多层人造神经网络的制作方法
本发明与人造神经网络(artificialneuralnetwork)相关,并且尤其与可执行深度学习的多层人造神经网络相关。
背景技术:
以人造神经网络进行机器学习的概念存在已久,但先前受限于处理器运算能力,相关研究始终无法顺利推进。近十年来,随着处理器运算速度、存储器存取速度以及机器学习演算法等各方面技术的长足进步,能产出复杂判断结果的人造神经网络逐渐成为可能,因而在自动驾驶、图像辨识、自然语言辨识、数据勘探等领域中重新受到高度重视。
现行的人造神经网络通常被设计为具有多层(multi-layer)结构。除了最前端的输入层与最后端的输出层,其他串接在输入层与输出层之间的称为隐藏层(hiddenlayer)。输入层用以接收外部数据,不进行运算。隐藏层与输出层则是各自接收前一层的输出信号作为当层的输入信号,且各自包含多个进行运算工作的神经元。若以神经元连接方式区分,每一个隐藏层与输出层可以各自是一卷积层(convolutionallayer)或一全连接层(fully-connectedlayer)。目前有多种人造神经网络架构,对于卷积层与全连接层的配置组合各有不同的规划。以alexkrizhevsky等学者于2012年提出的alexnet架构为例,其中总共包含六十五万个神经元,构成依序串接的五个卷积层以及三个全连接层。在需要进行较复杂的判断时,人造神经网络可能包含高达二十九个运算层。
实际上,人造神经网络大多是利用一超级电脑或一单芯片系统来实现。在使用单芯片系统的情况下,目前的做法是令单芯片系统中的同一套电路在不同时间点分别扮演多层人造神经网络中不同的运算层。图1呈现一个单芯片系统的功能方块图作为说明范例。时脉计数器11负责产生供控制器12与处理器13参考的时脉信号。在第一段工作周期内,处理器13首先扮演第一运算层的角色。控制器12会令存储器14输出应由第一运算层负责处理的输入数据以及第一运算层中各神经元的可学习参数(learnableparameter),存入本地暂存器13a,供处理器13使用。在进行对应于第一运算层的运算期间,处理器13的运算结果会被暂存于本地暂存器13a。待处理器13完成所有对应于第一运算层的运算后,暂存于本地暂存器13a的运算结果会被转存至存储器14。随后,在第二段工作周期内,处理器13改为扮演第二运算层的角色。因此,控制器12会令存储器14改为输出应由第二运算层负责处理的输入数据以及第二运算层中各神经元的可学习参数,存入本地暂存器13a,供处理器13使用。依此类推,处理器13可逐步完成一多层人造神经网络中各个运算层的运算工作。
对于多层人造神经网络来说,各个运算层的输入数据、可学习参数与运算结果的数量都非常可观。因此,上述做法的缺点之一是本地暂存器13a与存储器14之间必须有大量的数据转移。此类大规模的存储器存取相当耗时,人造神经网络的整体效能会因此受限。此外,由这个范例可看出,必须等到本地暂存器13a中的运算结果被转移至存储器14,且新的输入数据与可学习参数自存储器14被载入本地暂存器13a后,处理器13才能开始进行下一轮的运算工作。处理器13因此有许多时间花费在等待数据转移,造成运算资源未被充分利用的问题。
技术实现要素:
为解决上述问题,本发明为多层人造神经网络提出一种新的硬件架构。
根据本发明的一具体实施例为一种多层人造神经网络,其中包含至少一高速通信接口与n个运算层。n为大于1的整数。该n个运算层通过该至少一高速通信接口串联。每一个运算层各自包含一运算电路与一本地存储器。该本地存储器用以存储供该运算电路使用的输入数据以及可学习参数。第i个运算层中的该运算电路将其运算结果通过该至少一高速通信接口提供至第(i+1)个运算层中的该本地存储器,供该第(i+1)个运算层中的该运算电路作为输入数据。i为范围在1到(n-1)间的一整数指标。
在其中一种实施例中,该n个运算层利用至少n个完全相同的单位芯片来实现。
在其中一种实施例中,该n个运算层包含一卷积层,且该卷积层包含并联的m个该单位芯片,m为大于1的正整数。
在其中一种实施例中,该n个运算层包含一全连接层,且该全连接层包含并联的p个该单位芯片,作为p个神经元,p为大于1的正整数。
在其中一种实施例中,第i个运算层中的该运算电路依序产生q笔运算结果,q为大于1的整数,在开始产生该q笔运算结果中的第q笔运算结果时,该运算电路同时将已产生的第(q-1)笔运算结果通过该至少一高速通信接口提供至第(i+1)个运算层中的该本地存储器,其中q为范围在2到q间的一整数指标。
在其中一种实施例中,该n个运算层根据一管线式架构同时运作。
在其中一种实施例中,一运算层中的该运算电路被预设为根据多笔真实数据与多笔假数据进行运算,该多层人造神经网络进一步包含:
一控制器,耦接至该运算层中的该运算电路,用以作废根据该多笔假数据产生的一笔或多笔运算结果,并保留完全根据该多笔真实数据产生的一笔或多笔运算结果。
在其中一种实施例中,该高速通信接口包含一高速串列器-解串列器或是一射频接口。
在其中一种实施例中,第i个运算层与第(i+1)个运算层被设置为处于同一集成电路芯片中、处于不同集成电路芯片但同一封装中,或是处于不同封装中。
通过实施本发明,几乎或完全不需要等待数据转移,其运算资源因此可被充分利用。
关于本发明的优点与精神可以通过以下发明详述及所附图式得到进一步的了解。
附图说明
图1呈现一单芯片系统的功能方块图作为背景技术的范例。
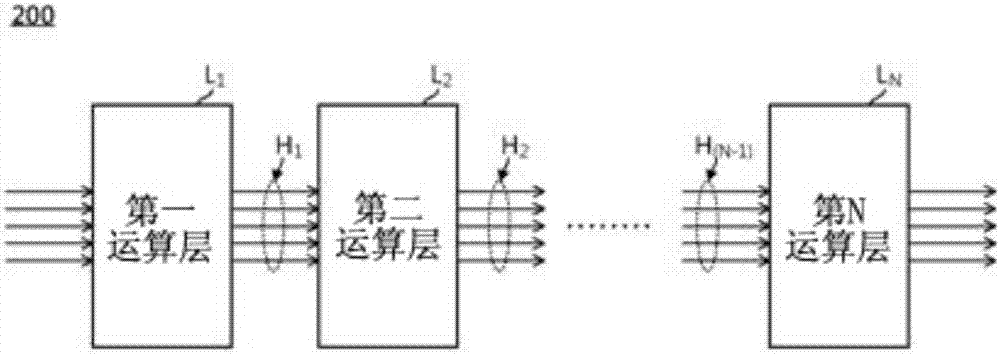
图2呈现根据本发明的一实施例中的多层人造神经网络的功能方块图。
图3呈现根据本发明的两个相邻运算层间的详细连接方式。
图4a至图4e图像化呈现存储在两个本地存储器中的输入数据矩阵。
图5呈现根据本发明的控制器与两运算层间的详细连接方式。
图6呈现并联两个单位芯片以提高数据处理量的概念。
图7呈现并联多个单位芯片以组成一全连接层的概念。
须说明的是,本发明的图式包含呈现多种彼此关联的功能性模块的功能方块图。该等图式并非细部电路图,且其中的连接线仅用以表示信号流。功能性元件及/或程序间的多种互动关系不一定要通过直接的电性连结始能达成。此外,各个元件的功能不一定要如图式中绘示的方式分配,且分散式的区块不一定要以分散式的电子元件实现。
附图标号
11:时脉计数器
12:控制器
13:处理器
13a:本地暂存器
14:存储器
200:多层人造神经网络
l1至ln:运算层
h1至h(n-1):高速通信接口
t1至t5:工作周期
ri_t1至ri_t4:运算结果
510:控制器
610:数据分离电路
621、622:单位芯片
630:数据结合电路
710_1至710_p:单位芯片
具体实施方式
请参阅图2。根据本发明的一具体实施例为一种多层人造神经网络,其中包含(n-1)个高速通信接口h1至h(n-1)与n个串联的运算层l1至ln(n为大于1的整数)。以包含三个隐藏层的人造神经网络为例,电路设计者可令n等于四,并且令运算层l1至l4分别对应于其中的三个隐藏层与一个输出层。实际上,n的大小可依多层人造神经网络200的应用场合来决定,不限于特定数值。
如图2所示,两个相邻的运算层是通过高速通信接口h串联。举例而言,高速通信接口h可为但不限于一高速串列器-解串列器(highspeedserializer-deserializer)或是一射频接口(radiofrequencyinterface,rfi)。须说明的是,高速通信接口h的传输速率愈高,愈有助于缩短在两运算层间传递数据的时间,但本发明的范畴不受限于高速通信接口h的传输速率。
多层人造神经网络200中的运算层l1至ln各自具有独立的硬件。更明确地说,每一个运算层各自包含一运算电路与一本地存储器。图3以其中的第i个运算层li与第(i+1)个运算层l(i+1)为例,呈现两个相邻运算层间的详细连接方式(i为范围在1到(n-1)间的整数指标)。如图3所示,第i运算电路的输入端连接于第i本地存储器,而第i运算电路的输出端通过高速通信接口hi连接至第(i+1)本地存储器。
第i本地存储器中存储有供第i运算电路使用的输入数据以及可学习参数。若运算层li为多层人造神经网络200中最前端的隐藏层,第i本地存储器中存储的输入数据便是来自多层人造神经网络200的输入层(未绘示)。若运算层li并非多层人造神经网络200中最前端的隐藏层,第i本地存储器中存储的输入数据便是来自第(i-1)个运算层,也就是第(i-1)运算电路产生的运算结果。另一方面,在训练多层人造神经网络200的过程中,第i本地存储器中存储的可学习参数可能会被持续地修改,直到训练结果与理想结果的差异能收敛至低于一预设门槛值。随后,于一般的运算程序中,第i本地存储器中存储的可学习参数便是经训练完成后固定的数值。
实际上,运算层l1至ln可利用串接多个完全相同的单位芯片来实现。使用相同的单位芯片的好处在于,多层人造神经网络200所包含的运算层数量有相当大的调整弹性。只要串接更多数量的单位芯片,多层人造神经网络200所包含的运算层的数量便可以无限延伸。须说明的是,该等单位芯片在实体上可被设置为处于同一集成电路芯片中、处于不同集成电路芯片但同一封装中,或是处于不同封装中。换句话说,相邻的两个运算层间可以是通过同一芯片内、跨越芯片、跨越封装甚至是跨越电路板的高速通信接口互相连接。
于一实施例中,运算层l1至ln根据一管线式(pipeline)架构同时运作,以提高多层人造神经网络200的整体数据处理量。举例而言,假设有多组数据依序通过运算层l1至ln;当运算层l1在对第n组数据施以运算时,运算层l2可对第(n-1)组数据施以运算,……,运算层ln可对第1组数据施以运算。
配合管线式架构,各个运算层完成运算工作所需要的时间可被设计为大致相同。以下段落以两个分别包含3*3个神经元的卷积层为例,介绍一种可配合管线式架构的数据处理方法。在这个范例中,运算层li、l(i+1)的取样窗(window)大小皆为2*2,且跨幅(stride)皆为1。运算层li的输入数据是一个3*3的数据矩阵,运算层l(i+1)的输入数据则是一个2*2的数据矩阵。为了达到令各个运算层工作时间大致相同的效果,运算层l(i+1)的输入数据被填入五笔假数据(例如数值0),使得运算层l(i+1)的输入数据矩阵大小变为3*3,亦即与运算层li的输入数据矩阵大小相同。第i本地存储器与第(i+1)本地存储器中存储的输入数据矩阵被图像化呈现于图4a,其中的真实数据以实心圆点表示,假数据则以具有实线轮廓的空心圆点表示。
首先,如图4a所示,在工作周期t1中,运算层li、l(i+1)的取样窗各自涵盖第i本地存储器与第(i+1)本地存储器中坐标为(1,1)、(2,1)、(1,2)、(2,2)的四个位置。更明确地说,在工作周期t1中,第i运算电路针对存储在第i本地存储器中位置坐标为(1,1)、(2,1)、(1,2)、(2,2)的四笔数据进行运算,而第(i+1)运算电路针对存储在第(i+1)本地存储器中位置坐标为(1,1)、(2,1)、(1,2)、(2,2)的四笔数据进行运算。因处理的数据量相同,第i运算电路和第(i+1)运算电路会大致在同一时间完成运算。随后,第i运算电路将其运算结果ri_t1存入第(i+1)本地存储器中坐标为(1,1)的位置,并以具有虚线轮廓的空心圆点表示。须说明的是,基于卷积层的运算特性,第(i+1)本地存储器中坐标位置(1,1)原本存放的数据之后不再被需要,以运算结果ri_t1取代原本存放于该位置的数据不会有任何问题。相似地,第(i+1)运算电路会其运算结果r(i+1)_t1存入第(i+2)本地存储器(未绘示)中坐标为(1,1)的位置,取代原本存放于该位置的数据。
接着,如图4b所示,在工作周期t2中,运算层li、l(i+1)的取样窗各自涵盖第i本地存储器与第(i+1)本地存储器中的坐标为(2,1)、(2,1)、(2,2)、(3,2)的四个位置。第i运算电路会将本次的运算结果ri_t2存入第(i+1)本地存储器中坐标为(2,1)的位置,取代原本存放于该位置的数据。相似地,第(i+1)运算电路可其运算结果r(i+1)_t2存入第(i+2)本地存储器中坐标为(2,1)的位置。值得注意的是,运算结果r(i+1)_t2是根据一部分真实数据与一部分假数据所产生,因此是无效的运算结果,其处理方式容后详述。
接着,如图4c所示,在工作周期t3中,运算层li、l(i+1)的取样窗各自涵盖第i本地存储器与第(i+1)本地存储器中坐标为(1,2)、(2,2)、(1,3)、(2,3)的四个位置。第i运算电路会将本次的运算结果ri_t3存入第(i+1)本地存储器中坐标为(1,2)的位置,取代原本存放于该位置的数据。第(i+1)运算电路可其运算结果r(i+1)_t3存入第(i+2)本地存储器中坐标为(1,2)的位置。相似地,运算结果r(i+1)_t3是无效的运算结果。
接着,如图4d所示,在工作周期t4中,运算层li、l(i+1)的取样窗各自涵盖第i本地存储器与第(i+1)本地存储器中坐标为(2,2)、(3,2)、(2,3)、(3,3)的四个位置。第i运算电路会将本次的运算结果ri_t4存入第(i+1)本地存储器中坐标为(2,2)的位置,取代原本存放于该位置的数据。第(i+1)运算电路可其运算结果r(i+1)_t4存入第(i+2)本地存储器中坐标为(2,2)的位置。相似地,运算结果r(i+1)_t4是无效的运算结果。
如图5所示,多层人造神经网络200可进一步包含一控制器510,耦接至第i运算电路与第(i+1)运算电路。控制器510用以作废根据假数据产生的运算结果,并保留完全根据真实数据产生的运算结果。以图4呈现的情况为例,控制器510会请求第(i+1)运算电路作废运算结果r(i+1)_t2、r(i+1)_t3、r(i+1)_t4,仅保留运算结果r(i+1)_t1。实际上,控制器510可请求第(i+1)运算电路不实际进行产生运算结果r(i+1)_t2、r(i+1)_t3、r(i+1)_t4的运算,或是请求第(i+1)运算电路不将运算结果r(i+1)_t2、r(i+1)_t3、r(i+1)_t4继续向后传递至第(i+2)本地存储器。由于各运算层的输入数据矩阵的实际尺寸皆为预先所知,控制器510可明确掌握应作废哪些运算结果。实际上,控制器510可利用多种固定式或可程序化的逻辑电路实现,例如可程序化逻辑门阵列、针对特定应用的集成电路、微存储器、微处理器、数字信号处理器。此外,控制器510亦可被设计为通过执行一存储器(未绘示)中所存储的处理器指令来完成任务。
在图4a至图4d呈现的范例中,第i运算电路在工作周期t1至t4依序产生四笔运算结果ri_t1、ri_t2、ri_t3、ri_t4。至工作周期t4结束时,运算层li需要针对图4a中存储于第i本地存储器内的输入数据矩阵所进行的运算皆已完成。由图4e可看出,在工作周期t5开始时,运算层li稍早产生的运算结果ri_t1、ri_t2、ri_t3、ri_t4,也就是运算层l(i+1)接下来所需要的新的输入数据矩阵,皆已被存储在第(i+1)本地存储器中坐标为(1,1)、(2,1)、(1,2)、(2,2)的四个位置。另一方面,对应于运算层l(i+1)的可学习参数原本即已存放在第(i+1)本地存储器中。因此,第(i+1)运算电路可以直接开始进行运算工作,几乎或完全不需要等待数据转移,其运算资源因此可被充分利用。
须说明的是,上述范例呈现的概念可以被应用在各种尺寸的输入数据矩阵、各种尺寸的取样窗,以及各种尺寸的取样跨幅。于实际应用中,运算层li、l(i+1)实际上可能各自包含数万个人造神经元。由于高速串列器-解串列器等高速通信接口的传输速率可以达到每秒十吉赫位以上,即使第i运算电路同时产生数百或数千笔运算结果,运用图4a-图4e呈现的概念即时完成数据搬移仍是实际可行的。
须说明的是,前述“将运算结果ri_t1存入第(i+1)本地存储器”的动作,也可改放在工作周期t2中进行,甚至与“第i运算电路进行运算以产生运算结果ri_t2”平行进行。更广泛地说,假设第i运算电路依序产生q笔运算结果(q为大于1的整数),在第i运算电路将已产生的第(q-1)笔运算结果存入第(i+1)本地存储器时,可同时开始进行运算、产生第q笔运算结果(q为范围在2到q间的一整数指标)。藉此,整个运算流程需要的时间可被进一步缩短。
如先前所述,运算层l1至ln可利用多个完全相同的单位芯片来实现。除了串联之外,该等单位芯片也可以被并联使用。假设每个单位芯片能接收的输入数据最高数量为k、能产生的运算结果最高数量为j。如图6所示,数据分离电路610将收到的2*k笔数据分为两组k笔数据,并分别提供给单位芯片621、622进行处理。单位芯片621、622各自产生的j笔运算结果被向后传递,由数据结合电路630进行合并,并输出总数量为2*j的运算结果。依此类推,令一个运算层包含m个单位芯片(m为一正整数),便可以平行产生数量为m倍的运算结果。
上述并联单位芯片的概念可以用于卷积层,也可用于全连接层。图7呈现一种利用并联的p个单位芯片(p为一正整数)作为p个神经元以组成一全连接层的范例。单位芯片710_1至710_p的输入端都是接收相同的k笔输入数据,并且各自对该k笔输入数据施以加权运算、加总运算以及激发函数(activationfunction)运算。每个单位芯片各自产生一个运算结果,p个单位芯片总共产生p个运算结果out_1至out_p。
实际上,多层人造神经网络200中的运算层l1至ln不一定要全部用单位芯片实现。以包含五个卷积层及三个全连接层的alexnet为例,电路设计者可用前述单位芯片实现其中的五个卷积层,搭配以其他非单位芯片实现的三个全连接层。须说明的是,除了先前介绍的运算层l1至ln与控制器510外,根据本发明的人造神经网络可包含其他电路,例如但不限于连接在某些卷积层后的池化层(poolinglayer)及负责产生时脉信号的振荡器。本领域技术人员可理解,本发明的范畴不限于以某种特定组态或架构来实现。根据本发明的人造神经网络可实现但不限于以下几种此领域中常被使用的网络架构:由yannlecun提出的lenet、由alexkrizhevsky等人提出的alexnet、由matthewzeiler等人提出的zfnet、由szegedy等人提出的googlenet、由karensimonyan等人提出的vggnet,以及由kaiminghe等人提出的resnet。
以上所述仅为本发明的较佳实施例,凡依本发明权利要求所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!