一种为不确定图的决策查询清洗的数据清洗方法与流程
本发明属于数据库领域,特别涉及为不确定图的决策查询清洗边的数据清洗技术。
背景技术:
在实际应用中,例如社交网络、知识图谱和蛋白质相互作用网络,图数据库是一个重要的数据存储库应用。但是,这些图中的数据会因为各种因素的影响而产生不确定性。因此,图中的每条边是否存在是有一定概率的。
有许多文献旨在研究处理在不确定图上的查询。他们假设图中的边是相互独立的,并且采用可能子图模型计算查询结果。考虑每条边是否存在,不确定图可以产生2^n个可能子图。每个可能子图是一个概率确定图,查询结果由所有子图中的结果组成。然而通常由于边的不确定性,结果是模糊的。比如,一个用户提出一个问题“点s和点t存在两条关系吗?”,通过计算所有的子图,结果是“YES”的概率是0.5,反之“NO”的概率也是0.5。用户不会满意这样的结果,因为这个结果不能为进一步的决策提供任何信息。
数据清洗是一种通过减少边的不确定性来减少查询结果模糊性的广泛使用的方法。如果可以通过数据清洗将查询结果更接近于0或1,结果的确定性就会比之前更明确。
众包平台的兴起促进了数据清洗需求的增长。有研究表明,在自然语言处理、实体解析等众多领域,人的表现会比机器更好,并且当任务被分成多个简单的子任务时,人的判断会更准确。换句话说,对于一个不确定图,清洗单个边会比在直接清洗查询结果更好。然而,如果将不确定图中所有的边都通过众包清洗,则既费时间又费钱,所以应该限制被选择清洗的边的数量。因此,亟需一种数据清洗方法决定如何选择被清洗的边使得结果质量提高最大。
技术实现要素:
本发明提出了一种为不确定图的决策查询清洗边的数据清洗方法,包括如下步骤:
步骤一:定义不确定图、可能子图、决策查询、查询结果质量及对于不确定图和多条边,计算每条边的值;
步骤二:从所述不确定图中选取值最大的边;
步骤三:全图清洗单边,直至找到查询结果质量数学期望最大的边,获得使所述数学期望最大的边。
本发明提出的所述为不确定图的决策查询清洗边的数据清洗方法中,所述值以如下公式(1)表示:
式(1)中,e表示边,表示通过所述边的路径中至少有一条路径连通而所有不经过所述边的路径都不连通的概率,Pr(G)表示可能子图的概率,G(εe,εe)表示所有满足以上这种条件的概率子图集合,p(e)表示边e存在的概率。
本发明提出的所述为不确定图的决策查询清洗边的数据清洗方法中,所述步骤二按如下步骤进行:
步骤2a:将边按存在概率p(e)升序排列;
步骤2b:上界U(e)按降序排列;
步骤2c:遍历这两个队列,计算
步骤2d:如果当前访问的边e的比大,更新和拥有最大的边;停止条件是
步骤2f:按边的概率升序排列,将计算边的上界U(e)降序排列,同时遍历两个队列计算当前如果当前大于则更新和拥有最大的边,搜索的停止条件是
本发明提出的所述为不确定图的决策查询清洗边的数据清洗方法中,所述步骤三按如下步骤进行:
步骤3a.使用上界帮助剪枝,
步骤3b.对于每条边,计算清洗边之后全图质量提高的上界UQ;
步骤3c.将边根据上界UQ的值排序。对于每条被访问的边,使用蒙特卡洛计算全图质量提高的数学期望EQ,并且维护一个EQmax记录当前最大的数学期望EQ;
步骤3d.如果UQ小于EQmax,搜索停止。
本发明的有益效果在于:本发明中使用蒙特卡洛计算子图概率,将无法求得的精确解转化为可计算的近似解,本发明提供的不确定图的决策查询清洗边的方法能够高效地提高不确定图的决策查询结果的质量。
附图说明
图1表示本发明数据清洗方法的流程示意图。
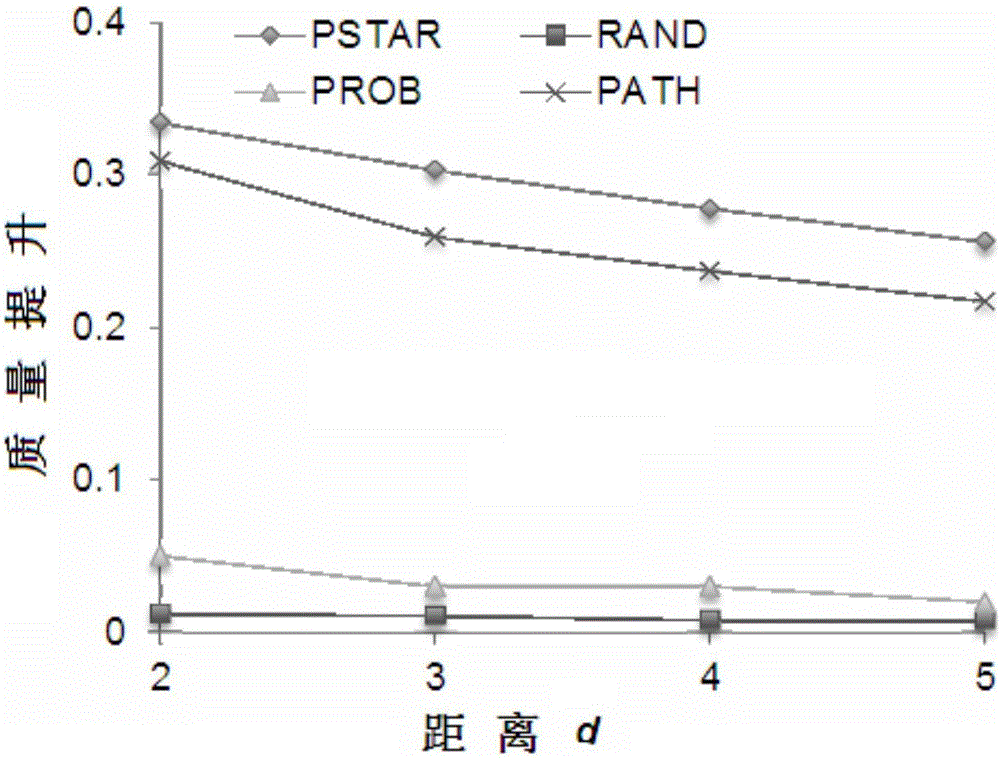
图2是数据清洗结果对比图。
具体实施方式
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。
本发明主要包括以下步骤:
步骤一:定义决策查询的质量
定义1:(不确定图)设g=(V,E,P,L)是一个无向不确定图,其中,V是顶点集,E是边集,P是每条边的概率,L是权重。
定义2:(可能子图)G=(VG,GG)是g的可能子图,如果并且VG=V。根据定义,一个不确定图有2^n个可能子图(n是边的数量)。可能子图的概率是
定义3:(不确定图的决策查询)在不确定图g中的决策查询q,用Rq(G)来表示。
当查询结果是”YES”的时候,Iq(G)=1,否则Iq(G)=0。
定义4:(决策查询的质量)对于决策查询q,不确定图g,查询结果质量是
Qq(g)=h(Rq(g))+h(1-Rq(g)),h(x)=-xlogx
定义5:(边清洗问题)对于不确定图g和n条边,边清洗问题是找到一个边集E,可以使EΔQ(g,Ec)最大。
定理1:设与ΔQ(g,e)正相关。
在定理1中证明了与质量提高值成正相关,因此问题就等价于找到有最大的边。
步骤二:找到有最大的边
根据排序。根据的定义,有两个主要的影响因素p(e)和找边最直接的方法是计算所有边的并排序。这样的计算花费了太多的计算单元,是非常没有效率的。算法1介绍了一种有效的排序方法。主要思想是根据边的上界而非精确值来对边进行排序。这个上界计算时间是线性的。特别的,这个算法与top-k的TA算法相近,它将边按降序排列,上界三升序排列。同时遍历这两个队列,计算如果当前访问的边e的比大,更新和拥有最大的边。停止条件是
上界U(e)。本发明创新地用蒙特卡洛获得子图Rq(g),将无法求得的精确解转化为可计算的近似解。
算法1找到有最大的边
输入:g,起始点s,终点t,d跳
输出:eh:有最大的边
算法描述:
相对于现有技术,步骤二找到了搜索停止的上界值。这些改进点所带来的有益效果是避免计算出所有之后再排序找出最大值。
步骤三:全图清洗单边。最终的目的是清洗边,提高整幅图的质量。与算法1相似,1.使用上界帮助剪枝(去除一定不可能的边);2.对于每条边,计算清洗边e后,全图质量提高的上界UQ(e);3.将边根据UQ的值排序。对于每条被访问的边,使用蒙特卡洛计算全图质量提高的数学期望EQ,并且维护一个EQmax记录当前最大的EQ。如果UQ小于EQmax,搜索停止。
UQ(e)。UQ(e)=Q(g)-EQ(e),EQ(e)=∑q∈Qw(q)×(p(e)Qq(ge=1)+(1-p(e))Qq(ge=0))
算法2全图清洗单边
输入:g,d,n,Q
输出:eh:能够使全图质量提高最大的边
算法2需要找出清洗后可以使全图质量提高最大的那条边。遍历每条边,计算UQ(e)并根据它降序排序图中的边。计算图中最大的EQ。遍历每条边,如果当前最大的数学期望EQ大于上界UQ(e),则停止搜索。遍历全图中的每个查询,找到最大的EQ,EQmax对应的边就是需要找的边。
图2显示的本实施例中数据清洗对比实验图。本例中采用的数据集KDD-cup的Co-author数据集。图中以PSTAR表示本发明数据清洗方法,RAND表示现有随机算法,PROB表示简单依据边的概率是否接近0.5的算法,PATH表示现有用简单的罗列所有路径并叠加路径概率的方法。其中,实验的度量是质量提升量,随着改变查询中的距离d,可以看出本发明算法(PSTAR)比随机算法(RAND)和简单依据边的概率是否接近0.5的算法(PROB)在质量提升量上分别提高了10倍和5倍以上,比用简单的罗列所有路径并叠加路径概率的方法(PATH)提升了近20%。
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
- 还没有人留言评论。精彩留言会获得点赞!