一种复杂表格及其内部手写数字识别方法与流程
本发明属于图像识别领域,尤其涉及一种复杂表格及其内部手写数字识别方法。
背景技术:
复杂表格及其内部手写数字识别属于图像识别应用领域的重要分支。由于一些因素的限制,需要通过手写书写方式记录数据,然后录入为电子版进行存储。这种记录方式转化为电子版的过程,是人脑理解图像与计算机识别图像的过程,若采用自动识别方式录入必提高生产效率,在生产和生活中应用及需求广泛。
针对Microsoft Excel(windows表格工具)或Numbers For Mac(mac表格工具)制作的由密集的行、列或行、列合并、拆分构成的表格框架(称为模板表格),打印表格框架填入较多手写数字后扫描成为手写电子表格,通过本方法实现表格及其内部手写数字识别,将手写数据录入计算机成为电子版数据(称为电子手写表格)进行存储。
目前解决表格及手写数字识别的方法有很多。公开号为CN105589841A的专利:将表标题、表格线及表格字符排布特点视为表格三大特征,采用区域并行生长的思想能在多表并存一页的复杂版面中准确定位表格。但是该方法主要针对没有倾斜、畸变、结构较简单的电子表格识别,对于复杂结构电子手写表格不适用。公开号为CN104992188A的专利:采用基于t混合因子分析的分布式训练和识别方式,对每个节点采集到的手写数字进行特征提取,而后对用于训练,接着各节点基于自身的训练数据计算局部统计量并广播给其邻居节点,同时各节点根据收到的来自所有邻居节点的局部统计量,计算联合统计量,并基于该联合统计量估计出t混合因子分析中的各个参数,完成分布式训练过程;测试数据可以输入任一节点,计算其关于训练好的每一个数字对应的tMFA的对数似然值,将最大对数似然值对应的数字作为识别结果。该方法训练及识别过程复杂度较高,实际使用时实时性不强。公开号为CN105320961A的专利:基于卷积神经网络和支持向量机的手写数字识别模型能深度地描述样本数据和期望数据的相关性,能从原始的数据中自动地学习图像特征,具有很好的决策平面,对数字模式分类的区分能力很强。然而支持向量机主要用于二分类问题,对于0-9这10类数字识别需要构造多个分类器来组合的这些两类分类器。
技术实现要素:
本发明目的在于解决现有技术不足,提出了一种对复杂结构表格及其内部手写数字识别的方法,利用该方法可解决工程电子手写表格及其内部数字识别录入问题。
为解决上述问题,本发明采用如下的技术方案:
一种复杂表格及其内部手写数字识别方法,包括以下步骤:
步骤1:对模板表格进行直线检测、角点检测,以解析扫描表格中的每个单元格结构间的拓扑关系,实现模板表格结构描述;
步骤2:对纸质手写表格转成的电子手写表格进行预处理,即对纸质手写表格经扫描转成的电子手写表格进行位置标定、倾斜矫正、噪点剔除预处理,使电子手写表格结构与步骤1得到模板表格结构一致;
步骤3:对步骤2中电子手写表格的每个单元格进行去除边线处理;
步骤4:对步骤3得到的单元格,将其中的数字图像提取出来,对字符分割预处理及分割成独立字符;
步骤5:对大量数字文本提取特征并训练得到分类器,将步骤4得到的独立字符送入分类器进行识别,得到识别结果;
步骤6:对步骤5得到的手写字符进行后处理,包括对于小数点、写字符常出现特殊情况的字符进行特殊处理,最后将识别出来的数字自动录入到电子表格对应位置。
作为优选,所述步骤1实现模板表格单元格结构描述具体如下:针对复杂结构表格模版,对其进行霍夫变换实现线段检测,采用Shi-Tomasi方法进行角点检测实现行及列分类排序,根据设定的线段、行角点、列角点统计规则解析表格拓扑关系,实现模板表格结构描述。
作为优选,所述步骤2对纸质手写表格转成的电子手写表格进行预处理:将对纸质手写表格经扫描转成的电子手写表格进行霍夫变换,对整张表格进行外轮廓提取,并求得外轮廓的外接矩形即表格的最外围边线,任取一条作为矫正基准线与模板表格对应边线进行匹配,通过旋转、缩放使模板表格结构与电子手写表格的结构一致。
作为优选,所述步骤3对每个单元格进行处理具体如下:通过步骤2进行模版适配,得到电子手写表格中每个单元格的准确位置,再次通过边界及角点检测提取感兴趣的区域ROI(region ofinterest),最终得到所要提取的单元格。
作为优选,所述步骤4提取单元格中数字图像具体如下:对步骤3得到的ROI单元格采取去除单元格边线、放大图像、二值化处理方式得到待识别数字的ROI区域,通过本文框方式将单个的字符取出并按取出顺序排列。
作为优选,所述步骤5对数字文本提取特征并训练得到分类器具体如下:采用MNIST数字字符集作为训练样本,对字符集每个数字集筛选出字符规则的3000个样本,采用轮廓法提取出每个样本的字符;同时对10个字符总共30000个样本采用KNN算法进行训练,得到分类器,并利用该分类器对步骤4提取的数字进行识别。
作为优选,所述步骤6对手写字符进行后处理具体为:
对于小数点的处理方式如下:若得到的识别自负的数组长度大于1,则可能存在小数点,首先选出最小高度minh的图像,并求其余待识别字符的图像平均高度aveh,若minh<aveh/2,则认为是小数点;
对于手写体中数字5的处理方式如下:数字5必须封口,若不封口,采用屏蔽处理,即若提取字符的图像满足:width>2*height,则屏蔽该字符图像,其中,width为字符图像的宽度,height为字符图像的高度。
本发明的优点及有益效果如下:
通过这种方式得到了较好的识别效果,其中借助工程表格的模板成功的还原了表格的结构,随后在取出单元格后,能基本完好的排除误差,基本去除表格边线的干扰,提取有用的待识别字符的信息。并采用轮廓算法提取出单个字符。随后在字符识别上,对待识别字符和样本字符采用了同样的位置归一化的方法,利用此简单的方法极大的提高了分类器的识别率。最终将得到了较为完美的识别结果,填入识别导出后的excel电子表格。另外,对多分类问题本发明采用简单且易实现的KNN算法,同时对于手写数字中的小数点、个别字符书写不规范等特殊情况具有较好的识别能力。
附图说明
图1为一种复杂表格及其内部手写数字识别方法系统结构图;
图2为一种复杂表格及其内部手写数字识别方法实现流程图;
图3为模板表格角点集;
图4为模板表格去燥后规范角点集;
图5(a)为电子手写表格单元格提取结果;
图5(b)为电子手写表格重新提取包含4周边线的单元格提取结果;
图5(c)为电子手写表格单元格去除边线结果;
图6(a)为电子手写表格待识别文本图像;
图6(b)为电子手写表格字符外接矩形;
图6(c)为电子手写表格去除单个待识别字符;
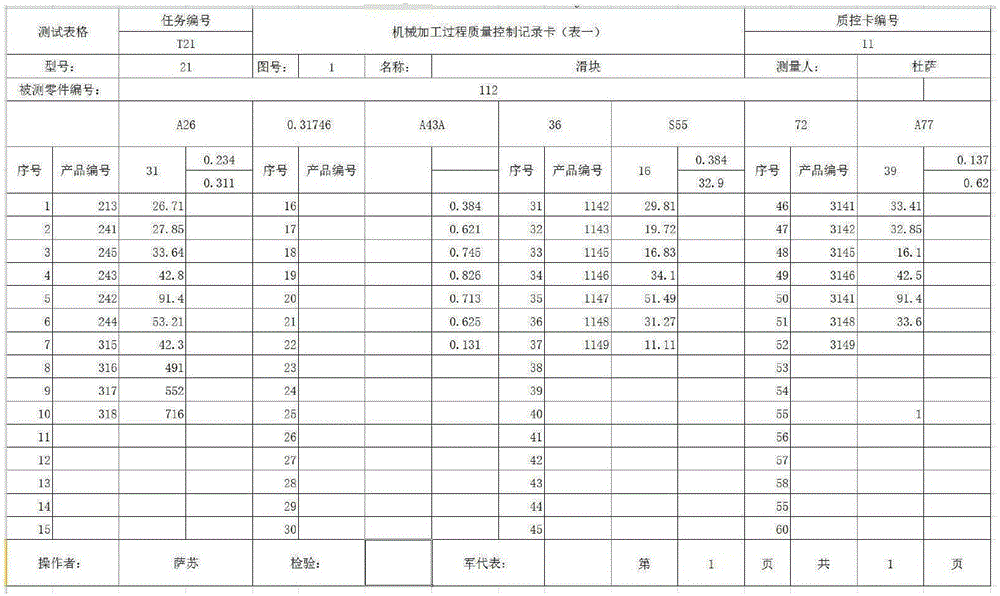
图7为手写电子表格;
图8为识别结果导入模板后的电子表格。
具体实施方式
为使本发明的技术方案、使用方法更加明确,下面结合附图对本发明作进一步详细说明。
本发明提供一种复杂表格及其内部手写数字识别方法,如图1所示,包括如下步骤:
步骤1:模板表格单元格结构描述;
1-1.直线检测
表格中的角点必然与直线构成线段。为此,将该图像二值化,检测直线。由于全局霍夫变换收到噪点影响会得到直线集合非常杂乱,本发明采用积累霍夫变换。设置滑窗为、步长为t,选取适当阈值,设置的检测最短线段长度为,进行霍夫变换,得到线段集。判断L中的直线位置是否在误差范围e内,是则连接,否则不相连。
1-2.角点检测
将模版图像进行Shi-tomasi角点检测,得到图中全部的角点集记为,并对按照行y轴坐标)、列x轴坐标从小到大排序。角点集如图3所示,可以看到存在一定的噪点,对得到的角点集进行行分类horizoncorners和列分类verticalcorners。由于是复杂工程表格,行或列的角点数一般不少于一定值,设行上不足m个点的角点全部为噪点,予以删除;同理,列上不足n个点的列角点全部删除,最终可以得到规范的角点集Corner,如图4所示。
1-3.模板表格定位及结构描述
模板表格定位及结构描述,即通过一组参数标定单元格位置。本方法采用5个参数描述模板表格的单元格位置,它们分别是行y(int类型),列x(int类型),几行合并rowMerge(int类型),几列合并colMerge(int类型),单元格的范围rect(Rect类型)。以行分类位基准进行定位,从第一个点开始遍历,记录Corner中的点位在行、列的位置,以及该点是否与下一点有直线相连(直线检测算法见1-1)来判断是否是单元格,并存入rect中。
步骤2:对纸质手写表格转成的电子手写表格进行预处理;
2-1.电子手写表格倾斜矫正;
在有大量文字信息的表格中,图表中难免会有噪点存在,靠近表格边线的文字会干扰表格矫正基准线的提取,本方法采用基于外轮廓的倾斜矫正。通过霍夫变换求得外轮廓的外接矩形,任取一条作为标定线,若标定线靠近y轴,则将图像以y轴为基准参考线,旋转一定角度斜角做倾斜矫正。同理,若靠近x轴,则以x轴为基准参考线做倾斜矫正。
2-2.模版适配
模版适配首先调整电子手写表格与模版表格大小一致,其次是个电子手写表格与模版表格位置信息一致。调整大小一致:扫描图像过程中存在诸多不可避免的因素导致模版图像与表格图像的大小不一致,本方法采用对角线算法调整表格大小。调整二者的位置信息一致:对调整大小一致的图像分别扩展左边和上边K个像素进行角点检测得到对角点,本发明只采用最左上的对角点lp(LX,LY),然后提取roi区域的范围是Rect rect(LX-X1,LY-Y1,X2+,Y2+)。完成模板适配,从而得到可以提取单元格的表格区域。
步骤3:对每个单元格进行处理;
步骤2提取到的电子手写表格单元格还存在表格边线,同时得到的图像较小可能较小(rows和cols均小于200),本方法采用递归算法去除表格边线。具体思路:对表格四周设置边线检测范围,即只在这个范围内判断是否存在边线;分别设置上、下、左、右一次边线检测的roi区域,若有一边没有检测到边线,便对此位置在原表格图像中扩充wide个像素点重新提取识别区域,并再次重新提取的单元格,直到4条边都被检测到,对4条边线进行去除。
步骤4:提取单元格中数字图像;
将步骤3得到仅含数字的单元格图像经过放大、采用大律法求阈值进行二值化、图像取反处理,以便从单元格中取出并对其排序。
步骤5:对数字文本提取特征并训练得到分类器;
决策树(Decision Trees)、人工神经网络、遗传算法、支持向量机、朴素贝叶斯、KNN算法等分类算法均可以实现手写字符的分类问题,具体采用何种分类算法不作为本发明的重点。本发明的重点是:采用简单、有效,重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)的训练方法,将具有相对较高识别正确了的结果填入复杂模板表格中。因此,本发明采用MNIST数字字符集,KNN算法训练分类器。
步骤6:对手写字符进行后处理;
识别出数字后,还存在小数点及数字5处理不完备的情况。
进一步的,对于小数点,利用小数点图像高度明显小于数字图像,采用如下方式处理:若得到的识别自负的数组长度大于1,则可能存在小数点,则首先选出最小高度minh的图像,并求其余待识别字符的图像平均高度aveh,若minh<(aveh/2),则认为是小数点。
进一步的,手写体中5常常会出现上方一横不封口,依据本算法工程表格的严格要求和本文轮廓提取字符的算法要求,5必须封口,若不封口,为避免多识别出一个字符,则通过提取字符的图像满足:width>2*height,屏蔽该字符图像,其中,width为字符图像的宽度,height为字符图像的高度。
本发明以一个具体的应用实例来描述。如图2所示,实现步骤如下:
步骤1:模板表格单元格结构描述
对于一幅共有298个单元格的表格模版打印扫描后,形成标准的模版表格图片。将该图像二值化,设置滑窗为、步长为t,选取适当阈值,设置的检测最短线段长度为,进行霍夫变换,得到线段集。判断L中的直线位置是否在误差范围内,是则连接,否则不相连。
将该图像进行Shi-tomasi角点检测,得到初步角点集。对角点集去燥后,排序规则为:两角点若不在同一个水平线上(两角点的y值相减小于10则认为在同一水平线上),则y坐标小的排序靠前,若在同一水平线上,则比较两者的垂直距离,若两者不在同一垂直线上(两角点的x值相减小于10则认为在同一垂直线上),则x坐标小的排序靠前。最后设置二维动态数组存储结果,维数按水平线从小到大排列,同一维内的一维数组按照垂直距离从小到大排列存储,得到规范角点集Corner。
设置5个参数标定单元格,分别是:行y(int类型),列x(int类型),几行合并rowMerge(int类型),几列合并colMerge(int类型),单元格的范围rect(Rect类型)。设置一个与列分类verticalcorners的二维动态数组维数和大小一致的指针数组verlink,将列分类结果分别指向筛选后的角点集Corner得到verlink,同时记录Corner中的点位于哪一列,以及记录该点是否与下一点有直线相连(直线检测算法见1-2);而后再按照同样的思路进行行分类,将列分类结果分别指向筛选后的角点集Corner得到horilink,记录Corner中的点位于哪一行,以及该点与该行的下一点是否有直线相连。进一步的,借助上面的数组进行单元格定位,以行分类位基准进行定位,从第一个点开始遍历,各点判断方式如下:
1.首先判断某点p1是否在行上有下一点q1相连,若是进行步骤2,不是结束此次循环。
2.判断该点p1与该列下一点p2是否相连,若是则进行步骤3,不是结束此次循环。
3.则判断q1是否在列上有下一点q2相连,若是则进行步骤4,不是则进入步骤5。
4.循环判断p2是否能够经过有限次数连接到q2,若是则定位一个单元格,将相应数据计算压入记录表格的动态数组,跳出循环;若不是进入步骤5。
5.判断p2与q2行数大小,若p2.row>q2.row,则q2继续寻找在列上下一个相连的点,若p2.row=q2.row,p2与q2同时寻找下一个在列上相连的点,若p2.row<q2.row,则p2继续寻找在列上下一个相连的点。
步骤2:对纸质手写表格转成的电子表格进行预处理;
对整张电子手写表格进行全局霍夫变换,提取外轮廓并求得轮廓外接矩形,选取标定线,根据基准参考线进行倾斜矫正。然后进行模版适配,首先调整表格大小与模版大小一致,其次是个表格图像的位置信息与模版图像的位置信息一致。
进一步的,调整电子手写表格与模版表格大小一致,具体如下:
1.对模版表格角点行分类后,分别对第一行和最后一行点的y坐标求平均值得到Y1,Y2;再对模版表格角点列分类,分别对第一列角点和最后一列角点x坐标求平均,得到X1,X2;最终的到模版的对角点,p1(X1,Y1),p2(X2,Y2)。
2.对电子手写表格做角点检测,并进行做相同的行列分类处理,同样得到对角坐标q1(TX1,TY1),q2(TX2,TY2)。
3.由于放缩往往是同比放缩,故分别求水平放缩比例=(X2-X1)/(TX2-TX1);垂直放缩比例=(Y2-Y1)/(TY2-TY1),对二值求平均得到scale,按此比例放缩,使其大小一致。
进一步的,调整电子手写表格与模板表格使其位置一致,以便在模版中得到的矩形区域。可以在表格中准确的得到相应的位置,以上缩放操作后,对放缩后待识别图像扩展边界区域(本文分别扩展左边和上边300像素)进行角点检测等一系列同上处理得到对角点,只采用最左上的对角点lp(LX,LY),然后提取roi区域的范围是Rect rect(LX-X1,LY-Y1,X2+100,Y2+100),从而得到可以提取单元格的表格区域。
步骤3:对每个单元格进行处理;
上一步得到的单元格存在表格边线如图5(a),而且得到的图像较小(rows和cols均小于200),对此,本发明文通过以下方式去除表格边线:
3-1.对表格四周设置边线检测范围。本例设置的范围是R,即只在这个范围内判断是否存在边线,并同时设置4个大小的标志数组,用于记录是否从上下左右检测到边线,初始化为false,设置检测边线的区间宽度w,和轮询判别的宽度wide,满足w+wide=10。
3-2.设置一次边线检测的roi区域分别为:
lineROI[0]=Mat(textarea,Rect(0,j,textarea.cols,w));//上边
lineROI[1]=Mat(textarea,Rect(j,0,w,textarea.rows));//左边
lineROI[2]=Mat(textarea,Rect(textarea.cols-w-j,0,w,textarea.rows));//右边
lineROI[3]=Mat(textarea,Rect(0,textarea.rows-w-j,textarea.cols,w));//下边
其中j的范围是[0,wide],即轮询3-1中设置的大小范围,textarea为待处理的单元格图像,本文设置的roi宽度为w。
此步骤中有两种判别方式,可酌情选取其中一种。第一种:首先判断此位置的标志位(即检测到了边线),为false,便在此区域中直线检测算法(见上文)检测是否存在边线,若存在,则用背景色(白色)覆盖此roi区域和下一个roi区域,标志次位置的标志位为true(确保再次循环到此位置不再执行检测算法),如此循环wide次;第二种:同样循环检测四个边线是否存在边线,检测到边线后先不处理,而是设置标志位记录location=j(大于0小于wide)位置已经首先检测到边线,继续进行循环检测,直到再次检测不到边线后跳出循环,再次覆盖记录,即location=j。四个位置全部记录到后,统一对[0,location+temp]区域置白,其中temp为适当的扩充区域。本例采取第二种方式。
4.若有一边没有检测到边线,便对此位置在原表格图像中扩充wide个像素点重新提取识别区域,得到图5(b),并再次提取单元格后执行此步骤,直到4条边都被检测到并去除成功,得到5(c)。
步骤4:提取单元格中数字图像;
将图像放大二倍,二值化(采用大律法求阈值),图像取反后成功获得待识别的文本图像,如图6(a)所示。对单元格单个字符提取并排序,方法如下:
4-1.对图6(a)图像进行外轮廓检测。
4-2.得到检测到的外轮廓的外接矩形(往往是一个倾斜的矩形),如图6(b)。
4-3.对4-2检测到外轮廓矩形旋转成正方位的外接矩形,以方便设置roi,取出带识别字符如图6(c)。
4-4.根据步骤4-3可以得到所有字符的roi,根据这些roi区域的左上角x的坐标大小进行排序,并依次存储这些待识别的字符样本。
4-5.训练的样本为28x28的图像,且训练样本的字符周围都有一定留黑的区域。故接下来要将字符预处理得到可以用来识别的图片,首先将字符放缩,然后四周扩充黑色边界。放缩方式为:
a.比较字符图片的rows和cols,得到大的一方记为长,小的一方记为宽。
b.将长放缩至22,并计算放缩比例为:长/22。
c.将宽按照放缩比例放缩,即:宽=宽/(长/22),然后为保证宽为偶数,做如下处理:宽=(宽/2)*2。
d.做留白处理,将长方向两端扩冲5个像素,宽方向的两端扩冲(22-宽)/2的像素。
经过如上处理,可保证图片放缩成与训练样本特征和大小一致的待识别样本,并可保证在放缩过程中使得字符不变形。然后进入字符识别分类器。
步骤5:对数字文本提取特征并训练得到分类器;
文本识别采用MNIST数字字符集,对其字符集每个数字集筛选出字符规则的3000个样本,采用轮廓法提取出每个样本的字符,并采用与待识别字符同样的方法处理该字符,为使得其字符的位置信息一致,为后续序列化做准备,借此简单方式,代替复杂的特征提取过程。完成上述过程后,本发明对总共30000个样本采用KNN算法进行训练,得到分类器,用于识别数字。
步骤6:对手写字符进行后处理;
对于工程表格中常常会有小数点,若得到的识别自负的数组长度大于1,则可能存在小数点,本发明首先选出最小高度minh的图像,并求其余待识别字符的图像平均高度aveh,若minh<(aveh/2),则认为是小数点。
依据本算法工程表格的严格要求和本文轮廓提取字符的算法要求,5必须封口,若不封口,为避免多识别出一个字符,本方法做如下屏蔽处理:若提取字符的图像满足:width>2*height,则屏蔽该字符图像,其中,width为字符图像的宽度,height为字符图像的高度。
通过这种方式得到了较好的识别效果,其中借助工程表格的模板成功的还原了表格的结构,随后在取出单元格后,基本完好的排除误差,基本去除表格边线的干扰,提取有用的待识别字符的信息。并采用轮廓算法提取出单个字符。随后在字符识别上,对待识别字符和样本字符采用了同样的位置归一化的方法,利用此简单的方法极大的提高了分类器的识别率。最终得到了较为完美的识别结果如下所示,图7是手写电子表格,图8识别结果导入模板后的电子表格。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!