一种基于混合算法的网页分类方法和装置与流程
本发明涉及网页分类技术领域,具体涉及一种基于混合算法的网页分类方法和装置。
背景技术:
随着互联网及其相关技术的飞速发展,出现了海量且庞杂的网络信息资源。如何从这些海量的非结构化数据中提取和产生知识,找到人们感兴趣的内容,已经成为当前迫切需要解决的问题。各种搜索引擎如Google,百度,Yahoo等的出现开始对这一问题有所缓解,但是这些搜索工具面向的是所有用户,他们通常是把一个通用性的结果返回给所有用户,这样并不能满足处于特定时期,特定领域,特定目的的查询要求。人们真正感兴趣的东西往往被淹没在浩瀚的信息海洋里,那么如何有效地组织、处理这些海量信息,如何更好地分配、利用所需的网络信息资源便成为了亟待解决的问题。
支持向量机(SVM)是根据统计学习理论,以结构风险最小化原则为理论基础的一种新的机器学习方法,其主要思想是针对二分类问题,在高维空间中寻找一个超平面作为二类的分割,以保证最小的错分率,但是缺点是针对大量数据分类时SVM训练时间过长。
朴素贝叶斯是一类利用概率统计知识进行分类的算法,但是单独使用精确度不够高。
鉴于上述缺陷,本发明创作者经过长时间的研究和实践终于获得了本发明。
技术实现要素:
为解决上述技术缺陷,本发明采用的技术方案在于,提供一种基于混合算法的网页分类方法,其包括:
步骤a,搜索待分类网页,对所述待分类网页进行处理得到网页数据;
步骤b,对所述网页数据进行处理,用向量空间模型将所述网页数据转换为文本表示,计算词条项的权值并将所述待分类网页的特征向量转化成数值形式;
步骤c,利用数值形式的特征向量作为训练数据,建立SVM的分类模型,并利用SVM分类器对待分类网页的所述特征向量进行分类;
步骤d,将SVM分类器输出的符合分类条件的所述特征向量输送至朴素贝叶斯分类器当中进行分类;
步骤e,利用朴素贝叶斯分类器对所述待分类网页的所述特征向量进行分类。
较佳的,所述步骤c包括:
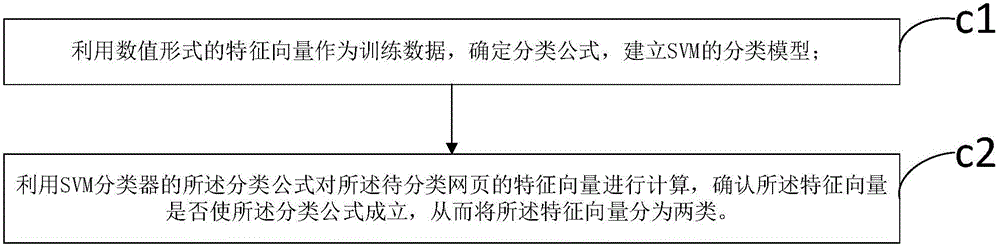
步骤c1,利用数值形式的特征向量作为训练数据,确定分类公式,建立SVM的分类模型;
步骤c2,利用SVM分类器的所述分类公式对所述待分类网页的特征向量进行计算,确认所述特征向量是否使所述分类公式成立,从而将所述特征向量分为两类。
较佳的,所述步骤e包括:
步骤e1,从SVM分类器输出的所述特征向量中选择一部分作为训练样本,确定所述训练样本中每个特征向量对应的特征属性,以及每个特征向量对应的所述待分类网页的类别;
步骤e2,统计所述训练样本中所述待分类网页各个类别出现的频率以及各类别下各个特征属性的条件概率估计;
步骤e3,对SVM分类器输出的所述待分类网页中的所述特征属性进行分析,计算该待分类网页属于各个类别的类别概率;
步骤e4,确定所述待分类网页的类别概率中数值最大的类别概率,该类别概率对应的类别为所述待分类网页的类别。
较佳的,所述步骤e3中,所述待分类网页的类别概率的计算公式为:
其中,x为待分类网页的特征向量,i为类别的序号,j为特征属性的序号,m为特征属性的总数,C为常数,yi为第i个类别,aj为第j个特征属性,P(yi)为第i个类别出现的频率,P(aj|yi)为第i个类别中第j个特征数学的条件概率估计,P(yi|x)为待分类网页的类别概率。
较佳的,所述网页数据为半结构化数据。
较佳的,所述步骤b中,所述词条项的权值计算公式为:
其中,ωi(d)为第i个词条项在文本d中的权值,ωi(d)为第i个词条项在文本d中出现的词频,N为所有文本的数目,ni为出现了第i个词条项的文本的数目。
较佳的,所述步骤c中,所述SVM分类模型的核函数为RBF核函数。
其次提供一种与上述所述的网页分类方法对应的基于混合算法的网页分类装置,其包括:
网页处理单元,搜索待分类网页,对所述待分类网页进行处理得到网页数据;
数据转换单元,对所述网页数据进行处理,用向量空间模型将所述网页数据转换为文本表示,计算词条项的权值并将所述待分类网页的特征向量转化成数值形式;
SVM分类单元,利用数值形式的特征向量作为训练数据,建立SVM的分类模型,并利用SVM分类器对待分类网页的所述特征向量进行分类;
数据输送单元,将SVM分类器输出的符合分类条件的所述特征向量输送至朴素贝叶斯分类器当中进行分类;
贝叶斯分类单元,利用朴素贝叶斯分类器对所述待分类网页的所述特征向量进行分类。
较佳的,所述SVM分类单元包括:
模型建立模块,利用数值形式的特征向量作为训练数据,确定分类公式,建立SVM的分类模型;
模型分类模块,利用SVM分类器的所述分类公式对所述待分类网页的特征向量进行计算,确认所述特征向量是否使所述分类公式成立,从而将所述特征向量分为两类。
较佳的,所述贝叶斯分类单元包括:
特征确定模块,从SVM分类器输出的所述特征向量中选择一部分作为训练样本,确定所述训练样本中每个特征向量对应的特征属性,以及每个特征向量对应的所述待分类网页的类别;
概率统计模块,统计所述训练样本中所述待分类网页各个类别出现的频率以及各类别下各个特征属性的条件概率估计;
概率计算模块,对SVM分类器输出的所述待分类网页中的所述特征属性进行分析,计算该待分类网页属于各个类别的类别概率;
类别确定模块,确定所述待分类网页的类别概率中数值最大的类别概率,该类别概率对应的类别为所述待分类网页的类别。
与现有技术比较本发明的有益效果在于:一种基于混合算法的网页分类方法和装置,利用SVM分类模型结合朴素贝叶斯支持增量式训练的特点,先采用SVM进行二分类,然后再用朴素贝叶斯方法进行多分类,分类更迅速,更精确;且当收录新的数据后能够自动进行调整,修正判断,提高准确率而不需要重新训练。它拥有提高分类计算效率与分类准确率、降低算法复杂度的优点。这种混合分类方法可以为网页分类以及实时营销提供快速准确的用户需求。
附图说明
为了更清楚地说明本发明各实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。
图1是本发明基于混合算法的网页分类方法的流程图;
图2是本发明基于混合算法的网页分类方法步骤c的流程图;
图3是本发明基于混合算法的网页分类方法步骤c的流程图;
图4是本发明基于混合算法的网页分类装置的结构示意图;
图5是本发明基于混合算法的网页分类装置SVM分类单元的结构示意图;
图6是本发明基于混合算法的网页分类装置贝叶斯分类单元的结构示意图。
具体实施方式
以下结合附图,对本发明上述的和另外的技术特征和优点作更详细的说明。
实施例1
如图1所示,其为本发明基于混合算法的网页分类方法的流程图,其中,所述基于混合算法的网页分类方法包括:
步骤a,搜索待分类网页,对所述待分类网页进行处理得到网页数据;
从所述待分类网页中获得网页数据,是通过这个页面的url来得到这个网页里面的某些数据,可用HttpClient获得。这些信息可以包括浏览量(PV)、访问次数、访客数(UV)、新访客数、新访客比率、IP、跳出率、平均访问时长、平均访问页数、转化次数、转化率等等。
所述网页数据为半结构化数据,通常表现为HTML格式。在中文网页的表示中,通过采用信息搜集系统搜索相关网页,将HTML文件中的标题与正文分别处理,(标题也作为正文的一部分),这样就可以将网页的表示转换为文本的表示。和普通纯文本相比,半结构化数据具有一定的结构性,但又不是具有严格理论模型的关系数据库的数据。比如XML就比较适合存储半结构化的数据,将不同类别的信息保存在XML的不同的节点中就可以了。
步骤b,对所述网页数据进行处理,用向量空间模型将所述网页数据转换为文本表示,计算词条项的权值并将所述待分类网页的特征向量转化成数值形式。
所述向量空间模型中,代表所述待分类网页特征的特征向量是由带有权重的词条组成的,即:特征向量的每个元素都是词条。
在所述向量空间模型中,文本空间被看作是由一组正交词条向量组成的向量空间。假设所有文本的特征总数是n,则构成一个n维的向量空间,其中每一个文本被表示为一个n维的特征向量:
V(d)=(t1,ω1(d);t2,ω2(d);…;tn,ωn(d))
其中V(d)为文本d对应的特征向量,t1、t2、tn为第1、2、n个词条项(向量),ω1(d)、ω2(d)、ωn(d)为t1、t2、tn在文本d中的权值。
词条项的权值计算公式为:
其中,ωi(d)为第i个词条项在文本d中的权值,ωi(d)为第i个词条项在文本d中出现的词频,N为所有文本的数目,ni为出现了第i个词条项的文本的数目。
该计算公式没有复杂的数学推导式,计算简单快速,利于理解,结果符合实际情况。简单、快速、准确地计算出权值,进而可以快速把每一个文本被表示为一个n维的特征向量。
步骤c,利用数值形式的特征向量作为训练数据,建立SVM的分类模型,并利用SVM分类器对待分类网页的所述特征向量进行分类。
所述SVM为支持向量机(Support Vector Machine)的简称。
SVM分类器对待分类网页的所述特征向量进行分类后,将特征向量分为两类一类是符合分类条件的样本,一类是不在分类范畴内的样本。比如获取到的网页数据存储在数据库当中,这些数据中不能确定哪些是符合分类条件的,需要用SVM进行一次过滤筛选。
步骤d,将SVM分类器输出的符合分类条件的所述特征向量输送至朴素贝叶斯分类器当中进行分类。
SVM分类器对待分类网页的所述特征向量进行分类后,将特征向量分为两类一类是符合分类条件的样本,一类是不在分类范畴内的样本。比如获取到的网页数据存储在数据库当中,这些数据中不能确定哪些是符合分类条件的,需要用SVM进行一次过滤筛选。
其中,符合分类条件的样本为需要的样本。所述分类条件根据实际情况确定,根据需要确定具体阈值,比如访客数(UV)大于多少,平均访问页数为多少等等。
步骤e,利用朴素贝叶斯分类器对所述待分类网页的所述特征向量进行分类。
这样,利用SVM分类模型结合朴素贝叶斯支持增量式训练的特点,先采用SVM进行二分类,然后再用朴素贝叶斯方法进行多分类,分类更迅速,更精确;且当收录新的数据后能够自动进行调整,修正判断,提高准确率而不需要重新训练。它拥有提高分类计算效率与分类准确率、降低算法复杂度的优点。这种混合分类方法可以为网页分类以及实时营销提供快速准确的用户需求。
实施例2
如上述所述的基于混合算法的网页分类方法,本实施例与其不同之处在于,所述步骤c中,所述SVM分类模型的核函数为RBF(径向基函数)核函数,这是因为网页类别繁多,使用RBF(径向基函数)核函数,其方法简单且容易实现,可以加快对网页分类的处理速度,进而加快建立SVM分类模型和利用SVM分类模型对待分类网页进行分类的速度。
其中,所述径向基函数中的向量之间的距离计算公式为:
其中,D为向量之间的距离,ωi(dm)为第i维空间中的向量dm,ωi(dn)为第i维空间中的向量dn。
其中,这种计算方法简单且容易实现,可以加快对网页分类的处理速度,进而加快建立SVM分类模型和利用SVM分类模型对待分类网页进行分类的速度。
实施例3
如上述所述的基于混合算法的网页分类方法,本实施例与其不同之处在于,如图2所示,所述步骤c包括:
步骤c1,利用数值形式的特征向量作为训练数据,确定分类公式,建立SVM的分类模型;
对待分类网页的类别进行判断,并将判断后的待分类网页的特征向量作为训练数据;利用所述训练数据,确定SVM分类模型的分类公式。
这里,作为训练数据的待分类网页是所有待分类网页的其中一部分。
所述SVM的建立过程为:
(xi,yi),i=1,...,n,x∈Rd,y∈{-1,+1}是类别符号。d维空间中线性判别函数的一般形式为g(x)=wx+b,分类线方程为wx+b=0。将判别函数进行归一化,使两类所有样本都满足|g(x)|=1,也就是使离分类面最近的样本的|g(x)|=1,此时分类间隔等于2/||w||,因此使间隔最大等价于使||w||(或||w||2)最小。
最后得到分类公式yi[(wx)+b]-1≥0,i=1,2,...,n
步骤c2,利用SVM分类器的所述分类公式对所述待分类网页的特征向量进行计算,确认所述特征向量是否使所述分类公式成立,从而将所述特征向量分为两类。
其中,能使所述分类公式成立的为一类样本,不能使所述分类公式成立的是另一类样本。
实施例4
如上述所述的基于混合算法的网页分类方法,本实施例与其不同之处在于,如图3所示,所述步骤e包括:
步骤e1,从SVM分类器输出的所述特征向量中选择一部分作为训练样本,确定所述训练样本中每个特征向量对应的特征属性,以及每个特征向量对应的所述待分类网页的类别。
比如一个特征向量中包括多个特征属性,则可以表示为x={a1,…,am},其中每个a为x的一个特征属性。
所述待分类网页的类别有多个,则可以表示为类别集合C={y1,…,yn}
步骤e2,统计所述训练样本中所述待分类网页各个类别出现的频率以及各类别下各个特征属性的条件概率估计。
所述各类别下各个特征属性的条件概率估计为:
P(a1|y1),P(a2|y1),…,P(am|y1);P(a1|y2),P(a2|y2),…,P(am|y2);…;P(a1|y
其中,y1、y2、...、yn是指从第1到第n个类别,a1、a2、...、am是从第1到第m个特征属性。P(am|yn)是指第n个类别中第m个特征属性的条件概率估计,也即是在出现了第n个类别的基础上,第m个特征属性出现的概率。
其中,所述条件概率估计是通过统计的方法根据实际情况确定的。
步骤e3,对SVM分类器输出的所述待分类网页中的所述特征属性进行分析,计算该待分类网页属于各个类别的类别概率。
其中,所述待分类网页的类别概率的计算公式为:
其中,x为待分类网页的特征向量,i为类别的序号,j为特征属性的序号,m为特征属性的总数,C为常数,yi为第i个类别,aj为第j个特征属性,P(yi)为第i个类别出现的频率,P(aj|yi)为第i个类别中第j个特征数学的条件概率估计,P(yi|x)为待分类网页的类别概率。
这样,可以快速计算出待分类网页属于各个类别的概率,从而迅速判断出待分类网页的最佳类别,提高判断效率;且公式简单,计算方便,节约了系统资源。
步骤e4,确定所述待分类网页的类别概率中数值最大的类别概率,该类别概率对应的类别为所述待分类网页的类别。
即如果:
P(yi|x)=max{P(y1|x),P(y2|x),…,P(yn|x)}
则x∈yk,即所述待分类网页的类别为第i个类别。
这样,用朴素贝叶斯模型进行多分类,分类更迅速;且当收录新的数据后能够自动进行调整,修正判断,提高准确率而不需要重新训练。它拥有提高分类计算效率与分类准确率、降低算法复杂度的优点。
实施例5
如上述所述的基于混合算法的网页分类装置,本实施例为与其对应的基于混合算法的网页分类装置,如图4所示,其为本发明基于混合算法的网页分类装置的结构示意图,其中,所述基于混合算法的网页分类装置包括:
网页处理单元1,搜索待分类网页,对所述待分类网页进行处理得到网页数据;
从所述待分类网页中获得网页数据,是通过这个页面的url来得到这个网页里面的某些数据,可用HttpClient获得。这些信息可以包括浏览量(PV)、访问次数、访客数(UV)、新访客数、新访客比率、IP、跳出率、平均访问时长、平均访问页数、转化次数、转化率等等。
所述网页数据为半结构化数据,通常表现为HTML格式。在中文网页的表示中,通过采用信息搜集系统搜索相关网页,将HTML文件中的标题与正文分别处理,(标题也作为正文的一部分),这样就可以将网页的表示转换为文本的表示。和普通纯文本相比,半结构化数据具有一定的结构性,但又不是具有严格理论模型的关系数据库的数据。比如XML就比较适合存储半结构化的数据,将不同类别的信息保存在XML的不同的节点中就可以了。
数据转换单元2,对所述网页数据进行处理,用向量空间模型将所述网页数据转换为文本表示,计算词条项的权值并将所述待分类网页的特征向量转化成数值形式。
所述向量空间模型中,代表所述待分类网页特征的特征向量是由带有权重的词条组成的,即:特征向量的每个元素都是词条。
在所述向量空间模型中,文本空间被看作是由一组正交词条向量组成的向量空间。假设所有文本的特征总数是n,则构成一个n维的向量空间,其中每一个文本被表示为一个n维的特征向量:
V(d)=(t1,ω1(d);t2,ω2(d);…;tn,ωn(d))
其中V(d)为文本d对应的特征向量,t1、t2、tn为第1、2、n个词条项(向量),ω1(d)、ω2(d)、ωn(d)为t1、t2、tn在文本d中的权值。
词条项的权值计算公式为:
其中,ωi(d)为第i个词条项在文本d中的权值,ωi(d)为第i个词条项在文本d中出现的词频,N为所有文本的数目,ni为出现了第i个词条项的文本的数目。
该计算公式没有复杂的数学推导式,计算简单快速,利于理解,结果符合实际情况。简单、快速、准确地计算出权值,进而可以快速把每一个文本被表示为一个n维的特征向量。
SVM分类单元3,利用数值形式的特征向量作为训练数据,建立SVM的分类模型,并利用SVM分类器对待分类网页的所述特征向量进行分类。
所述SVM为支持向量机(Support Vector Machine)的简称。
SVM分类器对待分类网页的所述特征向量进行分类后,将特征向量分为两类一类是符合分类条件的样本,一类是不在分类范畴内的样本。比如获取到的网页数据存储在数据库当中,这些数据中不能确定哪些是符合分类条件的,需要用SVM进行一次过滤筛选。
数据输送单元4,将SVM分类器输出的符合分类条件的所述特征向量输送至朴素贝叶斯分类器当中进行分类。
SVM分类器对待分类网页的所述特征向量进行分类后,将特征向量分为两类一类是符合分类条件的样本,一类是不在分类范畴内的样本。比如获取到的网页数据存储在数据库当中,这些数据中不能确定哪些是符合分类条件的,需要用SVM进行一次过滤筛选。
其中,符合分类条件的样本为需要的样本。所述分类条件根据实际情况确定,根据需要确定具体阈值,比如访客数(UV)大于多少,平均访问页数为多少等等。
贝叶斯分类单元5,利用朴素贝叶斯分类器对所述待分类网页的所述特征向量进行分类。
这样,利用SVM分类模型结合朴素贝叶斯支持增量式训练的特点,先采用SVM进行二分类,然后再用朴素贝叶斯模型进行多分类,分类更迅速,更精确;且当收录新的数据后能够自动进行调整,修正判断,提高准确率而不需要重新训练。它拥有提高分类计算效率与分类准确率、降低算法复杂度的优点。这种混合分类装置可以为网页分类以及实时营销提供快速准确的用户需求。
实施例6
如上述所述的基于混合算法的网页分类装置,本实施例与其不同之处在于,所述SVM分类单元3中,所述SVM分类模型的核函数为RBF(径向基函数)核函数,这是因为网页类别繁多,使用RBF(径向基函数)核函数,其方法简单且容易实现,可以加快对网页分类的处理速度,进而加快建立SVM分类模型和利用SVM分类模型对待分类网页进行分类的速度。
其中,所述径向基函数中的向量之间的距离计算公式为:
其中,D为向量之间的距离,ωi(dm)为第i维空间中的向量dm,ωi(dn)为第i维空间中的向量dn。
其中,这种计算方法简单且容易实现,可以加快对网页分类的处理速度,进而加快建立SVM分类模型和利用SVM分类模型对待分类网页进行分类的速度。
实施例7
如上述所述的基于混合算法的网页分类装置,本实施例与其不同之处在于,如图5所示,SVM分类单元3包括:
模型建立模块31,利用数值形式的特征向量作为训练数据,确定分类公式,建立SVM的分类模型;
对待分类网页的类别进行判断,并将判断后的待分类网页的特征向量作为训练数据;利用所述训练数据,确定SVM分类模型的分类公式。
这里,作为训练数据的待分类网页是所有待分类网页的其中一部分。
所述SVM的建立过程为:
(xi,yi),i=1,...,n,x∈Rd,y∈{-1,+1}是类别符号。d维空间中线性判别函数的一般形式为g(x)=wx+b,分类线方程为wx+b=0。将判别函数进行归一化,使两类所有样本都满足|g(x)|=1,也就是使离分类面最近的样本的|g(x)|=1,此时分类间隔等于2/||w||,因此使间隔最大等价于使||w||(或||w||2)最小。
最后得到分类公式yi[(wx)+b]-1≥0,i=1,2,...,n
模型分类模块32,利用SVM分类器的所述分类公式对所述待分类网页的特征向量进行计算,确认所述特征向量是否使所述分类公式成立,从而将所述特征向量分为两类。
其中,能使所述分类公式成立的为一类样本,不能使所述分类公式成立的是另一类样本。
实施例8
如上述所述的基于混合算法的网页分类装置,本实施例与其不同之处在于,如图6所示,所述贝叶斯分类单元5包括:
特征确定模块51,从SVM分类器输出的所述特征向量中选择一部分作为训练样本,确定所述训练样本中每个特征向量对应的特征属性,以及每个特征向量对应的所述待分类网页的类别。
比如一个特征向量中包括多个特征属性,则可以表示为x={a1,...,am},其中每个a为x的一个特征属性。
所述待分类网页的类别有多个,则可以表示为类别集合C={y1,...,yn}
概率统计模块52,统计所述训练样本中所述待分类网页各个类别出现的频率以及各类别下各个特征属性的条件概率估计。
所述各类别下各个特征属性的条件概率估计为:
P(a1|y1),P(a2|y1),…,P(am|y1);P(a1|y2),P(a2|y2),…,P(am|y2);…;P(a1|y
其中,y1、y2、...、yn是指从第1到第n个类别,a1、a2、...、am是从第1到第m个特征属性。P(am|yn)是指第n个类别中第m个特征属性的条件概率估计,也即是在出现了第n个类别的基础上,第m个特征属性出现的概率。
其中,所述条件概率估计是通过统计的方法根据实际情况确定的。
概率计算模块53,对SVM分类器输出的所述待分类网页中的所述特征属性进行分析,计算该待分类网页属于各个类别的类别概率。
其中,所述待分类网页的类别概率的计算公式为:
其中,x为待分类网页的特征向量,i为类别的序号,j为特征属性的序号,m为特征属性的总数,C为常数,yi为第i个类别,aj为第j个特征属性,P(yi)为第i个类别出现的频率,P(aj|yi)为第i个类别中第j个特征数学的条件概率估计,P(yi|x)为待分类网页的类别概率。
这样,可以快速计算出待分类网页属于各个类别的概率,从而迅速判断出待分类网页的最佳类别,提高判断效率;且公式简单,计算方便,节约了系统资源。
类别确定模块54,确定所述待分类网页的类别概率中数值最大的类别概率,该类别概率对应的类别为所述待分类网页的类别。
即如果:
P(yi|x)=max{P(y1|x),P(y2|x),…,P(yn|x)}
则x∈yk,即所述待分类网页的类别为第i个类别。
这样,用朴素贝叶斯模型进行多分类,分类更迅速;且当收录新的数据后能够自动进行调整,修正判断,提高准确率而不需要重新训练。它拥有提高分类计算效率与分类准确率、降低算法复杂度的优点。
以上所述仅为本发明的较佳实施例,对本发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在本发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!