一种基于数据分析的智能路况信息检索方法与流程
本发明涉及智慧交通与信息检索领域,特别是涉及一种在交通电台采编播系统中的智能路况管理信息检索方法。
背景技术:
随着网络通信日益发展和大数据时代的到来,网络提供的数据呈现指数级增长趋势。在交通播报平台系统中,在如此海量的信息中得到各自需要的路况信息,在现在科技手段中,最常用的方法就是利用信息检索技术把相关结果呈现给相关的用户(热心听众、出租车司机、私家车司机、微信用户等)。在交通电台播报系统中,由于路况编辑的浏览界面是呈现信息的其中一种方法,则如何在路况编辑员界面中进行信息检索成为目前交通电台采编播系统中需要解决的难题。
现有的交通电台采编播系统中进行信息索引时,一般是直接在当前页面进行信息检索,数据量大,遍历数据多且没有模糊匹配功能,有可能因输入错误而不能检索到用户所需的信息,导致检索操作复杂,且没有路况折线图等可视化信息,导致检索效率低等问题。
信息检索顾名思义是指信息按照一定的方式组合起来,并根据信息用户的需要找出与用户关键词相关的信息的过程和技术。在通常情况下信息检索的全称为信息储存与检索,指将信息按照某种特定的方式精心组织后并加以储存的过程。其中,信息检索有如下的评价指标:
检索效率:通过最快速度处理用户查询的请求并及时反馈检索结果。主要衡量指标是用户每提交一次关键字查询请求到用户获取结果所经历的时间加上每次处理的查询数目。
查准率和查全率:对于每个用户的查询,应该根据查询要求查询到精准合理的查询结果并最大量的检索出查询结果。
在信息检索的过程中,如何提升检索质量和检索效率,并将最相似用户查询要求的查询结果排在前面,是近几年该技术开发者的重要研究方向。
技术实现要素:
为了解决现有的交通电台采编播系统中路况信息检索效率低和检索质量低的问题,本发明的目的在于提出了一种基于数据分析的智能路况信息检索方法,加快了运算速度,有效的提高路况信息检索质量和检索效率。
本发明提出的一种基于数据分析的智能路况信息检索方法,包括如下的步骤:
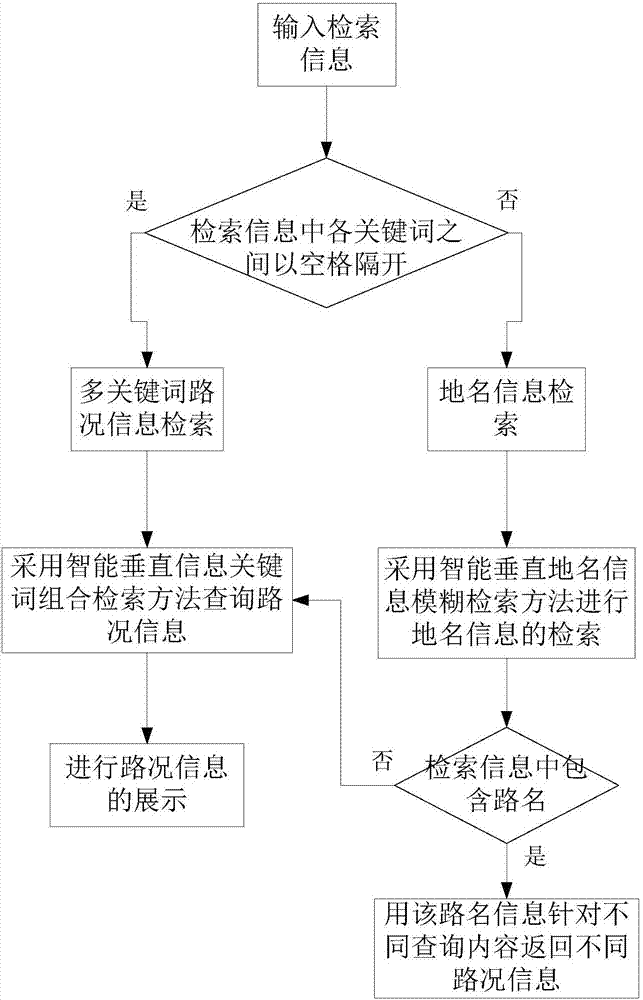
步骤s1:输入检索信息;
步骤s2:若输入检索信息中各关键词之间以空格隔开则为多关键词路况信息检索,执行步骤s4;否则为地名信息检索,执行步骤s3,
步骤s3:采用智能垂直地名信息模糊检索方法进行地名信息的检索,若检索信息中包含路名,则用该路名信息针对不同查询内容返回不同路况信息;否则将检索信息拆分为多个关键词后执行步骤s4;
步骤s4:采用智能垂直信息关键词组合检索方法,通过检索信息的每个关键词具有最大匹配率的路况信息特征,得到查询结果并进行路况信息的展示。
其中,步骤s3中采用智能垂直地名信息模糊检索方法进行地名信息的检索的方法包括以下步骤:
步骤s31:获取检索信息;
步骤s32:使用斯坦福大学分词系统对检索信息进行分词和词性标注,并且提取名词及名词短语作为候选词;
步骤s33:将步骤s32中提取的候选词与标准路名词库进行模糊匹配,选取各候选词最优的匹配率;
步骤s34:利用设定的语法规则库中的语法规则,对步骤s32的分词结果进行拆分或者合并,生成新的候选词,并将新的候选词与标准路名词库进行模糊匹配,选取各候选词最优的匹配率;
步骤s35:对步骤s33和步骤s34得到的各匹配率进行排序,对不同拆分状态下的所有候选词进行加权平均处理,得到各拆分状态的匹配率,并选取匹配率最高的拆分状态对应的匹配结果;
步骤s36:若所选取的最高的匹配率大于设定阈值,则判断为检索信息中包含路名,该匹配率下的拆分状态对应的匹配结果作为准确的路名匹配结果;否则判断为检索信息中不包含路名。
其中,步骤s4中采用智能垂直信息关键词组合检索的方法包括如下的步骤:
步骤s41:获取以空格隔开的关键词作为候选词;
步骤s42:确定输入的每个关键词具有最大匹配率的路况信息特征;所述路况信息特征分为信息来源、信息类型、创建时间、分区方向;
步骤s43:通过加权平均方法得到该条查询的查询结果;
步骤s44:将超过设定阈值的查询结果展示给查询用户。
其中,步骤s33中进行模糊匹配并选取各候选词最优的匹配率的方法包括如下步骤:
步骤s331:遍历候选词和标准路名词库;
步骤s332:计算匹配率,公式如下:
其中,c为候选词,d为标准路名词库中的词典词,count(ainb)表示a的每个字符出现在b中的总的次数;num(a)表示a的字符数;
步骤as333:对步骤s332中计算的每个候选词的匹配率使用快速排序法排序,选取匹配率最大的作为最优匹配率。
其中,步骤s34所述语法规则为名词结构的合并和拆分,具体规则为:
“识别地名,识别地名”重新生成为“识别地名,识别地名”;
“识别地名,方向词,识别地名”重新生成为“识别地名,识别地名”;
“简称略语,名词”重新生成为“识别地名”;
“其他专名,名词,方向词”重新生成为“识别地名,方向词”;
“识别地名”拆分为“名词,方向词”。
其中,步骤s35所述加权平均处理的方法为:
采用等权重平均方法计算总排序分数,基本公式如下所示:
其中n为一个拆分状态下的所有候选词的个数,s为检索信息。
其中,步骤s42中确定输入的每个关键词具有最大匹配率的路况信息特征的方法为:
步骤s421:采用步骤s332的方法计算匹配率,其中各关键词为候选词;
步骤s422:选取匹配率最大的路况信息特征作为该关键词指示的信息特征。
其中,步骤s43所述加权平均方法具体表现为如下公式:
其中n为步骤s31中获取的候选词的个数,s为由各关键词构成的查询语句,αj为权重系数。
其中权重系数αj的计算公式为
其中ti为关键词对应最大匹配率的路况信息特征;tj为特征词类别,包括开始时间、结束时间、创建用户、描述内容、路况信息来源、路况信息性质。
本发明加快了运算速度,并且可以有效的提高路况信息检索质量和检索效率,且具有很强的可操作性。
附图说明
图1为传统的信息检索服务框架图;
图2是本发明总体系统的框架流程图;
图3是智能垂直地名信息模糊检索方法流程框图;
图4是智能垂直信息关键词组合检索方法流程框图。
具体实施方式
为了使得本发明的优点、技术方案、发明目的更加明白清楚,下面结合实例和附图,对本发明进行更进一步分详尽说明。其中,此处所用的具体实施实例仅仅用于解释本发明,并不用于限定本发明。
在日常生活中,信息检索时所涉及到的信息资源有很多类,以交通广播电台的播报系统为例,通常会涉及如下的资源:网络设备、关系型数据库、本地文件等,且用户的一次检索,很可能会从多个信息中查找数据,目前所使用的典型信息检索服务架构示意图如图1所示:接收信息检索指令,该信息检索指令中包括信息检索关键词;根据信息检索指令,遍历所有的浏览器中打开的页面,从中查找与检索关键词匹配的页面,生成检索结果;输出检索结果
本发明提出的一种基于数据分析的智能路况信息检索方法,如图2所示包括如下步骤:
步骤s1:输入检索信息;
步骤s2:若输入检索信息中各关键词之间以空格隔开则为多关键词路况信息检索,执行步骤s4;否则为地名信息检索,执行步骤s3,
步骤s3:采用智能垂直地名信息模糊检索方法进行地名信息的检索,若检索信息中包含路名,则用该路名信息针对不同查询内容返回不同路况信息;否则将检索信息拆分为多个关键词后执行步骤s4;
步骤s4:采用智能垂直信息关键词组合检索方法,通过检索信息的每个关键词具有最大匹配率的路况信息特征,得到查询结果并进行路况信息的展示。
本实施例中,步骤s3中采用智能垂直地名信息模糊检索方法进行地名信息的检索的方法,主要用于准确的召回检索信息中的地名路名相关信息,具体如图3所示包括以下步骤:
步骤s31:获取检索信息;
步骤s32:使用斯坦福大学分词系统对检索信息进行分词和词性标注,并且提取名词及名词短语作为候选词;
步骤s33:将步骤s32中提取的候选词与标准路名词库进行模糊匹配,选取各候选词最优的匹配率;
步骤s34:利用设定的语法规则库中的语法规则,对步骤s32的分词结果进行拆分或者合并,生成新的候选词,并将新的候选词与标准路名词库进行模糊匹配,选取各候选词最优的匹配率;
步骤s35:对步骤s33和步骤s34得到的各匹配率进行排序,对不同拆分状态下的所有候选词进行加权平均处理,得到各拆分状态的匹配率,并选取匹配率最高的拆分状态对应的匹配结果;
步骤s36:若所选取的最高的匹配率大于设定阈值,则判断为检索信息中包含路名,该匹配率下的拆分状态对应的匹配结果作为准确的路名匹配结果;否则判断为检索信息中不包含路名。
本实施例中,步骤s33中进行模糊匹配并选取各候选词最优的匹配率的方法包括如下步骤:
步骤s331:遍历候选词和标准路名词库;
步骤s332:计算匹配率,计算方法如公式(1)所示:
其中,c为候选词,d为标准路名词库中的词典词,count(ainb)表示a的每个字符出现在b中的总的次数;num(a)表示a的字符数;
步骤as333:对步骤s332中计算的每个候选词的匹配率使用快速排序法排序,选取匹配率最大的作为最优匹配率。
因为斯坦福的分词系统处理大而常的路名有时有些出入,例如:该分词系统会把建国门外大街分成建国门/ns外/f大街/n,从而使得现成的分词系统对处理路名长等问题十分棘手。根据语法规则对分词结果进行处理,去除可能的由分词错误造成的系统检索错误。具体设计语法规则如表1所示。
表1
其中,ns为识别地名,n为名词,f为方向词,nz为其他专名,j为简略词。
在本实施例中具体表现为步骤s34所述语法规则为名词结构的合并和拆分,具体规则描述为:
“识别地名,识别地名”重新生成为“识别地名,识别地名”;
“识别地名,方向词,识别地名”重新生成为“识别地名,识别地名”;
“简称略语,名词”重新生成为“识别地名”;
“其他专名,名词,方向词”重新生成为“识别地名,方向词”;
“识别地名”拆分为“名词,方向词”。
本实施例中,步骤s35所述加权平均处理的方法为:
采用等权重平均方法计算总排序分数,计算公式如公式(2)所示:
其中n为一个拆分状态下的所有候选词的个数,s为检索信息。
本实施例中,步骤s4中采用智能垂直信息关键词组合检索的方法,针对交通路况信息的特点对各输入关键词,按照分类特征进行匹配检索,具体如图4所示,包括如下的步骤:
步骤s41:获取以空格隔开的关键词作为候选词;
步骤s42:确定输入的每个关键词具有最大匹配率的路况信息特征;所述路况信息特征分为信息来源、信息类型、创建时间、分区方向;
步骤s43:通过加权平均方法得到该条查询的查询结果;
步骤s44:将超过设定阈值的查询结果展示给查询用户。
所述选取最优路况信息匹配特征方法,主要基于基本思想:用户的每一个查询关键词都是针对某一查询特征(不同关键词针对的特征可以重复,即,可以用多个关键词描述一个特征)。因此提出最优匹配率的概念,找出每一个用户输入关键词的路况信息特征,具体描述为本实施例中步骤s42中确定输入的每个关键词具有最大匹配率的路况信息特征的方法,包括以下步骤:
步骤s421:采用步骤s332的方法计算匹配率,其中各关键词为候选词;
具体为,各候选词在每一个特征下按照步骤s332计算匹配率,该公式可以保证例如输入关键字“建国门”,候选集中“建国门”的匹配率比“建国门桥”要高,同时输入“建国门桥”时,候选集中匹配率“建国门桥”大于“建国门”大于“建国门外大街”
步骤s422:选取匹配率最大的路况信息特征作为该关键词指示的信息特征。
本实施例中,步骤s43所述加权平均方法具体表现为公式(3):
其中n为步骤s31中获取的候选词的个数,s为由各关键词构成的查询语句,αj为权重系数,
权重系数αj的计算公式如公式(4)所示
其中ti为关键词对应最大匹配率的路况信息特征;tj为特征词类别,包括开始时间、结束时间、创建用户、描述内容、路况信息来源、路况信息性质。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!