云计算环境下基于攻击预测的虚拟机监控资源分配方法与流程
本发明涉及一种云计算环境下虚拟机监控方法,是一种基于博弈论对多种攻击行为进行监控的优化策略方法,属于计算机安全技术领域。
背景技术:
云计算以其经济性,便利性和高度的可扩展性成为当前信息技术领域的研究热点。在云计算环境下,IT领域按需服务的理念得到了真正的体现,就像从古老的单台发电机模式转向了电厂集中供电的模式。云计算意味着计算能力可以作为一种商品进行流通,就像煤气、水电一样,取用方便,费用低廉。最大的不同在于,它是通过网络提供服务的。云计算提供了多种计算资源给租户,如主机服务,存储服务,应用服务等等。租户可以访问和管理云服务,如同管理自己本地的计算资源一样,这种开放式的远程访问模式为云平台的使用者带来了极大的便利。在云计算的IaaS(基础设施即服务)层中,通过虚拟化技术提供虚拟硬件基础设施,如虚拟机,用户可以在虚拟机上可以获得和在物理机上相同的操作体验。
随着云计算的不断普及,云安全已经成为制约其发展的主要因素之一。根据国际数据公司IDC的数据显示,2015年全球云计算基础设施支出增长26.4%,达334亿美元,约占IT总支出的三分之一。未来几年,云计算基础设施支出预计将以年均15.6%的速度增长,到2019年将会达546亿美元,这将占据IT基础设施支出近一半(46.5%)的市场。由于云计算采用虚拟化技术,使得用户业务系统不再明确地运行在物理的服务器上,而是运行在动态的虚拟机之上。这就使得多个数据源之间没有物理界限,一旦被侵入将难以设置隔离区。由此带来的结果是,一台服务器感染病毒,将可能影响其它所有的设备,而云计算服务器一旦感染病毒,将影响大量企业甚至公共系统。2015年,毒液漏洞爆发,亚马逊云业务为修复漏洞,对主机进行了重启,造成诸多企业业务中断。层出不穷的虚拟机安全事件已经为我们敲响了虚拟化安全的警钟。若虚拟机遭受攻击,则使用虚拟机的用户或者与之通信的虚拟机的安全将会受到严重威胁,所以加强虚拟机的安全防护已经成云提供商和租户之间的共同问题。
针对上述安全隐患,云服务商必须对虚拟机监控,获取虚拟机的安全态势,以做出相应的防御策略。但不同的监控方法将会消耗不同数量的资源,因此资源损耗和安全态势信息获取是一个需要权衡的问题。虽然用最大数量的资源监控虚拟机是最安全的,但是这样将会导致过多的资源损耗,从而使得云提供商的整体收益减少。现有的研究主要集中在针对特定类型的攻击者行为,制定相应的最优防御策略,然而在实际网络环境中,云提供商通常需要同时防御多种类型的攻击者行为。因此,有必要提出一种虚拟机监控方法,当攻击虚拟机的攻击者行为不确定时,为云提供商尽可能多的捕获攻击行为,以确保虚拟机安全。
博弈论是一种用来分析参与者如何在交互过程中做出决策的工具,在经济学,计算机科学等学科都有广泛的应用,尤其是在安全领域。
技术实现要素:
本发明的目的在于提供一种云环境下的虚拟机监控方法,从资源管理的角度出发,基于博弈论方法分析,高效的利用有限资源,在攻击者行为不确定的情况下,确定监控的虚拟机对象,以获取最优的监控策略,使得云提供商可以尽可能多地捕获攻击行为,使防御者的利益最大化。
为了实现上述目的,本发明采用如下技术方案:一种云环境下的虚拟机监控方法,
其特征在于:是以云环境中的虚拟机作为监控对象,即攻击者的攻击目标;云提供商作为防御者,监控虚拟机,其具体步骤如下:
步骤一、获取攻防双方对云环境中虚拟机采取不同行动的情况下各自获得的收益数据;
步骤二、计算攻击者和防御者的效用函数;
步骤三、建立复合攻击者行为模型 ,其中表示同时满足多个目标,即同时最优的一组最优监控概率分布;多目标函数进行求解,以使多个目标,即所述的对多种攻击者行为的防御概率同时达到最优,以取得最好的监控效果;
所述的步骤一中的收益数据包括以下四种情况:
1)当攻击者对第i台虚拟机发动攻击,且防御者对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
2)当攻击者对第i台虚拟机发动攻击,而防御者并未对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
3)当攻击者并未对第i台虚拟机发动攻击,而防御者对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为;
4)当攻击者并未对第i台虚拟机发动攻击,且防御者并未对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为0。
其中表示监控成功的概率,即攻击被成功检测到的概率;若防御者检测到攻击者在第i台虚拟机上发动攻击,则防御者会获得的监控奖励,攻击者会收到的攻击惩罚,若攻击未被检出则防御者会收到的监控惩罚,攻击者会获得的攻击奖励;表示攻击成本,表示监控成本,攻击成本与监控成本主要指攻击目标和监控目标所消耗的不同数量的资源,包括存储、计算、带宽、电量、网络占用时间等资源。
所述的步骤二中的防御者的效用函数如公式一所示:
公式一、
所述的步骤二中的攻击者的效用函数如公式二所示:
公式二、
其中T表示云环境下所有虚拟机的集合;表示防御者的效用函数;表示攻击者的效用函数;p表示攻击者的策略,即对T中的虚拟机进行攻击的概率分布,表示对第i个虚拟机进行攻击的概率,n为虚拟机的个数。q表示监控者的策略,即对T中的虚拟机进行监控的概率分布,表示对第i个虚拟机进行监控的概率。公式一和公式二中,表示监控成功的概率,即攻击被成功检测到的概率;表示防御者检测到攻击者在第i台虚拟机上发动攻击,则防御者会获得的监控奖励,表示攻击者会收到的攻击惩罚,表示攻击未被检出则防御者会收到的监控惩罚,表示攻击者会获得的攻击奖励;表示攻击成本,表示监控成本,攻击成本与监控成本主要指攻击目标和监控目标所消耗的不同数量的资源,包括存储、计算、带宽、电量、网络占用时间等资源。
所述的步骤三中复合攻击者行为模型由以下五种单独的攻击者行为模型按照不同的权重值复合而成:
1)完全理性攻击者行为模型:对公式一和公式二进行求解,分别得到攻防双方的最优策略记为公式三:
公式三、
公式三中,表示求解当攻击者的效用函数取最大值时,根据公式二求解出攻击者的策略p的值,表示求解当防御者的效用函数取最大值时,根据公式一求解出攻击者的策略p的值,迭代计算公式三,直到达到纳什均衡。公式三为一组纳什均衡解:记作,表示以完全理性攻击者行为对虚拟机进行攻击时,第i台虚拟机受到攻击的概率;表示防御完全理性攻击者行为对虚拟机进行攻击时,第i台虚拟机受到监控的概率;
将公式三的计算结果代入公式一得出攻击者为完全理性攻击者行为时,最终防御者的效用函数值,记作。
2)QR攻击者行为模型:在QR模型中,攻击者为有限理性行为,其攻击概率预测公式为公式四:
公式四、
其中为攻击者理性程度,是用来控制攻击者行为理性程度的一个正参数,也可以用来指代攻击对手行为中出现的错误级别或者数量。当时,对手行为中存在许多的错误,此时对手处于完全不理性的状态;当时,对手行为中错误较少,此时对手处于相对理想的状态。
其中是攻击者关于监控策略变化的效用函数,如公式五所示:
公式五、
将公式五代入到公式四中得公式六:
公式六、。
将公式六代入公式一,得公式七:
公式七、
根据公式七,可得出在攻击行为为QR模型时的攻防双方的最优策略,记作公式八:
公式八、
迭代计算公式八,直到达到纳什均衡。公式八为一组纳什均衡解:记作,表示以QR攻击者行为对虚拟机进行攻击时,第i台虚拟机受到攻击的概率;表示防御QR攻击者行为对虚拟机进行攻击时,第i台虚拟机受到监控的概率;
将公式八的计算结果代入公式一得出攻击者为QR攻击者行为时,最终防御者的效用函数值,记作。
3)SUQR3攻击者行为模型:在SUQR3模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚和监控概率这三个决策指标的加权求和函数如公式九所示:
公式九、
SUQR3预测的虚拟机i上的攻击概率如公式十所示:
公式十、
其中代表攻击者的偏好程度,即权重值;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率。
将公式十代入公式一得公式十一:
公式十一、
根据公式十一,可得出在攻击行为为SUQR3模型时的攻防双方的最优策略,记作公式十二:
公式十二、
迭代计算公式十二,直到达到纳什均衡。公式十二为一组纳什均衡解:记作,表示以SUQR3攻击者行为对虚拟机进行攻击时,第i台虚拟机受到攻击的概率;表示防御SUQR3攻击者行为对虚拟机进行攻击时,第i台虚拟机受到监控的概率;
将公式十二的计算结果代入公式一得出攻击者为SUQR3攻击者行为时,最终防御者的效用函数值,记作。
4)SUQR4攻击者行为模型:在SUQR4模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚,监控成功概率和监控概率这四个决策指标的加权求和函数如公式十三所示:
公式十三、
SUQR4预测的虚拟机i上的攻击概率如公式十四所示:
公式十四、
其中代表攻击者的偏好程度,即权重值;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率,表示对虚拟机i监控成功概率。
将公式十四代入公式一得公式十五:
公式十五、
根据公式十五,可得出在攻击行为为SUQR4模型时的攻防双方的最优策略,记作公式十六:
公式十六、
迭代计算公式十六,直到达到纳什均衡。公式十六为一组纳什均衡解:记作,表示以SUQR4攻击者行为对虚拟机进行攻击时,第i台虚拟机受到攻击的概率;表示防御SUQR4攻击者行为对虚拟机进行攻击时,第i台虚拟机受到监控的概率;
将公式十六的计算结果代入公式一得出攻击者为SUQR4攻击者行为时,最终防御者的效用函数值,记作。
5)PT攻击者行为模型:PT攻击者模型提供了攻击者如何在多个备选目标中,选择具有最大的前景的目标进行攻击的过程。根据PT攻击者模型预测的虚拟机i上的攻击概率如公式十七所示:
公式十七、
其中攻击虚拟机i的前景表示为公式十八:
公式十八、
其中表示权重,。
其中为固定参数。
将公式十八代入公式一得公式十九:
公式十九、
根据公式十九,可得出在攻击行为为PT模型时的攻防双方的最优策略,记作公式二十:
公式二十、
迭代计算公式二十,直到达到纳什均衡。公式二十为一组纳什均衡解:记作,表示以PT攻击者行为对虚拟机进行攻击时,第i台虚拟机受到攻击的概率;表示防御PT攻击者行为对虚拟机进行攻击时,第i台虚拟机受到监控的概率;
将公式十二的计算结果代入公式一得出攻击者为PT攻击者行为时,最终防御者的效用函数值,记作。
本发明的积极效果是基于博弈论的云环境下虚拟机监控方法,从资源管理的角度出发,利用博弈论方法进行分析,提高了资源的效用,与以往只考虑单独一种攻击行为的分析方法相比,是在攻击者行为不确定的情况下,决定监控的虚拟机对象,以获取最优的监控策略,使得云提供商,即防御者利益最大化。
附图说明
图1为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按完全理性攻击者行为对8台虚拟机进行监控时防御者收益对照关系图。
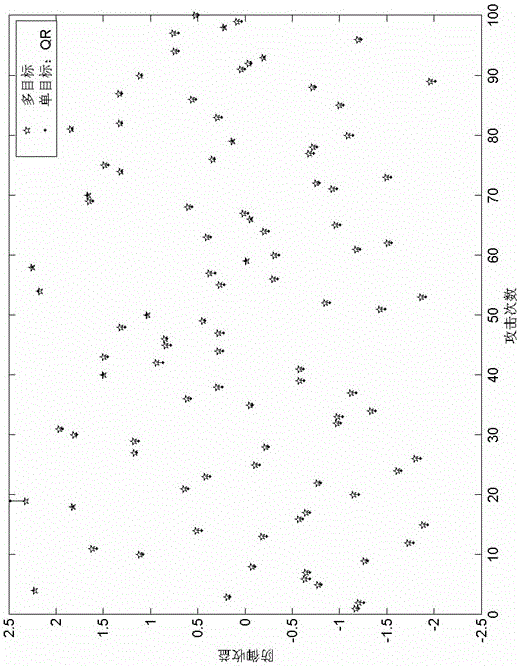
图2为本发明随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按QR攻击者行为对8台虚拟机进行监控时防御者收益对照关系图。
图3为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按SUQR3攻击者行为对8台虚拟机进行监控时防御者收益对照关系图。
图4为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按SUQR4攻击者行为对8台虚拟机进行监控时防御者收益对照关系图。
图5为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按PT攻击者行为对8台虚拟机进行监控时防御者收益对照关系图。
图6为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按完全理性攻击者行为对20台虚拟机进行监控时防御者收益对照关系图。
图7为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按QR攻击者行为对20台虚拟机进行监控时防御者收益对照关系图。
图8为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按SUQR3攻击者行为对20台虚拟机进行监控时防御者收益对照关系图。
图9为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按SUQR4攻击者行为对20台虚拟机进行监控时防御者收益对照关系图。
图10为随机发动100次攻击的情况下,本发明所述针对多目标攻击行为的监控方法与按PT攻击者行为对20台虚拟机进行监控时防御者收益对照关系图。
具体实施方式
下面结合附图和实施例对本发明做进一步的描述:
实施例1
1A、获取攻防双方对云环境中虚拟机采取不同行动的情况下各自获得的收益数据;
所述收益数据包括以下四种情况:
1.当攻击者对第i台虚拟机发动攻击,且防御者对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
2.当攻击者对第i台虚拟机发动攻击,而防御者并未对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
3.当攻击者并未对第i台虚拟机发动攻击,而防御者对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为。
4.当攻击者并未对第i台虚拟机发动攻击,且防御者并未对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为0。
其中表示监控成功的概率,即攻击被成功检测到的概率,;在本实施例中一共选取8台虚拟机,即,若防御者检测到攻击者在第i台虚拟机上发动攻击,则防御者会获得的监控奖励,在本实施例中,攻击者会收到的攻击惩罚,在本实施例中;若攻击未被检出则防御者会收到的监控惩罚,在本实施例中,攻击者会获得的攻击奖励,在本实施例中;表示攻击成本,在本实施例中,表示监控成本,在本实施例中,攻击成本和监控成本主要指攻击目标和监控目标所消耗的不同数量的资源,包括存储、计算、带宽、电量、网络占用时间等资源。
1B、计算攻击者和防御者的效用函数;
本发明步骤二所述防御者的效用函数如等式(1-1)所示:
(1-1)
攻击者的效用函数如等式(1-2)所示:
(1-2)
其中T表示云环境下所有虚拟机的集合,在本实施例中虚拟机个数为8;p表示攻击者的策略,即对T中的虚拟机进行攻击的概率分布,在本实施例中随机生成100组不同概率分布p,表示攻击者的随机攻击行为。q表示监控者的策略,即对T中的虚拟机进行监控的概率分布。
、建立复合攻击者行为模型:
所述复合攻击者行为模型以下五种单独的攻击者行为模型按照不同的权重值复合而成:
1.攻击者为完全理性攻击者行为模型时:对等式(1-1)和等式(1-2)进行求解,分别得到攻防双方的最优策略记为表达式(1-3):
(1-3)
式(1-3)为一组纳什均衡解。将式(1-3)代入等式(1)得出攻击者为完全理性攻击者行为时,防御者的效用函数,记作。
2.攻击者为QR攻击者行为模型时:在QR模型中,攻击者为有限理性行为,其攻击概率为等式(1-4)所示:
(1-4)
其中为攻击者理性程度,是用来控制攻击者行为理性程度的一个正参数,也可以用来指代攻击对手行为中出现的错误级别或者数量。当时,对手行为中存在许多的错误,此时对手处于完全不理性的状态;当时,对手行为中错误较少,此时对手处于相对理想的状态。在本实施例中,
其中是攻击者关于监控策略变化的效用函数,如等式(1-5)所示:
(1-5)
将等式(1-5)代入到等式(1-4)中得式(1-6):
(1-6)
将等式(1-6)代入等式(1-1),得等式(1-7):
(1-7)
其中n=8。
根据等式(1-7),可得出在攻击行为为QR模型时的攻防双方的最优策略,记作等式(1-8),是一组纳什均衡解。
(1-8)
将等式(1-8)代入等式(1-1)得出攻击者为QR攻击者行为时,防御者的效用函数,记作。
3.攻击者为SUQR3攻击者行为模型时:在SUQR3模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚和监控概率这三个决策指标的加权求和函数如等式(1-9)所示:
(1-9)
SUQR3预测的虚拟机i上的攻击概率如等式(1-10)所示:
(1-10)
其中代表攻击者的偏好程度,即权重值,在本实施例中;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率。
将等式(1-10)代入等式(1-1)得等式(1-11):
(1-11)
根据等式(1-11),可得出在攻击行为为SUQR3模型时的攻防双方的最优策略,记作等式(1-12),是一组纳什均衡解。
(1-12)
将等式(1-12)代入等式(1-1)得出攻击者为SUQR3攻击者行为时,防御者的效用函数,记作。
4.攻击者为SUQR4攻击者行为模型时:在SUQR4模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚,监控成功概率和监控概率这四个决策指标的加权求和函数如等式(1-13)所示:
(1-13)
SUQR4预测的虚拟机i上的攻击概率如等式(1-14)所示:
(1-14)
其中代表攻击者的偏好程度,即权重值,在本实施例中;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率,表示对虚拟机i监控成功概率,在本实施例中。
将等式(1-14)代入等式(1-1)得等式(1-15):
(1-15)
根据等式(1-15),可得出在攻击行为为SUQR4模型时的攻防双方的最优策略,记作等式(1-16),是一组纳什均衡解。
(1-16)
将等式(1-16)代入等式(1-1)得出攻击者为SUQR4攻击者行为时,防御者的效用函数,记作。
5.攻击者为PT攻击者行为模型时:PT攻击者模型提供了攻击者如何在多个备选目标中,选择具有最大的前景的目标进行攻击的过程。根据PT攻击者模型预测的虚拟机i上的攻击概率如等式(1-17)所示:
(1-17)
其中攻击虚拟机i的前景表示为等式(1-18):
(1-18)
其中表示权重,。
其中为固定参数,在本实施例中。
将等式(1-18)代入等式(1-1)得等式(1-19):
(1-19)
根据等式(1-19),可得出在攻击行为为PT模型时的攻防双方的最优策略,记作等式(20),是一组纳什均衡解。
(1-20)
将等式(1-20)代入等式(1-1)得出攻击者为PT攻击者行为时,防御者的效用函数,记作。
将以上所求得代入以下等式(1-21),
(1-21)
其中表示同时满足多个目标,即同时最优的一组最优监控概率分布。本实施例中采用fgoalattain 方法对多目标函数进行求解,以使多个目标,即本发明中所述的对多种攻击者行为的防御概率同时达到最优。由图1可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,其防御收益100%优于假设攻击者行为完全理性的监控方法;由图2可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,其防御收益90%优于假设攻击者行为QR的监控方法;由图3可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,其防御收益95%优于假设攻击者行为SUQR3的监控方法;由图4可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,其防御收益100%优于假设攻击者行为SUQR4的监控方法;由图5可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,其防御收益89%优于假设攻击者行为PT的监控方法,可见,在现实网络环境中,攻击者为随机行为,并不完全符合任何单目标行为攻击规律,以本发明所述监控方法可以取得比任何单目标监控方法收益都高的最好的监控效果。
实施例2
2A、获取攻防双方对云环境中虚拟机采取不同行动的情况下各自获得的收益数据;
所述收益数据包括以下四种情况:
1.当攻击者对第i台虚拟机发动攻击,且防御者对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
2.当攻击者对第i台虚拟机发动攻击,而防御者并未对该虚拟机进行监控时,则攻击者获得的收益为;防御者获得的收益为。
3.当攻击者并未对第i台虚拟机发动攻击,而防御者对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为。
4.当攻击者并未对第i台虚拟机发动攻击,且防御者并未对该虚拟机进行监控时,则攻击者获得的收益为0;防御者获得的收益为0。
其中表示监控成功的概率,即攻击被成功检测到的概率,;在本实施例中一共选取20台虚拟机,即,若防御者检测到攻击者在第i台虚拟机上发动攻击,则防御者会获得的监控奖励,在本实施例中
,
攻击者会收到的攻击惩罚,在本实施例中
;
若攻击未被检出则防御者会收到的监控惩罚,在本实施例中
,
攻击者会获得的攻击奖励,在本实施例中
;
表示攻击成本,在本实施例中
表示监控成本,在本实施例中
攻击成本和监控成本主要指攻击目标和监控目标所消耗的不同数量的资源,包括存储、计算、带宽、电量、网络占用时间等资源。
2B、计算攻击者和防御者的效用函数;
本发明步骤二所述防御者的效用函数如等式(2-1)所示:
(2-1)
攻击者的效用函数如等式(2-2)所示:
(2-2)
其中T表示云环境下所有虚拟机的集合,在本实施例中虚拟机个数为20;p表示攻击者的策略,即对T中的虚拟机进行攻击的概率分布,在本实施例中随机生成100组不同概率分布p,表示攻击者的随机攻击行为。q表示监控者的策略,即对T中的虚拟机进行监控的概率分布。
、建立复合攻击者行为模型:
所述复合攻击者行为模型以下五种单独的攻击者行为模型按照不同的权重值复合而成:
1.攻击者为完全理性攻击者行为模型时:对等式(2-1)和等式(2-2)进行求解,分别得到攻防双方的最优策略记为表达式(2-3):
(2-3)
式(2-3)为一组纳什均衡解。将式(2-3)代入等式(2-1)得出攻击者为完全理性攻击者行为时,防御者的效用函数,记作。
2.攻击者为QR攻击者行为模型时:在QR模型中,攻击者为有限理性行为,其攻击概率为等式(2-4)所示:
(2-4)
其中为攻击者理性程度,是用来控制攻击者行为理性程度的一个正参数,也可以用来指代攻击对手行为中出现的错误级别或者数量。当时,对手行为中存在许多的错误,此时对手处于完全不理性的状态;当时,对手行为中错误较少,此时对手处于相对理想的状态。在本实施例中,
其中是攻击者关于监控策略变化的效用函数,如等式(2-5)所示:
(2-5)
将等式(2-5)代入到等式(2-4)中得式(2-6):
(2-6)
将等式(2-6)代入等式(2-1),得等式(2-7):
其中n=20。
根据等式(2-7),可得出在攻击行为为QR模型时的攻防双方的最优策略,记作等式(2-8),是一组纳什均衡解。
(2-8)
将等式(2-8)代入等式(2-1)得出攻击者为QR攻击者行为时,防御者的效用函数,记作。
3.攻击者为SUQR3攻击者行为模型时:在SUQR3模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚和监控概率这三个决策指标的加权求和函数如等式(2-9)所示:
(2-9)
SUQR3预测的虚拟机i上的攻击概率如等式(2-10)所示:
(2-10)
其中代表攻击者的偏好程度,即权重值,在本实施例中;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率。
将等式(2-10)代入等式(2-1)得等式(2-11):
(2-11)
根据等式(2-11),可得出在攻击行为为SUQR3模型时的攻防双方的最优策略,记作等式(2-12),是一组纳什均衡解。
(2-12)
将等式(2-12)代入等式(2-1)得出攻击者为SUQR3攻击者行为时,防御者的效用函数,记作。
4.攻击者为SUQR4攻击者行为模型时:在SUQR4模型中,攻击者的期望效用函数被模拟成关于攻击奖励,攻击惩罚,监控成功概率和监控概率这四个决策指标的加权求和函数如等式(2-13)所示:
(2-13)
SUQR4预测的虚拟机i上的攻击概率如等式(2-14)所示:
(2-14)
其中代表攻击者的偏好程度,即权重值,在本实施例中;指攻击者通过攻击虚拟机i获得的奖励,指攻击者通过攻击虚拟机i得到的惩罚,指防御者在虚拟机 i上的监控概率,表示对虚拟机i监控成功概率,在本实施例中。
将等式(2-14)代入等式(2-1)得等式(2-15):
(2-15)
根据等式(2-15),可得出在攻击行为为SUQR4模型时的攻防双方的最优策略,记作等式(2-16),是一组纳什均衡解。
(2-16)
将等式(2-16)代入等式(2-1)得出攻击者为SUQR4攻击者行为时,防御者的效用函数,记作。
5.攻击者为PT攻击者行为模型时:PT攻击者模型提供了攻击者如何在多个备选目标中,选择具有最大的前景的目标进行攻击的过程。根据PT攻击者模型预测的虚拟机i上的攻击概率如等式(2-17)所示:
(2-17)
其中攻击虚拟机i的前景表示为等式(2-18):
(2-18)
其中表示权重,。
其中为固定参数,在本实施例中。
将等式(2-18)代入等式(2-1)得等式(2-19):
(2-19)
根据等式(2-19),可得出在攻击行为为PT模型时的攻防双方的最优策略,记作等式(2-20),是一组纳什均衡解。
(2-20)
将等式(2-20)代入等式(2-1)得出攻击者为PT攻击者行为时,防御者的效用函数,记作。
将以上所求得代入以下等式(2-21),
(2-21)
其中表示同时满足多个目标,即同时最优的一组最优监控概率分布。本实施例中采用fgoalattain 方法对多目标函数进行求解,以使多个目标,即本发明中所述的对多种攻击者行为的防御概率同时达到最优。由图6可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,对20台虚拟机监控的防御收益100%优于假设攻击者行为完全理性的监控方法;由图7可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,对20台虚拟机监控的防御收益100%优于假设攻击者行为QR的监控方法;由图8可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,对20台虚拟机监控的防御收益99%优于假设攻击者行为SUQR3的监控方法;由图9可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,对20台虚拟机监控的防御收益100%优于假设攻击者行为SUQR4的监控方法;由图10可见本发明所述多目标攻击者行为监控方法,在随机发动的100次攻击的情况下,对20台虚拟机监控的防御收益94%优于假设攻击者行为PT的监控方法,可见,在现实网络环境中,攻击者为随机行为,并不完全符合任何单目标行为攻击规律,以本发明所述监控方法可以取得比任何单目标监控方法收益都高的最好的监控效果。
- 还没有人留言评论。精彩留言会获得点赞!