一种基于关键用户的微博信息传播预测方法与流程
本发明涉及的是一种网络分析方法,具体地说是一种微博信息传播预测方法。
背景技术:
随着社会网络的飞速发展,人类进入了自媒体时代。微博网络作为典型的社交媒体平台,其140字的短文本信息发送方式以及多种的交互模式,使其成为人们获取信息、分享信息、传播信息的重要平台。由于微博网络具有数据量大、信息碎片化严重、交互多样性、信息传播快等特性,通过系统审核或人工实时监控,并不能有效地限制社交网络舆情危机信息的传播。因此微博除了成为民众表达关切和诉求的窗口之外,也成为了虚假信息、流言蛮语滋生的平台。
针对在特定的网络舆情事件中可能产生微博负面舆情危机的问题,在负面舆情被大规模传播之前需要对特定热点舆情事件中的微博消息的传播进行预测。在负面信息大规模爆发之前进行有效地处理是社会网络舆情安全研究所必须解决的问题。社交网络中的网络舆情传播通常是由一个或多个用户协同来进行大规模扩散的。因此在研究社交网络舆情传播预测的过程中,如何针对影响信息传播的关键用户来动态调整传播预测模型,是社交网络舆情信息传播预测的重要环节。
与本发明相关的公开报道包括:
[1]WANG Jing,LIU Zhijing,ZHAO Hui,“Micro-blogs Entity Recognition Based on DSTCRF”,Chinese Journal of Electronics,Vol.23,No.1,pp 147-150,2014;
[2]YANG Zhen,FAN Kefeng,LAI Yingxu,GAO Kaiming and WANG Yong,“Short Texts Classification Through Reference Document Expansion”,Chinese Journal of Electronics,Vol.23,No.2,2014;
[3]Yang Z,Guo J,Cai K,Tang J,Li J,Zhang L,et al.,Understanding retweeting behaviors in social networks.Proceedings of the 19th ACM international conference on Information and knowledge management;2010:ACM.1633-1636 p;
[4]Peng H-K,Zhu J,Piao D,Yan R,Zhang Y,Retweet modeling using conditional random fields.Data Mining Workshops(ICDMW),2011 IEEE 11th International Conference on;2011:IEEE.336-343 p;
[5]Zaman TR,Herbrich R,Van Gael J,Stern D,Predicting information spreading in twitter.Workshop on computational social science and the wisdom of crowds,nips;2010:Citeseer.17599-17601 p;
[6]Kupavskii A,Ostroumova L,Umnov A,Usachev S,Serdyukov P,Gusev G,et al.,Prediction of retweet cascade size over time.Proceedings of the 21st ACM international conference on Information and knowledge management;2012:ACM.2335-2338 p;
[7]Cheng J,Adamic L,Dow PA,Kleinberg JM,Leskovec J,Can cascades be predicted?Proceedings of the 23rd international conference on World wide web;2014:ACM.925-936 p;
[8]Zhao Q,Erdogdu MA,He HY,Rajaraman A,Leskovec J,SEISMIC:A Self-Exciting Point Process Model for Predicting Tweet Popularity.Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining;2015:ACM.1513-1522 p;
[9]Yang J,Leskovec J,Modeling information diffusion in implicit networks.Data Mining(ICDM),2010IEEE 10th International Conference on;2010:IEEE.599-608p;
[10]Wang CX,Guan XH,Qin Tao,Zhou YD.Modeling Opinion Leader’s Influence in Microblog Message Propagation and Its Application.Journal of Software,2015,26(6)。
技术实现要素:
本发明的目的在于提供一种具有准确的预测效果,并可以挖掘影响预测性能的关键用户的基于关键用户的微博信息传播预测方法。
本发明的目的是这样实现的:
步骤1:数据采集;
步骤2:数据处理;
步骤3:利用线性模型预测;
步骤4:基于关键用户挖掘的模型调整,进行后续预测。
本发明还可以包括:
1、所述数据采集具体包括:
步骤1.1:在微博网络中实时获取给定消息id的转发用户;
步骤1.2:获取微博用户的配置信息,所述配置信息包括关注数、粉丝数。
2、所述数据处理具体包括:
步骤2.1:根据给定的时间间隔将步骤1.1与1.2所获得的数据划分为多个时间窗口;
步骤2.2:选取前k个时间窗口作为训练数据窗口,第k+1时间窗口为预测窗口。
3、所述利用线性模型预测具体包括:
步骤3.1:首先根据训练集的时间窗口内用户的转发量确定时间窗口内的关键用户;
步骤3.2:根据用户的转发数对线性函数进行拟合,迭代的确定线性函数的待估参数值,确定预测函数;
步骤3.3:将预测时间窗口的窗口值代入预测函数,生成预测值。
4、所述基于关键用户挖掘的模型调整具体包括:
步骤4.1:根据预测值和实际值的差异确定是否需要进行关键用户检测;
步骤4.2:当预测差异大于阈值时,根据该时间窗口的用户转发数确定关键用户;
步骤4.3:利用关键用户的粉丝数,以及之前其他关键用户的粉丝数来确定关键用户的数值,来对线性模型进行调整。
步骤4.4:利用新生成的线性模型对下一时间窗口进行预测。
本发明提出了一种基于消息传播中的关键用户的动态线性预测模型,该模型在预测的同时检查影响预测准确性的关键用户,通过关键用户动态调整线性预测模型。
本发明的方法,利用从微博网络上获取的消息的用户转发数据,通过基于关键用户的动态线性模型来预测未来信息传播的状态,并在预测的过程中实时的挖掘关键用户,在新增关键用户的基础上对线性模型进行改进。
与现有技术相比,本发明具有如下的有益效果:
1、本发明提出一种基于关键用户的微博信息传播预测方法,该技术主要考虑信息传播预测过程中关键用户出现导致预测失准的问题,来对传统的线性预测模型进行改进。并取得了良好的预测效果。
2、本发明能够有效的针对微博类的大规模社会网络,具有较为准确的预测效果,并可以挖掘影响预测性能的关键用户。
附图说明
图1是本发明的总体流程图。
图2是本发明的线性模型的具体示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。
结合图1,本发明的基于关键用户的微博信息传播预测方法的具体实现步骤如下:
步骤101:数据采集;
步骤102:数据处理;
步骤103:线性模型预测;
步骤104:基于关键用户挖掘的模型调整。
步骤101中,其所述数据采集的步骤包括:
在微博网络中实时获取给定消息id的转发用户;
获取微博用户的配置信息,关注数、粉丝数等;
所述步骤102中,其所述数据处理的步骤包括:
根据给定的时间间隔将微博数据划分为多个时间窗口;
选取前k个时间窗口作为训练数据窗口,第k+1时间窗口为预测窗口;
所述步骤103中,其所述线性模型预测的步骤为:
首先根据训练集的时间窗口内用户的转发量确定时间窗口内的关键用户;
根据用户的转发数对线性函数进行拟合,迭代的确定线性函数的待估参数值,确定预测函数。
将预测时间窗口的窗口值代入预测函数,生成预测值。
所述步骤104中,其所述的基于关键用户挖掘的模型调整:
根据预测值和实际值的差异确定是否需要进行关键用户检测;
当预测差异大于阈值时,根据该时间窗口的用户转发数确定关键用户;
利用关键用户的粉丝数,以及之前其他关键用户的粉丝数来确定关键用户的数值,来对线性模型进行调整。
利用新生成的线性模型对下一时间窗口进行预测。
在步骤101中,数据采集是指从微博网络实时获取微博转发用户数据。
在步骤102中,数据处理是指将获取的微博转发数据按固定时间间隔划分时间窗口。
将微博消息oid为相同值的微博微博消息按照消息的时间,以固定的时间间隔L划分为N个微博窗口ms,ms=[win1,…,winj,…,winL],winj为第j个微博窗口,且满足
在步骤103中,线性模型预测是指根据给定的训练时间窗口训练线性模型对下一个时间窗口进行预测。
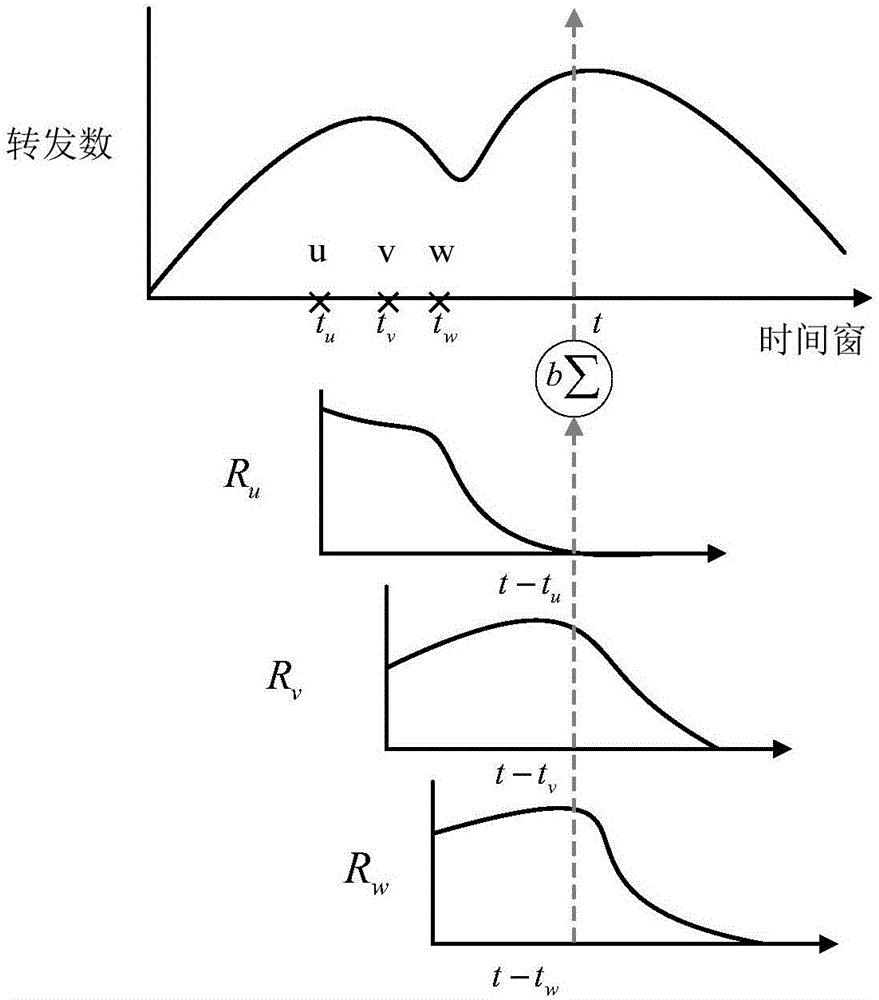
在线性预测模型预测的过程中仅考虑关键用户对转发规模具有影响如图2所示,并根据图2建立公式(1)。公式主要由三部分组成,本发明考虑微博消息制造者作为第一个关键用户与其他的关键用户的影响效果是不同的,因此使用参数at,bt对两类关键用户进行区分。然后是用dt来调节其他节点带来的部分消息转发影响。
其中表示t时刻用户ui的预测转发量,表示m消息在t时刻的关键用户集合。
根据公式需求,首先确定发布用户为第一个关键用户,然后根据训练集中用户的被转发数确定训练集关键用户,最后通过公式(1)进行预测。
在步骤104中,初始候选集合选取,是指根据预测值和实际值得差异性来确定是否进行关键用户挖掘并根据关键用户改进线性模型。
在消息的传播过程中,训练集中的关键用户通常很容易被确定,但当预测时间窗口中出现关键用户后,预测算法的准确性被关键用户干扰后,导致预测准确度下降。因此本发明将关键用户作为微博转发规模预测准确度的重要因素。当关键用户出现在预测时间窗口内时,预测算法会产生相应的预测偏差,因此本发明定义Key_Thrseshold作为关键用户存在阈值,其公式如所示:
当Key_Thrseshold<θ时,证明该时间窗口内不存在影响预测的关键用户,当Key_Thrseshold≥θ时并且R_Fact(t)-R_Precdit(t)≥10表明该预测时间窗内可能存在影响预测的关键用户,需要对该时间窗口进行关键用户挖掘。Key_Thrseshold≥θ表明预测算法和实际值有较大的差异,R_Fact(t)-R_Precdit(t)≥10为了避免小于10的转发规模影响阈值计算。同时当Key_Thrseshold≤-θ时,表明之前窗口可能有部分的关键用户失效,需要删除关键用户影响。
首先根据该时间窗口中的用户自身转发数进行用户排序,生成排序集合依次的将集合中的用户添加到下列公式中,直到满足下列公式为止。
通过找到的关键用户集合对线性模型进行动态的调整,来进行下一步的预测。
- 还没有人留言评论。精彩留言会获得点赞!