一种多级安全模型访问控制数据融合方法与流程
本发明涉及数据处理领域,尤其是一种多级安全模型访问控制数据融合方法。
背景技术:
1、术语解释:
BLP(Bell–LaPadula model)访问模型:
一种强制访问控制与自主访问控制相结合的访问控制模型。由是在1976年Bell和Padulla提出一个多级安全策略模型。BLP通过每个主体和客体都有一个安全级别,包括安全等级和分类,即安全级别可定义为:Level=(C,S),C为密级,S表示分类级。其中,密级具有层级关系,分类则为一些类别标签。而安全级别Level是存在偏序关系。当主体访问客体时,比较两者之间的安全级别,然后根据访问矩阵决定其访问的授权。
BLP模型主要针对数据机密性保护。当用户处较低安全级别时,无法读取较高级别的数据信息,这样便保证了数据信息的单向流通,控制数据信息从低级别流向高级别。此外,当用户级别处于高级别时,无法向低级别的数据信息进行写操作。此两条规则,可描述为SS特性、*-特性,其中F(S)表示主体S的安全级别,F(O)表示客体O的安全级别。为了添加自主访问控制性质,添加访问的灵活性,还增加了使用访问矩阵来描述自主安全规则。当主体用户和客体在访问矩阵中具有访问属性,主体才允许客体访问。
BLP模型的三大特性可以表示为
1)SS特性(简单安全特性):当且仅当F(S)≥F(O),主体S对客体O进行读操作。
2)*-特性(星安全特性):当且仅当F(S)≤F(O),主体S对客体O进行写操作。
3)DS特性(自主安全特性):当且仅当当前状态下的主体与客体都处于当前状态的访问矩阵中,则当前状态主体可以访问客体。
格(Lattice):
数论中,Lattice是一种偏序关系的集合。在访问控制中,是一种多级安全级别,由两部分组成,安全等级和安全分类。安全等级则是具有明确的级别分类,如Top secret(TS),Secret(S),Confidential(C),Unclassified(U),其中的TS≥S≥C≥U。而安全分类,则是标记的组合。假设有两个安全级别l1=(c1,k1)和l2=(c2,k2)。当且仅当c1≤c2和时,l1和l2满足偏序关系≤,可表示为l1≤l2。
Hasse图:
在序论里,Hasse图是一种用于表达有限的偏序关系集合的图,以图形形式表现偏序关系集合的传递简约。
在偏序集合<S,≤>,在S的每个元素在Hasse图是一个顶点。而对于两个元素S1和S2满足偏序关系,即s1,s2∈S并且s1≤s2,则在Hasse图里偏序关系表示一段有向线段,从S2 指向S1。
2、现有技术:
海量数据的出现,人们越来越专注于如何有效地利用这些数据并获取其最大的价值。例如,美国医疗零售商在使用大数据进行分析和利用,有效提高他们的利益60%。与此同时,大数据的利用也帮助欧洲政府提高工作效率,减少近1000亿欧元的政府开销。
其中一种数据利用的方式,就是将数据开放提供给其他用户,将多个不同来源的数据整合在一起。因此,在数据融合过程中,越来越复杂的数据随之产生。与此同时,这也会给这些数据利用者提供便利,让其得到更精确的数据分析,在数据挖掘和智能决策上得到更精确的利用。而在现实生活中,Apache Solr和ElasticSearch就是通常用于作为搜索引擎来在融合数据上进行搜索行为。
在融合数据上进行检索中所面临的一个数据安全问题,就是如何处理融合数据获取中的机密性保护。在大数据中,数据获取中需要保护个人隐私信息,如个人兴趣,爱好和财产等。人们可以轻松通过Facebook用户的公开页面来获取用户的个人信息。在混合云的云计算环境中,敏感数据尽量放在私有云上,减少个人隐私信息泄露风险。
因此,多个数据源上的数据进行融合,当用户在融合数据上进行搜索,搜索的结果必须不能包含该用户所不能访问的数据。假设,一个用户u允许访问数据集DA,不允许访问数据集DB。数据融合过程中,一个新的数据集DC由DA和DB融合所产生的,例如连接操作,DA和DB的join。因此,DC将会包含DA和DB的数据信息。当用户u在融合数据上发出搜索语句q,那么检索结果必须过滤来自数据集DB的数据。因为如果没有过滤,直接将那些来自DC的数据返回给用户u,用户u就极有可能获取得到来自数据集DB的数据信息,从而使得数据泄露。
所以,在多数据源的环境下不仅仅需要对数据进行融合,还需要对各数据源中的访问策略进行融合。针对于多级安全模型的访问策略问题,需要有一种将访问策略融合进行融合的方案。针对于各访问策略之间可能存在的冲突问题,方法需要有效解决冲突问题。
研究国内外关于访问策略融合现有的研究工作中,其中一种方法来解决融合策略时出现的冲突就是使用数学上的逻辑运算。Rao将策略表达成一种数理逻辑代数式,并提出一个框架通过代数运算来表示融合的过程。而在框架里面,Rao使用XACML(eXtensible Access Control Markup Language,可扩展的访问控制标记语言)来描述策略。它是一种基于XML的开放标准语言,它设计用于描述安全政策以及对网络服务、数字版权管理(DRM)以及企业安全应用信息进行访问的权限。在融合过程中,融合生成的新策略的结果,就是通过计算每条策略的数理逻辑的运算结果,并返回最终结果。
而另一种方法解决融合策略出现的冲突就是重写查询语句或者生成全局映射模式。例如,一个查询语句Q可以被转化为Q’,而Q’所返回的结果集符合原来的数据集的安全策略。Hu使用基于语义的安全策略。通过本体映射和合并,查询语句将被重写成一类实体和属性名称,并且映射到本地查询。此外,本地策略可以映射到全局模式当中。Cruz将本地策略存储在XML中。并在融合过程中,将其转变成一个全局RDF方案。当两个访问策略合并时,本地模式转换为RDF模式,然后再合并成全局RDF模式。在web service环境下,Alodib提出了访问控制策略服务,它将合并请求者、服务提供者和访问策略信息,以网络服务描述语言(Web Services Description Language,WSDL)进行描述。当访问策略进行合并时,则根据WSDL文件进行合并,取代当前的WSDL文件。
根据上述融合数据的方法:(1)若将访问策略转化为数理逻辑运算,则当访问策略融合时,可能因用户属性不完整,出现结果值未知。
因为属性不完整性或提供的信息不融合数据搜索的多级安全模型齐全,若使用数理逻辑运算极有可能返回的结果是未知。因为未知的结果,使得系统只能做出拒绝访问(因为保护最高隐私),这在一定程度上影响系统的可用性。
(2)若将访问查询语句重写或生成全局映射模式,当某个数据源需要修改访问策略时,则需要重新生成一个新的全局映射模式。
技术实现要素:
为了解决上述技术问题,本发明的目的是:提供一种建立融合的速度快、安全性高的多级安全模型访问控制数据融合方法。
本发明所采用的技术方案是:一种多级安全模型访问控制数据融合方法,所述多级安全模型访问控制数据的数据源基于BLP访问模型建立,包括有以下步骤:
A、将原始格转换为Hasse图后进行合并,从而实现对格的融合;
B、对数据源进行映射函数转换;
C、对访问控制矩阵进行合并。
进一步,所述步骤A包括有以下子步骤:
A1、根据Hasse图之间的顶点的相等关系或支配关系添加顶点间的有向线段;
A2、删除在冲突路径中出现次数最多的一条关联线段,若在所有冲突路径中每条关联线段出现的次数相同,则删除在冲突路径中涉及的安全级别最高的关联线段;
A3、对Hasse图中存在冗余的关联线段进行化简处理。
进一步,所述步骤A1具体为:若Hasse图之间的顶点为相等关系,则在两顶点之间添加两条互相指向的有向线段;若Hasse图之间的顶点为支配关系,则在两顶点之间添加一条由支配顶点指向被支配顶点的有向线段。
进一步,所述步骤A3中的冗余线段包括有平等关系的关联线段和覆盖关系的关联线段。
进一步,所述步骤A3具体为:对于合并后Hasse图中平等关系的关联线段,将关联线段的两个节点进行合并生成新的节点;对于合并后Hasse图中覆盖关系的关联线段,将从起始点直接指向结束点的关联线段删除。
进一步,所述步骤B具体为:将原始格上的安全等级映射函数转换成融合后的格的安全等级映射函数。
进一步,所述步骤C具体为:所述对访问控制矩阵进行合并包括对数据集的合并和对用户信息数据的合并。
进一步,所述对数据集的合并的方法为:将数据源的数据集合合并成一个数据集合。
进一步,所述对用户信息数据的合并的方法为:将用户信息数据求并集。
本发明的有益效果是:本发明方法通过格的融合、映射函数转换、访问矩阵合并实现将访问策略中的格转化为Hasse图,当判断用户是否对数据集有访问权限时,则可以根据融合Hasse图上的偏序关系判断;并且访问策略中的访问矩阵合并两个原始访问矩阵的用户和数据集,用户属性不必全局统一,只需映射到相对应的节点即可。同时,某个数据源修改了访问策略时,则无需重新再建立合并过程,只需要将用户或者数据集的映射关系修改即可,避免了重新建立融合过程。
附图说明
图1为本发明方法总步骤流程图;
图2为本发明步骤中格的融合的流程图;
图3为本发明步骤中映射函数转换的流程图;
图4为本发明步骤中访问矩阵合并的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
参照图1,一种多级安全模型访问控制数据融合方法,所述多级安全模型访问控制数据的数据源基于BLP访问模型建立,因为每个数据源都是基于BLP模型下建立访问策略的,因此,根据BLP模式,访问策略Pi定义为Pi=(fi,LTCi,Mi),其中i表示第i个数据源。当不同的数据源合并在一起,就会产生一个新的融合数据集。因为不同的数据源之间存在着一些差异,所以融合的访问策略PG=(fG,LTCG,MG)必须处理融合时的冲突,并且保持与原有的数据源中的访问策略一致。而融合过程主要是三部分的融合,一部分是格(Lattice)的融合,一部分是映射函数的转换,另一部分是访问矩阵的融合,具体包括有以下步骤:
A、格的融合:将原始格转换为Hasse图后进行合并,从而实现对格的融合;
因为格是一种特殊的偏序关系集合,所以格也可以用Hasse图来表示。因此,格的融合可以转换为两幅Hasse图的合并。
B、映射函数转换:对数据源进行映射函数转换;
C、访问矩阵的融合:对访问控制矩阵进行合并。
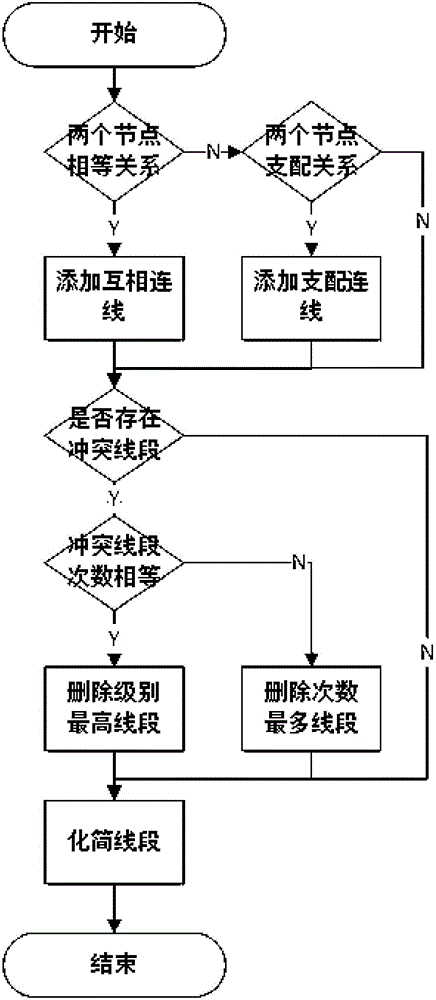
参照图2,进一步作为优选的实施方式,合并过程主要分为三个阶段,初始化阶段,冲突处理阶段和化简阶段。初始化阶段是在两幅原始的Hasse图之间添加满足偏序关系的线段。在添加关联线段后,融合Hasse图可能会存在着与原有Hasse图的冲突,所以需要对融合Hasse图进行冲突检测和处理,删除一些冲突线段。最后,还需要对融合Hasse图进行化简,删除冗余的线段;所述步骤A包括有以下子步骤:
A1、初始化阶段:根据Hasse图之间的顶点的相等关系或支配关系添加顶点间的有向线段;
假设两个格表示为LTC1=<S1,R1>和LTC2=<S2,R2>。在初始化阶段,需要对两个格之间的节点关系进行考虑。而两个节点之间的关系分为两种,一种是相等关系,另一种是支配关系。
对于两个安全等级l1=<c1,k1>和l2=<c2,k2>,当且仅当c1=c2和k1=k2,则l1与l2是相等关系。
对于两个安全等级l1=<c1,k1>和l2=<c2,k2>,当且仅当c1≥c2和则l1与l2是支配关系。其中,l1称为支配点,l2称为被支配点。
在添加了根据两个节点关系线段之后,此时的融合Hasse图可能存在着冗余的线段或者冲突线段。因此,接下来的步骤A2处理与原有格的Hasse图冲突的线段。
A2、冲突处理阶段:删除在冲突路径中出现次数最多的一条关联线段,即在合并Hasse图中,列举出所有冲突路径,然后去统计每条关联线段出现的次数,删除出现最多的一条关联线段;若在所有冲突路径中每条关联线段出现的次数相同,则删除在冲突路径中涉及的安全级别最高的关联线段;
一条路径是冲突的条件:1)这条路径是回路;2)这条路径起始点和结束点在原有的Hasse图中是不可比关系,但这条路径使得在合并Hasse图中变得可比。
A3、化简处理阶段:对Hasse图中存在冗余的关联线段进行化简处理;
经过冲突处理阶段后,合并Hasse图应该不存在任何具有冲突的路径,但此时的Hasse图可能会是比较冗余的,因此需要对Hasse图进行最后一个步骤,化简操作。
进一步作为优选的实施方式,根据两个格之间的节点关系,在格的融合的初始化阶段,针对两个Hasse图间的节点关系,作出以下计算,所述步骤A1具体为:若Hasse图之间的顶点为相等关系,则在两顶点之间添加两条互相指向的有向线段;若Hasse图之间的顶点为支配关系,则在两顶点之间添加一条由支配顶点指向被支配顶点的有向线段。
进一步作为优选的实施方式,所述步骤A3中的冗余线段包括有平等关系的关联线段和覆盖关系的关联线段。
假设在Hasse图中,有两个节点s1和s2,当且仅当这两条路径(关联线段)是互相直接指向对方的,即s1→s2和s2→s1时,两条路径是平等关系。
假设在Hasse图中,有两个节点s1和s2,当且仅当一条路径是由s1直接指向s2,如s1→s2,另一条路径则是由s1到s2,并中间经过若干个节点,如s1→···→s2,则两条路径是覆盖关系。
冗余线段即上述满足平等关系或覆盖关系的关联线段。
因此,若冲突处理后的Hasse图存在冗余线段,本文给出两条规则来对冗余线段进行删除,并化简Hasse图,得到最终简化的Hasse图。
进一步作为优选的实施方式,所述步骤A3具体为:对于合并后Hasse图中平等关系的关联线段,将关联线段的两个节点进行合并生成新的节点;
在冲突处理后的Hasse图中,两个节点Levela和Levelb互相指向,即Levela→Levelb和Levelb→Levela,那么可以对Levela和Levelb这两个节点进行合并,形成新的节点Levela,b。
对于合并后Hasse图中覆盖关系的关联线段,将从起始点直接指向结束点的关联线段删除;
在冲突处理后的Hasse图中,两个节点Levela和Levelb分别作为起始点和终结点,若存在两条路径,其中一条路径由Levela直接指向Levelb,即Levela→Levelb,另一条路径则是由Levela经过若干个节点到达Levelb,即Levela→Level1→Level2···→Level3→Levelb,则将Levela→Levelb线段删除。
参照图3,进一步作为优选的实施方式,所述步骤B具体为:将原始格上的安全等级映射函数转换成融合后的格的安全等级映射函数。
因为每个数据源都是用BLP模型来管理访问控制,因此有每个数据源都有一个映射函数fi(i表示数据源i),将主体或者客体映射到各自对应的安全级别上。例如,f1(u1)={TS,<k1,k2>}表示在数据源1中,用户u1拥有安全级别{TS,<k1,k2>}。
在融合过程中,在格的融合后需要将在原始格上的安全等级映射到新生成的格的安全等级。在Hasse图中,每个安全级别对应的是图中的节点。因此,安全级别的映射转换就等同于在原有的Hasse图上节点映射到融合Hasse图上的节点。
参照图4,进一步作为优选的实施方式,所述步骤C具体为:所述对访问控制矩阵进行合并包括对数据集的合并和对用户信息数据的合并。
进一步作为优选的实施方式,所述对数据集的合并的方法为:将数据源的数据集合合并成一个数据集合。
进一步作为优选的实施方式,所述对用户信息数据的合并的方法为:将用户信息数据求并集。
除了BLP访问模型的强制访问控制外,在发明中模型通过访问控制矩阵实现自动灵活的自主访问控制。访问矩阵合并是将原有的矩阵的行与列进行合并。假设M=SUB×OBJ是合并产生的矩阵,M1=subject1×object1和M2=subject2×object2分别是两个需要合并的原始访问矩阵。
对于矩阵的合并,合并矩阵的客体(数据集)就是两个数据源的数据集合合并生成的过程,因此OBJ=Int(object1,object2)。而合并矩阵的主体(用户)就是两个数据源的主体的并集,因此SUB=subject1∪subject2。
当用户可以在两个数据源中对能访问数据集时,该用户才能在访问控制数据融合后访问融合的数据集。这过程可以形式化描述为:融合的访问矩阵的值为TRUE,即MG(sub,obj)=TRUE,其中obj=Int(object1,object2),当且仅当用户sub都在两个原始访问矩阵中都能访问融合前的数据集,即M1(sub,obj)=TRUE和M2(sub,obj) =TRUE。其中,sub∈subject1,sub∈suject2和obj∈object1,obj∈object2。否则,融合访问矩阵的值为FALSE。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可以作出种种的等同变换或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!