一种基于分类模型判断的数据质量监控方法与流程
本发明涉及多源异构数据源整合技术领域,具体而言,涉及一种基于分类模型判断的数据质量监控方法。
背景技术:
数据质量可以通过数据质量元素来描述,数据质量元素分为数据质量定量元素和数据质量非定量元素。数据质量定量元素用于描述数据集满足预先设定的质量标准及指标的程度,并提供定量的质量信息。数据质量非定量元素提供综述性的、非定量的质量信息。数据质量定量元素主要包括数据完整性和逻辑一致性等,数据质量非定量元素主要包括数据的目的、用途和数据志等。
数据整合的效果受数据质量的制约,数据质量的监控对整合的结果产生重要的影响,数据质量的监控贯穿整个数据整合流程,从而确保数据的准确性和可用性。数据质量监控在数据整合的整个过程中,通过质量控制、质量保证和质量改进,来实现数据质量的提升。
数据挖掘通过预测未来趋势及行为,做出前摄的、基于知识的决策。其中分类是找出数据中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据中的数据项映射到某个给定的类别。
现有的数据整合中针对数据质量监控存在一定的局限性,首先数据质量监控依赖于大量的元数据定义或质量规则,这样就对应的存在有数据质量监控规则库的建立与维护;其次,现有数据质量监控多涉及的是字段级别的规则设定,未真正意义上涉及到整体记录的正确规范性。
技术实现要素:
为解决上述问题,本发明的目的在于提供一种基于分类模型判断的数据质量监控方法,完善了数据质量监控体系,提高了数据整合的效率。
本发明提供了一种基于分类模型判断的数据质量监控方法,该方法包括:
步骤1,人工筛选获取的数据集,将没有字段值缺失的数据进行质量好坏的标记;
步骤2,依据标记好的数据进行分类模型训练;
步骤3,将训练后的分类模型以预测模型标记语言的形式进行持久化保存;
步骤4,将需要整合的数据进行预处理,以满足分类模型数据输入的要求;
步骤5,在数据整合的过程中对预测模型标记语言文件进行解析调用;
步骤6,依据分类模型对整合数据进行分类标记;
步骤7,依据标记结果,对数据进行处理。
作为本发明进一步的改进,步骤1具体包括:
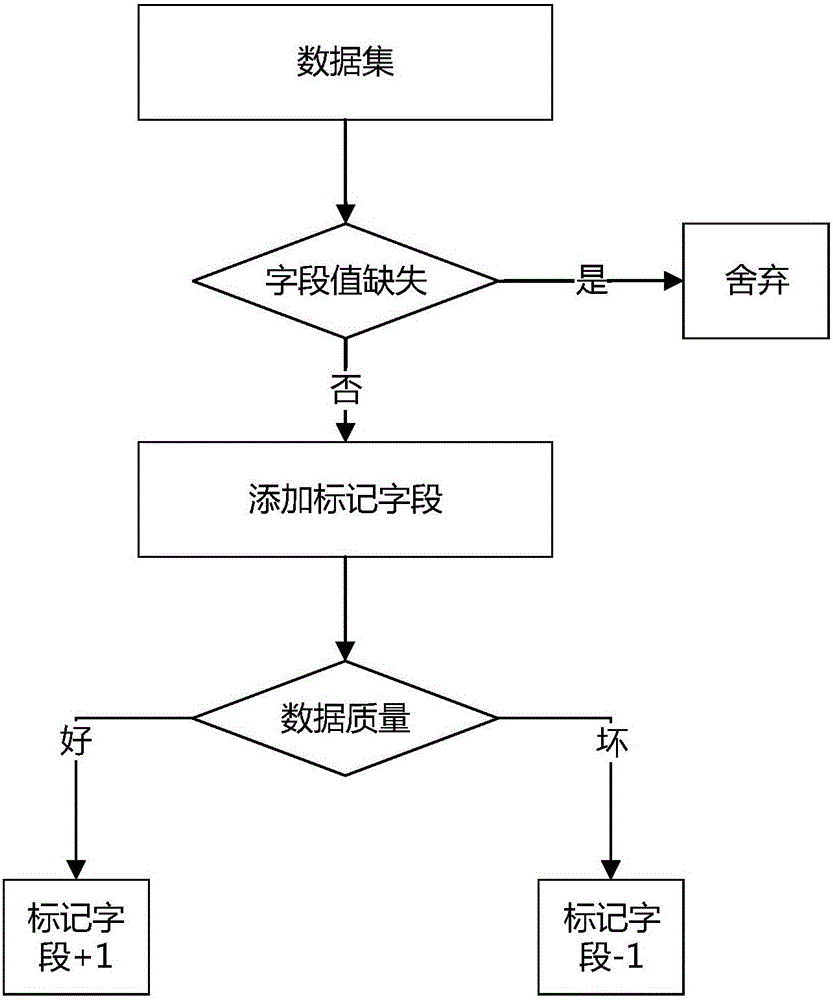
步骤101,获取业务数据后,人工筛选数据集,如果数据中有缺失的字段值,则舍弃该数据,如果数据中没有缺失的字段值,则保留该数据;
步骤102,在保留的数据字段上,添加一个标记字段;
步骤103,人工地对数据质量的好坏进行标记,其中,将符合质量要求的数据标记字段+1,将不符合质量要求的数据标记字段-1。
作为本发明进一步的改进,步骤2中,对分类模型进行优化,具体包括:
步骤201,对标记完的数据集进行强关联字段组合,生成新的特征字段,计算组合字段值,同时,舍弃掉原有字段;
步骤202,利用随机森林分类器,将其中部分棵决策树分类模型修改调整为支持向量机分类模型。
作为本发明进一步的改进,步骤4具体包括:
步骤401,对需要整合的数据集进行筛选,如果数据中有缺失的字段值,则将该数据标记字段-1,并且不运行分类模型判断的流程,如果数据中没有缺失的字段值,则进行步骤402;
步骤402,将需要整合的多源异构数据进行元数据统一;
步骤403,将统一后的数据集进行强关联字段组合,生成新的特征字段,并计算组合字段值。
作为本发明进一步的改进,步骤7具体包括:
步骤701,将标记为-1的数据集单独存储,不进行后续数据整合步骤;
步骤702,将标记为+1的数据集进行后续的数据整合步骤,数据整合完成后入库;
步骤703,基于步骤701中单独存储的数据集,人工介入进行判断,如果没有标记错误的数据,则人工对数据进行取舍,如果有标记错误的数据,则进行步骤704和步骤705;
步骤704,人工修订标记错误的数据,将标记修订为+1,完成步骤702中后续的数据整合步骤,数据整合完成后入库;
步骤705,人工修订标记错误的数据,将标记修订为+1,重新进行步骤2的分类模型训练进行模型修订。
本发明的有益效果为:
根据业务数据生成的模型可以自动地生成对各字段合理性的判断条件,同时该模型也可以自动地生成对各字段逻辑性组合合理性的判断条件,模型可通过单一的模型文件进行存储与调用,无需进行大量质量规则的制定与维护,高效地保障了数据整合流程与数据的完整性、一致性。
附图说明
图1为本发明实施例所述的一种基于模型判断的数据质量监控方法的流程示意图;
图2为图1中步骤1的流程示意图;
图3为图1中步骤2中对分类模型进行优化的流程示意图;
图4为图1中步骤4的流程示意图;
图5为图1中步骤7的流程示意图。
具体实施方式
下面通过具体的实施例并结合附图对本发明做进一步的详细描述。
如图1所示,本发明实施例所述的一种基于分类模型判断的数据质量监控方法,该方法包括:
步骤1,人工筛选获取的数据集,将没有字段值缺失的数据进行质量好坏的标记;
步骤2,依据标记好的数据进行分类模型训练;
步骤3,将训练后的分类模型以预测模型标记语言(PMML)的形式进行持久化保存;
步骤4,将需要整合的数据进行预处理,以满足分类模型数据输入的要求;
步骤5,在数据整合的过程中对PMML文件进行解析调用;
步骤6,依据分类模型对整合数据进行分类标记;
步骤7,依据标记结果,对数据进行处理。
人工筛选出没有字段值缺失的数据,同时要保障筛选出的数据必须有质量好与坏之分,这样才能有效的进行后续分类模型的训练。如图2所示,步骤1具体包括:
步骤101,获取业务数据后,人工筛选数据集,如果数据中有缺失的字段值,则舍弃该数据,如果数据中没有缺失的字段值,则保留该数据;
步骤102,在保留的数据字段上,添加一个标记字段;
步骤103,人工地对数据质量的好坏进行标记,其中,将符合质量要求的数据标记字段+1,将不符合质量要求的数据标记字段-1。
分类模型可用的判断依据是较高的真负类率。如图3所示,步骤2中,可对分类模型进行优化,具体包括:
步骤201,对标记完的数据集进行强关联字段组合,生成新的特征字段,计算组合字段值,以提升分类模型判断的真负类率,同时,舍弃掉原有字段,否则存在重复的字段会产生多重共线性问题;
步骤202,利用随机森林分类器,将其中部分棵决策树分类模型修改调整为支持向量机分类模型,以增强分类器的泛化能力。
在运用分类模型进行数据质量标记之前,需进行数据预处理,以适应模型定义的字段。如图4所示,步骤4具体包括:
步骤401,对需要整合的数据集进行筛选,如果数据中有缺失的字段值,则将该数据标记字段-1,并且不运行分类模型判断的流程,如果数据中没有缺失的字段值,则进行步骤402;
步骤402,将需要整合的多源异构数据进行元数据统一;
步骤403,将统一后的数据集进行强关联字段组合,生成新的特征字段,并计算组合字段值。
在对数据进行质量标记后,对数据进行处理。如图5所示,步骤7具体包括:
步骤701,将标记为-1的数据集单独存储,不进行后续数据整合步骤;
步骤702,将标记为+1的数据集进行后续的数据整合步骤,数据整合完成后入库;
步骤703,基于步骤701中单独存储的数据集,人工介入进行判断,如果没有标记错误的数据,则人工对数据进行取舍,如果有标记错误的数据,则进行步骤704和步骤705;
步骤704,人工修订标记错误的数据,将标记修订为+1,完成步骤702中后续的数据整合步骤,数据整合完成后入库;
步骤705,人工修订标记错误的数据,将标记修订为+1,重新进行步骤2的分类模型训练进行模型修订,以迭代式的修订方式,完善分类模型。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!