一种数据模型自动化评审系统的制作方法
本发明涉及一种数据模型评审系统,尤其涉及一种数据模型自动化评审系统。
背景技术:
大数据技术现在被越来越多的行业所使用,典型的电信行业就是使用大数据的先驱者,电信系统最显著的一个特点就是数据量大,月存储PB数量级,随着集群的增大,越来越多样式的数据接入,数据以各种形式存放在集群里。数据的多样性,复杂性给管理带来很大的成本,且数据模型的管理基本上各厂家都有一套自己的规范,这也导致整个集群出现各种命名模式的模型,使得模型较为混乱,因此一些集群便出现了模型管理人员,但目前这些管理人员仍然用最原始的方法进行模型评审,即厂家开发人员提交模型过来,模型评审人员结合自己的业务理解和技术能力对所提交模型进行评审,整体流程如图1所示,包括如下阶段:
1、提交阶段:建模厂家提交建立模型的SQL语句,各厂家按照自己的规范进行建模。
2、评审阶段:模型评审人员收到建模厂家的建模语句后,结合自己以往的业务经验和技术能力,进行评估,目前主要是针对命名规范性进行校验。
3、通知阶段:评审人员将校验结构反馈给建模厂家。
对于电信系统业务等大型业务系统,一般具有特点:1、业务数据量大,数据样式多;2、建模时效性要求高;3、厂家众多,建模数量多。
由上可见,现有的技术具有如下缺点:1、人工操作,容易产生错误;2、效率较为低下;3、对评审人员的业务知识,系统熟悉度要求较高。
技术实现要素:
本发明所要解决的技术问题是提供一种数据模型自动化评审系统,使得模型审批能够自动化的进行,不需要完全依赖于管理人员的经验和水平,减少对建模厂家的进度耽误,同时减少人为的错误评审。
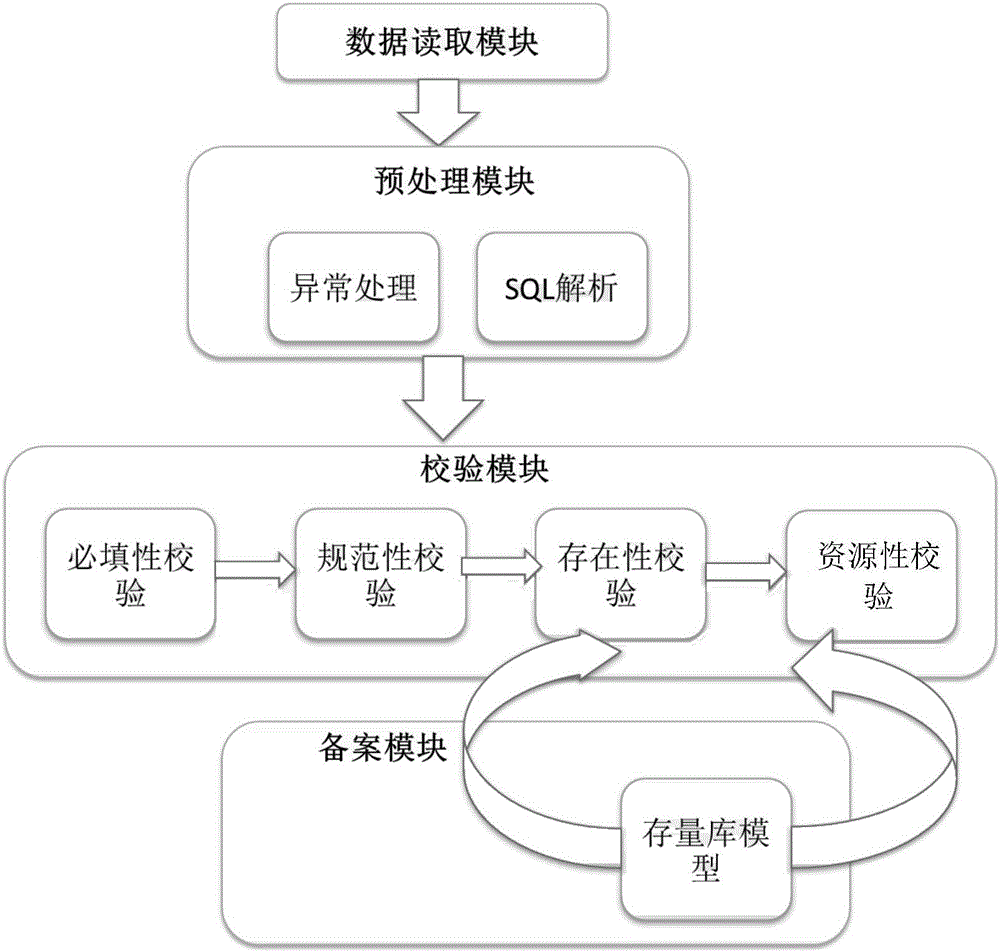
本发明为解决上述技术问题而采用的技术方案是提供一种数据模型自动化评审系统,包括数据读取模块:批量读取建模厂家提交的数据模型,并将读取的数据放入数据库临时表中;预处理模块:对数据库临时表中的数据进行格式化异常处理,并对其中的建模SQL语句进行解析;校验模块:对经过预处理后的数据,每条数据按照预定规则进行校验,将校验结果写回每条记录结果字段,循环进行上述校验过程,直至本批次数据全部校验完毕;备案模块:对于所有数据都校验成功的数据模型进行记录,形成建模存量库。
上述的数据模型自动化评审系统,其中,所述建模厂家提交的数据模型采用EXCEL文件模板。
上述的数据模型自动化评审系统,其中,所述预处理模块对数据库临时表中的数据进行如下格式化异常处理:消除回车符和制表符,并统一中英文标点符号。
上述的数据模型自动化评审系统,其中,所述预处理模块根据正则表达式对建模SQL语句进行模式匹配,解析获取该数据模型的名称,字段,字段类型以及备注信息。
上述的数据模型自动化评审系统,其中,所述校验模块按照如下预定规则对每条数据依次进行校验:必填性校验、规范性校验、存在性校验和资源性校验。
上述的数据模型自动化评审系统,其中,所述必填性校验包括对数据模型名称,开发商名,用途说明,保留时长,模型类别以及SQL解析后的字段进行必填校验。
上述的数据模型自动化评审系统,其中,所述规范性校验包括根据业务类型对业务事实表、业务中间表、配置表、日志表、临时表、视图分别进行统一命名,并限定各自的存放表空间。
上述的数据模型自动化评审系统,其中,所述存在性校验过程如下:对于已经存在的数据模型,通过对新提交的数据模型里的建模语句及用途说明与建模存量库中已经存在的模型进行比对;当发现相似的数据模型时,将该数据模型在校验信息中反馈给建模厂家。
上述的数据模型自动化评审系统,其中,所述资源性校验包括对解析后的建模SQL语句,识别出维度字段;根据维度字段,在建模存量库中匹配出相同或者相近的维度组合模型,统计该匹配模型的空间情况,并以该匹配模型空间作为新提交数据模型的预估空间;如果建模存量库中没有相近维度的模型,则按照开发商提交的字段“预计占用空间”作为该新提交数据模型的预估空间;统计该新提交数据模型存放的数据库当前剩余空间,将当前剩余空间与预估空间比对,如果预估空间与剩余空间之比达到预设阀值,则提示剩余空间不足的校验信息。
本发明对比现有技术有如下的有益效果:本发明提供的数据模型自动化评审系统,通过设置预处理模块和校验模块对批量读取的建模厂家提交的数据模型进行处理,使得模型审批能够自动化的进行,不需要完全依赖于管理人员的经验和水平,减少对建模厂家的进度耽误,同时减少人为的错误评审。
附图说明
图1为现有数据模型评审流程示意图;
图2为本发明数据模型自动化评审系统架构示意图;
图3为本发明数据模型自动化评审流程示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图2为本发明数据模型自动化评审系统架构示意图。
请参见图2,本发明提供的数据模型自动化评审系统,包括数据读取模块、预处理模块、校验模块和备案模块;主要模块功能实现如下:
1、数据读取模块:识别建模厂家提交的EXCEL的数据,进行批量读取,将读取的数据放入数据库临时表中;
2、预处理模块:对数据库临时表中的数据进行预处理,主要分为消除回车符,制表符,统一中英文标点符号;对模板中建模的SQL语句进行SQL解析(解析算法,主要依据正则表达式进行模式匹配),解析后能区分出该模型的名称,字段,字段类型,备注等信息;
3、校验模块:经过预处理后的数据,每条按照规范进行校验,校验顺序为“必填性校验->规范性校验->存在性校验->资源性校验”,将校验结果写回每条记录结果字段,并进行循环,直至本批次数据全部校验完毕。校验模块核心处理流程如下。
3.1、必填性校验
模型名称,开发商名,用途说明,保留时长,模型类别等信息必须填写,对以上字段进行必填校验,其中模板上的必填字段,没有填写则提示必须填写,模型的备注,字段的备注,需要SQL解析,对解析后的字段也需要进行必填校验;
3.2、规范性校验
模型命名规范,按照约定,制定规范性说明,例如“类别_厂家简称_业务(配置)”
对于业务事实表,统一以“F_”开头
对于业务中间表,统一以“I_”开头
对于配置表,统一以“CFG_”开头
对于日志表,统一以“LOG_”开头
对于临时表,统一以“TMP_”开头
对于视图,统一以“V_”开头
统一各厂家的英文简称,约定业务类型的英文名称;对于传统的关系型数据库,模型存放表空间必须存放各自的表空间,不允许使用他人表空间;对于大数据如hadoop的模型(HIVE里的模型或者其他HDFS),必须存放各自的目录,不允许使用他人目录或者公共目录;对违反以上规范的模型,提示相关的不规范说明已提示建模厂商修正。
3.3、存在性校验
对于已经存在的模型,通过对模板里的建模语句及用途说明进行与建模存量库中已经存在的模型进行比对(首次运行,不需要比对);当发现相似的模型时,将该模型在校验信息中反馈给建模厂家。
3.4、资源性校验
对解析后的SQL语句,识别出维度字段,根据维度字段,在存量库中匹配出相同或者相近的维度组合模型,统计该模型的空间情况,优先以该模型空间作为模板模型预估空间。如果存量库中没有相近维度的模型,则按照开发商提交的字段“预计占用空间”为该模板模型预估空间。统计该模型存放的数据库当前剩余空间,将该空间与预估空间比对,如果预估空间大于或等于剩余空间80%,则提示校验信息“剩余空间为XX,【模型名称】空间过大,需减少保存时长”。
4、备案模块:对于通过所有校验,及校验成功的模型,进行记录,形成存量库。
本发明能够对建模厂家提交的excel附件中一些特殊字符进行处理,使得代码能够识别有效数据。接着对建模SQL进行SQL解析,自动拆分出关键字段,并根据拆分后的信息做后期的必填性,规范性,存在性,资源性校验。校验模块逻辑需区分先后,只有先通过必填性校验,才能进行规范性校验,继而对存在性校验,最后资源性校验,按照上述顺序则可进一步提高校验效果。
本发明制定了一套机制有效地快速进行模型评审,通过制定的模型建模规范模板,收集厂家的建模信息,结合后台的规范化验证建模程序;通过后台的校验程序来实现自动化评审。在前期准备阶段,需要调研系统业务数据特性,与各建模厂商达成一致,形成一套统一的命名规范,制定统一的建模模板,模型管理人员根据此规范模板,进行编程,由程序实现校验逻辑。在提交阶段,则建模厂家按照模板进行提交,程序读取数据,并自动化进行评审,按照规则输出校验信息给建模厂商,厂商根据校验信息就行模型修正并再次提交评审,程序对校验成功的模型进行记录,形成存量库,如图3所示。具体优点如下:1、脚本化自动校验,减少了人为的失误而造成的错误,提高了模型评审的准确率,同时自动化大大提升了评审的效率,原来1个模型/5分钟的人工评审,利用本发明,可以1秒完成。2、模型评审由脚本完成,相比传统的人工(靠经验)评审,脚本评审可以不断去完善,考虑方面多样化,评审方式更加全面。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!