一种基于选举标签传播的社区发现方法与流程
本发明涉及网络社区发现技术领域,特别是一种应用于社会网络的基于选举标签传播的社区发现方法。
背景技术:
诸如万维网、社会关系网络与生物网络等多种自然或社会复杂系统都可以用复杂网络来描述,复杂网络具有度幂律分布、高聚集系数与模块化社区等特征。本质上,网络的社区结构是指这样的节点集合:集合内的节点之间的链接稠密而集合内节点与集合外节点的链接稀疏。例如,具有复杂网络研究兴趣的学者之间联系比较紧密,他们构成一个社区,目前常在一起探讨问题,而与图形图像研究者沟通不多。社区结构能够刻画复杂系统功能部件间的拓扑关系,从复杂系统网络中挖掘出隐藏的潜在有价值的社区结构模式是一个很有意义但包含挑战的工作。
近年来,网络社区发现研究同时在物理学、社会学与计算机科学等不同领域中备受关注,涌现出的算法五花八门。绝大多数现有的社区发现算法都有着较高的计算复杂度,例如,GN算法的时间复杂度为O(m2n),模块度优化法的时间复杂度为O(mklogn)。过高的计算成本使得这些传统社区发现方法无法满足大规模复杂网络社区模式发现的需要。在此背景下,具有近似线性时间复杂度的标签传播算法(Label Propagation Algorithm,LPA)在大规模网络社区发现研究中倍受青睐。
Raghavan等人最早于2007年首先提出基于标签传播算法的社区发现方法RAK,该方法首先将每个节点初始化为一个独特的社区标签,然后通过迭代过程将每个节点的标签都更新为其大多数邻近节点的标签,最后密集连接的节点组会逐步从一个独特标签变成了一个具有共识的社区节点从而形成网络社区结构。RAK承袭了标签传播算法的高效计算特性,但由于其在初始标签、选择邻居节点和更新顺序等方面都采用随机策略,这使得发现的网络社区结构具有很大随机性,甚至可能产生所有节点属于同一社区的奇异解。针对此,社区发现研究者从多个方面对LPA算法进行了改进。
随机初始标签方面,Subelj等人提出一种新的标签传播算法DPA以层次方式将防御保护与进攻扩展两种社区形成策略组合起来,通过递归方式提取社区核心与调整社区核心来发现微小社区(whisker communities)。Leung等人通过Web网络社区发现的实验,发现节点标签跳 衰减策略与节点强度传播策略能有效提升LPA算法的性能。考虑到随机选取邻居节点标签的更新策略会降低LPA算法的鲁棒性,Zhang等人提出在出现多个最优的不同标签时应选择与当前待更新节点存在局部环的标签对当前节点更新。Lin等人提出一种基于社区核的标签传播算法CK-LPA,根据节点在网络中的重要性对其赋值并以此值对节点标签进行异步更新。为了避免产生众多碎小社区,赵卓翔等人提出了一种基于标签影响力的社区发现算法LIB,该算法首先选取一个小的顶点集作为种子集并赋予每个种子唯一的标签再以种子集作为起点进行传播,在对节点标签更新时需要对顶点邻居中相同标签所占比例、顶点度数和边的权重等多种因素进行综合考虑。为了避免产生怪兽社区(同一网络内所有节点都隶属同一个社区),Barber等人提出了一种模块化标签传播算法LPAm,通过给定一个目标函数,使得标签传播算法在迭代传播过程中受到约束,将社区发现的问题转化成为寻找目标函数最优解的问题,在邻居标签个数相同的基础上定义一个目标函数利用标签传播算法发现函数的局部化的最优值。注意到LPAm因容易陷入模块度局部极大值而损害结果社区的准确性,Liu等人提出了LPAm+算法,将LPAm算法与多步贪心聚合(MSG)相结合,利用MSG同时合并多个相似社区以避免陷入局部最大值,实现更加精准地检测网络社区。Subelj等人提出的BPA算法,先计算每个节点的平衡因子,再通过累加相同标签的平衡因子来选取最大的邻居集合,避免了奇异解的产生。Xie等人提出基于Speaker和Listener概念的社区发现算法SLPA,武志昊等提出基于平衡归属系数(Balanced belonging coefficient)社区发现算法。
上述算法虽然在一定程度上提升了结果社区的质量,但简单的传播规则无法适应更加复杂的社区网络。针对此,本文提出了一种基于选举标签传播的社区发现方法(Voting-based Label Propagation algorithm for Non-Overlapping communities detection,VLPNO)。
技术实现要素:
本发明的目的在于提供一种基于选举标签传播的社区发现方法,该方法能够提高社区发现的有效性和稳定性,有效发现隐藏于社交网络的社区结构模式。
为实现上述目的,本发明的技术方案是:一种基于选举标签传播的社区发现方法,包括以下步骤:
步骤S1:对于给定社会网络,计算每个网络节点的影响力;
步骤S2:对于各网络节点,利用候选者产生策略分别从其邻居节点中选出若干个节点作为候选者;
步骤S3:对于各候选者,根据影响力大小比较各候选者与其邻居节点,相互竞争产生胜出者;
步骤S4:对于各胜出者,根据票数高低比较各胜出者与其邻居胜出者,相互竞争产生新胜出者;
步骤S5:对支持率低于设定值的胜出者进行调整,从其邻居胜出者中选出新胜出者;
步骤S6:根据网络节点标签进行网络节点的社区划分并输出,即对于所有网络节点,通过将具有相同标签者归属到同一社区的方法构造网络的社区结构。
进一步的,所述步骤S1中,对于网络节点u,其影响力p(u)为:
其中
其中,deg(u)为节点u的度,N(u)是节点u的邻居节点集合。
进一步的,所述步骤S2中,利用候选者产生策略分别从各网络节点的邻居节点中选出若干个节点作为候选者,具体包括以下步骤:
步骤S21:对于网络节点u,对其邻居节点集合N(u)中的节点进行依影响力的降序排序,根据影响力从N(u)中选择K个影响力大于p(u)的节点作为候选者,若N(u)中影响力大于p(u)的节点不足K个,则以N(u)中所有影响力大于p(u)的节点作为候选者;
步骤S22:所有候选者构成候选者集合Vh,Vh中的每个候选者的票箱Bbox中的票数初始均为1,同时给Vh中的每个候选者都赋予唯一的社区标签。
进一步的,所述步骤S3中,对于候选者v,将v与N(v)中的节点进行影响力比较,若N(v)中存在影响力大于p(v)的节点,则从中选择具有最大影响力的节点作为胜出者,同时将v降为投票者并对所述胜出者进行投票,即进行将所述胜出者的票数加1与将v的社区标签更新为所述胜出者的社区标签的操作,否则,候选者v成为胜出者,并保持其社区标签不变,同时将v的票数加1。
进一步的,所述步骤S4中,重复如下竞争过程直至票数稳定或者达到最大迭代数:对于胜出者w,将w与其邻居胜出者进行票数比较,若在w的邻居胜出者中存在票数高于w的节点,则从中选择具有最高票数的节点作为新胜出者,同时将w降为投票者并将w的社区标签与支持w的投票者的社区标签都更新为所述新胜出者的社区标签,否则,w还是胜出者,并保持其社区标签不变。
进一步的,所述步骤S5中,对于胜出者y,若其支持率Support(y)低于设定值,则从其邻居胜出者中选择具有最高支持率的节点作为新胜出者,同时将y降为投票者并将y的标签与支持y的投票者的社区标签都更新为所述新胜出者的社区标签,其中 ly与lv分别为节点y与v的社区标签,δ(ly,lv)为克罗内克函数,若ly=lv则函数值为1,否则为0。
本发明的有益效果是提供了一种基于选举标签传播的社区发现方法,相较于传统的网络社区发现方法,本发明方法基于现实生活中的选举模式,通过投票和拉票的方式来选取网络中的核心节点,形成以核心节点为中心的社区,能显著提高社区发现的有效性与稳定性,有效发现隐藏于社交网络的社区结构模式,可广泛应用于微博网络、邮件网络、BBS论坛网络等各种社交平台,可以提升信息主动服务质量,增强网络文化安全等。
附图说明
图1是本发明实施例的实现流程图。
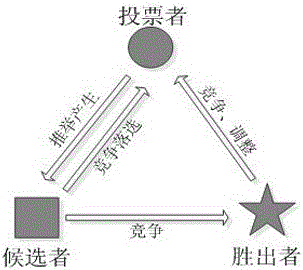
图2是本发明实施例中投票者、候选者与胜出者的关系示意图。
图3是本发明实施例中候选者产生策略的示意图。
图4是本发明实施例中投票者更新标签的示意图。
图5是本发明实施例中Karate网络的示意图。
图6是本发明实施例中人工网络Net_1的Q值收敛性分析的示意图。
图7是本发明实施例中人工网络Net_2的Q值收敛性分析的示意图。
图8是本发明实施例中人工网络Net_3的Q值收敛性分析的示意图。
具体实施方式
本发明提供一种基于选举标签传播的社区发现方法,如图1所示,包括以下步骤:
步骤S1:对于给定社会网络,计算每个网络节点的影响力。对于网络节点u,其影响力p(u)为:
其中
其中,deg(u)为节点u的度,N(u)是节点u的邻居节点集合。
步骤S2:对于各网络节点,利用候选者产生策略分别从其邻居节点中选出若干个节点作为候选者。具体包括以下步骤:
步骤S21:对于网络节点u,对其邻居节点集合N(u)中的节点进行依影响力的降序排序,根据影响力从N(u)中选择K个影响力大于p(u)的节点作为候选者,若N(u)中影响力大于p(u)的节点不足K个,则以N(u)中所有影响力大于p(u)的节点作为候选者;
步骤S22:所有候选者构成候选者集合Vh,Vh中的每个候选者的票箱Bbox中的票数初始均为1,同时给Vh中的每个候选者都赋予唯一的社区标签。
步骤S3:对于各候选者,根据影响力大小比较各候选者与其邻居节点,相互竞争产生胜出者。具体方法为:对于候选者v,将v与N(v)中的节点进行影响力比较,若N(v)中存在影响力大于p(v)的节点,则从中选择具有最大影响力的节点作为胜出者,同时将v降为投票者并对所述胜出者进行投票,即进行将所述胜出者的票数加1与将v的社区标签更新为所述胜出者的社区标签的操作,否则,候选者v成为胜出者,并保持其社区标签不变,同时将v的票数加1。
步骤S4:对于各胜出者,根据票数高低比较各胜出者与其邻居胜出者,相互竞争产生新胜出者。具体方法为:重复如下竞争过程直至票数稳定或者达到最大迭代数:对于胜出者w,将w与其邻居胜出者进行票数比较,若在w的邻居胜出者中存在票数高于w的节点,则从中选择具有最高票数的节点作为新胜出者,同时将w降为投票者并将w的社区标签与支持w的投票者的社区标签都更新为所述新胜出者的社区标签,否则,w还是胜出者,并保持其社区标签不变。
步骤S5:对支持率低于设定值的胜出者进行调整,从其邻居胜出者中选出新胜出者。具体方法为:对于胜出者y,若其支持率Support(y)低于设定值,则从其邻居胜出者中选择具有最高支持率的节点作为新胜出者,同时将y降为投票者并将y的标签与支持y的投票者的社区标签都更新为所述新胜出者的社区标签,其中ly与lv分别为节点y与v的社区标签,δ(ly,lv)为克罗内克函数,若ly=lv则函数值为1,否则为0。
步骤S6:根据网络节点标签进行网络节点的社区划分并输出,即对于所有网络节点,通过将具有相同标签者归属到同一社区的方法构造网络的社区结构。
下面结合附图及具体实施例对本发明作进一步说明。为了方便详细阐述本发明,首先对相关定义进行说明,然后分析现有半同步更新的标签传播算法的不足。
相关定义
定义1(网络社区结构)给定无向网络G=(V,E),网络节点集合为V,网络边集合为E。对于每个节点u,u∈V,令其邻居节点标签集合为N(u),节点u的度表示为deg(u),节点u的标签为lu。节点集合V所对应的网络社区结构为集合P={P1,P2,…,Pk},其中且k值可由用户指定或者算法自动确定,若 则称P为G的非重叠社区,反之若使得 成立,则称P为G的重叠社区。
定义2(节点影响力)给定网络G=(V,E),节点u∈V的影响力表现为u与其他节点之间的连接度,一般地,节点的度越高则其影响力越大,该节点的重要性越显著。节点u的影响力度量方法可形式化为如下公式:
其中Infl(u)表示节点u的影响力,deg(u)表示节点u的度,N(u)与N(v)分别表示节点u与节点v的邻居集合。
定义3(候选者)竞选开始阶段,先推举一些具有一定影响力的节点作为候选者,每个候选者都具有一个唯一的初始标签与一个用于统计自身所获票数的计数器BCounter,令所有被推选为候选者的节点集合为Vh。每个候选者初始分配一个票箱用于统计票数,不论候选者是晋升还是降级,票箱始终用于统计该节点获得的票数,并参与同类标签票数的累加,即两个票箱标签相同,票数进行累加运算。
定义4(胜出者)候选者之间通过竞争机制实现优胜劣汰,竞争失败的候选者降为投票者,而竞争成功的候选者升为胜出者,胜出者保持原有的标签,令胜出者集合Vs。
定义5(投票者)在整个竞选过程中影响力较低的节点不具有被选举权,这类节点称为投票者,投票者仅具有投票的权利,通过投票的方式选择与其连接候选者或者胜出者的标签作为自身的标签,令投票者集合为Vt。
网络节点在民主投票的标签决策过程中,其角色不是一成不变的,可以通过竞争、产生与调整等机制实现投票者、候选者与胜出者之间的角色转换,这种转换关系如图2所示。通过基于节点影响力的候选产生机制可实现投票者转变成候选者,而调整机制可将低支持率的胜出者转变为投票者,类似地,竞争机制可使得候选者有机会成为胜出者。
候选者产生策略
正如现实民主生活中的投票选举场景一样,在进行投票选举之前首先要按照某种方式产生候选对象(候选者),在VLPNO的初始阶段,每个网络节点都初始化为投票人,并计算每个网络节点的节点影响力,然后每个节点根据自身影响力从其邻居节点集合中推选K个比其影响力大的节点作为候选人,若邻居中比其影响力大的节点不足K个,则尽可能推选满足条件邻居的即可,K为常数,可根据网络的稠密度对其进行调节。如图3所示,节点u初始为投票者,推举3个影响力(箭头指向影响力大者)比其大的节点为候选人。所有候选者构成候选者集合Vh,Vh中的所有候选者的票箱Bbox初始为1,同时给Vh中的每个候选者都赋予唯一的标签。
值得指出的是,VLPNO采用的是基于节点影响力的候选人推举策略而不是随机策略,这主要基于这样的考虑:传统LPA算法研究表明,简单的随机初始化策略由于没有考虑节点特性及其邻居的关系往往会导致在后续的标签传播过程中出现大量零散孤立的小社区与“逆流”现象,即使得更有意义的大社区无法形成与影响力较小的节点在标签传播过程中会反过来影响一些影响力较大的节点。
竞选策略
每轮竞选分为两个过程,先候选者和胜出者之间竞争,再由投票者根据结果进行投票。在民主投票决策的过程中,候选者必须通过不同途径来展示自己的特点与优势,以能够在候选者之间的竞争获得胜出。在VLPNO中,候选者之间竞争主要包括选举票数比较和自身影响力比较两种方式。具体为,候选者在首次竞争时通过比较影响力来决定首轮竞选结果,即:影响力大者晋升为胜出者,而在后续的竞争过程中,候选者通过比较其从投票者处获得的票数来决定竞选结果,即:票数多者晋升为胜出者。胜出者保持自身标签不变,失败者则降级为投票者,更改自身标签,并将票投给胜者。候选者竞争过程主要涉及如下2个阶段:
阶段1:每个候选者从其相邻的候选者集合中选择一个影响力最大节点作为胜出者,并将自身标签更新为胜出者标签,即自己竞选失败降为投票者,并将自己的票投给该选举者。若没有影响力比其大的邻居候选人,则自身成为胜出者,并保持标签不变。对于给定候选者u,阶段1竞争的产生胜出者为如公式(2)的Vic(u)。
其中Infl(v)表示节点v的影响力,N(u)表示节点u的邻居。
阶段2:重复如下竞争直至票数稳定或者达到最大迭代数:胜出者从其相邻的胜出者集合中选择总票数最多的胜出者作为新的胜出者,并将自身标签更新为胜出者标签(即:自己竞选失败降为投票者,并将自己的票投给该胜出者),与此同时支持该失败者的投票者也需要将自己的标签更新为胜出者标签,若没有票数比其大的邻居选举者人,则自身成为选举者,并保持标签不变。类似阶段1,对于产生于阶段1的胜出者u,其在阶段2的迭代过程中通过公式(3)生成新的胜出者。
其中u.BCounter表示节点u的所获票数,每轮投票结束后,需要统计胜出者所获票数参与下一轮竞选。u.Bbox表示节点u票箱Bbox中的票数。
投票者主要是包括2部分节点,其一是由初始阶段没有被推举为候选者的节点,其二是在候选者竞争过程中竞争失败的候选者节点。投票者通过投票来变更自己的标签以表示对其选定胜出者的追随。在投票选择的过程中,每个投票者只有一次投票机会,且每次都是对其邻居节点集合中票数最多的胜出者进行投票,若其邻居节点中存在多个最大票数的胜出者,则等待下一轮投票。如图4所示,投票者u选择邻居中具有票数最多的团体标签来更新自己的标签,图中黄色标签的票数为(P11+P12),红色标签的票数为(P21+P22),蓝色标签的票数为(P31),若红色票数最大则将票数投给节点v3或者节点v4(投票者u只有1票,团体中只需一个票数增加即可)。若存在多个票数一样多,则等待下一轮投票。
后期调整策略
经过多轮竞选和投票后,竞选会趋于稳定,即没有投票行为。此时,还需要对一些支持率比较低的胜出者进行降级操作,如图3-4(颜色对应标签),竞选结束后,虽然胜出者(五角星)独占鳌头,但是其支持率很低,邻居中节点大多数都属于不同社区,对于这种小社区需要进行合并。对于支持率低于50%的胜出者强制进行降级操作。胜出者支持率Support(u)计算公式如下所示:
其中,表示与节点u同标签的节点数。lu与lv分别为节点u与v的标签,δ(lu,lv)为克罗内克函数,若lu=lv则该函数值为1,否则为0。
另外,在竞选过程中,竞选失败的胜出者将自身标签更新为胜者的标签,而之前跟随该失败者的投票者也需要更新自己的标签,即将标签更新为失败者的新标签。
性能评测
为了定量地分析VLPNO算法的性能,我们将VLPNO算法与3个常用的标签传播算法(LPA、SLPA、BMLPA)在3个基准真实网络数据集和3个LFR网络生成程序数据集上进行实验比较与分析。实验环境为:CPU为CoreTM2i5-3230M,内存4G;OS为Win7。3个真实网络分别是:Karate网络,该网络是美国一所大学中的空手道俱乐部成员间的相互社会关系,共有34个节点,78条边;Dolphins网络,共有62个节点、159条边;Football网络,该网络是Newman等人对美国大学生橄榄球联赛的2000个赛季的比赛情况进行分析整理而建立的网络,它包含115个节点及616条边。3个人工网络主要通过设置不同的参数由 LFR网络程序生成,网络参数及其意义如表1所示,根据表1中的参数分别生成三种不同类型的人工网络,小型社区网络Net_1、中型社区网络Net_2和大型社区网络Net_3,其具体参数如表2。
表1人工生成网络参数列表
评价标准
本实验采用模块度Q和标准化互信息NMI(Normalized Mutual information)两个指标对ISLPA算法的有效性与鲁棒性进行评价。模块度Q是当前使用最为广泛的社区质量指标,其值等于网络中社区内部边所占的比例减去另一个随机网络中社区内部边所占的比例,具体可形式化如下:
其中,m表示网络中的边数;当节点i与节点j相连时,Aij等于1,反之为0;ki表示节点i的度数;gi表示节点i所属社区;δ(gi,gj)为克罗内克函数,当gi=gj时,δ(gi,gj)=1,否则,δ(gi,gj)=0。网络社区模块化程度与Q是正相关的,即当社区结构明显时,Q接近1;当社区结构不明显时,Q接近0。
NMI是一种基于信息论理论的社区质量评价指标,它通过计算已知社区结构和由算法得到的社区结构之间的相似度来实现网络社区结构质量的测度,其值越大说明算法结果社区与真实社区结构相一致的程度越高,具体公式如下:
其中Pres为算法划分集合,Ptrue为网络真实划分集合,m和n为对应划分社区个数,Vm为社区m的节点集合。
有效性分析
为了验证算法的有效性,选取了四种算法在网络数据集上运行50次所得的Q值与NMI值的平均值,进行对比分析。通过表3可以看出真实网络的划分,本文提出的VLPNO算法相对与其他对比算法有更高的模块度。尤其在跆拳道和海豚网中,划分效果尤为明显。究其原因,主要是因为这两类网络相对于足球俱乐部网络结构更加明显,存在影响力较大的核心节点,周边节点均以核心节点为中心形成社区。而足球网,对应的社区一般都是影响力均衡的足球队,所以在结构不明显的网络中VLPNO算法优势不是很明显。
表3真实网络Q值对比
由表4可以观测,VLPNO在跆拳道网络的划分接近于1.0,等效于真实网络划分,远远大于其他三类算法。结合图6,可以看出,该Karate俱乐部主要以主管和校长两个为核心的网络结构。在网络调查中发现,形成两个团体的原因是俱乐部的主管和校长在是否抬高俱乐部收费的问题上产生了争执,所以网络分裂成以这两位为核心的团体。这种网络的形成类似于生活中的选举,通过拉票和投票,形成以竞选者为核心的团体。因此,引入选举模式的传播算法,能够有效地发现生活中以影响力大者为核心的社区网络。
表3-4真实网络NMI值对比
鲁棒性分析
为了评价VLPNO算法的鲁棒性,我们通过调节混合参数μ(混合参数μ越小社区结构越明显)来构造社区模块度各异的不同人工网络。图6、7与8分别为4种LPA算法在不同网络中的划分结果(NMI值)。由图6、7与8可知,在3个人工网络中,所有算法均随着混乱 系数μ的增加而降低,但是VLPNO的下降幅度要比其他对比算法小,说明算法具有较好的稳定性。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!