结合从句级远程监督和半监督集成学习的关系抽取方法与流程
本发明涉及信息抽取领域,具体涉及一种结合从句级远程监督和半监督集成学习的关系抽取方法。
背景技术:
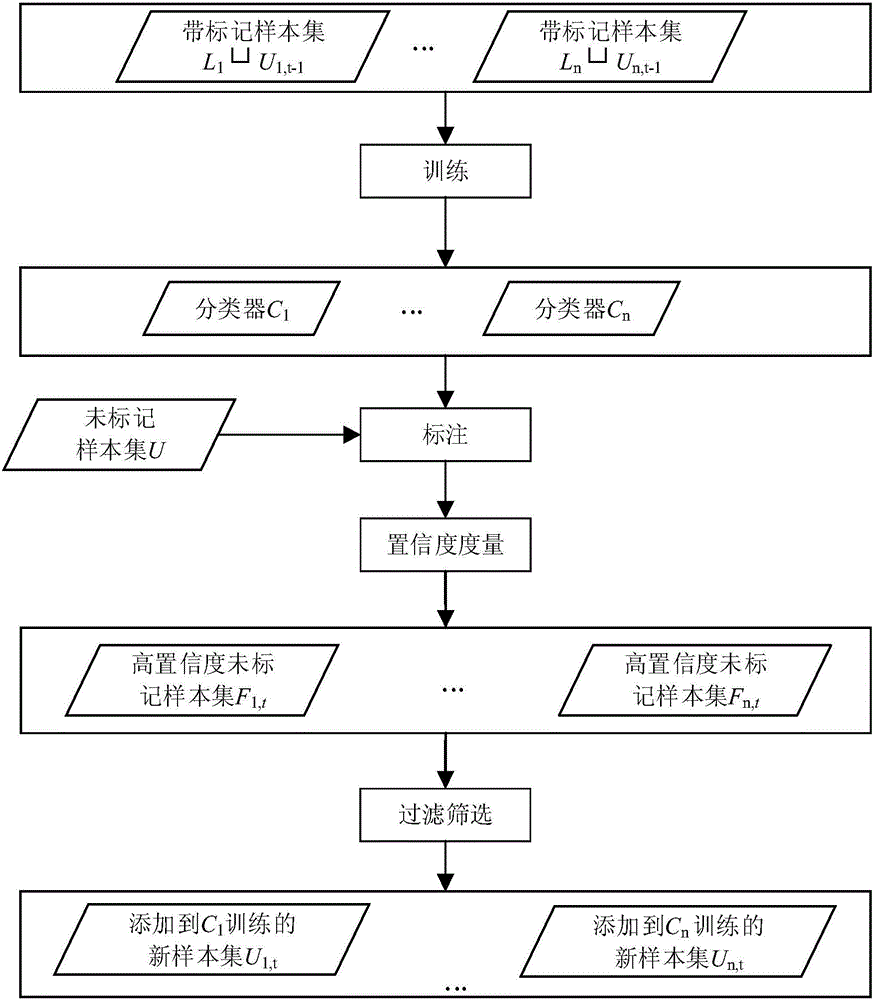
:信息抽取(InformationExtraction)是指从一段文本中抽取实体、事件、关系等类型的信息,形成结构化数据存入数据库中以供用户查询和使用的过程。关系抽取(RelationExtraction)是信息抽取的关键内容,旨在抽取实体之间存在的语义关系。关系抽取技术在自动问答系统构建、海量信息处理、知识库自动构建、搜索引擎和特定文本挖掘等领域具有广阔的应用前景。传统的关系抽取研究一般采用有监督的机器学习方法,该类方法将关系抽取看作分类问题,使用人工标注的训练数据,通过抽取的词法特征和句法特征训练关系分类器,能取得一定的分类效果。但是,由于需要代价高昂的人工标注数据,使得有监督的关系抽取方法能识别的关系类型局限于特定领域且不能适应海量网络文本的情况。为了解决有监督的关系抽取方法人工标注数据不足的问题,研究人员提出了自动生成标注数据的方法—远程监督(DistantSupervision),其假设如果两个实体之间有某种语义关系,则所有包含它们的句子都在一定程度上表达了这种关系。基于上述假设,远程监督利用知识库蕴含的大量关系三元组,通过与训练语料的文本对齐,可以生成大量的标注数据。远程监督解决了有监督的关系抽取方法标注数据不足的问题,但由于其假设并不总是正确,导致生成的标注数据中存在大量的错误标注数据(即噪声数据),对关系抽取模型造成不利影响。针对噪声问题,现有处理方法一般通过修改关系抽取模型的方式来减小噪声数据的负面影响,虽然能够取得一定的效果,但并不能够从根本上解决噪声问题。另外,基于远程监督的关系抽取普遍存在负例数据利用不足的问题,这是因为通过远程监督生成的关系实例集中负例关系实例数量远大于正例关系实例数据数量,导致特征数据集中负例数据的数量远大于正例数据数量,为保证参与训练的正例数据和负例数据数量均衡,一般选取特征数据集全部的正例数据和少部分负例数据组成训练数据集,剩余的大部分负例数据被搁置不用。技术实现要素:为了解决关系抽取方法中噪声数据和负例数据问题,本发明提供了一种结合从句级远程监督和半监督集成学习的关系抽取方法,该方法既能够去除噪声数据,又能够充分利用负例数据。一种结合从句级远程监督和半监督集成学习的关系抽取方法,主要包括如下步骤:步骤1,通过远程监督将知识库中的关系三元组对齐到语料库,构建关系实例集;步骤2,使用基于句法分析的从句识别去除关系实例集中的噪声数据;步骤3,抽取关系实例的词法特征并转化为分布式表征向量,构建特征数据集;步骤4,选择特征数据集中全部的正例数据和少部分负例数据组成标注数据集,其余负例数据在去除标签后组成未标注数据集,使用半监督集成学习算法训练关系分类器。在步骤1中,通过远程监督将知识库K中的关系三元组对齐到语料库D,构建关系实例集Q={qn丨qn=(sm,ei,rk,ej),sm∈D}。其中,qn为关系实例,sm为句子,ei和ej为实体,rk为ei和ej之间存在的实体关系。如果句子sm同时包含实体ei和实体ej,且知识库K中存在关系三元组(ei,rk,ej),则qn=(sm,ei,rk,ej)为正例关系实例,同时选择一些不符合上述条件的关系实例作为负例关系实例。步骤2的具体步骤如下:步骤2-1,使用概率上下文无关文法对关系实例qn的句子sm进行解析,得到其语法树,根据语法树表示的句子sm的词之间的结构关系,将sm划分成从句;步骤2-2,根据关系实例qn的实体对(ei,ej)是否同时出现在句子sm的某一个从句当中来判断关系实例qn是否是噪声数据;如果qn是噪声数据,则将其从关系实例集Q中去除;如果关系实例qn=(sm,ei,rk,ej)是正例关系实例,当句子sm对应的实体对(ei,ej)没有出现在句子sm的任一从句中时,认为关系实例qn是噪声数据,并将其从关系实例集Q中去除;如果关系实例qn=(sm,ei,rk,ej)是负例关系实例,当句子sm对应的实体对(ei,ej)出现在句子sm的某一从句中时,认为关系实例qn是噪声数据,并将其从关系实例集Q中去除。步骤3的具体步骤如下:步骤3-1,抽取关系实例集Q中每个关系实例qn的词法特征lexn;步骤3-2,将词法特征lexn转化为分布式表征向量vn,构建特征数据集M。在步骤3-1中,对于关系实例qn=(sm,ei,rk,ej),其词法特征lexn为实体对(ei,ej)本身以及(ei,ej)在句子sm中的上下文,具体的词法特征类型如表1所示。表1词法特征类型在步骤3-2中,将词法特征lexn转化为分布式表征向量vn,然后将所有的vn集合起来组成特征数据集M;关系实例集Q中正例关系实例的词法特征向量化后变为M的正例数据,关系实例集Q中负例关系实例的词法特征向量化后变为M的负例数据。步骤4的具体步骤如下:步骤4-1,选择特征数据集M中全部的正例数据和少部分负例数据组成标注数据集L;剩余负例数据在去除标签后作为未标注数据集U;步骤4-2,从标注数据集L中有放回地选取n个初始样本集L1,L2,…,Ln;步骤4-3,使用初始样本集Li和第t-1轮选出的高置信度的未标注样本集Ui,t-1训练对应的关系分类器Ci,其中,i=1,2,…,n;步骤4-4,n个关系分类器C1,C2,…,Cn对未标注数据集U中未标注样本xu的类标记分别进行预测,通过投票法生成高置信度的未标注样本集Fi,t;步骤4-5,根据一定的过滤筛选准则,从高置信度的未标注样本集Fi,t中,为第i个关系分类器Ci挑选一定数量的未标注样本xu,构成Ui,t,在下一轮迭代过程中加入到第i个关系分类器Ci的训练集中,然后重新训练对应的关系分类器Ci;步骤4-6,重复步骤4-4,4-5,4-6,当所有Ui,t都为空集,即没有新的未标注样本xu加入到训练集中时,或者迭代次数已经达到预先设定的最大迭代次数时,该训练过程停止。在步骤4-3中,Ui,t-1表示在第t-1轮迭代中,关系分类器为第i个关系分类器Ci时,挑选的未标注样本xu的集合,该未标注样本xu由U中的未标注样本xu以及从t-1轮迭代中得到的类标记组成,其中t大于等于2,当t=1时,Ui,t-1为空集。注意,t-1轮前添加到训练集的未标注样本xu将会从训练集中被删除掉,重新加入到未标注样本集Fi,t中,每一轮迭代中训练集都只扩充上一轮添加的未标注样本xu。在步骤4-4中,Fi,t表示在第t轮迭代中,关系分类器为Ci时,挑选的高置信度未标注样本xu的集合,该集合经过一定的过滤筛选后,留下来的未标注样本xu将构成Ui,t。针对未标注样本xu,用hi(xu)表示第i个关系分类器Ci对未标注样本xu预测的类标记。关系分类器E中删除Ci后的集合设为Ei,即Ei={Cj∈E|j≠i}。未标注样本xu的类标记由Ei中的多个关系分类器Ei投票决定,选择票数最多的类标记作为未标注样本xu的类标记。样本预测结果的一致性程度,即为置信度,关系分类器Ei根据其预测的样本标记的一致性计算置信度,计算公式为公式1-1:confi(xu)=Σj=0,j≠inI(hj(xu)=l^xui)n-1,---(1-1)]]>其中,confi(xu)表示xu的真实类标记为的置信度;I()是一个指示函数,如果输入为假,该函数值为0,否则为1。高置信度的未标注样本xu能够有效地提升关系分类器的分类准确率,如果在保证未标注样本标记高置信度的前提下,考虑Ci和Ei在同一样本上预测结果的不一致性,进而选择出能够纠正关系分类器Ci的未标注样本集Fi,t,则能进一步提升关系分类器的分类准确率。因此,在第t轮迭代过程中,公式1-2为第i个关系分类器选择高置信度的未标注样本xu,Fi,t=x|confi(x)≥θΛhi(x)≠l^xi,x∈U,---(1-2)]]>其中θ是一个预设的阈值,只有未标注样本xu的置信度大于该阈值,并且Ci与Ei的预测结果不一致时,该样本才会被选择加入到Fi,t中。在步骤4-5中,对于未标注样本xu,令P(hi(xu))表示Ci预测xu输出为hi(xu)的概率值,在过滤筛选时,同时考虑P(hi(xu))和confi(xu),将Fi,t集合中的高置信度未标注样本按照confi(xu)、P(hi(xu))的顺序依次降序排序,即confi(xu)越大的样本越靠前,confi(xu)相同的情况下,P(hi(xu))越大的样本越靠前;经过排序后,取前mi,t个样本构成Ui,t。本发明结合了从句识别和半监督集成学习算法,在去除关系实例噪声的同时,充分利用负例数据。与现有的技术相比,本发明的优点包括:(1)通过从句识别去除训练数据中的噪声数据,提高了训练数据的标记准确度,从而提高了关系抽取的分类准确度。(2)通过半监督集成学习算法训练关系分类器,将传统关系抽取中未被利用的负例数据去除标签后作为无标注数据使用,提高了负例数据的利用率,从而提高了关系抽取的分类准确度。附图说明图1是结合从句识别与半监督集成学习的关系抽取方法流程图;图2是第t轮迭代流程图。具体实施方式为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。图1所示的是本发明一种结合从句级远程监督与半监督集成学习的关系抽取方法的流程图,该方法分为数据处理和模型训练两个阶段。数据处理阶段数据处理的具体步骤如下:步骤a-1,通过远程监督将知识库K中的关系三元组对齐到语料库D,构建关系实例集Q={qn丨qn=(sm,ei,rk,ej),sm∈D}。如果句子sm同时包含实体ei和ej,且知识库K中存在关系三元组(ei,rk,ej),则(sm,ei,rk,ej)为正例关系实例,同时选择一些不符合上述条件的关系实例作为负例关系实例。步骤a-2,使用概率上下文无关文法对关系实例qn的句子sm进行解析,得到其语法树,根据语法树表示的句子sm的词之间的结构关系,将sm划分成从句。步骤a-3,根据关系实例qn的实体对(ei,ej)是否同时出现在句子sm的某一个从句当中来判断关系实例qn是否是噪声数据;如果qn是噪声数据,则将其从关系实例集Q中去除;如果关系实例qn=(sm,ei,rk,ej)是正例关系实例,当句子sm对应的实体对(ei,ej)没有出现在句子sm的任一从句当中时,认为关系实例qn是噪声数据,并将其从关系实例集Q中去除;如果关系实例qn=(sm,ei,rk,ej)是负例关系实例,当句子sm对应的实体对(ei,ej)出现在句子sm的某一从句中时,认为关系实例qn是噪声数据,并将其从关系实例集Q中去除。步骤a-4,抽取关系实例集Q中每个关系实例qn的词法特征lexn。对于关系实例qn=(sm,ei,rk,ej),其词法特征lexn为实体对(ei,ej)本身以及(ei,ej)在句子sm中的上下文,具体的词法特征类型如表1所示。表2词法特征类型步骤a-5,将词法特征lexn转化为分布式表征向量vn,构建特征数据集M。将词法特征lexn转化为分布式表征向量vn,然后将所有的vn集合起来组成特征数据集M;关系实例集Q中正例关系实例的词法特征向量化后变为M的正例数据,关系实例集Q中负例关系实例的词法特征向量化后变为M的负例数据。模型训练阶段模型训练是一个迭代式学习过程,其第t次迭代如图2所示。步骤b-1,选择特征数据集M中全部的正例数据和少部分负例数据组成标注数据集,记作L;剩余负例数据在去除标签后作为未标注数据集,记作U。步骤b-2,从标注数据集L中有放回地选取n个初始样本集L1,L2,…,Ln。步骤b-3,使用初始样本集Li和第t-1轮选出的高置信度未标注样本集Ui,t-1训练对应的关系分类器Ci,其中,i=1,2,…,n。Ui,t-1表示在第t-1轮迭代中,关系分类器为第i个关系分类器Ci时,挑选的未标注样本xu的集合,该未标注样本xu由U中的未标注样本xu以及从t-1轮迭代中得到的类标记组成,其中t大于等于2,当t=1时,Ui,t-1为空集。注意,t-1轮前添加到训练集的未标注样本xu将会从训练集中被删除掉,重新加入到未标注样本集Fi,t中,每一轮迭代中训练集都只扩充上一轮添加的未标注样本xu。步骤b-4,n个关系分类器C1,C2,…,Cn对未标注数据集U中未标注样本xu的类标记分别进行预测,通过投票法生成高置信度的未标注样本集Fi,t;Fi,t表示在第t轮迭代中,关系分类器为Ci时,挑选的高置信度未标注样本xu的集合,该集合经过一定的过滤筛选后,留下来的未标注样本xu将构成Ui,t。针对未标注样本xu,用hi(xu)表示第i个关系分类器Ci对未标注样本xu预测的类标记。关系分类器E中删除Ci后的集合设为Ei,即Ei={Cj∈E|j≠i}。未标注样本xu的类标记由Ei中的多个关系分类器Ei投票决定,选择票数最多的类标记作为未标注样本xu的类标记。样本预测结果的一致性程度,即为置信度,关系分类器Ei根据其预测的样本标记的一致性计算置信度,计算公式为公式1-1:confi(xu)=Σj=0,j≠inI(hj(xu)=l^xui)n-1,---(1-1)]]>其中,confi(xu)表示xu的真实类标记为的置信度;I()是一个指示函数,如果输入为假,该函数值为0,否则为1。高置信度的未标注样本xu能够有效地提升关系分类器的分类准确率,如果在保证未标注样本标记高置信度的前提下,考虑Ci和Ei在同一样本上预测结果的不一致性,进而选择出能够纠正关系分类器Ci的未标注样本集Fi,t,则能进一步提升关系分类器的分类准确率。因此,在第t轮迭代过程中,公式2为第i个关系分类器选择高置信度的未标注样本,Fi,t=x|confi(x)≥θΛhi(x)≠l^xi,x∈U,---(1-2)]]>其中θ是一个预设的阈值,只有未标注样本xu的置信度大于该阈值,并且Ci与Ei的预测结果不一致时,该样本才会被选择加入到Fi,t中。步骤b-5,根据一定的过滤筛选准则,从高置信度的未标注样本集Fi,t中,为第i个关系分类器Ci挑选一定数量的未标注样本xu,构成Ui,t,在下一轮迭代过程中加入到第i个关系分类器Ci的训练集中,然后重新训练对应的关系分类器Ci;对于未标注样本xu,令P(hi(xu))表示Ci预测xu输出为hi(xu)的概率值,在过滤筛选时,同时考虑P(hi(xu))和confi(xu),将Fi,t集合中的高置信度未标注样本按照confi(xu)、P(hi(xu))的顺序依次降序排序,即confi(xu)越大的样本越靠前,confi(xu)相同的情况下,P(hi(xu))越大的样本越靠前。经过排序后,取前mi,t个样本构成Ui,t。步骤b-6,重复步骤b-3、b-4、b-5,当所有Ui,t都为空集,即没有新的未标注样本加入到训练集中时,或者迭代次数已经达到预先设定的最大迭代次数时,该训练过程停止。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1