一种基于深度学习的移动机器人快速物体识别方法与流程
本发明涉及一种移动机器人快速物体识别方法,尤其涉及一种基于深度学习的移动机器人快速物体识别方法。
背景技术:
目前市场上存在物体检测识别系统一般首先通过滑动窗口或者物体区域推荐技术获取一个物体候选区域集合,然后采用启发式的特征选取来对这个集合中的候选区域进行识别,识别是指通过分类器给候选区域指定最贴近的物体类别。
根据分类器使用特征的不同,目前检测系统大概可分为两个类型:基于深度学习的方式;基于启发式特征的方式。基于启发式特征的方案一般通过经验人为设计特征来表示候选区域,而基于深度学习的方式,通过多层神经网络对物体特征进行提取,从而达到对物体局部特征的多次组合,从而达到对物体进行分类的效果。深度学习特征可以根据数据分布进行自适应学习,所以近些年来深度学习技术相比启发式特征技术在检测准确率上有了一定优势。然而启发式学习技术因为其快速简单的固有特性,依然在一些简单应用中被使用,例如人脸检测。
然而目前这两项技术依然存在缺点,不能应用到实际场景中,主要体现为:启发式特征方法虽然快速,但特征表达能力有限。在现实场景中,由于被识别物体通常存在于整幅场景之中,而且物体大小尺寸随机变化较大,同时由于多个物体相互之间存在遮挡,所以物体检测准确率比较低;另外一方面深度学习技术虽然可以很好的表示物体区域,但是需要对每个物体候选区域进行分类,一般情况下物体候选区域集合比较庞大,所以分类需要很长的时间;并且需要精心设计后处理技术对已分类的物体区域进行筛选,例如非局部极大值抑制等,另外这些技术都没有利用图像的全局信息,在复杂场景物体检测识别中依然存在缺陷。
技术实现要素:
本发明的目的在于提供一种基于深度学习的移动机器人快速物体识别方法,
针对物体检测识别系统中由于检测与识别部件分开而导致的运行效率下降,同步完成物体检测预测与识别其类别的功能,为了不损失检测的准确率,引入表达能力更强的残差式的多层深度网络提高集成式方案的准确性,解决现有技术存在的缺憾。
本发明采用如下技术方案实现:
1、一种基于深度学习移动机器人快速物体识别方法,其特征在于,该识别系统包括如下步骤:
1)移动图片获取:用以获得机器人在移动过程中通过摄像头感知的视觉数据,深度图片因为其包含深度信息,可用来还原场景物理体系来建立场景中的约束条件。
2)图片数据预处理:本步骤中用到两个软件单元:色彩图片预处理单元和深度图片预处理单元,色彩图片预处理单元用以对输入的色彩图片进行分块处理,将整幅图片分割为一块块的网格,如果其中的网格块中出现物体的中心则将其网格标识为此物体的一部分,而且对应于此网格,神经网络将预测多个物体包围框,并且对于此网格归属的物体类别进行一定的置信度生成,为物体识别提供相应数据基础;
深度图片预处理单元用以产生室内环境下的约束条件,通过对距离数据的处理和对重力向量进行估计,从而建立相应的物理环境体系,根据此环境体系建立相应的环境约束,例如获得物体与平面之间的参照量,在检测与识别模块中使用此环境约束来消除错误解;
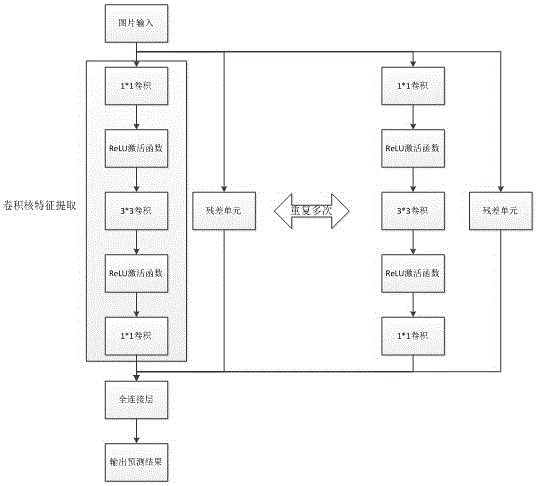
3)图片特征提取:通过构建多层残差神经网络来完成,主要包含两个软件单元:卷积核特征提取单元和残差单元构造单元,随后将卷积核特征提取单元和残差单元作为神经网络的组成部分进行顺序叠加,从而形成深度特征提取神经网络,完成图像特征的多层分布式重现;
a)卷积核特征提取:给定一幅图像,系统通过重复使用多种卷积核函数、块归一化单元和非线性矫正单元的方式来提取适合物体检测识别的图像特征,其中卷积核函数是一个小的数据窗口,例如3*3的数据窗口,卷积操作即为数据窗口在全局图片区域上滑动,并且按数据窗口中的每一位与响应图片位求乘积并按数据窗口区域对结果进行求和,相应的卷积核函数和网络参数将通过训练来获得,非线性单元通过增加非线性来增强特征的表达能力。图片局部特征将作为神经网络的输入数据来完成预测包围框和物体类别的生成处理。
b)残差单元构造单元:由于神经网络的深度结构在输出收敛的同时也会出现退化的现象:即随着网络深度的增加,虽然精度逐渐提高,当到达一个极值的时候突然迅速下降。而这一现象并非由于过拟合引起,通过继续增加网络深度也不能对此作出缓解。相比于传统方案利用前一特征提取单元(卷积核、非线性单元的特定组合)的输出作为下一层特征单元的顺序模型,)残差神经单元将前一特征单元的输出和输入相加作为下一层特征提取单元的输出;
4)图片预测输出:
任意给定一张输入图片,算法输出的结果包括图片中潜在物体的包围框的大小、坐标、物体的类别和置信度。由于一副图片中可能包含多个物体,为了降低模型的不确定性,想比于从整张图片预测单个物体包围框,本发明试图先将图片划分为p*p的方格,预测每个方格中是否存在物体,如果存在预测物体的坐标、大小、类别和置信度(6维度)。因为同一个物体可能出现在多个方格中,多个方格的协作预测增加了物体预测的鲁棒性和准确率。而且对应于每个网格,神经网络将预测k个可能的物体包围框,因为一个方格中可能同时存在多个物体的区域,采用线性的分类器预测(p*p*k*6)个输出,最后采用非极大抑制删除冗余的并且置信度小的物体窗口。
5)环境约束优化:环境约束优化模块用以根据深度数据产生相应的环境约束条件,由于深度数据可还原出空间的三维点云结构,因此可以通过点云数据来计算出环境中的重力向量,从而根据重力向量来自底向上对平面和物体进行描述形成约束条件;
6)图片识别输出:在经过环境约束优化之后,系统将把经过神经网络检测识别后并通过语义环境约束条件优化后的结果输出至机器人接受模块进行处理,图片识别输出模块同时输出了对于物体检测和识别的结果,输出数据包含物体类别、包围检测框的中心点x轴y轴坐标、包围检测框宽度和高度等数据。此数据用以机器人辅助环境理解和导航构图使用。在具有较高准确度的前提下,整个系统可达到随着机器人的移动实时处理(>24FPS),从而保证了机器人相应指令的及时性和准确性。
2、根据权利要求1所述的基于深度学习的移动机器人快速物体识别方法,其特征在于,所述摄像头为深度摄像头,深度摄像头在获得普通色彩图片的同时还可以获得以距离信息为主的深度图片。
本发明的有益技术效果是:
1)通过检测和识别结果的统一整合,克服传统物体识别系统需要使用物体识别加检测的复杂性和不稳定性;2)通过多层残差网络设计和环境重力约束条件的生成,克服集成式物体识别系统准确度差的缺点;3)检测识别任务的整合还可保证系统的处理效率,提高机器人移动过程中的感知能力。
附图说明
图1是本发明识别方法的整体流程图。
图2是多层残差神经网络图。
图3是残差神经单元图。
具体实施方式
通过下面对实施例的描述,将更加有助于公众理解本发明,但不能也不应当将申请人所给出的具体的实施例视为对本发明技术方案的限制,任何对部件或技术特征的定义进行改变和/或对整体结构作形式的而非实质的变换都应视为本发明的技术方案所限定的保护范围。
步骤1、移动图片获取:移动图片获取模块获得机器人在移动过程中通过摄像头感知的视觉数据,视觉数据包括深度图片和普通RGB彩色图片两部分。
步骤2、图片数据预处理:图片数据预处理模块对图片获取模块中取得的图片进行预处理,首先生成相应的色彩图片和深度图片,后色彩图片预处理单元用以对输入的色彩图片进行分块,将整幅图片分割为一块块网格,使用网格的方式来定位物体。深度图片预处理单元对重力向量进行迭代计算,首先计算图片平面法向量。随之将水平与垂直法向量进行分类优化迭代,最终获得重力向量的准确近似,建立自底向上的物体环境语义约束。
步骤3、图片特征提取:图片特征提取模块使用多层残差神经网络结合卷积核的形式来将特征一层层凸显出来,如下图所示:随着神经网络的深入,可发现物体边缘的特征越来越明显,呈现亮色。神经网络将边缘特征提取再进行特征结合形成更高层的特征呈现,从而完成预测。
步骤4、图片预测输出:图片预测输出模块对输入图片中物体进行包围框大小、坐标、物体的类别和置信度的预测。本发明产生多个预测框,再使用非极大抑制删除冗余的并且置信度小的物体窗口产生多个预测结果。
步骤5、环境约束优化:环境约束优化模块利用重力向量方向,对平面和物体进行高度描述形成约束条件。例如人高于座椅平面,物体高于桌子平面等,对于预测网络输出的结果可根据约束进行优化,从而去除一些环境约束下的错误解,人体的包围框也出现了在预测结果中,经过约束条件将其判断为正确。
步骤6、图片识别输出:图片识别输出模块输出识别结果包括类别、包围框的中心点x轴y轴坐标、包围框宽度和高度等数据,用以机器人辅助环境理解和导航构图使用。在具有较高准确度的前提下,整个系统可达到随着机器人的移动实时处理(>24FPS),从而保证了机器人相应指令的及时性和准确性。
当然,本发明还可以有其他多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员可以根据本发明做出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!