一种以项集为序列元素的对比序列模式挖掘方法与流程
本发明涉及序列模式挖掘领域,具体地,涉及一种以项集为序列元素的对比序列模式挖掘方法。
背景技术:
序列模式挖掘作为数据挖掘的一个重要领域,吸引了大批研究者的关注。序列模式的多种子类被相继提了出来,例如频繁序列模式、闭合序列模式、偏序序列模式、对比序列模式、周期序列模式等等。在现实世界中,序列模式的应用领域相当广泛。例如,电子商务公司可以通过分析用户的购物记录,用于商品推荐;交通管理部门可以通过挖掘交通流量监控序列上道路的堵塞模式,以分析交通状况及其影响因素。通过对传染病疫情监测的时空序列数据,传染病防控研究人员可以分析出不同疾病在传播规律的不同之处;药物公司通过对致病基因或者蛋白质的研究寻找疾病临床表现的差异,然后以发现的致病机理为指导进行新药的研发。
在现有的序列模式挖掘工作中,间隔约束是一个常用的概念,其作用是使得序列模式的匹配更加灵活,并增强序列模式的实用性,还能增强序列模式对于序列集中噪声的抵抗性。间隔约束有很多种表述,通常而言我们用由两个非负整数确定的区间来定义间隔约束,区间的左右两个端点上对应的数值分别表示序列模式匹配过程中两个相邻元素在匹配序列中允许间隔的元素数目的最小值和最大值。例如,当间隔约束为[0,2]时,若有序列模式P=bc能在序列S中找到一个匹配,那么意味着序列S中存在元素b和元素c,并且存在一组偏序bc(即元素b在元素c之前),且这组元素b和元素c之间的间隔最少是0个元素(即相邻),间隔最多是2个元素。
假定一个场景:超市经理可以查看每位消费者的购物记录,其中每位消费者的购物记录均为一条以项集为序列元素的序列,序列记录了消费者在一段时间内购买的商品的信息,序列中的每个元素都是一个项集,元素中每个项都是一个商品的名称,元素表示该消费者在某次购物中购买商品名称的集合(即购物清单)。为了向已婚的客户提供个性化的服务,超市经理需要发掘并且利用已婚客户的消费偏好与未婚客户的消费偏好之间的差异。
上述场景中提到的序列模式挖掘问题不能通过现有的序列模式挖掘计算方法,或者对比序列模式挖掘计算方法来获得解答,这意味着该问题是一个新颖的问题,需要提出一个新的计算方法来解决它。在这类场景中,两类序列集中的每个序列都是一个以项集为元素的有序序列,在两类序列集中选择一个类作为目标类,我们想要挖掘出在目标类的序列集中频繁出现,但是在另外一个类的序列集中不频繁出现的以项集为序列元素的对比序列模式。与传统的元素是单个项的对比序列模式不同,这类序列模式的元素是项集的,因此我们将这类序列模式叫做以项集为序列元素的对比序列模式。同时我们在以项集为序列元素的对比序列模式中引入传统对比序列模式中常见的支持度阈值约束、最小化模式约束和间隔约束,就得到了间隔约束下基于项集的最小化对比序列模式(Itemset-based Minimal Distinguishing Sequential Patterns with Gap Constraint)问题。
学术界已有大量关于对比序列模式挖掘的计算方法,但是很遗憾的是这些计算方法的研究目标都是以项为序列元素的序列集,与本专利提出挖掘问题不同,其研究目标是以项集为序列元素的序列集。相比之前的工作,我们研究的以项集为序列元素的对比序列模式挖掘更具有通用性。
综上所述,本申请发明人在实现本申请实施例中发明技术方案的过程中,发现上述技术至少存在运行时间较长,执行效率偏低的技术问题。
技术实现要素:
由于已有对比序列模式挖掘计算方法是用于以项为序列元素的序列数据,序列的每个元素都必须是一个单一项(符号)。但是在现实世界绝大多数应用场景中,序列元素是由多个项组成的集合(项集)。针对此问题,本发明定义了一个新的数据挖掘问题,即间隔约束下以项集为序列元素的最小化对比序列模式问题(Itemset-based Minimal Distinguishing Sequential Pattern with Gap Constraint,iDSP),并提出了一个包含多个剪枝策略和一个类似于边界的精简表达方式(等价元素)的iDSP-Miner计算方法来解决该问题。
与已有研究的区别是,本专利考虑了以项集为序列元素的情况,是传统研究领域的扩展。此外,以项集为元素的序列模式挖掘在产生序列模式时会产生搜索空间的组合爆炸,为了避免序列模式搜索空间的组合爆炸,我们必须要为候选元素和序列模式找到一个更加精简的表达方式,以减少计算方法的运行时间。正是 有了上述关键不同点,iDSP问题的潜在应用和挖掘方法与以往的以项为序列元素的对比序列模式完全不同。
本发明提供了一种以项集为序列元素的对比序列模式挖掘方法,方法采用了基于等价元素的候选元素表达方式和剪枝策略等技术手段,解决了在现有技术中,现有的对比序列模式挖掘的计算方法存在计算运行时间较长,效率较低的技术问题,实现了以项集为序列元素的对比序列模式挖掘方法,达到了计算时间较短,效率提升的技术效果。
本申请提供了一种以项集为序列元素的对比序列模式挖掘方法,定义一个有穷的符号集合Σ,其中的任意符号t∈Σ为项,以项集为元素的序列是由Σ中项构成的项集组成的有序序列,表示为S=<e1,e2,…,en>,其中ei={t1,t2,…,tm}(1≤i≤n,),且tj∈Σ(1≤j≤m),P=<e1,e2,…,e|P|>是一个间隔约束下以项集为序列元素的最小化对比序列模式,其中P满足下列条件:
(1)支持度条件:Sup(P,D+)≥α,并且Sup(P,D–)≤β;
(2)最小化条件:对于任何序列P’不满足条件1;
所述方法包括:
步骤1:输入以项集为元素的正例序列集D+和负例序列集D–,间隔约束γ,正例支持度阈值α,负例支持度阈值β;
步骤2:基于步骤1输入的数据,扫描正例序列集D+、负例序列集D-,生成等价元素;
步骤3:基于等价元素生成候选序列模式;
步骤4:将候选序列模式进行去冗余处理,输出最小化对比序列模式。
进一步的,间隔约束γ为区间[γ.min,γ.max],γ.min≤γ.max,其中γ.min和γ.max分别表示间隔约束中允许的最小和最大间隔元素数目,γ.min和γ.max均大于等于0。
进一步的,在间隔约束γ下,序列P在序列集D中的支持度(记作Sup(P,D,γ))为:
其中,S为序列,|D|表示序列集D中的序列的数目,P在序列S中满足间隔约束γ的子序列,记为
进一步的,在间隔约束γ下,序列P在正例序列集D+与负例序列集D–之间的对比度,记作CR(P,D+,D–,γ):
CR(P,D+,D–,γ)=Sup(P,D+,γ)-Sup(P,D–,γ) (2)
进一步的,,生成等价元素具体步骤包括:
对于正例序列集D+和负例序列集D-,首先生成候选元素:
(1)对于序列集D+和序列集D-生成全部元素实例的集合E;
(2)对于集合E,生成元素闭包的集合
(3)对于且c’≠c,执行操作:
EC←EC\ε;EC←EC\ε’;EC←EC∪(ε|ε’),即将ε与ε’从集合中移除,然后将ε|ε’产生的两个新等价元素放入集合中;
(4)重复操作(3)直到集合中的任意两个等价元素之间不存在冗余;
进一步的,使用集合枚举树生成候选模式具体为:使用等价元素,按深度优先的方式遍历集合枚举树生成候选序列模式。
进一步的,采用三个剪枝策略对等价元素和集合枚举数进行处理,具体包括:
剪枝策略1:若等价元素ε满足Sup(ε,D+)<α,那么将等价元素ε从候选元素集合中移除;
剪枝策略2:若序列P满足Sup(P,D+)≥α和Sup(P,D–)≤β,那么将集合枚举树中与序列P对应节点的全部子孙节点移除;
剪枝策略3:若序列P满足Sup(P,D+)<α,那么序列P的连续超序列P’对应节点都被从集合枚举树中移除。
进一步的,所述方法还包括对将候选序列模式进行去冗余处理,具体为:在候选序列模式枚举结束之后,对于满足支持度阈值条件和最小化条件的序列模式,若多个序列模式所出现的序列完全相同,那么将这些序列模式合并成一个序列模式。
本申请实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
由于采用了基于等价元素的候选元素表达方式和剪枝策略等技术手段,避免 了枚举不满足条件的候选对比序列模式,提高了候选对比序列模式生成及评价的效率。从而有效地解决了在现有技术中,现有的对比序列模式挖掘的计算方法存在计算运行时间较长,效率较低的技术问题,实现了以项集为序列元素的对比序列模式挖掘方法,计算时间较短,效率较高的技术效果。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定;
图1是本申请实施例一中以项集为序列元素的对比序列模式挖掘方法的流程示意图;
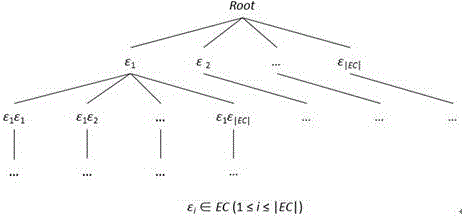
图2是本申请实施例一中集合枚举树示例示意图;
图3是本申请实施例一中等价元素示例示意图。
具体实施方式
本发明提供了一种以项集为序列元素的对比序列模式挖掘方法,解决了在现有技术中,现有的对比序列模式挖掘的计算方法存在计算运行时间较长,效率较低的技术问题,实现了以项集为序列元素的对比序列模式挖掘方法,计算时间较短,效率较高的技术效果。
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一:
在实施例一中,请参考图1-图3,提供了1、一种以项集为序列元素的对比序列模式挖掘方法,所述方法包括:
步骤1:输入以项集为元素的正例序列集D+和负例序列集D–,间隔约束γ,、正例支持度阈值α、负例支持度阈值β;
步骤2:基于步骤1输入的数据,扫描序列集,生成等价元素;
步骤3:基于等价元素生成候选序列模式;
步骤4:将候选序列模式进行去冗余处理,输出最小化对比序列模式。
为方便描述,首先定义本发明设计的算法的挖掘目标:间隔约束下以项集为序列元素的最小化对比序列模式。
给定一个有穷的符号集合Σ,我们将其称为字母表,字母表中的任意符号i∈Σ被称之为项。由Σ中项构成的项集组成的有序序列称为序列,表示为S=<e1,e2,…,en>,其中ei={t1,t2,…,tm}(1≤i≤n,),且tj∈Σ(1≤j≤m)被称为元素。我们使用|S|表示序列S的长度,即序列S中包含的元素的个数;使用|e|表示元素e的大小,即该元素包含的项的数目。给定两个元素e和e’,若满足 那么我们称元素e’是元素e的子元素。
我们用S[i]来表示序列S中的第i个元素(1≤i≤|S|)。对于序列S中的两个元素S[i]和S[j](1≤i≤j≤|S|),使用gap(S,i,j)来表示在序列S中这两个元素之间间隔的元素个数,即gap(S,i,j)=j-i-1。
对于任意两个序列S和S’,满足如下条件:
(1)|S|≥|S’|,即S的长度不小于S’的长度;
(2)存在一组数字1≤k1≤k2≤…≤k|S’|≤|S|,使得对于1≤i≤|S’|恒成立;
那么,我们称<k1,k2,…,k|S’|>是序列S’在序列S中的一个出现(也可以说序列S是序列S’的超序列;或者序列S’是序列S的子序列),记为注意,在序列S中,序列S’可能有多个出现。若k|S’|-k1=|S’|-1,那么我们称S’是S的连续子序列(或者序列S’是序列S的连续超序列)。
间隔约束γ被定义为一个区间[γ.min,γ.max](γ.min≤γ.max),其中γ.min(γ.min≥0)和γ.max(γ.max≥0)分别表示间隔约束中允许的最小和最大间隔元素数目。给定两个序列S和S’,令<k1,k2,…,k|S’|>是序列S’在序列S中一个出现。若有γ.min≤gap(S,ki,ki+1)≤γ.max对于任意1≤i<|S’|均成立,那么我们称序列S’是在序列S中满足间隔约束γ的子序列,表示为
给定一个序列集合D(又被称为序列集D),在间隔约束γ下,序列P在序列集D中的支持度用Sup(P,D,γ)来表示,其物理意义为序列集D中序列P的在 间隔约束γ下的超序列的数目与序列集D中序列的数目的比值,具体定义参照公式1。
其中|D|表示序列集D中的序列的数目。需要注意的是,对于任意的元素e(即长度为1的序列),其在序列集D中的支持度是独立于间隔约束γ的,我们使用Sup(e,D)来表示。
在间隔约束γ下,给定两个序列集,正例序列集D+与负例序列集D–,序列P在正例序列集D+与负例序列集D–之间的对比度用CR(P,D+,D–,γ)来表示,其意义是表示该序列在两个序列集之间的支持度的差异,具体定义参照公式2。
CR(P,D+,D–,γ)=Sup(P,D+,γ)-Sup(P,D–,γ) 公式2
类似于元素在序列集中的支持度Sup(e,D),元素在正例序列集D+与负例序列集D–之间的对比度也是独立于间隔约束γ的,我们使用CR(e,D+,D–)表示元素e的对比度。
给定两个序列集合,正例序列集D+和负例序列集D–,以及两个序列集中对应的支持度阈值约束,正例支持度阈值α(α>0)和负例支持度阈值β(β≥0),在间隔约束γ下,一个序列P=<e1,e2,…,e|P|>是一个间隔约束下以项集为元素的最小化对比序列模式,那么序列P应该满足如下条件:
(1)(支持度条件)Sup(P,D+)≥α,并且Sup(P,D–)≤β;
(2)(最小化条件)对任何序列不存在P’满足条件1。
在间隔约束γ下,给定的正例/负例序列集以及对应的正例/负例支持度阈值α/β,间隔约束下以项集为元素的最小化对比序列模式挖掘问题旨在找出全部满足间隔约束、正例支持度阈值/负例支持度阈值约束的以项集为元素的最小化对比序列模式。
本发明挖掘间隔约束下以项集为序列元素的最小化对比序列模式的主要步骤包括:(1)输入;(2)扫描序列集;(3)生成等价元素;(4)生成候选序列模式;(5)去冗余;(6)输出序列模式。
使用本发明提出的算法时只用输入两类序列样本集合D+和D–,D+的支持度阈值α,,D–的支持度阈值β,以及间隔约束γ,就可以得到在序列集D+和序列 集D–中的间隔约束下以项集为序列元素的满足支持度阈值条件的最小化对比模式,算法的执行流程如图1所示。
本发明通过枚举所有可能的候选序列模式来保证挖掘的无遗漏,即挖出所有满足间隔约束下以项集为序列元素的最小化对比序列模式。本发明采用在序列数据挖掘中广泛应用的集合枚举树方法(如图2所示)产生候选序列模式。对给定序列样本集合,若序列元素集合∑,集合枚举树依照集合元素的全序,枚举集合元素的所有可能组合。本发明按深度优先的方式遍历集合枚举树。
为提高枚举所有候选对比序列模式的效率,本发明设计了基于等价元素的候选元素表达方式和三个剪枝策略。
基于等价元素的候选元素表达方式。将候选元素中位置列表完全相同的元素合并成一个等价元素,从而减少了候选元素的数目,进而减少候选序列模式生成需要消耗的时间。
给定一个序列集D,对于任意序列S和序列S’(S∈D且S’∈D),若存在两个整数i和j使得元素e满足:
(1)1≤i≤|S|且1≤j≤|S’|;
(2)e=S[i]∩S’[j],且
那么,我们称元素e是序列集D中的一个元素实例。
给定一个元素e,元素e的元素闭包表示元素e的全部非空子元素的集合,表示为
等价元素本质上是一个元素的集合,其由:(1)一个元素c(我们将其称为闭合元素),以及(2)一个元素的集合X(我们将该集合中的元素称为排除元素),其形式为[X,c],其中
等价元素的生成策略:对于正例序列集D+和负例序列集D-,我们按照如下步骤生成候选元素:
(1)对于序列集D+和序列集D-生成全部元素实例的集合E;
(2)对于集合E,生成元素闭包的集合
(3)对于且c’≠c,执行操作:EC←EC\ε;EC←EC\ε’;EC←EC∪(ε|ε’),即将ε与ε’从集合中移除,然后将ε|ε’产生的两个新等价元素放入集合中;
(4)重复操作(3)直到集合中的任意两个等价元素之间都不存在冗余。
三个剪枝策略具体包括:
剪枝策略1:若等价元素ε满足Sup(ε,D+)<α,那么将等价元素ε从候选元素集合中移除;
剪枝策略2:若序列P满足Sup(P,D+)≥α和Sup(P,D–)≤β,那么将集合枚举树中与序列P对应节点的全部子孙节点移除;
剪枝策略3:若序列P满足Sup(P,D+)<α,那么序列P的连续超序列P’对应节点都被从集合枚举树中移除。
进一步减少冗余:为了进一步的减少挖掘出的序列模式之间的表达冗余,在候选序列模式枚举结束之后,对于满足支持度阈值条件和最小化条件的序列模式,若多个序列模式的出现位置完全相同,那么将这些序列模式合并成一个序列模式。
上述本申请实施例中的技术方案,至少具有如下的技术效果或优点:
由于采用了基于等价元素的候选元素表达方式和剪枝策略1、2、3等技术手段,避免枚举不满足条件的候选对比序列模式,提高了生成和评价候选对比序列模式的效率。从而有效地解决了在现有技术中,现有的对比序列模式挖掘的计算方法存在计算运行时间较长,效率较低的技术问题,实现了以项集为序列元素的对比序列模式挖掘方法,计算时间较短,效率较高的技术效果。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!