结果图如附图5所示。发现本文所提出的推荐技术的推荐准确率仍然是各种推荐方法中最好的,有一定的实用性和有效性。
以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的原则和精神之内所作的任何修改、等同替换和改进等,均就包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!