一种人脸跟踪方法及装置与流程
本发明涉及图像处理技术领域,尤其是一种人脸跟踪方法及装置。
背景技术:
在现有的人脸跟踪技术中,一般是先通过人脸检测找出视频首帧中的人脸区域,再通过持续计算人脸区域中的颜色、角点或光流等特征,在下一帧中找到特征相匹配的区域作为下一帧的人脸区域,以此类推……以实现视频中的人脸跟踪。然而,上述方案受光照、人脸角度等影响较大,跟踪效果较差,并且跟踪框不稳定、很容易出现跟踪失败的情况。
另一种改进的人脸跟踪方案是通过在线学习人脸区域中的特征来实现跟踪,虽然能够改善跟踪效果,但在线学习会增加计算的复杂度,不适于在移动端进行实时人脸跟踪。
鉴于上述人脸跟踪方案的优缺点,考虑到在实际的人脸跟踪中(比如,人脸视频上妆),目标对象常处于摆姿势、做表情等运动过程中,需要对目标的人脸进行实时跟踪以定位五官位置;同时,在视频图像中,目标对象常不止一个,还需要对多个目标同时进行人脸跟踪。这就导致跟踪问题很复杂,既要保证跟踪准确,又要解决跟踪运算量大的问题。
技术实现要素:
为此,本发明提供了一种人脸跟踪方法及装置,以力图解决或者至少缓解上面存在的至少一个问题。
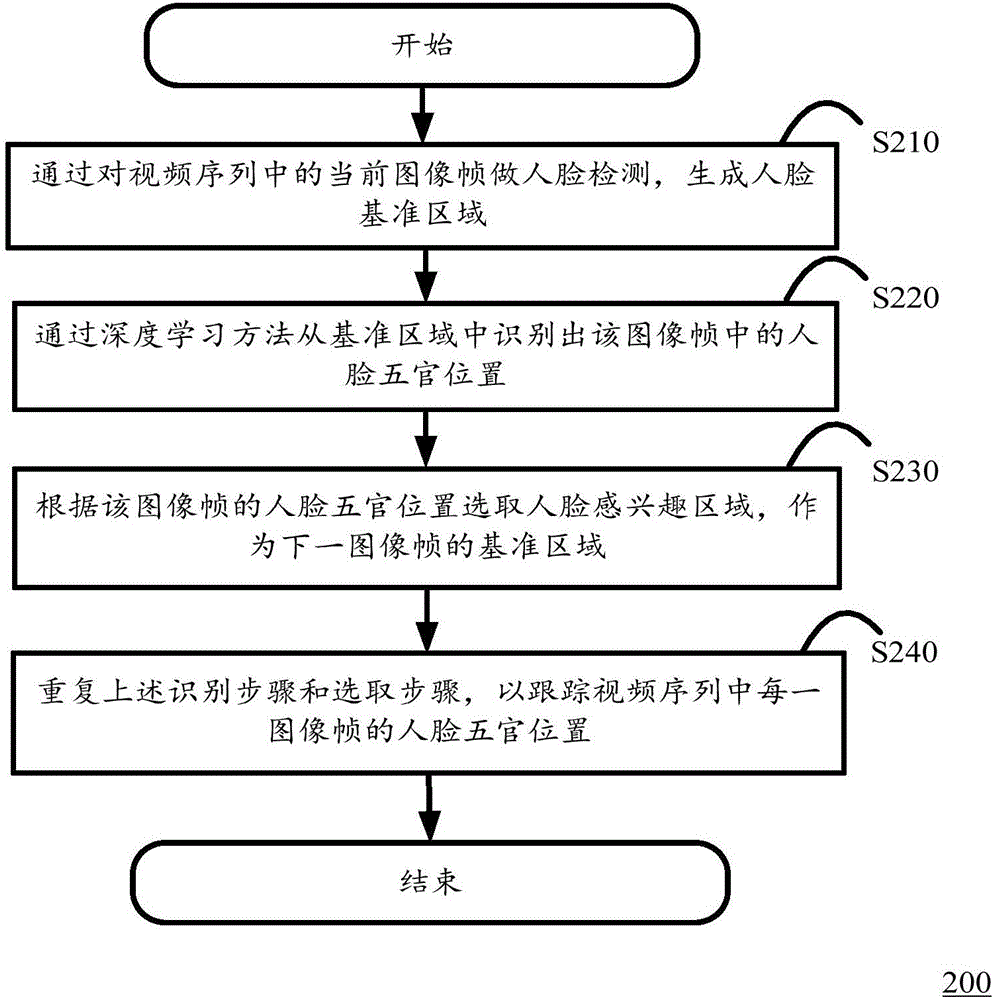
根据本发明的一个方面,提供了一种人脸跟踪方法,包括步骤:通过对视频序列中的当前图像帧做人脸检测,生成人脸基准区域;通过深度学习方法从基准区域中识别出该图像帧中的人脸五官位置;根据该图像帧的人脸五官位置选取人脸感兴趣区域,作为下一图像帧的基准区域;以及重复上述识别步骤和选取步骤,以跟踪视频序列中每一图像帧的人脸五官位置。
可选地,在根据本发明的人脸跟踪方法中,还包括步骤:若检测到当前图像帧中有多个人脸,则对每个人脸都生成一个人脸基准区域;对每个人脸的基准区域分别执行上述识别步骤、选取步骤、和重复步骤,以跟踪视频序列中的多个人脸五官位置。
可选地,在根据本发明的人脸跟踪方法中,根据该图像帧的人脸五官位置选取人脸感兴趣区域的步骤包括:根据识别出的人脸五官位置生成该图像帧的子区域,其中子区域为矩形;以该子区域的中心为基准,将该子区域的长、宽各放大第一数目倍,得到人脸感兴趣区域。
可选地,在根据本发明的人脸跟踪方法中,第一数目是根据视频序列的帧频计算得到。
可选地,在根据本发明的人脸跟踪方法中,采用深度学习方法识别人脸五官位置的步骤包括:采用深度学习方法建立人脸对齐模型;以及由人脸对齐模型提取出人脸五官特征,其中,人脸对齐模型包括至少一个图像卷积层。
可选地,在根据本发明的人脸跟踪方法中,由人脸对齐模型提取出人脸五官特征的步骤包括:将基准区域的图像作为输入图像,输入人脸对齐模型;通过图像卷积层对输入图像进行卷积、ReLU、池化的迭代操作;以及输出预测的人脸五官特征点位置。
可选地,在根据本发明的人脸跟踪方法中,池化操作包括:利用平均值进行池化;或利用最大值进行池化。
根据本发明的另一个方面,提供了一种人脸跟踪装置,包括:生成单元,适于对视频序列中的当前图像帧做人脸检测,生成人脸基准区域;识别单元,适于通过深度学习方法从基准区域中识别出该图像帧中的人脸五官位置、还适于从选取单元选取的下一图像帧的基准区域中识别出下一图像帧的人脸五官位置,以跟踪视频序列中每一图像帧的人脸五官位置;以及选取单元,适于根据该图像帧的人脸五官位置选取人脸感兴趣区域,作为下一图像帧的基准区域。
可选地,在根据本发明的人脸跟踪装置中,生成单元还适于在检测到当前图像帧中有多个人脸时,对每个人脸都生成一个人脸基准区域;识别单元还适于识别出该图像帧中每个人脸基准区域对应的人脸五官位置;以及选取单元还适于根据该图像帧中的每个人脸的五官位置选取对应的人脸感兴趣区域,作为该人脸在下一图像帧中对应的基准区域。
可选地,在根据本发明的人脸跟踪装置中,选取单元还适于根据识别出的人脸五官位置生成该图像帧的子区域,其中子区域为矩形,并且以该子区域的中心为基准,将该子区域的长、宽各放大第一数目倍,得到人脸感兴趣区域。
可选地,在根据本发明的人脸跟踪装置中,选取单元包括:计算模块,适于根据视频序列的帧频计算得第一数目。
可选地,在根据本发明的人脸跟踪装置中,识别单元包括:建模模块,适于采用深度学习方法建立人脸对齐模型,其中人脸对齐模型包括至少一个图像卷积层;提取模块,适于利用人脸对齐模型输出预测的人脸五官特征点位置。
可选地,在根据本发明的人脸跟踪装置中,提取模块还适于将基准区域的图像作为输入图像,输入人脸对齐模型、且适于对输入图像进行卷积、ReLU、池化的迭代操作、输出提取的人脸五官特征。
可选地,在根据本发明的人脸跟踪装置中,提取模块还适于利用平均值进行池化操作、或利用最大值进行池化。
根据本发明的人脸跟踪方案,通过引入基于深度学习的人脸对齐方案替代传统跟踪算法中人脸区域特征计算与匹配,能够提高人脸对齐的精度、且具有很好的鲁棒性、抗旋转性和抗光性,在人脸识别精度方面有很好的表现。同时,本方案不需要在线学习人脸特征,只需要根据上一图像帧中识别到的人脸五官位置初步确定下一图像帧的人脸区域,这就降低了计算的复杂度,能够在移动终端完成实时跟踪。综上,通过本方案,能够准确、快速地跟踪视频图像中的人脸。
另外,通过采用ROI区域搜索,可以方便快速地对多个被摄目标进行跟踪。
附图说明
为了实现上述以及相关目的,本文结合下面的描述和附图来描述某些说明性方面,这些方面指示了可以实践本文所公开的原理的各种方式,并且所有方面及其等效方面旨在落入所要求保护的主题的范围内。通过结合附图阅读下面的详细描述,本公开的上述以及其它目的、特征和优势将变得更加明显。遍及本公开,相同的附图标记通常指代相同的部件或元素。
图1示出了根据本发明的一个示例性实施方式的移动终端100的构造框图;
图2示出了根据本发明一个实施例的人脸跟踪方法200的流程图;
图3示出了根据本发明一个实施例的人脸对齐模型中第一卷积层的结构示意图;以及
图4示出了根据本发明一个实施例的人脸跟踪装置400的示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
图1为根据本发明的一个实施方式的移动终端100构造示意图。参照图1,移动终端100包括:存储器接口102、一个或多个数据处理器、图像处理器和/或中央处理单元104,以及外围接口106。存储器接口102、一个或多个处理器104和/或外围接口106既可以是分立元件,也可以集成在一个或多个集成电路中。在移动终端100中,各种元件可以通过一条或多条通信总线或信号线来耦合。传感器、设备和子系统可以耦合到外围接口106,以便帮助实现多种功能。例如,运动传感器110、光传感器112和距离传感器114可以耦合到外围接口106,以方便定向、照明和测距等功能。其他传感器116同样可以与外围接口106相连,例如定位系统(例如GPS接收机)、温度传感器、生物测定传感器或其他感测设备,由此可以帮助实施相关的功能。
相机子系统120和光学传感器122可以用于方便诸如记录照片和视频剪辑的相机功能的实现,其中所述相机子系统和光学传感器例如可以是电荷耦合器件(CCD)或互补金属氧化物半导体(CMOS)光学传感器。可以通过一个或多个无线通信子系统124来帮助实现通信功能,其中无线通信子系统可以包括射频接收机和发射机和/或光(例如红外)接收机和发射机。无线通信子系统124的特定设计和实施方式可以取决于移动终端100所支持的一个或多个通信网络。例如,移动终端100可以包括被设计成支持GSM网络、GPRS网络、EDGE网络、Wi-Fi或WiMax网络以及BlueboothTM网络的通信子系统124。音频子系统126可以与扬声器128以及麦克风130相耦合,以便帮助实施启用语音的功能,例如语音识别、语音复制、数字记录和电话功能。
I/O子系统140可以包括触摸屏控制器142和/或一个或多个其他输入控制器144。触摸屏控制器142可以耦合到触摸屏146。举例来说,该触摸屏146和触摸屏控制器142可以使用多种触摸感测技术中的任何一种来检测与之进行的接触和移动或是暂停,其中感测技术包括但不局限于电容性、电阻性、红外和表面声波技术。一个或多个其他输入控制器144可以耦合到其他输入/控制设备148,例如一个或多个按钮、摇杆开关、拇指旋轮、红外端口、USB端口、和/或指示笔之类的指点设备。所述一个或多个按钮(未显示)可以包括用于控制扬声器128和/或麦克风130音量的向上/向下按钮。
存储器接口102可以与存储器150相耦合。该存储器150可以包括高速随机存取存储器和/或非易失性存储器,例如一个或多个磁盘存储设备,一个或多个光学存储设备,和/或闪存存储器(例如NAND,NOR)。存储器150可以存储操作系统152,例如Android、IOS或是Windows Phone之类的操作系统。该操作系统152可以包括用于处理基本系统服务以及执行依赖于硬件的任务的指令。存储器150还可以存储应用154。这些应用在操作时,会从存储器150加载到处理器104上,并在已经由处理器104运行的操作系统之上运行,并利用操作系统以及底层硬件提供的接口实现各种用户期望的功能,如即时通信、网页浏览、图片管理等。应用可以是独立于操作系统提供的,也可以是操作系统自带的。
根据本发明的一个实施例,提供了一种具有人脸跟踪功能的移动终端100,可以通过在移动终端100中布置相应的人脸跟踪装置400来实现上述功能。
图2示出了根据本发明一个实施例的在移动终端100上实现人脸跟踪方法200的流程图。如图2所示,该方法200始于步骤S210(生成步骤),将一个视频序列表示为I0I1I2I3……,其中I0、I1......分别代表第一帧图像、第二帧图像……对其中的当前图像帧(例如I0)做人脸检测,根据检测到的人脸区域裁切出一个人脸的基准区域Face0。简单来讲,人脸检测(Face detection)就是判断一帧图像中是否包含人脸区域,若包含人脸则返回人脸的大小、位置等信息。人脸检测技术相关的算法有很多,可以是基于几何特征的方法、基于模板或者模型的方法,诸如模板匹配模型、肤色模型、ANN模型、SVM模型、Adaboost模型等等。在本方案中,对人脸检测的具体算法不作限制,任何人脸检测方法都可以与本方案的实施例相结合,以实现人脸跟踪。
随后在步骤S220中(识别步骤),通过深度学习方法从基准区域Face0中识别出该图像帧I0中的人脸五官位置。换句话说,由生成步骤检测到的只是人脸区域的大致范围,需要通过识别步骤进一步得到人脸精确区域(或位置)。
具体地,采用深度学习方法训练建立起人脸对齐模型,然后通过人脸对齐模型提取人脸的五官位置。所谓人脸对齐,就是对检测出的人脸区域,例如Face0,进行定位操作以得到人脸五官的具体位置点。本方案采用深度学习方法建立对齐模型,以解决在真实场景中,姿态、表情等对人脸对齐的影响。
根据本发明的实施例,人脸对齐模型包括至少一个图像卷积层。将步骤S210中计算出的基准区域Face0对应的图像作为输入图像,输入到人脸对齐模型,根据一种实现方式,由多个图像卷积层对该输入图像进行“卷积→ReLU→池化→卷积→ReLU→池化→卷积→ReLU→池化→…→卷积”的操作。
以其中第一卷积层为例,卷积层的结构如图3所示,对输入图像先进行卷积运算,提取图像特征。
再由ReLU(Rectified Linear Units,经校正过的线性单元)作为激活函数,优化算法,这里选取ReLU作激活函数主要是考虑到和使用别的激活函数的模型相比,ReLU不仅识别错误率低、计算效率更高、而且可以形成了所谓"稀疏表征"(sparse representation),用少量的神经元可以高效、灵活、稳健地表达抽象复杂的概念。
然后,对经过ReLU处理后的数据进行池化(pooling)操作,可选地,池化操作可以是利用平均值或最大值进行池化,本发明对此不作限制。
为提高网络的泛化能力,在池化操作后,对数据进行局部响应归一化处理。以下面的公式为例:
其中,a表示每一个神经元的激活,n是在同一个位置(x,y)上临近的kernel map的数目,N是在这一层中卷积核的总数目,k、α、β都是预设的一些超参数(hyper-parameters),可选地,k=2,n=5,α=10-4,β=0.75。
根据实现方式,该人脸对齐模型中具有超过一层的图像卷积层,且每一个图像卷积层的结构可能会有所不同,例如在五层卷积层结构中,第三、四、五层的图像卷积层可以不设置池化操作和局部响应归一化处理。
最后,再通过卷积层将卷积得到的特征进行合并或组合,最终预测输出人脸五官特征点的位置(即,特征点坐标),其中人脸五官特征点可以包括鼻子、嘴唇、眼睛、眉毛、外轮廓点等。可选地,人脸对齐模型还可以包括全连接层,通过全连接层将卷积得到的特征进行组合后输出特征点位置,全连接层可以至少包括两层,在第一个全连接层中,对输入的特征进行连通合并后,同样输入ReLU中进行非线性化后再输入到第二个全连接层进行预测,本发明对特征的合并方式不做限制。
本方案通过引入基于深度学习的人脸对齐方案替代传统跟踪算法中人脸区域特征计算与匹配,主要是考虑到深度学习算法在人脸对齐精度、鲁棒性、抗旋转、抗光等方面表现都十分优异,而准确的人脸特征识别可以提高跟踪的效果。
随后在步骤S230中(选取步骤),根据该图像帧I0的人脸五官位置选取人脸感兴趣区域,作为下一图像帧I1的基准区域Face1。
具体做法是:根据识别步骤(S220)中识别出的人脸五官位置点生成图像帧I0的一个矩形子区域Box0(也就是人脸的精确区域),以图在最小的区域范围内包含人脸五官,一般地,矩形子区域Box0的范围是小于基准区域Face0的。然后,以该矩形子区域Box0的中心为基准,将该子区域的长、宽各放大第一数目倍,得到人脸感兴趣区域(ROI区域),作为下一图像帧I1的基准区域Face1。根据本发明的一个实施例,第一数目根据视频序列的帧频计算得到。例如,正常流畅实时的视频或摄像播放时的帧频是30帧,那么两帧之间相隔就是33ms,根据经验,两帧之间人脸不会移动超过四倍的人脸精确区域,因此选取第一数目为1,即Face1的面积=4*Box0的面积。
随后在步骤S240中(重复步骤),重复上述S220识别步骤和S230选取步骤,以跟踪视频序列中每一图像帧的人脸五官位置。展开来说,就是将Face1作为图像帧I1的基准区域;然后将Face1的图像输入到人脸对齐模型中,识别出人脸五官位置;再根据人脸五官位置生成图像帧I1的子区域Box1,根据Box1生成下一图像帧I2的基准区域Face2;将Face2作为图像帧I2的基准区域;然后将Face2的图像输入到人脸对齐模型中……以此类推,这样就跟踪得到每一图像帧的人脸五官位置。
根据一种实现方式,若检测到当前图像帧中有多个人脸,则分别对每个人脸进行人脸检测,生成多个人脸基准区域;然后,对每个人脸的基准区域分别执行上述识别步骤、选取步骤、和重复步骤,以跟踪视频序列中的多个人脸五官位置。
故方法200引入深度学习方法进行人脸对齐,在人脸识别精度方面有很好的表现,同时又不需要在线学习人脸特征,降低了计算的复杂度,以实现移动端的实时跟踪,达到了准确快速跟踪视频图像中的人脸的技术效果。另外,因采用了ROI区域搜索,又可以方便快速的对多个被摄目标进行跟踪。
图4示出了根据本发明一个实施例的人脸跟踪装置400的示意图。如图4所示,该装置400包括:生成单元410、识别单元420、和选取单元430。
假设视频序列为I0I1I2I3……,生成单元410适于对该视频序列中的当前图像帧I0做人脸检测,得到一个人脸的基准区域Face0。人脸检测技术相关的算法有很多,可以是基于几何特征的方法、基于模板或者模型的方法,诸如模板匹配模型、肤色模型、ANN模型、SVM模型、Adaboost模型等等。在本方案中,对人脸检测的具体算法不作限制,任何人脸检测方法都可以与本方案的实施例相结合,以实现人脸跟踪。
识别单元420适于从基准区域Face0中进一步确定人脸的精确位置,根据本发明的实施例,通过深度学习方法从基准区域Face0中识别出该图像帧中的人脸五官位置。
具体地,识别单元420包含建模模块和提取模块,其中建模模块适于采用深度学习方法建立人脸对齐模型,其中人脸对齐模型包括至少一个图像卷积层,然后提取模块适于利用人脸对齐模型提取出人脸五官特征。本方案采用深度学习方法建立对齐模型,能够很好地解决在真实场景中,姿态、表情等对人脸对齐的影响。
建模模块适于选取大量的人脸图像作为样本数据,通过深度学习方法训练建立起人脸对齐模型,根据本发明的实施例,人脸对齐模型包括至少一个图像卷积层。其中,图3示出了根据本发明一个实施例的图像卷积层的结构图。
在测试阶段,由提取模块对输入的基准区域Face0的图像,经过“卷积→ReLU→池化→卷积→ReLU→池化…→卷积”的处理提取出人脸五官特征,具体过程如下:
图像卷积层对该输入的基准区域Face0的图像进行“卷积→ReLU→池化→卷积→ReLU→池化→卷积→ReLU→池化→…→卷积”的操作。以其中第一卷积层为例,卷积层的结构如图3所示,对输入图像先进行卷积运算,提取图像特征。
再由ReLU(Rectified Linear Units,经校正过的线性单元)作为激活函数进行校正,这里选取ReLU作激活函数主要是考虑到和使用别的激活函数的模型相比,ReLU不仅识别错误率低、计算效率更高、而且可以形成所谓"稀疏表征"(sparse representation),用少量的神经元可以高效、灵活、稳健地表达抽象复杂的概念。
然后,对经过ReLU处理后的数据进行池化(pooling)操作,可选地,提取模块424在进行池化操作时,可以利用平均值或最大值进行池化,本发明对此不作限制。
为提高网络的泛化能力,在池化操作后,对数据进行局部响应归一化处理。以下面的公式为例:
其中,a表示每一个神经元的激活,n是在同一个位置(x,y)上临近的kernel map的数目,N是在这一层中卷积核的总数目,k、α、β都是预设的一些超参数(hyper-parameters),可选地,k=2,n=5,α=10-4,β=0.75。
根据实现方式,该人脸对齐模型中具有超过一层的图像卷积层,且每一个图像卷积层的结构可能会有所不同,例如在五层卷积层结构中,第三、四、五层的图像卷积层可以不设置池化操作和局部响应归一化处理。
最后,通过卷积层将卷积得到的特征进行合并,输出最终提取的人脸五官特征,其中人脸五官特征点可以包括鼻子、嘴唇、眼睛、眉毛、外轮廓点等。
根据另一种实施方式,人脸对齐模型还可以包括全连接层,由全连接层将卷积得到的特征进行组合后,输出预测的人脸特征点位置(即,特征点坐标)。可选地,全连接层至少包括两层,且在第一个全连接层中,对输入的特征进行合并后,同样输入ReLU中进行校正后再输入到第二个全连接层进行预测,本发明对特征的合并方式不做限制。
选取单元430适于根据识别单元420识别到的人脸五官位置生成一个精准的人脸区域,即,根据人脸五官位置裁切出一个矩形子区域Box0,以图在最小的区域范围内包含人脸五官,一般地,矩形子区域Box0的范围是小于基准区域Face0的。再以该矩形子区域Box0的中心为基准,将该子区域的长、宽各放大第一数目倍,得到人脸感兴趣区域(ROI区域),作为下一图像帧I1的基准区域Face1。
根据本发明的一个实施例,选取单元430包括适于根据视频序列的帧频计算第一数目的计算模块。例如,正常流畅实时的视频或摄像播放时的帧频是30帧,那么两帧之间相隔就是33ms,根据经验,两帧之间人脸不会移动超过四倍的人脸精确区域,因此选取第一数目为1,即Face1的面积=4*Box0的面积。
根据本发明的实施方式,识别单元420还适于将选取单元430选取的下一图像帧的基准区域Face1对应的图像输入到人脸对齐模型中,识别出下一图像帧I1的人脸五官位置,并将其发送给与之耦接的选取单元430,由选取单元430根据人脸五官位置选取出图像帧I1的子区域,并根据子区域生成ROI区域作为下一图像帧I2的基准区域Face2……以此类推,最终跟踪到视频序列中每一图像帧的人脸五官位置。
根据本发明的实施方式,生成单元410还适于在检测到当前图像帧中有多个人脸时,对每个人脸都生成一个人脸基准区域。而后识别单元420适于分别识别该图像帧中每个人脸基准区域对应的人脸五官位置。再由选取单元430根据该图像帧中的每个人脸的五官位置分别选取对应的人脸感兴趣区域,作为该人脸在下一图像帧中对应的基准区域。这样就解决了视频图像中多目标的跟踪难题。
应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员应当理解在本文所公开的示例中的设备的模块或单元或组件可以布置在如该实施例中所描述的设备中,或者可替换地可以定位在与该示例中的设备不同的一个或多个设备中。前述示例中的模块可以组合为一个模块或者此外可以分成多个子模块。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
本发明公开了:
A6、如A5所述的方法,其中由人脸对齐模型提取出人脸五官特征的步骤包括:将基准区域的图像作为输入图像,输入所述人脸对齐模型;通过图像卷积层对输入图像进行卷积、ReLU、池化的迭代操作;以及输出预测的人脸五官特征点位置。
A7、如A6所述的方法,其中池化操作包括:利用平均值进行池化;或利用最大值进行池化。
B13、如B12所述的装置,其中,提取模块还适于将基准区域的图像作为输入图像,输入人脸对齐模型、且适于对输入图像进行卷积、ReLU、池化的迭代操作、输出预测的人脸五官特征点位置。
B14、如B13所述的装置,其中,提取模块还适于利用平均值进行池化操作、或利用最大值进行池化。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
此外,所述实施例中的一些在此被描述成可以由计算机系统的处理器或者由执行所述功能的其它装置实施的方法或方法元素的组合。因此,具有用于实施所述方法或方法元素的必要指令的处理器形成用于实施该方法或方法元素的装置。此外,装置实施例的在此所述的元素是如下装置的例子:该装置用于实施由为了实施该发明的目的的元素所执行的功能。
如在此所使用的那样,除非另行规定,使用序数词“第一”、“第二”、“第三”等等来描述普通对象仅仅表示涉及类似对象的不同实例,并且并不意图暗示这样被描述的对象必须具有时间上、空间上、排序方面或者以任意其它方式的给定顺序。
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。此外,应当注意,本说明书中使用的语言主要是为了可读性和教导的目的而选择的,而不是为了解释或者限定本发明的主题而选择的。因此,在不偏离所附权利要求书的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。对于本发明的范围,对本发明所做的公开是说明性的,而非限制性的,本发明的范围由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!