一种属性缺失数据集的聚类方法与流程
本发明涉及信息数据处理技术领域,具体是一种属性缺失数据集的聚类方法。
背景技术:
数据集的属性缺失是指数据集中某些样本缺失一个或多个属性值。这种情况往往是由传感器采集或信号传输过程中的信息丢失造成的。当多个样本出现属性缺失时会造成数据集聚类结果精度下降问题。
针对该问题,学者们在现有完整数据集聚类算法的基础上提出了许多解决策略,其中模糊C均值算法(Fuzzy C-Means,FCM)应用较为广泛。在该算法的思想下,学者们提出了基于FCM的属性缺失数据集聚类方法。尤其是Hathaway等提出的完整数据集法(Whole Data Strategy,WDS)、局部距离法(Partial Distance Strategy,PDS)、最近邻原型法(Nearest Prototype Strategy,NPS)和优化完整法(Optimal Completion Strategy,OCS)获得了广泛的关注。WDS和PDS通过舍弃属性缺失数据或缺失属性,对其余数据进行FCM聚类;NPS和OCS在每一次迭代中先对缺失属性进行估计,构成的完整数据集后再进行聚类,可以同时得到缺失属性的估计值和数据集聚类结果。此外,Timm等提出了一种基于Gath-Geva算法的不完全数聚类方法;Honda等利用局部主成分分析法划分线性模糊子类,实现不完整数据集的聚类。这些聚类算法不同程度的解决了非完整数据集的聚类问题,但对于缺失属性的估计偏差较大,由此得到的聚类结果的准确度不是很高,尤其是缺失比例较高时WDS和PDS聚类精度较差。有鉴于此,有必要研究一种新的解决策略,以提高属性缺失数据集缺失属性的估计精度,进而提高聚类结果的准确度。
技术实现要素:
为了克服现有技术的缺陷,本发明提供一种基于模糊C均值的缺失属性混杂聚类方法,该方法通过采取最近邻法(Nearest Neighbor,NN)确定缺失属性估值约束空间,来提高缺失属性估计的准确度,并采用蚁群算法进行寻优完成缺失属性估计并确定聚类中心,在此基础上通过模糊C均值隶属度函数完成数据集聚类,从而提高聚类结果的精度。
本发明采用技术方案如下:
一种属性缺失数据集的聚类方法,对于缺失数据集S进行聚类,聚类的类别数为c,所述缺失数据集S包含x个数据,属性维度为y,缺失属性的个数为n,聚类中心表示为大小为c*y的矩阵,所述聚类方法包括以下步骤:
S1.对缺失属性和聚类中心进行蚁群编码:将数据集中的所有缺失属性和每个聚类中心的各维度属性值进行空间叠加构成一个n+c*y维的向量,
并将所述向量作为蚁群中单只蚂蚁的位置向量;
S2.确定缺失属性及聚类中心的取值空间,所述取值空间即为所述位置向量对应维度的搜索范围;
S3.进行蚁群搜索,通过搜索获得缺失属性最优估计值及聚类中心,得到隶属度矩阵,完成聚类。
优选的,步骤S3中蚁群中有w只蚂蚁,搜索过程中的迭代次数为t,蚁群中单只蚂蚁antp的搜索方法包括:
第一步:在搜索范围内对蚂蚁antp进行实数编码,即随机设定蚂蚁antp初始位置:antp(0)=antp(1)(0),antp(2)(0),antp(3)(0),...,antp(n+c*y)(0),从而获得对应于antp缺失属性和聚类中心的值,构成对应于antp(0)的完整数据集S′p(0),并得到对应于antp(0)的聚类中心Vp(0);
第二步:得到对应于antp(0)的隶属度矩阵Up(0)及目标函数值F(antp(0)),并由此得到对应于antp(0)的信息素J(antp(0));
第三步:根据前后两次信息素的大小关系判断蚂蚁antp是否进行移动操作:重复上述步骤得到J(antp(1)),
当J(antp(1))>J(antp(0))时,对蚂蚁antp进行移动操作,即用antp(1)=antp(1)(1),antp(2)(1),antp(3)(1),...,antp(n+c*y)(1)的值替代antp(0)=antp(1)(0),antp(2)(0),antp(3)(0),...,antp(n+c*y)(0),用J(antp(1))的值替代J(antp(1)),
否则不进行移动,以此类推,直至执行完t次迭代。
优选的,步骤S3还包括:
在第z(z=1,2,3...t)次迭代中,获取所有w只蚂蚁中信息素最大的蚂蚁个体antbest(z),则在完成t次迭代后通过所得antbest(t)的位置向量分量antbest(t)=antbest(1)(t),antbest(2)(t),antbest(3)(t),...,antbest(n+c*y)(t),从而获得缺失属性最优估计值及聚类中心最佳估计值,即得到完整数据集S′和聚类中心V;
根据完整数据集S′和聚类中心V获取隶属度矩阵U,完成聚类。
优选的,所述根据完整数据集S′和聚类中心V根据公式1获取隶属度矩阵U;
公式1为usk表示第k个数据对第s类的隶属度,xk表示数据集中的第k个数据;vs表示第s类的聚类中心;m是模糊因子,用来决定聚类结果模糊度的权重指数,m∈[1,∞),聚类的类别数为c。
优选的,m不大于2.5并且不小于1.5。
优选的,所述确定缺失属性及聚类中心的取值空间包括:
对于缺失属性,利用最近领域法得到所述缺失属性的最近邻区间,并将所述最近邻区间作为缺失属性估计空间;
对于聚类中心,选取数据集中每一维未缺失属性值中的最大值和最小值作为边界值构成聚类中心对应维度属性的取值空间。
优选的,所述最近邻区间的获取方法包括:
获取所述缺失属性所在的数据与其它数据的欧氏距离,找出其它数据中与所述缺失属性所在的数据欧式距离最小的q个数据,所述q个数据与所述缺失属性对应的属性均没有缺失,根据所述q个数据中与所述缺失属性对应的属性的最大值和最小值构建所述最近邻区间。
优选的,所述第二步中根据公式1和公式2得到对应于antp(0)的隶属度矩阵Up(0)及目标函数值F(antp(0)),
所述公式2为其中,F(U,P)即为目标函数,表示样本与其典型样本的误差平方和,即所述缺失数据集中数据与聚类中心的误差平方和;dsk表示第s类中的数据xk与第s类的聚类中心vs之间的失真度;usk为数据xk在第s类中的隶属度;m是模糊因子,用来决定聚类结果模糊度的权重指数,m∈[1,∞);聚类的类别数为c,x表示所述缺失数据集中数据的个数。
优选的,失真度用两个矢量的欧氏距离度量。
本发明的有益效果是:
本发明打破了FCM聚类算法的收敛方式,将缺失属性和聚类中心组成一个向量,蚁群中的被编码的每个蚂蚁个体代表缺失属性和聚类中心的一组解,将FCM算法的目标函数的倒数作为是适应度函数,利用蚁群同时搜索出缺失属性和聚类中心的最佳估计值,从而求取出最终隶属度矩阵,完成对非完整数据集的聚类。这种方法的最终聚类结果不再是FCM聚类的结果,而变成了智能优化的结果。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1是实施例1聚类方法示意图;
图2是实施例1方法对缺失比5%的Iris数据集的聚类结果示意图;
图3是实施例1方法对缺失比5%的Iris数据集的聚类时目标函数随迭代次数变化示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
经过对现有技术的分析,发明人发现属性缺失数据集聚类算法的准确性主要受限于以下两个方面:
①缺失属性估计的准确度。直接对缺失属性进行估计所得估计值相较原始值往往具有较大的偏差。因此,在估值过程中,一般采用划定约束空间的方式对缺失属性限制,以提升估值的准确度。但界定可靠且覆盖区域尽可能小的约束空间的难度较大,约束空间界定是否准确将直接影响聚类结果的准确性。
②聚类中心的选取。现有的基于FCM的属性缺失数据集聚类算法大多采用“属性估计-模糊C均值聚类”这样的分步方式,因而其聚类中心仍由模糊C均值算法得到,但FCM算法在迭代中目标函数易陷入局部最小值,由此得到的聚类中心的准确性也相对较差。
为此,针对第一个方面,本发明采取最近邻法确定缺失属性的估值约束空间,提高缺失属性估计的准确度;针对第二个方面,采取对聚类中心进行蚁群编码寻优,在该思想下,聚类中心不再由FCM算法获得,降低了聚类中心陷入局部最小值的风险性,提高了聚类结果的准确性。
本发明的技术方案如下:
实施例1:
一种属性缺失数据集的聚类方法,对于缺失数据集S进行聚类,聚类的类别数为c,所述缺失数据集S包含x个数据,属性维度为y,缺失属性的个数为n,聚类中心表示为大小为c*y的矩阵,所述聚类方法包括以下步骤:
S1.对缺失属性和聚类中心进行蚁群编码:将数据集中的所有缺失属性和每个聚类中心的各维度属性值进行空间叠加构成一个n+c*y维的向量,并将所述向量作为蚁群中单只蚂蚁的位置向量;
S2.确定缺失属性及聚类中心的取值空间,所述取值空间即为所述位置向量对应维度的搜索范围。
对于缺失属性,利用最近领域法得到所述缺失属性的最近邻区间,并将所述最近邻区间作为缺失属性估计空间;
对于聚类中心,选取数据集中每一维未缺失属性值中的最大值和最小值作为边界值构成聚类中心对应维度属性的取值空间。
所述最近邻区间的获取方法包括:
获取所述缺失属性所在的数据与其它数据的欧氏距离,找出其它数据中与所述缺失属性所在的数据欧式距离最小的q个数据,所述q个数据与所述缺失属性对应的属性均没有缺失,根据所述q个数据中与所述缺失属性对应的属性的最大值和最小值构建所述最近邻区间。
具体地,欧式距离其中,和分别是数据和第j个属性值,s为一个完整数据包含的属性个数,并且其中XM是缺失属性集合。
具体地,根据局部欧氏距离的大小,能够表征出属性缺失数据与其它数据(既包括属性完整数据,也包括其他属性缺数据)的亲疏关系,可从中确定与属性缺失数据距离最近的q个数据。但需要注意,这q个数据与该数据缺失属性相同维度的属性必须没有缺失。为兼顾算法效率和估值准确度,本实施例中将q的取值设定为6。
S3.进行蚁群搜索,通过搜索获得缺失属性最优估计值及聚类中心,得到隶属度矩阵,完成聚类。
蚁群中有w只蚂蚁,搜索过程中的迭代次数为t,蚁群中单只蚂蚁antp的搜索方法包括:
第一步:在搜索范围内对蚂蚁antp进行实数编码,即随机设定蚂蚁antp初始位置:antp(0)=antp(1)(0),antp(2)(0),antp(3)(0),...,antp(n+c*y)(0),从而获得对应于antp缺失属性和聚类中心的值,构成对应于antp(0)的完整数据集S′p(0),并得到对应于antp(0)的聚类中心Vp(0)。
第二步:得到对应于antp(0)的隶属度矩阵Up(0)及目标函数值F(antp(0)),并由此得到对应于antp(0)的信息素J(antp(0)),其中,J(antp(0))为F(antp(0))的倒数。
具体地,根据公式1和公式2得到对应于antp(0)的隶属度矩阵Up(0)及目标函数值F(antp(0)),
公式1为usk表示第k个数据对第s类的隶属度,xk表示数据集中的第k个数据;vs表示第s类的聚类中心;m是模糊因子,用来决定聚类结果模糊度的权重指数,m∈[1,∞),聚类的类别数为c。具体地,m不大于2.5并且不小于1.5。
公式2为其中,F(U,P)即为目标函数,表示样本与其典型样本的误差平方和,即所述缺失数据集中数据与聚类中心的误差平方和;dsk表示第s类中的数据xk与第s类的聚类中心vs之间的失真度;usk为数据xk在第s类中的隶属度;m是模糊因子,用来决定聚类结果模糊度的权重指数,m∈[1,∞);聚类的类别数为c,x表示所述缺失数据集中数据的个数。具体地,m不大于2.5并且不小于1.5。
具体地,所述失真度用两个矢量的欧氏距离度量。
第三步:根据前后两次信息素的大小关系判断蚂蚁antp是否进行移动操作:重复上述步骤得到J(antp(1)),
当J(antp(1))>J(antp(0))时,对蚂蚁antp进行移动操作,即用antp(1)=antp(1)(1),antp(2)(1),antp(3)(1),...,antp(n+c*y)(1)的值替代antp(0)=antp(1)(0),antp(2)(0),antp(3)(0),...,antp(n+c*y)(0),用J(antp(1))的值替代J(antp(1)),
否则不进行移动,以此类推,直至执行完t次迭代。
在第z(z=1,2,3...t)次迭代中,获取所有w只蚂蚁中信息素最大的蚂蚁个体antbest(z),则在完成t次迭代后通过所得antbest(t)的位置向量分量antbest(t)=antbest(1)(t),antbest(2)(t),antbest(3)(t),...,antbest(n+c*y)(t),从而获得缺失属性最优估计值及聚类中心最佳估计值,即得到完整数据集S′和聚类中心V。
最后,根据完整数据集S′和聚类中心V获取隶属度矩阵U,从而完成聚类。
其中,所述根据完整数据集S′和聚类中心V根据公式1获取隶属度矩阵U;
公式1为usk表示第k个数据对第s类的隶属度,xk表示数据集中的第k个数据;vs表示第s类的聚类中心;m是模糊因子,用来决定聚类结果模糊度的权重指数,m∈[1,∞),聚类的类别数为c。具体地,m不大于2.5并且不小于1.5。
具体地,利用采用Matlab2012a软件对本实施例提出的方法进行仿真验证。假设条件如下:
(1)从UCI数据库(http://www.sgi.com/Technology/mlc/db/)中选取两个数据集作为实验对象:①被广泛用作测试用途的标准数据集Iris(鸢尾草植物)。该数据集由150个样本点构成,其中每个样本由4维特征描述,整个样本集包含了3个Iris种类,每类各有50个样本;
②Wine数据集。该数据集由178个样本点构成,每一个样本点都有14维属性值,第1维属性表征所属类别,第2到14重属性表征了葡萄酒的十三种化学成分,数据集由3类样本构成,分别包含59、71、48个样本。
(2)用于验证的缺失比选取为:0%,5%,10%和15%(其中缺失比为0%时即为完整的数据集),数据集的属性缺失由matlab随机产生。
(3)实验的对比参照选取为WDS、PDS、NPS、OCS四种算法。
(4)设定算法的参数为:
①属性缺失数据的最近邻范围表证数q=6;
②蚁群算法中参设定如表1:
表1 蚁群算法参数设定值
需要说明的是,为保证蚁群算法的搜索能力,针对不同数据集和缺失比,随着样本数量和缺失比的增大,蚂蚁数量m和迭代次数t要一定程度的增大。
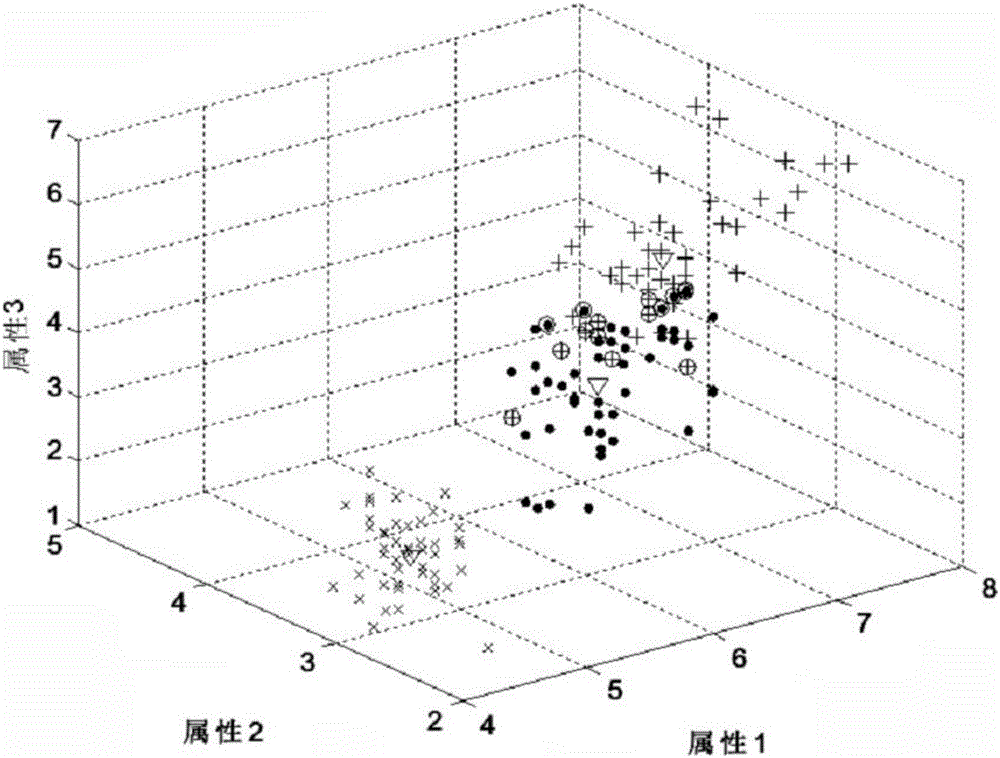
为验证本实施例中方法的性能,选取缺失比为5%的Iris数据集进行聚类,将聚类后的样本点及聚类中心绘制在图2上。其中缺失的属性由算法得出的估计值代替。为得到可视化图形,在不影响结果的前提下,本文舍弃了Iris数据集的第4维属性值,所以聚类结果图为三维图像。‘×’、‘·’、‘+’分别表示对Iris数据集的三类聚类结果,‘○’所圈点表示被误分的数据,‘▽’表示三类数据的聚类中心。
同时将目标函数与蚁群算法迭代次数的关系以及缺失属性的估计值与真实值的对比(选取前10个缺失属性)分别表示在图3中和表2中:
表2 缺失比为5%的Iris属性缺失数据集的缺失属性估计值与真实值的对比
由实验结果可得出以下结论:①本实施例中的方法可确定聚类中心的大致位置,错分数相对较低;②本实施例中的方法在迭代600次之后逐渐趋于收敛(总迭代次数为1200);③本实施例中的方法的缺失属性估计结果接近真实值,估值精度稳定。
(2)对比验证
为验证本实施例中的方法在聚类结果准确性和缺失属性估计方面的优势,在Iris和Wine数据集下,分别进行了缺失比例为0%,5%,10%和15%时的仿真实验。分别计算出本实施例中的方法在不同缺失比下的误分数以及缺失属性估计值的相对误差。将该结果与WDS、PDS、NPS和OCS四种算法进行比较,结果列于表3和表4中。
表3 属性缺失数据集聚类平均误分数
表4 缺失属性的估值相对误差平均值
通过表3和表4实验数据对比,可得到以下结论:
①相比于Bezdek的提出的四种方法,本实施例方法在缺失比例为0%,5%,10%和15%的数据集下聚类结果最优,错分数明显低于其他四种方法;
②从缺失属性的估计效果来看,WDS和PDS不可以对缺失属性进行估计,NPS的估计结果误差较大,相较之下OCS和本实施例方法的估计相对误差值比NPS有了指数级的提升,且本实施例方法的结果更优;
③随着缺失比例的增加,错分数和估计值相对误差也随之增加,但在Iris数据集的使用本实施例方法进行聚类时错分数在缺失比是5%时要低于缺失比为0%(即完整数据集)。
为验证本实施例方法的鲁棒性,分别求出本实施例方法在缺失比例为5%,10%和15%时10次实验中误分数的标准差,并计算出标准差与均值的比值,结果列于表5中:
表5 本实施例方法的误分数标准差
由实验结果可以得出以下的结论:
①本实施例方法聚类结果误分数的标准差较小,且与均值的比值均不超过17%,特别是当缺失比例较小时,标准差与均值的比值不超过10%,说明本实施例方法的鲁棒性较强;
②随着缺失比例的增加,本实施例方法聚类结果误分数的标准差也增加,即算法的鲁棒性随缺失比例的增大而降低。
本实施例提出了基于缺失属性与聚类中心编码的混杂聚类算法,即HOC算法,通过利用蚁群算法在缺失属性的最近邻区间及聚类中心取值范围内同时搜索,对非完整数据集的缺失属性进行估值的同时进行数据集分类。通过仿真说明HOC算法具有以下优势:
(1)较大程度地提高对缺失属性估计值的准确度;
(2)相较于其他方法,得到的聚类结果错分率相有显著的降低,得到的聚类结果更好更稳定。
以上所揭露的仅为本发明的较佳实施例而已,当然不能以此来限定本发明的权利范围,依据本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!