一种基于内存的频繁模式挖掘方法与流程
本发明属于存储器技术领域,具体涉及一种基于内存的频繁模式挖掘方法。
背景技术:
随着计算机科技的日益成熟,数据分析自20世纪确立以来有了极大的发展。数据分析能够在海量数据中发现并提取出感兴趣的项目,从而给决策机构提供指导意见。机器学习和数据挖掘能够揭示数据背后隐藏的信息,已成为是数据分析的关键技术。
在数据挖掘领域中,发现数据集中的频繁项或频繁模式是数据挖掘研究中的一个重要课题,它是相关性分析、序列模式、因果关系、显露模式等许多重要数据挖掘任务的基础。目前有诸如Apriori和FP-tree等技术来处理频繁模式挖掘问题。
由于基于内存的频繁模式挖掘方法的条件是,被挖掘数据和数据元是保存在字节寻址寄存器上的,而DRAM要求需要持续供电来保持数据,因此,能效和持久性可能成为数据挖掘系统中的关键设计问题。为了解决该类问题,在基于内存的数据分析中如相变存储器(PCM)等非易失性存储器(NVM)由于其出色的非易失性和能效性能,通常被认为是DRAM的优秀替代品。但使用NVM作为主存又存在以下的问题:一是对NVM的读写操作时间差异比较大,读操作通常比写操作所耗费的时间和能量更多;二是NVM写操作次数有限,不均匀的写操作通常会加速整块NVM失效。正是由于缺乏对NVM本质特点的考虑,目前在NVM上进行的数据挖掘与机器学习算法严重影响存储系统的性能和寿命。
现有技术采用一种叫做FP-tree算法的技术方案,它是对Apriori算法的改进,将频繁模式的关键信息压缩为频繁模式树(FP-tree)的结构,以减少Apriori算法中开销巨大的候补项,从而解决了Apriori算法的性能瓶颈。简单地说,FP-tree算法是在不生成候选项的情况下,完成Apriori算法的功能。
J. Han, J. Pei, and Y. Yin. Mining frequent patterns without candidate generation. ACM SIGMOD International Conference on Management of Data (SIGMOD’00), 29(2):1–12, May 2000.(J. Han, J. Pei, and Y. Yin. “不产生候选项的频繁模式挖掘”,数据管理国际会议, 29(2):1–12, 2000.05.)记载了FP-tree算法的步骤如下:
(1) 扫描整个事务数据库D一次,获得D中所包含的全部项的支持度计数,排除支持度计数值小于阈值的项,剩余的项即为频繁项,对频繁项按其支持度计数降序排列得到一个列表L;
(2) 创建FP-tree的根节点T,以“null”标记。再次扫描事务数据库。对D中每个事务,将其中的频繁项选出并按L中的次序排序。设排序后的频繁项表为[p|P],其中p是第一个频繁项,而P是剩余的频繁项。调用insert_tree([p|P],T)。insert_tree([p|P],T)过程执行情况如下:如果T有子女N使N .item_name=p.item_name,则N的计数增加1;否则创建一个新结点N,将其计数设置为1,链接到它的父结点T。如果P非空,递归地调用insert_tree(P,N)。
经过以上步骤,就建立好了一棵完整的FP-tree。最后根据建立好的FP-tree由下往上循序进行挖掘,即可产生所需要的频繁模式。简言之可描述为利用事务数据库中的信息构造FP-tree,然后从FP-tree中挖掘频繁模式。其核心思想是直接压缩数据库构建一个频繁模式树,然后通过这棵树生成关联规则。
图1给出了FP-tree的构建过程示例。图1(a)为数据库,其中“交易ID”为每一条交易记录的序号,“项目”为每一条交易记录中的所有项,“排序后的项”为按照每个项出现次数降序排列后的项;首先建立一个标签为null的结点作为整个频繁模式树的根节点,扫描第一条交易记录后,建立结点a,并令结点a的计数域的值为1,表明项目a出现1次,如图1(b)所示;扫描第二条交易记录后,依次建立结点b,c,d,其结点计数域的值均为1,表明项目b,c,d也分别出现1次,如图1(c)所示;依次扫描完数据库中所有交易记录后,建立的完整的FP-tree如图1(d)所示,其中各字母表示数据库中的项,字母后的数字表示计数域中存储的值,即为该项在数据库中出现的次数。
但FP-tree算法存在的问题有:在构建频繁模式树的过程中,每扫描一条事务中的一个项,都要对FP-tree进行更新操作,即对FP-tree中对应项的结点计数域进行写操作,这就导致了大量重复的写操作,内存开销巨大;且越靠近根节点的写操作越多,密集的大量写操作会导致NVM的使用寿命减少。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的技术问题就是提供一种基于内存的频繁模式挖掘方法,它能减少在构建频繁模式树过程中对NVM的写操作,能避免密集的大量写操作,达到延长NVM寿命的目的
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括以下步骤:
步骤1,构建频繁模式初始树
1)、依次扫描数据库中的每一条交易记录,获得数据库中所包含的全部项的支持度计数,排除支持度计数值小于阈值的项,剩余的项即为频繁项,对频繁项按其支持度计数降序排列得到一个列表L;
2)、创建频繁模式树的根结点T,以“null”标记;
3)、再次扫描数据库,将读取的每条事务中的频繁项选出并按L中的次序排序;排序后以null为根结点构建一条频繁模式树的路径,只对路径上位于最末的结点的计数加1,路径上的其他结点的计数保持不变;依次扫描完整个数据库中所有事务后获得频繁模式初始树;
步骤2,用深度优先搜索算法对频繁模式初始树依次进行遍历,遍历结点的计数器值为该结点本身的值加上其所有孩子结点的值。
本发明的频繁模式树中所有元素的计数域的值即为该元素在整个数据库中出现的次数,与现有技术的频繁模式挖掘算法构建的树一样。
与现有技术相比,本发明的技术效果是:
本发明不再对当前整条事务中的所有项的结点的计数域进行更新操作,避免了在构建频繁模式树过程中的大量重复的写操作,减少对NVM的写操作,能快速的构建频繁模式树;且能减少对靠近根结点的结点计数域的大量密集的写操作,延长了NVM寿命。
附图说明
本发明的附图说明如下:
图1为背景技术中的频繁模式树的构建示例图;
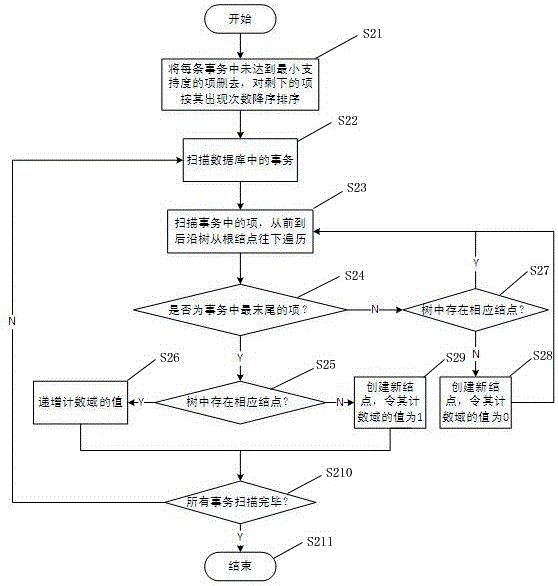
图2为本发明构建频繁模式初始树的流程图;
图3为本发明的频繁模式树的构建示例图;
图4为试验中读操作测试的对比图;
图5为试验中写操作测试的对比图;
图6为试验中构建树时间测试的对比图;
图7为试验中PCM寿命测试的对比图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明的输入是数据库和最小支持度阈值σ,输出是FP-tree。
本发明包括以下步骤:
步骤1,构建频繁模式初始树
1)、依次扫描数据库中的每一条交易记录,获得数据库中所包含的全部项的支持度计数,排除支持度计数值小于阈值的项,剩余的项即为频繁项,对频繁项按其支持度计数降序排列得到一个列表L;
2)、创建频繁模式树的根结点T,以“null”标记;
3)、再次扫描数据库,将读取的每条事务中的频繁项选出并按L中的次序排序;排序后以null为根结点构建一条频繁模式树的路径,只对路径上位于最末的结点的计数加1,路径上的其他结点的计数保持不变;依次扫描完整个数据库中所有事务后获得频繁模式初始树。
图2为本发明构建频繁模式初始树的流程图,其流程如下:
在步骤S21,将每个事务中未达到最小支持度的项删去,对剩下的项按其出现次数降序排序;
在步骤S22,依次扫描数据库中的事务;
在步骤S23,依次扫描事务中的每一个项,从前到后沿树从根结点往下遍历;
在步骤S24,判断当前项是否为事务中最末尾的项,若是,执行步骤S25;如不是,则执行步骤S27;
在步骤S25,判断树中是否存在相应结点,如存在,则执行步骤S26;如不存在,则执行步骤S29;
在步骤S26,递增该项中计数域的值;然后转至步骤S210;
在步骤S27,判断树中是否存在相应结点,如存在,则返回步骤S23;如不存在,则执行步骤S28;
在步骤S28,创建新结点,令其计数域的值为0;然后回步骤S23;
在步骤S29,创建新结点,令其计数域的值为1;然后转至步骤S210;
在步骤S210,判断所有事务是否扫描完毕,若未扫描完毕,则返回步骤S22;若扫描完毕,则执行步骤S211
在步骤S211,程序结束;
步骤2,构建完整的频繁模式树
用深度优先搜索算法对频繁模式初始树依次进行遍历,遍历结点的计数器值为该结点本身的值加上其所有孩子结点的值。
实施例
图3为本发明构建频繁模式树的一个实例,本实施例包括以下步骤:
步骤1,根据图3(a)数据库构建频繁模式初始树,具体过程如下:
如图3(b)所示,建立一个标签为null的结点作为整个频繁模式树的根节点;扫描第一条交易记录后,建立结点a,令结点a的计数域值为1,表明项目a出现1次;
如图3(c)所示,扫描第二条交易记录后,构建结点b、c、d,令b、c的count域值为0,d的count域值为1,表明项目d出现1次(此时为了减少构建频繁模式树时产生冗余的写,并不记录b,c出现的次数,仅记录位于该条交易记录末尾的项d出现的次数,因为之后b,c出现的次数可根据其孩子结点的计数域的值得到);
如图3(d)所示,依次扫描完整个数据库所有交易记录后所构建出的初始树;
步骤2,构建完整的频繁模式树
如图3(e)所示,用深度优先搜索算法对频繁模式初始树依次进行遍历,遍历结点的计数器值为该结点本身的值加上其所有孩子结点的值。例如c计数域的值为c原来的值0与d计数域的值5之和,最终得出c出现5次;f计数域的值为f的孩子结点e和g的值与f原来的值3之和,最终得出f出现6次。依次遍历完频繁模式树之后,构建出完整的频繁模式树。
实验测试
选取不同类型的数据集进行试验,统计各个数据集的读写操作次数、总的构建树的时间和PCM寿命。这些数据集的名称分别为T10I4D100K、T40I10D100K、chess、mushroom、pumsb*、connect、pumsb、accidents、C73D10、C20D10。
实验结果参见图4至图7:
图4中,纵坐标代表读的次数,横坐标代表各个数据集,从图4看出,本发明减少了大量的读操作;
图5中,纵坐标代表写的次数,横坐标代表各个数据集,从图5看出,本发明减少了大量的写操作;
图6中,纵坐标代表总的构建树的时间,横坐标代表各个数据集,从图6看出,本发明减少了构建树的时间;
图7中,纵坐标代表直到PCM被写坏,能处理的总的交易数目,横坐标代表各个数据集,从图7中看出,本发明最少可延长PCM的寿命为16.67%(发生在数据集T40I10D100K),最大可延长99.05%(发生在数据集connect),极大地延长了PCM的寿命。
- 还没有人留言评论。精彩留言会获得点赞!