一种基于地铁数据进行站点聚类的可视化方法与流程
本发明涉及交通数据可视化领域,尤其涉及一种基于地铁数据进行站点聚类的可视化方法。
背景技术:
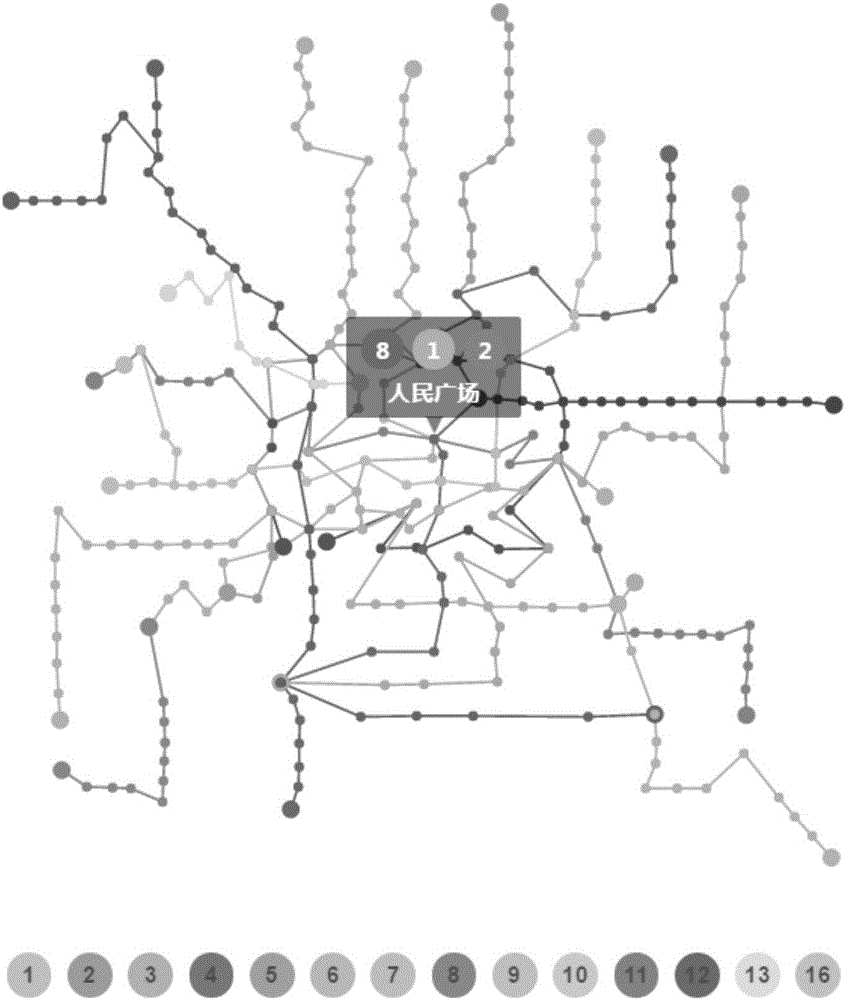
:随着城市交通的快速发展,随之产生了大量的交通数据,这些交通数据具有时间属性、空间属性,通过这些属性能够真实的反应交通客流状况。地铁为城市居民出行提供极大便利,成为公共交通的重要组成部分,每天有大量的乘客通过刷卡进出各个地铁站点。每个站点的客流数据与站点附近区域的功能息息相关。其中根据地铁客流数据,发现具有类似功能的地铁站点,这种区域功能的发现对了解城市结构有着极为重要的意义。然而地铁数据的庞杂和抽象造成从这些数据中挖掘信息并不容易,而可视化技术结合可视图表的展示形式和人机交互,操作简化分析过程,用户通过交互修改分析模型的参数,从而生成新的可视化结果,经过可视化分析,能够从地铁数据中得到更多有价值的信息。技术实现要素:本发明的目的主要针对上述数据分析的不便之处,提出一种基于地铁数据进行站点聚类的可视化方法,通过对地铁刷卡数据处理,提取出能够反映路段地铁站点客流模式的特征值,通过交互式参数设置,对各个地铁站点进行聚类,并对聚类结果进行可视化展示。为了解城市结构提供有效信息。本发明是通过以下技术方案达到上述目的:一种基于地铁数据进行站点聚类的可视化方法,其包括如下步骤:S1:对地铁数据进行预处理;S2:对S1所述地铁数据进行时空探索;S3:通过聚类算法对地铁站点进行聚类;S4:可视化展示聚类结果。其中S1具体包含:地铁刷卡数据的清洗,如清除缺失值、噪声数据等,以及地铁基础数据的规范化处理。其中S2具体包含如下步骤:S2.1:将地铁线路站点信息映射到OpenStreetMap地图上;S2.2:用户交互的进行时间和空间上的过滤;S2.3:对S2.2所述过滤结果进行可视化展示,包括显示进出站客流量变化情况的环形图和折线图。其中S3具体包含如下步骤:S3.1:时间划分:根据地铁站客流特征,将一天划分成m个时间段;S3.2:空间划分:根据所述地铁基础数据,将每个地铁站点作为一个空间单元,划分成n个空间单元;S3.3:对于S3.2所述的每个空间单元,分别统计其在S3.1所述的m个时间段内的进站人数和出站人数,形成n*2m的地铁站点客流特征矩阵。将此矩阵记为D,它是一个包含n个对象的数据集;S3.4:接收用户动态输入的参数k(k≤n),并作为站点聚类算法的簇数;S3.5:从D中随机选取k个对象,作为k个簇各自的中心,初始化后的k个簇的中心分别记为:μ(0)=μ1(0),...,μk(0)]]>S3.6:分别计算D中各个对象j∈{1,...,n}到k个簇中心的相似度,将这些对象分别划分到最接近的中心点所在的簇,公式如下:Cluster(t)(j)←argmini||μi-xj||2S3.7:根据S3.6聚类结果,重新计算k个簇各自的中心,计算公式如下:μi(t+1)←argminμΣj:Cluster(j)=i||μ-xj||2]]>S3.8:重复步骤S3.6–S3.7,直到每个簇的中心点μi不再发生变化。其中S4具体包含如下步骤:S4.1:在地铁基础数据集上,标记每个站点所属的簇Clusteri(0≤i<k);S4.2:通过地铁乘客刷卡数据,得到每次旅程的起始站点所属的簇、目的站点所属的簇和出行所属时间段;S4.3:根据所述S4.2中的数据,计算不同时间段,不同簇之间乘客的流动模式;S4.4:绘制弦图,用户选择时间段,通过弦图对比不同簇之间的客流模式,分析人类移动规律。附图说明图1为一种基于地铁数据进行站点聚类的可视化方法的流程图;图2为本发明实施案例利用上海市地铁基础数据可视化展示地铁线路站点信息;图3为本发明实施案例利用上海市2015年4月的地铁刷卡数据做时空选择的效果图;图4为本发明实施案例完成时空选择后,展示进出站客流量对比的环形图;图5为本发明实施案例完成时空选择后,显示不同时间点具体客流量的折线图;图6为本发明实施案例利用上海市2015年4月的地铁刷卡数据聚类后得到的可视化效果图;图7为本发明实施案例利用上海市2015年4月的地铁刷卡数据动态聚类后可视化不同区域乘客流动模式的弦图。具体实施方式为了使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式作进一步的详细描述。本发明实施例提供了一种基于地铁数据进行站点聚类的可视化方法,流程如图1所示,该方法包括:S1:对截止2015年4月上海市已经开通的14条地铁线路的基础数据和2015年4月上海地铁乘客刷卡数据做预处理。地铁线路基础数据包括线路信息和站点信息,分别如下表1,表2所示。表1编号名称注释1线路编号取值为01-13或16,唯一标识一条线路2线路中文名称站点实际中文名称3线路英文名称站点实际英文名称4线路类型取值为“直线”或“环线”5线路总长以“公里”为单位6线路颜色颜色的十六进制值表2编号名称注释1车站编号唯一标识一个车站2车站中文名称站点实际中文名称3车站英文名称站点实际英文名称4所述线路编号取值为1-13或16的整数,标记已开通的14条线路5车站GPS纬度以“度”为单位6车站GPS纬度以“度”为单位7换乘标志取值为“普通站”或“换乘站”8下行序号标记站点的连接关系9车站敷设方式取值为“地下”、“地面”、“高架”地铁乘客刷卡数据的结构如下表3所示。编号名称注释1卡号唯一标识一张地铁卡2刷卡日期格式为yyyy-mm-dd3刷卡时间格式为hh:mm:ss4线路站点名称格式为x号线xx站5交易金额以“元”为单位6交易性质取值为“优惠”或“非优惠”S2:根据地铁基础数据,可视化展示上海地铁14条线路291个站点的相关信息,效果图如图2所示,并对S1所述地铁乘客刷卡数据进行时空探索,步骤如下:S2.1:用户通过交互操作,进行时间和空间维度上的过滤。其中时间上的选择包括起始日期、起始时间的选择和终止日期、终止时间的选择,可选范围为2015年4月1日到30日;空间维度上的选择包括在地图上圈选区域或绘制多边形等方式。时空过滤如图3所示。S2.2:对S2.1所述过滤结果进行可视化的展示,包括展示进出站客流量对比的环形图,如图4所示;显示不同时间点具体客流量的折线图,如图5所示。S3:使用S1所述两类数据对地铁站点客流特征建模,提取不同站点客流模式,用户通过交互式操作完成参数设置后,通过提取的客流模式和用户输入参数对地铁站点进行聚类,步骤如下:S3.1:时间划分:根据上海地铁线路运营时间和乘客出行规律,将一天划分成4个峰段,具体的划分方式如表4所示。峰段起始时间终止时间早平峰05:00:0006:59:59早高峰07:00:0008:59:59午平峰09:00:0016:59:59晚高峰17:00:0019:29:59晚平峰19:30:0023:29:59S3.2:空间划分:依据所述地铁基础数据,将每个地铁站点作为一个空间单元,划分成291个空间单元;S3.3:对于每个空间单元,分别统计其在4个峰段内的进站人数ini(0≤i≤4)和出站人数outi(0≤i≤4),形成291*8的地铁站点客流特征矩阵。将此矩阵记为D,它是一个包含291个对象的数据集。S3.4:接收用户动态选择的参数k(k≤n),为了使站点划分有意义,限制k为2-10之间的整数,将k作为站点聚类算法的簇数;S3.5:从S3.3所述客流矩阵D中随机选取k个对象,作为k个簇各自的中心,初始化后的k个簇的中心分别记为:μ(0)=μ1(0),...,μk(0)]]>S3.6:分别计算D中各个对象j∈{1,...,n}到k个簇中心的相似度,将这些对象分别划分到最接近的中心点所在的簇,公式如下:cluster(t)(j)←argmini||μi-xj||2S3.7:根据S3.6所述聚类结果,重新计算k个簇各自的中心,计算公式如下:μi(t+1)←argminμΣj:Cluster(j)=i||μ-xj||2]]>S3.8:重复步骤S3.6–S3.7,直到每个簇的中心点μi不发生变化,即完成地铁站点的划分,各个站点被分别划分到k个簇中。S4:根据聚类结果,可视化展示不同地铁站点分区之间乘客流动模式;S4.1:在地铁基础数据集上,标记每个站点所属的区域Clusteri(0≤i<k);S4.2:处理地铁乘客刷卡数据,生成一个数据库表,包含每次旅程的起始站点所属区域、目的站点所属区域和出行所属时间峰段;S4.3:统计相同时间峰段内,不同区域之间乘客的流动模式。S4.4:根据S3所述聚类结果,对S2.2所述可视化展示做进一步处理,即依据站点划分结果将属于同一区域的站点做相同的颜色标记,如图6所示;S4.5:根据S3所述聚类结果和S4.3所述乘客流动模式,对S3.1所述4个时间段分别绘制弦图,用户可以交互式的选择对比不同时间段、不同区域之间客流的模式,当发生交互事件时,弦图将显示不同区域之间的客流信息,如图7所示。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1