基于网格快速搜寻密度峰值的教育数据聚类方法与流程
本发明涉及一种数据聚类方法,尤其是涉及一种基于网格快速搜寻密度峰值的教育数据聚类方法。
背景技术:
聚类分析是数据挖掘的一个重要方法,广泛应用于文本处理、Web搜索等多领域。其中比较典型的有k-means和DBSCAN算法,K-means算法将数据点划分到距离最近的中心点进行聚类,该类算法很难将非球形数据集聚类,DBSCAN算法可以对任意形状的数据集进行聚类,但须指定一个密度阈值,从而可以去除噪声点。基于密度峰值的空间聚类算法Clustering by Fast Search and Find of Density Peaks(简称CFSFDP),用于发现被低密度区域分离的高密度区域。与K-means算法相比,CFSFDP可自动获取类的个数,且算法的复杂度相对较低。与DBSCAN算法相比,CFSFDP可在噪声环境下聚类任意形状数据集且实现简单速度快。但同样也存在如下缺点:(1)算法使用全局密度阈值,并没有考虑数据空间的分布特性,所以当数据密度和类间距分布不均匀时,聚类质量不高;(2)当一个类中存在多密度峰值时,CFSFDP算法虽然对数据点按密度值降序进行排序,但聚类效果并不理想。
技术实现要素:
针对现有技术的不足,本发明的目的是提供一种基于网格快速搜寻密度峰值的教育数据聚类方法,解决了原CFSFDP算法中使用全局密度阈值,当数据密度和类间距分布不均匀时,聚类质量不高的问题。
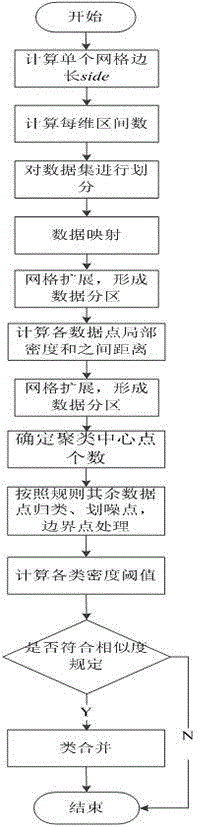
本发明技术方案如下:一种基于网格快速搜寻密度峰值的教育数据聚类方法,依次包括以下步骤,
步骤1:读取数据库中数据,进行数据预处理形成待聚类数据集,所述数据集包括学生在校学习和生活的若干属性,所述属性包括学生个人信息,学生选课成绩信息,学生的毕业情况信息,把所述信息的子属性当作聚类算法的输入属性,所述子属性包括学好、成绩、性别、政治面貌、民族、籍贯和考生类别,设每个所述子属性上的值在区间[li,hi)中,i=1,2,…,d,d为自然数,则S=[l1,h1)×[l2,h2)×…×[ld,hd)构成数据集;
步骤2:计算单个网格单元的边长side,以及每维区间数,根据计算结果,对数据集的每一个维度进行划分,将其划分成边长相等且互不相交的网格单元,对于每一维的网格单元,保证取值区间都是左闭右开的,所述每一个维度为每个所述子属性;
步骤3:对数据点进行映射,映射至对应的网格单元中,获取每维上对应的下标,所述数据点为所述数据集中的子属性的值;
步骤4:对每一网格单元,计算其包含的数据点数,考察任一网格单元P相邻的网格单元,与相邻网格单元比较密度大小,并向密度大于网格单元P的网格单元进行扩展,得到网格单元合集,形成数据分区;
步骤5:计算各数据分区中各数据点xi的局部密度ρi和距离δi并确定密度阈值dc,根据决策图确定聚类中心及其个数;
步骤6:对非聚类中心的数据点进行归类,根据密度阈值dc确定各类的核心区域和边界区域,并指定边界区域中最高点密度值ρb作为去除噪声点的阈值;
步骤7:假设边界点p的密度阈值dc邻域中包含的核心点同属于一个聚类中,则把该点p直接划分到包含这些核心点的簇中;假设边界点p同时落在几个分属于不同簇的核心点的dc邻域内,那么就把该边界点划入距离最近的簇中;
步骤8:计算类间相似度,合并两个满足类间相似条件的类;
步骤9:输出聚类结果。
优选的,所述类间相似条件为类间相似度小于等于类密度阈值的较小值。
本发明所提供的技术方案的优点在于:
通过对待聚类数据的划分和扩展形成多个网格单元合集,将该合集作为一个数据分区,采用CFSFDP算法对各个分区进行局部聚类。在局部聚类时,各分区根据其数据分布密集程度选择合适的密度阈值进行聚类,因而由全局密度阈值导致的聚类质量下降的问题得以解决,同时保持了CFSFDP算法的快速和高效。当一个类中存在多密度峰值时,本发明的聚类效果提升。本发明只关注各个数据点之间的相似性度量(距离或其他衡量标准)且无需指定数据集的中心点,比k-means算法更适合没有坐标的数据集,其确定类中心点的方案简洁而且精准。
附图说明
图1为本发明聚类方法流程示意图。
图2为本发明实施例聚类输出结果。
具体实施方式
下面结合实施例对本发明作进一步说明,但不作为对本发明的限定。
请结合图1,以教育数据聚类为例,本发明方法的具体实施是这样的,
步骤1:读取数据库中数据,进行数据预处理形成待聚类数据集,该数据集有多个属性,属性涵盖了学生在校学习和生活的所有方面,如学生个人信息,学生选课成绩信息,学生的毕业情况信息等等,把这些信息的子属性当作聚类算法的输入属性;
步骤2:教务数据集的属性(如性别,学业成绩,生源地等)都是有界的,设学业成绩上的值在区间[li,hi)中,i=1,2,…,d,d为自然数,则S=[l1,h1)×[l2,h2)×…×[ld,hd)就是教务数据集。对数据集的每一个维度进行划分,将其划分成边长相等且互不相交的网格区间,形成网格单元。对于每一维的网格单元,保证取值区间都是左闭右开的。为了提高计算效率和聚类效果,定义网格的边长side为:
其中a为比例系数,根据经验值进行指定,用来调整控制网格边长大小。本实施例中选取的a值都为1.5。根据网格边长,可计算出区间数目,计算公式如下:
根据计算结果,对数据集的每一个维度进行划分,将其划分成边长相等且互不相交的网格单元;
步骤3:把每个数据点都映射到所相对应的网格单元当中去,对于某个特定的数据对象来说,它所对应的网格在每个维度上面的所对应的下标为:
步骤4:对每一网格单元,计算其包含的数据点数,考察任一网格单元P相邻的网格单元,与相邻网格单元比较密度大小,并向密度大于网格单元P的网格单元进行扩展,得到网格单元合集,形成数据分区;
步骤5:计算各数据分区中各数据点xi的局部密度ρi和距离δi并确定密度阈值dc,教务数据集S={x1,x2,…,xn},相应的下标集为IS={1,2,…,n},dij=dist(xi,xj)为数据点xi和xj间的距离,当数据点为离散值时,局部密度ρi为:
其中j与i不相等且都属于IS,函数χ(x)为:
当数据点为连续值时,局部密度ρi为:
其中,参数dc>0为截断距离,ρi表示S中与数据点xi之间距离小于dc的数据点的个数,与密度更高的数据点的距离δi的计算公式为:
根据决策图确定聚类中心及其个数;
步骤6:对非聚类中心的数据点进行归类,根据密度阈值dc确定各类的核心区域和边界区域,并指定边界区域中最高点密度值ρb作为去除噪声点的阈值;
步骤7:假设边界点p的密度阈值dc邻域中包含的核心点同属于一个聚类中,则把该点p直接划分到包含这些核心点的簇中;假设边界点p同时落在几个分属于不同簇的核心点的dc邻域内,那么就把该边界点划入距离最近的簇中;
步骤8:当一个类中存在多密度峰值时,CFSFDP算法会将一个类划分成两个或多个类,此时需进行子类合并;在网格划分时,也可能将同一类中的数据点划分到两个相邻的网格当中,此时同样也需进行子类合并。因此当局部聚类完成后,应当对那些所在分区相邻并且关联性比较高的子类进行合并。假设存在两个类A,B,其密度阈值分别为dcA,dcB,边界区域点集分别为EA,EB,设p,q分别为EA,EB中的数据点,Dist{p,q}表示p和q之间的距离,边界区域中的点数为NA,NB,公式如下:
NA=|EA|,NB=|EB|
dc(A,B)的计算公式为:
dc(A,B)=min{dcA,dcB}
若类A和类B满足类间相似度:
则将类A、B进行合并;
步骤9:输出聚类结果。
本实施例的聚类结果如图2所示,其中分类1的特征:大部分是女生,学习综合成绩大部分为良好或中等,团员,江苏苏中,城镇户口居多。分类2的特征:大部分是女生,学习综合成绩大部分为良好,非江苏人居多,考生类别不详。分类3的特征:大部分是女生,学习综合成绩大部分为中等,团员,江苏城镇户口居多。分类4的特征:大部分是男生,学习综合成绩为中等,江苏苏北,农村户口居多。分类5的特征:大部分是男生,学习综合成绩大部分为中等,江苏苏北,城镇户口居多。分类6的特征:大部分是男生,学习综合成绩大部分为中等,江苏苏南,城镇户口居多。分类7的特征:大部分是男生极少女的,本三,学习综合成绩大部分为中等,考生类别未知居多。分类8的特征:大部分是男生,专转本居多,学习综合成绩大部分为中等,江苏苏北,考生类别未知居多。聚类也可以用于离群点的寻找,加入学习行为属性,可以寻找学习行为有问题的学生。
- 还没有人留言评论。精彩留言会获得点赞!