一种基于K‑means和LDA双向验证的网络行为习惯聚类方法与流程
本发明属于聚类分析、优化算法领域,特别涉及一种基于K-means和LDA的双向验证的网络行为习惯聚类方法,用于优化聚类结果,进而提高聚类准确性,并以此增加人员上网记录信息的使用价值。
背景技术:
掌握网络行为习惯数据的聚类方法对于研究人员的上网习惯有重要的作用和意义,随着互联网的不断普及,越来越多的人选择通过网络来获取感兴趣的信息。人员上网浏览的内容的信息量庞大,单单依靠人工来分析这些数据不仅效率低下,而且准确度也不高。通过聚类分析,再加上与另一种聚类方法双向验证,可以提高分析的效率以及分析的准确率。一般的聚类算法有K-means聚类和LDA文档主题提取模型等,一般的优化算法有模拟退火算法和遗传算法等。
聚类算法和优化算法的相关论文有:庞峰. 模拟退火算法的原理及算法在优化问题上的应用. 吉林大学硕士论文, 2006;李香平, 张红阳. 模拟退火算法原理及改进. 软件导刊, 2008(4):47-48;杨梦铎, 李凡长, 张莉. 李群机器学习十年研究进展. 计算机学报, 2015(7):1337-1356;Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation. Proceeding of Journal of Machine Learning Research. 2003, Vol.3:993-1022;Yuan J, Gao F, Ho Q, et al. LightLDA: Big Topic Models on Modest Computer Clusters. Proceeding of International Conference on World Wide Web. ACM, 2015;朱全银等人已有的研究基础包括:李翔, 朱全银. 联合聚类和评分矩阵共享的协同过滤推荐. 计算机科学与探索. 2014. Vol.8(6):751-759;Suqun Cao, Quanyin Zhu, Zhiwei Hou. Customer Segmentation Based on a Novel Hierarchical Clustering Algorithm. 2009, p:1-5;Quanyin Zhu,Sunqun Cao. A Novel Classifier-independent Feature Selection Algorithm for Imbalanced Datasets. 2009, p:77-82;Suqun Cao,Zhiwei Hou, Liuyang Wang, Quanyin Zhu. Kernelized Fuzzy Fisher Criterion based Clustering Algorithm. DCABES 2010, p:87-91;Quanyin Zhu, Yunyang Yan, Jin Ding, Jin Qian. The Case Study for Price Extracting of Mobile Phone Sell Online. 2011, p:282-285;Quanyin Zhu, Suqun Cao, Pei Zhou, Yunyang Yan, Hong Zhou. Integrated Price Forecast based on Dichotomy Backfilling and Disturbance Factor Algorithm. International Review on Computers and Software, 2011, Vol.6(6):1089-1093;Suqun Cao, Gelan Yang, Quanyin Zhu, Haihei Zhai. A novel feature extraction method for mechanical part recognition. Applied Mechanics and Materials, 2011, p:116-121;Pei Zhou, Quanyin Zhu. Multi-factor Matching Method for Basic Information of Science and Technology Experts Based on Web Mining. 2012, P:718-720;Jianping Deng, Fengwen Cao, Quanyin Zhu, Yu Zhang. The Web Data Extracting and Application for Shop Online Based on Commodities Classified. Communications in Computer and Information Science, Vol.234(4):120-128;Hui Zong, Quanyin Zhu, Ming Sun, Yahong Zhang. The case study for human resource management research based on web mining and semantic analysis. Applied Mechanics and Materials, Vol.488,2014 p:1336-1339;朱全银等人申请、公开与授权的相关专利:朱全银, 胡蓉静, 曹苏群, 周培等. 一种基于线性插补与自适应滑动窗口的商品价格预测方法. 中国专利:ZL 2011 1 0423015.5, 2015.07.01;朱全银, 曹苏群, 严云洋, 胡蓉静等. 一种基于二分数据修补与扰动因子的商品价格预测方法. 中国专利:ZL 2011 1 0422274.6, 2013.01.02;朱全银, 尹永华, 严云洋, 陈婷, 曹苏群. 一种基于神经网络的多品种商品价格预测的数据预处理方法. 中国专利:ZL 2012 1 0325368.6, 2016.06.08;朱全银, 潘禄, 刘文儒, 李翔, 周泓, 胡荣林, 丁瑾, 金鹰, 邵武杰, 唐海波. 一种科技新闻的增量学习多层次二分类方法. 中国专利公开号:CN 105205163A, 2015.12.30;朱全银, 严云洋, 黄涛贻, 张亮, 张于洋, 辛诚. 一种校园个性化掌上服务及用户行为习惯分析的实现方法. 中国专利公开号:CN 104731971A, 2015.06.24;朱全银,沈恩强,钱亚平,周泓等. 一种基于K-means聚类多权重自适应的学生学习行为分析方法. 中国专利申请号:201610222553.0, 2016.04.13;朱全银,邵武杰,唐海波,周泓,李翔,胡荣林,金鹰,曹苏群,潘舒新. 一种科学新闻标题的多层次多分类方法. 中国专利公开号:CN 105205163A, 2016.07.13;李翔,朱全银,胡荣林,周泓. 一种基于谱聚类的冷链物流配载智能推荐方法. 中国专利公开号:CN 105654267A, 2016.06.08。
LDA文档主题提取模型:
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
K-means聚类算法:
源于信号处理中的一种矢量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间划分为Voronoi cells的问题。这个问题在计算上是困难的(NP困难),不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。而且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允许聚类有不同的形状。
模拟退火算法:
模拟退火算法(Simulated Annealing,SA)最早的思想是由N. Metropolis等人于1953年提出。1983 年,S. Kirkpatrick 等成功地将退火思想引入到组合优化领域。它是基于Monte-Carlo迭代求解策略的一种随机寻优算法,其出发点是基于物理中固体物质的退火过程与一般组合优化问题之间的相似性。模拟退火算法从某一较高初温出发,伴随温度参数的不断下降,结合概率突跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性地跳出并最终趋于全局最优。模拟退火算法是一种通用的优化算法,理论上算法具有概率的全局优化性能,目前已在工程中得到了广泛应用,诸如VLSI、生产调度、控制工程、机器学习、神经网络、信号处理等领域。模拟退火算法是通过赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结构的优化算法。
启发式搜索:
计算机科学的两大基础目标,就是发现可证明其运行效率良好且可得最佳解或次佳解的算法。而启发式算法则试图一次提供一个或全部目标。例如它常能发现很不错的解,但也没办法证明它不会得到较坏的解;它通常可在合理时间解出答案,但也没办法知道它是否每次都可以这样的速度求解。在某些特殊情况下,启发式算法会得到很坏的答案或效率极差,然而造成那些特殊情况的数据结构,也许永远不会在现实世界出现。因此现实世界中启发式算法很常用来解决问题。启发式算法处理许多实际问题时通常可以在合理时间内得到不错的答案。常见的启发式算法有蚁群算法、遗传算法、模拟退火算法等。
技术实现要素:
为了帮助管理人员了解和改善被管理人员的上网习惯、减少互联网的不良影响以及挖掘出被管理人员的上网数据与兴趣爱好之间的一般性联系,通过综合分析被管理人员的上网记录,采用基于LDA模型的文档聚类算法以及K均值聚类算法,设计实现了一种基于K-means和LDA双向验证的网络行为习惯聚类方法,为被管理人员上网行为的分析与管理提供了有较好参考价值的系统模型。
为了便于理解本发明专利的理论基础,对本发明的理论与传统理论的区别描述如下:
在传统聚类方法中,一般是对初始数据采用一种方式进行聚类分析,再通过人工分析的方式进行验证。本发明在传统方法的基础上,创造性的采用两种聚类方法,通过自定义的验证方法验证聚类算法的准确性,并使用模拟退火算法来提高优化聚类结果的效率。
本发明的技术方案是:利用人员上网记录中的网页属性、关键词和频数,结合K-means算法、LDA文档主题提取模型和退火算法,先对全体人员-标签-频率集、人员浏览记录-人员-关键词集进行K-means算法聚类和LDA文档主题提取模型生成,存储计算中间结果,之后使用退火算法将K-means和LDA进行双向验证,计算全局最佳主题-分类标签序列,以此为依据优化网络行为习惯聚类的结果;其中,包含模拟退火算法主流程步骤A和成本函数处理流程步骤B:
模拟退火算法主流程步骤A1到步骤A26:
步骤A1:设全体人员-标签-频率集为PERSONLABELFREQ={(PERSONp1, LABELp1, FREQp1), (PERSONp2, LABELp2, FREQp2), …, (PERSONpa, LABELpa, FREQpa)},其中,PERSONp1, PERSONp2, …, PERSONpa代表人员唯一标识,LABELp1, LABELp2, …, LABELpa代表人员上网浏览内容的整体属性,一个人员唯一标识可对应多个属性,FREQp1,FREQp2, …, FREQpa代表人员上网浏览内容的整体属性的权重,设人员上网浏览记录-人员-关键词集为RECORDIDPERSONKEYWORD={(RECORDIDr1, PERSONr1, KEYWORDr1), (RECORDIDr2, PERSONr2, KEYWORDr2), …, (RECORDIDra, PERSONra, KEYWORDra)},其中,RECORDIDr1, RECORDIDr2, …, RECORDIDra代表人员记录唯一标识,由人员唯一标识和上网日期组成,PERSONr1, PERSONr2, …, PERSONra代表人员唯一标识,KEYWORDr1,KEYWORDr2, …, KEYWORDra代表人员上网浏览内容包含的关键词,设主题分布的狄利克雷参数为ALPHA,设关键词分布的狄利克雷参数为ETA,设LDA文档主题提取模型迭代次数为ITERLDA,设K-means聚类算法迭代次数为ITERKMEANS,设分类标签总数为CATEGORYNUM,设LDA文档主题提取模型的主题总数为TOPICNUM,设模拟退火算法温度为T,设模拟退火算法改变步长为STEP,设模拟退火算法冷却参数为COOL;
步骤A2:设K-means聚类算法的结果集为全体人员-分类标签集,即,表示为KMEANSPERSONCATEGORY,其中,分类标签由自然整数表示;设LDA模型的主题-关键词集为LDATOPICWORD,其中,主题由自然整数表示;设LDA模型的主题-人员集为LDATOPICPERSON,其中,主题由自然整数表示;设全局最佳主题-分类标签序列为FACTOR,设全局最大匹配数为EA,设当前主题-分类标签序列为vecb,设当前匹配数为eb,设主题-分类标签序列当前下标为index,设模拟退火算法当前步长为curstep;
步骤A3:调用K-means聚类算法工具,传入步骤A1中的分类标签总数CATEGORYNUM、步骤A1中的K-means聚类算法迭代次数ITERKMEANS以及步骤A1中的全体人员-标签-频率集PERSONLABELFREQ,得到K-means聚类算法结果集为全体人员-分类标签集,即,得到KMEANSPERSONCATEGORY={(PERSON1, CATEGORYc1), (PERSON2, CATEGORYc2), …, (PERSONa, CATEGORYca)},其中,KMEANSPERSONCATEGORY来自步骤A2;
步骤A4:调用LDA模型工具,传入LDA文档主题提取模型的主题总数TOPICNUM、主题分布的狄利克雷参数ALPHA、关键词分布的狄利克雷参数ETA、LDA文档主题提取模型迭代次数ITERLDA以及人员上网浏览记录-人员-关键词集RECORDIDPERSONKEYWORD,得到LDA模型的主题-关键词集,即,得到DATOPICWORD={(TOPICt1, KEYWORD1), (TOPICt2, KEYWORD2), …, (TOPICtb, KEYWORDb)}以及LDA模型的主题-人员集,即,LDATOPICPERSON={(TOPICt1, PERSONp1), (TOPICt2, PERSONp2), …, (TOPICtc, PERSONpc)},其中,LDATOPICWORD以及LDATOPICPERSON来自步骤A2;
步骤A5:用0到CATEGORYNUM-1之间的随机数初始化全局最佳主题-分类标签序列FACTOR,序列长度为LDA文档主题提取模型的主题总数TOPICNUM,序列中的每个元素的范围在0到CATEGORYNUM-1之间,其中,CATEGORYNUM为分类标签总数,初始化全局最大匹配数EA为0,即,FACTOR={FACTOR1, FACTOR2, …, FACTORTOPICNUM},EA=0;
步骤A6:当步骤A1中的模拟退火算法温度T大于0.1时,则执行步骤A7到步骤A25;否则执行步骤A26;
步骤A7:给步骤A2中的主题-分类标签序列当前下标index以随机数赋值,随机数的范围在0和TOPICNUM-1之间,其中,TOPICNUM为步骤A1中的LDA文档主题提取模型的主题总数;
步骤A8:给步骤A2中的模拟退火算法当前步长为curstep以随机数赋值,随机数的范围在-1×STEP和STEP之间,其中,STEP为步骤A1中的模拟退火算法改变步长;
步骤A9:令步骤A2中的当前主题-分类标签序列vecb等于步骤A2中的全局最佳主题-分类标签序列FACTOR,即,vecb=FACTOR;
步骤A10:改变步骤A2中的当前主题-分类标签序列vecb,第index位置上的数值,令vecbindex加上curstep,其中,index为步骤A2中的主题-分类标签序列当前下标,curstep为步骤A2中的模拟退火算法当前步长,即,vecbindex= vecbindex+curstep;
步骤A11:当步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值小于0时,即,vecbindex<0,则执行步骤A12;否则执行步骤A13;
步骤A12:令步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值等于0,即,vecbindex=0;转到步骤A15;
步骤A13:当步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值大于CATEGORYNUM-1时,其中,CATEGORYNUM为步骤A1中的分类标签总数,即,vecbindex>CATEGORYNUM-1,则执行步骤A14;否则执行步骤A15;
步骤A14:令步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值等于CATEGORYNUM-1,即,vecbindex= CATEGORYNUM-1,其中,CATEGORYNUM为步骤A1中的分类标签总数;
步骤A15:获取步骤A2中的全局最佳主题-分类标签序列FACTOR;
步骤A16:执行步骤B;
步骤A17:获取步骤B的结果赋给步骤A2中的全局最大匹配数EA;
步骤A18:获取步骤A2中的当前主题-分类标签序列vecb;
步骤A19:执行步骤B;
步骤A20:获取步骤B的结果赋给步骤A2中的当前匹配数eb;
步骤A21:当步骤A2中的当前匹配数eb大于步骤A2中的全局最大匹配数EA时,即,eb>EA,则执行步骤A22;否则执行步骤A25;
步骤A22:生成随机数random,其中,数值范围在0到1之间;
步骤A23:当步骤A22中的随机数random小于e(eb-EA)/T时,即,random<e(eb-EA)/T,其中,eb为步骤A2中的当前匹配数,EA为步骤A2中的全局最大匹配数,则执行步骤A24;否则执行步骤A25;
步骤A24:令步骤A2中的全局最佳主题-分类标签序列FACTOR的值为步骤A2中的当前主题-分类标签序列vecb,令步骤A2中的全局最大匹配数EA的值为步骤A2中的当前匹配数eb,即,FACTOR=vecb,EA=eb;
步骤A25:降低步骤A1中的模拟退火算法温度T,使用步骤A1中的模拟退火算法冷却参数COOL,即,T=T×COOL,执行步骤A6;
步骤A26:返回步骤A2中的全局最佳主题-分类标签序列,即,FACTOR={FACTOR1, FACTOR2, …, FACTORTOPICNUM};返回步骤A2中的全局最大匹配数EA;
成本函数处理流程步骤B从步骤B1到步骤B15:
步骤B1:获取步骤A中传入的主题-分类标签序列TMPFACTOR;
步骤B2:设LDA文档主题提取模型的人员-分类标签集为LDAPERSONCATEGORY,设人员唯一标识集为LDAPERSON,设人员总数为LDAPERSONNUM,设全体分类标签集为CATEGORY,设匹配数为SUM,设单个人员对应的主题集合为singlepersontopic,设LDA文档主题提取模型中当前分类人员集合为ldacurcategoryperson,设K-means聚类算法中当前分类人员集合为kmeanscurcategoryperson,设重合的人数集合为unionperson,设重合的人数为unionpersonnum;
步骤B3:从步骤A2中的LDA模型的主题-人员集LDATOPICPERSON中筛选出步骤B2中的人员唯一标识集LDAPERSON,并对筛选结果去重,即,LDAPERSON=Π2(LDATOPICPERSON) ={PERSONp1, PERSONp2, …, PERSONpd};
步骤B4:从步骤A2中的K-means算法的全体人员-分类标签集KMEANSPERSONCATEGORY中筛选出步骤B2中的全体分类标签集CATEGORY,并对筛选结果去重,即,CATEGORY=Π2(KMEANSPERSONCATEGORY)={CATEGORYc1, CATEGORYc2, …, CATEGORYcd};
步骤B5:设循环变量为i,i<LDAPERSONNUM,其中,LDAPERSONNUM为步骤B2中的人员总数;
步骤B6:从步骤A2中的LDA模型的主题-人员集LDATOPICPERSON中筛选出LDAPERSONi对应的主题集合singlepersontopic,即,={TOPICt1, TOPICt2, …, TOPICtc},其中,singlepersontopic来自步骤B2;
步骤B7:对LDAPERSONi对应的主题集合singlepersontopic中每一个主题,从步骤B1中的主题-分类标签序列TMPFACTOR中找到对应的分类标签,其中,TMPFACTOR的下标代表主题,下标对应的值代表该主题对应的分类标签,即,categoryt1 = TMPFACTORTOPICt1、categoryt2 = TMPFACTORTOPICt2、…、categorytc = TMPFACTORTOPICtc,其中,categoryt1 ,categoryt2 , …, categorytc 代表分类标签,并且,不同的变量可能代表同一个分类标签,singlepersontopic来自步骤B2;统计每个分类标签出现的次数,记为categorysnum1, categorysnum2, …, categorysnumCATEGORYNUM,找出分类标签出现次数最大的分类标签category;更新步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY,即,LDAPERSONCATEGORY=LDAPERSONCATEGORY∪{(LDAPERSONi, category)};
步骤B8:当循环变量i大于LDAPERSONNUM时,其中,LDAPERSONNUM为步骤B2中的人员总数,则执行步骤B9;否则,i值加1,即,i=i+1,执行步骤B6到步骤B7;
步骤B9:设循环变量为j,j<CATEGORYNUM,其中,CATEGORYNUM为步骤A1中的分类标签总数,设步骤B2中的匹配数SUM为0,即SUM=0;
步骤B10:从步骤A2中的K-means算法的全体人员-分类标签集KMEANSPERSONCATEGORY中筛选出CATEGORYj对应的人员集合kmeanscurcategoryperson,即, = {PERSONkmeans1, PERSONkmeans2, … , PERSONkmeansc},其中,kmeanscurcategoryperson来自步骤B2;
步骤B11:从步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY中筛选出CATEGORYj对应的人员集合ldacurcategoryperson,即, ={PERSONlda1, PERSONlda2, … , PERSONldac},其中,ldacurcategoryperson来自步骤B2;
步骤B12:计算步骤B2中的人员集合ldacurcategoryperson与步骤B2中的人员集合kmeanscurcategoryperson的交集unionperson,即,unionperson=ldacurcategoryperson∩kmeanscurcategoryperson={PERSONunion1, PERSONunion2, … , PERSONunionc};
步骤B13:统计步骤B2中的重合的人数集合unionperson的人数个数,赋值给步骤B2中的重合的人数unionpersonnum,并叠加到步骤B2中的匹配数SUM,即,SUM=SUM+unionpersonnum;
步骤B14:当循环变量j大于步骤A1中的分类标签总数CATEGORYNUM时,则执行步骤B15;否则,j的值加1,即,j=j+1,执行步骤B10到步骤B13;
步骤B15:返回步骤B2中的匹配数SUM。
其中,聚类是将全体人员上网记录使用K-means聚类算法和LDA模型进行聚类分析,再将两个聚类结果相互验证,并使用模拟退火算法提高优化聚类结果的效率,以此提高聚类准确性。
其中,步骤A3到步骤A4提供模拟退火算法所需的初始数据;步骤A7到步骤A12是在模拟退火算法中更改当前解序列中的随机位置上的数值;步骤B5到步骤B8是通过步骤B1中的主题-分类标签序列TMPFACTOR与步骤A2中的LDA模型的主题-人员集LDATOPICPERSON进行关联,关联出步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY;步骤B9到步骤B14是通过比对相同类别中,同时出现在K-means聚类结果中与LDA模型结果中的人员的个数,并叠加各个类别中此类人员的个数,并在流程的最后返回,并作为当前序列的成本;步骤A14到步骤A18是判断eb与EA的大小以及步骤A15中的随机数random与e(eb-EA)/T的大小,其中,eb为步骤A2中的当前匹配数,EA为步骤A2中的全局最大匹配数,当eb>EA并且random<e(eb-EA)/T时,则更新全局最佳主题-分类标签序列FACTOR的值以及全局最大匹配数EA的值,eb与EA的成本数值通过上述的步骤B得出;最终结果返回全局最大匹配数EA以及全局最佳主题-分类标签序列FACTOR。
其中,步骤A3中的K-means聚类算法迭代次数ITERKMEANS为300,分类标签总数CATEGORYNUM为3,步骤A4中的主题分布的狄利克雷参数ALPHA为0.1,关键词分布的狄利克雷参数ETA为0.01,LDA文档主题提取模型迭代次数ITERLDA为2000,步骤A1中的LDA文档主题提取模型的主题总数TOPICNUM为20。
本发明创造性地利用人员上网记录中的网页属性、关键词和频数,结合K-means算法、LDA文档主题提取模型与退火算法,先对全体人员-标签-频率集、人员浏览记录-人员-关键词集进行K-means算法聚类和LDA文档主题提取模型生成,存储计算中间结果,之后使用退火算法将K-means和LDA进行双向验证计算全局最佳主题-分类标签序列,以此依据优化网络行为习惯聚类的结果,K-means和LDA双向验证提高了对人员-分类标签的敏感度,退火算法能够提高优化聚类结果的效率,进而提高聚类准确性。
附图说明
附图1为模拟退火算法主流程。
附图2为成本函数处理流程。
具体实施方式
下面结合附图对本发明的技术方案进行详细说明:
如附图1,模拟退火算法主流程步骤A1到步骤A26:
步骤A1:设全体人员-标签-频率集为PERSONLABELFREQ={(PERSONp1, LABELp1, FREQp1), (PERSONp2, LABELp2, FREQp2), …, (PERSONpa, LABELpa, FREQpa)},其中,PERSONp1, PERSONp2, …, PERSONpa代表人员唯一标识,LABELp1, LABELp2, …, LABELpa代表人员上网浏览内容的整体属性,一个人员唯一标识可对应多个属性,FREQp1,FREQp2, …, FREQpa代表人员上网浏览内容的整体属性的权重,设人员上网浏览记录-人员-关键词集为RECORDIDPERSONKEYWORD={(RECORDIDr1, PERSONr1, KEYWORDr1), (RECORDIDr2, PERSONr2, KEYWORDr2), …, (RECORDIDra, PERSONra, KEYWORDra)},其中,RECORDIDr1, RECORDIDr2, …, RECORDIDra代表人员记录唯一标识,由人员唯一标识和上网日期组成,PERSONr1, PERSONr2, …, PERSONra代表人员唯一标识,KEYWORDr1,KEYWORDr2, …, KEYWORDra代表人员上网浏览内容包含的关键词,设主题分布的狄利克雷参数为ALPHA,设关键词分布的狄利克雷参数为ETA,设LDA文档主题提取模型迭代次数为ITERLDA,设K-means聚类算法迭代次数为ITERKMEANS,设分类标签总数为CATEGORYNUM,设LDA文档主题提取模型的主题总数为TOPICNUM,设模拟退火算法温度为T,设模拟退火算法改变步长为STEP,设模拟退火算法冷却参数为COOL;
步骤A2:设K-means聚类算法的结果集为全体人员-分类标签集,即,表示为KMEANSPERSONCATEGORY,其中,分类标签由自然整数表示;设LDA模型的主题-关键词集为LDATOPICWORD,其中,主题由自然整数表示;设LDA模型的主题-人员集为LDATOPICPERSON,其中,主题由自然整数表示;设全局最佳主题-分类标签序列为FACTOR,设全局最大匹配数为EA,设当前主题-分类标签序列为vecb,设当前匹配数为eb,设主题-分类标签序列当前下标为index,设模拟退火算法当前步长为curstep;
步骤A3:调用K-means聚类算法工具,传入步骤A1中的分类标签总数CATEGORYNUM、步骤A1中的K-means聚类算法迭代次数ITERKMEANS以及步骤A1中的全体人员-标签-频率集PERSONLABELFREQ,得到K-means聚类算法结果集为全体人员-分类标签集,即,得到KMEANSPERSONCATEGORY={(PERSON1, CATEGORYc1), (PERSON2, CATEGORYc2), …, (PERSONa, CATEGORYca)},其中,KMEANSPERSONCATEGORY来自步骤A2;
步骤A4:调用LDA模型工具,传入LDA文档主题提取模型的主题总数TOPICNUM、主题分布的狄利克雷参数ALPHA、关键词分布的狄利克雷参数ETA、LDA文档主题提取模型迭代次数ITERLDA以及人员上网浏览记录-人员-关键词集RECORDIDPERSONKEYWORD,得到LDA模型的主题-关键词集,即,得到DATOPICWORD={(TOPICt1, KEYWORD1), (TOPICt2, KEYWORD2), …, (TOPICtb, KEYWORDb)}以及LDA模型的主题-人员集,即,LDATOPICPERSON={(TOPICt1, PERSONp1), (TOPICt2, PERSONp2), …, (TOPICtc, PERSONpc)},其中,LDATOPICWORD以及LDATOPICPERSON来自步骤A2;
步骤A5:用0到CATEGORYNUM-1之间的随机数初始化全局最佳主题-分类标签序列FACTOR,序列长度为LDA文档主题提取模型的主题总数TOPICNUM,序列中的每个元素的范围在0到CATEGORYNUM-1之间,其中,CATEGORYNUM为分类标签总数,初始化全局最大匹配数EA为0,即,FACTOR={FACTOR1, FACTOR2, …, FACTORTOPICNUM},EA=0;
步骤A6:当步骤A1中的模拟退火算法温度T大于0.1时,则执行步骤A7到步骤A25;否则执行步骤A26;
步骤A7:给步骤A2中的主题-分类标签序列当前下标index以随机数赋值,随机数的范围在0和TOPICNUM-1之间,其中,TOPICNUM为步骤A1中的LDA文档主题提取模型的主题总数;
步骤A8:给步骤A2中的模拟退火算法当前步长为curstep以随机数赋值,随机数的范围在-1×STEP和STEP之间,其中,STEP为步骤A1中的模拟退火算法改变步长;
步骤A9:令步骤A2中的当前主题-分类标签序列vecb等于步骤A2中的全局最佳主题-分类标签序列FACTOR,即,vecb=FACTOR;
步骤A10:改变步骤A2中的当前主题-分类标签序列vecb,第index位置上的数值,令vecbindex加上curstep,其中,index为步骤A2中的主题-分类标签序列当前下标,curstep为步骤A2中的模拟退火算法当前步长,即,vecbindex= vecbindex+curstep;
步骤A11:当步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值小于0时,即,vecbindex<0,则执行步骤A12;否则执行步骤A13;
步骤A12:令步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值等于0,即,vecbindex=0;转到步骤A15;
步骤A13:当步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值大于CATEGORYNUM-1时,其中,CATEGORYNUM为步骤A1中的分类标签总数,即,vecbindex>CATEGORYNUM-1,则执行步骤A14;否则执行步骤A15;
步骤A14:令步骤A2中的当前主题-分类标签序列vecb在第index位置上的数值等于CATEGORYNUM-1,即,vecbindex= CATEGORYNUM-1,其中,CATEGORYNUM为步骤A1中的分类标签总数;
步骤A15:获取步骤A2中的全局最佳主题-分类标签序列FACTOR;
步骤A16:执行步骤B;
步骤A17:获取步骤B的结果赋给步骤A2中的全局最大匹配数EA;
步骤A18:获取步骤A2中的当前主题-分类标签序列vecb;
步骤A19:执行步骤B;
步骤A20:获取步骤B的结果赋给步骤A2中的当前匹配数eb;
步骤A21:当步骤A2中的当前匹配数eb大于步骤A2中的全局最大匹配数EA时,即,eb>EA,则执行步骤A22;否则执行步骤A25;
步骤A22:生成随机数random,其中,数值范围在0到1之间;
步骤A23:当步骤A22中的随机数random小于e(eb-EA)/T时,即,random<e(eb-EA)/T,其中,eb为步骤A2中的当前匹配数,EA为步骤A2中的全局最大匹配数,则执行步骤A24;否则执行步骤A25;
步骤A24:令步骤A2中的全局最佳主题-分类标签序列FACTOR的值为步骤A2中的当前主题-分类标签序列vecb,令步骤A2中的全局最大匹配数EA的值为步骤A2中的当前匹配数eb,即,FACTOR=vecb,EA=eb;
步骤A25:降低步骤A1中的模拟退火算法温度T,使用步骤A1中的模拟退火算法冷却参数COOL,即,T=T×COOL,执行步骤A6;
步骤A26:返回步骤A2中的全局最佳主题-分类标签序列,即,FACTOR={FACTOR1, FACTOR2, …, FACTORTOPICNUM};返回步骤A2中的全局最大匹配数EA;
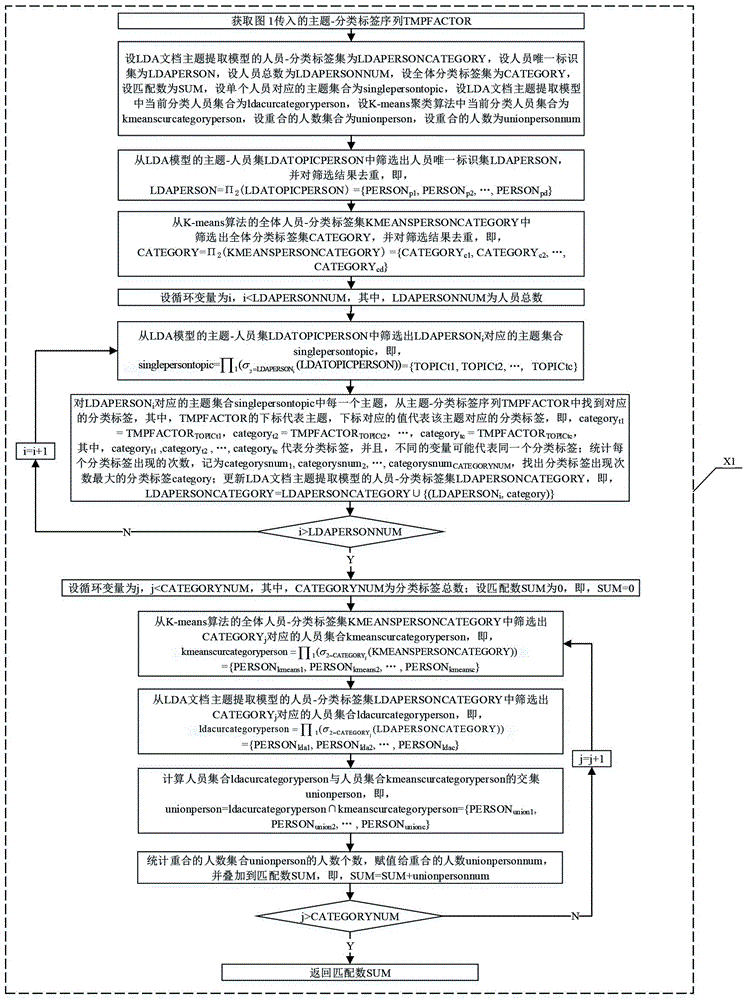
如附图2,成本函数处理流程步骤B从步骤B1到步骤B15:
步骤B1:获取步骤A中传入的主题-分类标签序列TMPFACTOR;
步骤B2:设LDA文档主题提取模型的人员-分类标签集为LDAPERSONCATEGORY,设人员唯一标识集为LDAPERSON,设人员总数为LDAPERSONNUM,设全体分类标签集为CATEGORY,设匹配数为SUM,设单个人员对应的主题集合为singlepersontopic,设LDA文档主题提取模型中当前分类人员集合为ldacurcategoryperson,设K-means聚类算法中当前分类人员集合为kmeanscurcategoryperson,设重合的人数集合为unionperson,设重合的人数为unionpersonnum;
步骤B3:从步骤A2中的LDA模型的主题-人员集LDATOPICPERSON中筛选出步骤B2中的人员唯一标识集LDAPERSON,并对筛选结果去重,即,LDAPERSON=Π2(LDATOPICPERSON) ={PERSONp1, PERSONp2, …, PERSONpd};
步骤B4:从步骤A2中的K-means算法的全体人员-分类标签集KMEANSPERSONCATEGORY中筛选出步骤B2中的全体分类标签集CATEGORY,并对筛选结果去重,即,CATEGORY=Π2(KMEANSPERSONCATEGORY)={CATEGORYc1, CATEGORYc2, …, CATEGORYcd};
步骤B5:设循环变量为i,i<LDAPERSONNUM,其中,LDAPERSONNUM为步骤B2中的人员总数;
步骤B6:从步骤A2中的LDA模型的主题-人员集LDATOPICPERSON中筛选出LDAPERSONi对应的主题集合singlepersontopic,即,={TOPICt1, TOPICt2, …, TOPICtc},其中,singlepersontopic来自步骤B2;
步骤B7:对LDAPERSONi对应的主题集合singlepersontopic中每一个主题,从步骤B1中的主题-分类标签序列TMPFACTOR中找到对应的分类标签,其中,TMPFACTOR的下标代表主题,下标对应的值代表该主题对应的分类标签,即,categoryt1 = TMPFACTORTOPICt1、categoryt2 = TMPFACTORTOPICt2、…、categorytc = TMPFACTORTOPICtc,其中,categoryt1 ,categoryt2 , …, categorytc 代表分类标签,并且,不同的变量可能代表同一个分类标签,singlepersontopic来自步骤B2;统计每个分类标签出现的次数,记为categorysnum1, categorysnum2, …, categorysnumCATEGORYNUM,找出分类标签出现次数最大的分类标签category;更新步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY,即,LDAPERSONCATEGORY=LDAPERSONCATEGORY∪{(LDAPERSONi, category)};
步骤B8:当循环变量i大于LDAPERSONNUM时,其中,LDAPERSONNUM为步骤B2中的人员总数,则执行步骤B9;否则,i值加1,即,i=i+1,执行步骤B6到步骤B7;
步骤B9:设循环变量为j,j<CATEGORYNUM,其中,CATEGORYNUM为步骤A1中的分类标签总数,设步骤B2中的匹配数SUM为0,即SUM=0;
步骤B10:从步骤A2中的K-means算法的全体人员-分类标签集KMEANSPERSONCATEGORY中筛选出CATEGORYj对应的人员集合kmeanscurcategoryperson,即, = {PERSONkmeans1, PERSONkmeans2, … , PERSONkmeansc},其中,kmeanscurcategoryperson来自步骤B2;
步骤B11:从步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY中筛选出CATEGORYj对应的人员集合ldacurcategoryperson,即,={PERSONlda1, PERSONlda2, … , PERSONldac},其中,ldacurcategoryperson来自步骤B2;
步骤B12:计算步骤B2中的人员集合ldacurcategoryperson与步骤B2中的人员集合kmeanscurcategoryperson的交集unionperson,即,unionperson=ldacurcategoryperson∩kmeanscurcategoryperson={PERSONunion1, PERSONunion2, … , PERSONunionc};
步骤B13:统计步骤B2中的重合的人数集合unionperson的人数个数,赋值给步骤B2中的重合的人数unionpersonnum,并叠加到步骤B2中的匹配数SUM,即,SUM=SUM+unionpersonnum;
步骤B14:当循环变量j大于步骤A1中的分类标签总数CATEGORYNUM时,则执行步骤B15;否则,j的值加1,即,j=j+1,执行步骤B10到步骤B13;
步骤B15:返回步骤B2中的匹配数SUM。
其中,聚类是将全体人员上网记录使用K-means聚类算法和LDA模型进行聚类分析,再将两个聚类结果相互验证,并使用模拟退火算法提高优化聚类结果的效率,以此提高聚类准确性。
其中,步骤A3到步骤A4提供模拟退火算法所需的初始数据;步骤A7到步骤A12是在模拟退火算法中更改当前解序列中的随机位置上的数值;步骤B5到步骤B8是通过步骤B1中的主题-分类标签序列TMPFACTOR与步骤A2中的LDA模型的主题-人员集LDATOPICPERSON进行关联,关联出步骤B2中的LDA文档主题提取模型的人员-分类标签集LDAPERSONCATEGORY;步骤B9到步骤B14是通过比对相同类别中,同时出现在K-means聚类结果中与LDA模型结果中的人员的个数,并叠加各个类别中此类人员的个数,并在流程的最后返回,并作为当前序列的成本;步骤A14到步骤A18是判断eb与EA的大小以及步骤A15中的随机数random与e(eb-EA)/T的大小,其中,eb为步骤A2中的当前匹配数,EA为步骤A2中的全局最大匹配数,当eb>EA并且random<e(eb-EA)/T时,则更新全局最佳主题-分类标签序列FACTOR的值以及全局最大匹配数EA的值,eb与EA的成本数值通过上述的步骤B得出;最终结果返回全局最大匹配数EA以及全局最佳主题-分类标签序列FACTOR。
其中,步骤A3中的K-means聚类算法迭代次数ITERKMEANS为300,分类标签总数CATEGORYNUM为3,步骤A4中的主题分布的狄利克雷参数ALPHA为0.1,关键词分布的狄利克雷参数ETA为0.01,LDA文档主题提取模型迭代次数ITERLDA为2000,步骤A1中的LDA文档主题提取模型的主题总数TOPICNUM为20。
为了更好的说明本方法的有效性,首先对5153个学生的上网浏览记录进行预处理,产生的数据格式为:学生记录编号、学生编号、关键词1、关键词2、…、 关键词n,记录总数为11167条。使用LDA文档主题提取模型,将学生的记录抽象成文档,设置初始主题数20个。将学生的上网浏览记录中的关键词通过第三方分类语料库进行量化,最后通过K-means算法聚出3个类别。采用人工的方式,分析LDA模型的主题的具体意义并分出类别,最终与K-means算法聚类聚出的结果进行比对,能够最终确定3149个人的具体分类,占总数61.11%;采用本实验的方法,能够最终确定3610个人的具体分类,占总数的70.06%,较之于人工分析,提高了8.95%。
本发明可与计算机系统结合,从而自动完成人员网络行为习惯聚类。
本发明创造性地利用人员上网记录中的网页属性、关键词、频数,结合K-means算法、LDA文档主题提取模型、退火算法,先对全体人员-标签-频率集、人员浏览记录-人员-关键词集进行K-means算法聚类和LDA文档主题提取模型生成,存储计算中间结果,之后使用退火算法将K-means和LDA进行双向验证计算全局最佳主题-分类标签序列,以此依据优化网络行为习惯聚类的结果,K-means和LDA双向验证提高了对人员-分类标签的敏感度,退火算法能够提高优化聚类结果的效率,进而提高聚类准确性。
- 还没有人留言评论。精彩留言会获得点赞!