基于文本标签特征挖掘的网页正文提取方法与流程
本发明属于文本提取领域,特别涉及一种基于文本标签特征挖掘的网页正文提取方法。
背景技术:
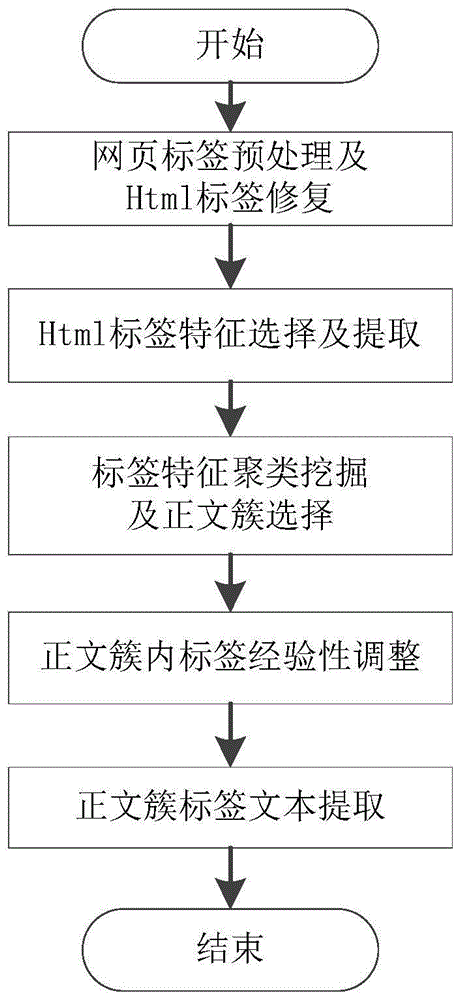
:随着Web应用的火速发展,人们正面临着“信息爆炸”带来的挑战,即是信息极大丰富,信息极速传播,而知识过于贫乏。随着最近两年国家极力号召“互联网+”,其将给人们带来更好的互联网体验,面对各式各样的网页,准确而迅速提取出网页的主题信息已经成为一个重要而有意义的研究方向。随着技术革新,Web逐渐成长为内容生产与消费平台,互联网上形成了无数以HTML网页形式存在的信息源,如导航条、广告、推荐链接、免责申明和版权声明等噪声信息,使得用户不能快速的找到自己所需要的信息,这些噪声数据也严重影响了网页解析程序对网页内容的解析效果。随着搜索引擎、网络舆情的监控以及智能Web等研究项目和应用的迅速展开,使得网页正文、图片和标题等内容的抽取研究受到广泛的关注,针对某一门户新闻网页进行文本提取相对简单,但是从任意网站中抽取新闻正文信息将是一个难题。所谓新闻文本采集即信息采集,是指从众多网页中将非结构化文本信息提取出来,并另存为结构化数据的过程。在新闻采集过程中主要涉及两大方面的研究:其一、网络爬虫。网络爬虫是通过发送HTTP协议请求来获取网页信息,像蜘蛛爬虫一样不间断的在互联网这张以链接为边、以网站网页为节点的网上爬行,故称之为蜘蛛网络爬虫。网络爬虫需要一个入口网页,在爬虫中一般称其为种子页面,然后对种子页面进行解析,获取其页面中包含的其它网页的超链接,再对这些网页的超链接解析,以此不间断的循环进行,直到满足爬虫停止条件。分布式爬虫和集中式爬虫作为网络爬虫的两大类,其划分依据为网页爬虫网页的方式。根据待爬取页面的先后爬取顺序,可分为三类:宽度优先搜索、深度优先搜索和聚焦最优优先策略,这是最常见的三种爬虫策略。其二、Web新闻网页正文文本提取。早在二十世纪六七十年代,信息抽取就作为自然语言处理的一个分支领域,开始探究如何从现有的自然语言文本中提炼出有用的结构化信息。该研究在当时风靡一时,众多研究者都投身其中,其中美国纽约大学开展的LinguisticString项目和耶鲁大学开展的有关故事理解的研究项目作为那个时代自然语言处理的杰出代表作品。目前主流Web网页正文提取技术大致分为三类:包装器、DOM树解析和文本特征方法。(1)基于包装器的网页解析方法,采用包装器解析网页主要是人为的确定不同网页解析的规则。该类方法首先对各个待解析网站设定对应的模板信息,比如正文标签名、链接匹配信息和正文结构化特征等。再根据提供的模板信息和解析规则得到该网站网页的包装器。目前该类方法主要的研究成果:基于模板的包装器处理和挖掘TSIMMIS[13]系统内信息的方法,包装器中的规则主要可以从三个方面获取,其一是通过全自动方法进行抽取活动;其二是在人工干预下运用半自动抽取方法进行规则提取;其三是完全人工抽取获得。此类方法实质上是根据匹配的方式和各式各样的解析规则进行网页正文文本信息提取,此类方法针对制式相对固定的网页具有很好的效果。由于互联网科学技术的飞速发展,HTML语言也日益变化,不同网站的数据源具有不同的特征,使得基于包装器的网页正文解析方法越来越难以适应了。包装器的方法对维护人员专业水平要求高,所以维护成本很高。(2)基于DOM树解析的方法,DOM树解析方法主要是从网页HTML源码入手对网页进行解析,方法首先将网页源码构建成一颗DOM树,其次是根据预先设定的各类规则将构建成的DOM树中无用的元素删去,然后通过权值计算树的每个子树的正文概率,根据概率值来确定网页正文信息所在区域块,从而获取正文内容。该方法典型代表:基于统计的网页正文信息抽取方法、基于机器学习的网页正文提取方法、逆序解析DOM树及网页正文信息提取方法和基于CURE算法的网页分块的正文提取方法。该方法要求网页HTML源码必须规范,而HTML语言具有开放性和随意性,网页HTML编写允许开发者犯错,比如标签缺失和标签不匹配等,这些错误都会导致DOM树构建失败。而且将网页源码转为DOM树耗时多,造成网页解析效率不高。(3)基于视觉特征的方法,该方法是把视觉的角度作为出发点,解析网页的结构特征,根据解析出的特点抽取网页正文文本内容。该方法代表成果:VIPS算法、基于分块的网页信息解析器的研究与设计和基于视觉特征的网页正文提取方法研究。Web技术的革新使其逐渐成为网络内容产生和消费的平台,互联网上充斥着无数以网页形式存在的信息源,而搜索引擎、网络监控和新闻个性化推送等应用和研究工作的深入发展,使得互联网新闻文本采集成为国内外相关人士研究的热点。Web页面中不仅包含用户关注的正文内容,还包含大量噪声信息,如广告、导航和相关推荐信息等,使得网页正文文本提取技术成为新闻文本采集的难题。传统的基于模板的网页正文提取不仅需要人工的配置各个网站的模板,而且不能实时的适应网页结构化的变化,使得后期维护成本较大。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种通过对网页源码进行标签挖掘,提取出正文标签所在的簇,再根据经验对标签簇内的标签进行调整,再根据调整后的正文簇特征进行文本提取,具有更好通用性、高准确率、易用性的基于文本标签特征挖掘的网页正文提取方法。本发明的目的是通过以下技术方案来实现的:基于文本标签特征挖掘的网页正文提取方法,包括以下步骤:S1、进行网页标签预处理及Html标签修复;S2、Html标签特征选择及提取;S3、标签特征聚类挖掘及正文簇选择;S4、正文簇内标签经验性调整;S5、正文簇标签文本提取。进一步地,步骤S1中采用字符串处理的方式来进行网页标签的预处理工作,具体包括以下子步骤:S11、字符串遍历开始位findIndex置为0,定义标签栈Stack,左标签Flag置为Flase;S12、遍历查询是否已经获取标签信息,若是进行步骤S14,否则进行步骤S13;S13、检查标签是否嵌套,若是则清空标签栈,删除左标签,结束预处理;否则判断左标签Flag是否为True,若左标签Flag为True则删除左标签信息并结束预处理,否则直接结束预处理;S14、检测是否具有右标签,若是则进行步骤S16,否则进行步骤S15;S15、检查标签是否嵌套,若是则将左标签信息压入标签栈,否则将左标签Flag置为True;S16、检查标签是否嵌套,若是则进行步骤S161,否则进行S162:S161、检查标签栈是否为空,若是则删除右标签信息并进行步骤S17,否则将左标签迁出标签栈并进行步骤S162;S162、检查左右标签之间的内容是否已经删除,若是则进行步骤S163,否则进行步骤S164;S163、检查左标签Flag是否为True,若是则删除左右标签间的全部内容,Flag置为False;否则删除右标签信息;S164、删除左右标签之间的全部内容,将Flag置为False;S17、将findIndex设置为右标签的结束位置,返回步骤S12。进一步地,左标签定义为Html标签的开始部分,右标签定义为Html标签的闭合部分。进一步地,步骤S1中的Html标签对修复的规则为:由于标签具有嵌套的特点,在修复标签对时运用数据栈进行标签存储,利用栈的特性完成标签对修复;针对转义字符的修复,通过字符串处理的方式进行字符反转义的,将其替换为相应的转义字符。进一步地,步骤S2的特征提取具体挖掘以下六个标签特征:标签ID、标签内容字符串长度、标签内容中标点符号数、左标签长度、右标签长度和标签层次;文本标签特征提取包括以下子步骤:S21、将字符串标签遍历开始位findIndex置0,标签内容查询开始位PostIndex置0,定义标签特征栈LableStack,左标签Flag置为Flase;S22、遍历查询是否已经获取标签信息,若是则进行步骤S23,否则结束文本标签特征提取操作;S23、查询是否具有右标签,若是则进行步骤S24,否则进行步骤S26;S24、检查标签栈是否为空,若是则进行步骤S241,否则进行步骤S242;S241、删除右标签之前的所有内容并将findIndex置0,然后返回步骤S22;S242、检测栈顶标签名是否等于右标签名并且检测栈顶标签是否为左标签,若是则取标签时间的文本内容,然后进行步骤S243;否则将findIndex置为右标签结束位,然后返回步骤S22;S243、检查文本内容是否为空或全字符,若文本内容为空或全字符则进行步骤S25,否则进行步骤S244;S244、构建标签结构体对象,标签进行自修正处理,将PostIndex置为标签内容的结束位;S245、检查标签是否具有自过滤机制,若是则进行步骤S25,否则进行步骤S246;S246、将标签结构体对象加入标签信息队列,然后进行步骤S25;S25、删除标签对之间的内容字符,将findIndex置为左标签开始位,将标签栈进行出栈操作,然后返回步骤S22;S26、检查标签栈是否为空,若是则进行步骤S261,否则进行步骤S262;S261、将左标签进行入栈操作并返回步骤S22;S262、取栈顶标签和左标签之间的文本内容;S263、检查文本内容是否为空或者全字符,若是则进行步骤S269,否则进行步骤S264;S264、构建标签结构体对象,将PostIndex置为标签内容结束位;S265、进行标签自补全处理和标签自修正处理;S266、检查标签是否具有自过滤机制,若是则进行步骤S268,否则进行步骤S267;S267、将标签结构体对象加入标签信息队列,然后进行步骤S268;S268、删除栈顶标签TopLable与左标签之间的内容tmpContent,利用左标签起始位参数减去tmpContent长度值;S269、将栈顶标签TopLable的LeafLabFlag参数置为Flase,将左标签进行入栈操作,并返回步骤S22。进一步地,步骤S3中标签特征聚类挖掘的具体实现方法为:将文本向量定为6维,分别为标签ID、标签文本长度、左标签长度、右标签长度、标签文本标点符号个数和标签层次数;遍历标签信息列表,将满足上诉规则的标签添加到标签向量矩阵中,获得一个N行6列的特征向量矩阵,然后将各维数据做归一化处理。进一步地,步骤S3中的正文簇采用AGENS层次聚类算法生成;正文簇的选择采用以下策略:将各个聚类簇中文本长度和标点符号数之和作为判断依据,取各个聚类簇中文本长度和标点符号数之和最大的Top标签信息,经对比实验后将Top选定为5,再计算取出的Top标签的加权平均值,获取对应的加权向量,如果某个聚类簇中的标签特征向量数量小于Top个,则取该聚类簇的中心向量做为加权向量,最后取加权向量中文本平均长度与平均标点数之和最大的聚类簇作为正文簇。进一步地,步骤S4包括以下子步骤:S41、获取正文标签名、标签层次数和确定为正文标签的标签ID,把确定为正文标签的标签ID作为中心扩展标签ID组;S42、遍历查询中心扩展标签ID组是否完成扩展,若是则进行步骤S45,否则进行步骤S43;S43、分别以标签ID为中心向前后扩展正文标签范围,形成待测标签子中心块;S44、对S43得到的待测正文标签子中心块进行合并以及选择:将ID连续的待测标签子中心块合并为一个待测标签子中心块;判断合并后的待测标签子中心块是否为确定为正文标签的正文标签子中心块,若是则对该待测标签子中心块进行合并,否则删除该待测标签子中心块;然后返回步骤S42;S45、组合所有正文子中心,并返回新的正文簇标签ID,结束调整。进一步地,步骤S44对于待测正文标签子中心块是否为确定为正文标签的正文标签子中心块的判定方法为:(1)针对合并后只有一个待测正文标签子中心块的情况,若待测正文标签子中心块内标签ID数量小于4个且标签ID分布在全标签信息ID的尾部,此时求取待测正文标签子中心块中标签文本的平均长度,如果标签文本平均长度小于预设值且网页的总标签数大于预设值时,判定该待测正文标签子中心块为非正文标签子中心块,将该子中心块删除;(2)针对合并后存在多个待测正文标签子中心块的情况,判定并清理单标签ID的子中心块:遍历所有子中心块,若某子中心块只有一个标签ID,且这个标签ID与其前后的标签ID不具有连续性,则将此待测正文标签子中心块判定为非正文标签子中心块,删除该待测正文标签子中心块。本发明的有益效果是:本发明的网页正文提取方法挖掘了网页树结构特性、正文标签的中心性、正文标签的连续性、正文标签层次性和Html修饰标签特征等特点,运用层次聚类算法对网页标签进行聚类,对标签进行权值计算以及经验性调整确定网页最终的正文标签簇,再通过正文标签簇提取正文,能够提高智能Web新闻文本采集系统中的可行性和提高获取文本信息的准确率,在网页正文提取方面具有通用性和智能化的优点,将聚类方法运用到网页文本提取中可以更加准确和智能的提取出网页半结构化信息,适用于各大门户新闻网页的正文提取。附图说明图1为本发明的网页正文提取方法流程图;图2为本发明的网页标签的预处理流程图;图3为本发明的文本标签特征提取流程图;图4为本发明的正文簇内标签经验性调整流程图。具体实施方式下面结合附图进一步说明本发明的技术方案。如图1所示,一种基于文本标签特征挖掘的网页正文提取方法,包括以下步骤:S1、进行网页标签预处理及Html标签修复;网页正文提取方法围绕网页文本标签特征展开,而网页标签中包含大量无用的噪声标签,故在提取标签特征前需要排除JavaScript语言的script标签、排除用于网页结构特征的style标签、排除noscript标签、排除注释内容标签、排除无用的表格span标签及其内部列表li标签、排除文本格式修饰标签及换行标签等噪声标签。根据后文需要,在标签预处理过程中删除标签要考虑两种情况:一、标签及标签之间的内容都要清理;二、只清理标签信息,标签之间内容不清理。第一种包含的标签有:html、script、noscript、style、注释等标签;第二种包含的标签有:span、strong、br、nbsp、em、b等标签,其内容可以规划到上一个标签对中。本发明采用字符串处理的方式来进行网页标签的预处理工作,在此要声明两个定义:一、左标签:Html标签的开始部分,例如<script>;二、右标签:Html标签的闭合部分,例如</script>。根据Html语言特点和标签处理的需求,本文定义标签结构体如下:根据不同的Html标签的特点不同,预处理标签时可以分为两种情况:(1)待清理的Html标签不具有嵌套性质,可以直接找到该标签的开始标签和结束标签,根据上述删除标签的两种情况进行标签清理。(2)待清理标签具有嵌套性质,即如<p><p></p></p>标签嵌套情况,针对这种情况本方法将借用栈的思想获取完整嵌套标签对。根据上述删除标签的两种情况进行处理,循环遍历网页源码字符串,直到不再存在待删除的标签信息。本步骤中采用字符串处理的方式来进行网页标签的预处理工作,如图2所示,具体包括以下子步骤:S11、字符串遍历开始位findIndex置为0,定义标签栈Stack,左标签Flag置为Flase;S12、遍历查询是否已经获取标签信息,若是进行步骤S14,否则进行步骤S13;S13、检查标签是否嵌套,若是则清空标签栈,删除左标签,结束预处理;否则判断左标签Flag是否为True,若左标签Flag为True则删除左标签信息并结束预处理,否则直接结束预处理;S14、检测是否具有右标签,若是则进行步骤S16,否则进行步骤S15;S15、检查标签是否嵌套,若是则将左标签信息压入标签栈,否则将左标签Flag置为True;S16、检查标签是否嵌套,若是则进行步骤S161,否则进行S162:S161、检查标签栈是否为空,若是则删除右标签信息并进行步骤S17,否则将左标签迁出标签栈并进行步骤S162;S162、检查左右标签之间的内容是否已经删除,若是则进行步骤S163,否则进行步骤S164;S163、检查左标签Flag是否为True,若是则删除左右标签间的全部内容,Flag置为False;否则删除右标签信息;S164、删除左右标签之间的全部内容,将Flag置为False;S17、将findIndex设置为右标签的结束位置,返回步骤S12;由于Html标签对大小写不敏感,为了本文方法的处理考虑,故在标签预处理前将全部标签转换成小写,如<SCRIPT></SCRIPT>改为<script><script>。常见的Html源代码不规范主要包含标签缺失和特殊字符转义。Html语言中字符与转义序列如表1所示。表1常见转义序列表针对标签缺失而言,为了保证下文标签特征提取的完备性,在标签预处理之后需要对网页进行标签对缺失修复。标签对修复规则:由于标签具有嵌套的特点,在修复标签对时运用数据栈进行标签存储,利用栈的特性完成标签对修复;针对转义字符的修复,由于网页源文本是经过网页转码的,如果不进行相应的反转义,后文中提到的文本将出现转义序列,为了避免这种情况,通过字符串处理的方式进行字符反转义的,将其替换为相应的转义字符。S2、Html标签特征选择及提取;通过对新闻网页正文标签特点的总结,特征提取具体挖掘以下六个标签特征:标签ID、标签内容字符串长度、标签内容中标点符号数、左标签长度、右标签长度和标签层次,其中标签ID依次递增,用于标签位置索引,也是衡量新闻网页正文标签中心化特点。根据特征工程所选特征情况,本申请在提取过程中定义了以下标签信息结构体,用于存储标签信息,将网页源码中有用信息存储在标签结构体列表中,文本正文信息抽取做备份。标签信息结构体如下:structlableFeature{stringlableName;//标签名stringlableContent;//标签文本内容stringlableLeftPartContent;//左标签内容intlableBeginIndex;//左标签的开始位置intlableEndIndex;//右标签的结束位置intlableId;//标签IDintlableContentLength;//标签文本长度intlableLeftPartLength;//左标签长度intlableRightPartLength;//右标签长度intlablePunctNumber;//标签中标点符号的数量vector<string>lableAttributeVector;//标签存在的属性intlableLevelNumber;//标签层次树};在标签信息提取过程中如何确保正确的提取层次数和内容信息是一大难点,通过下文特征挖掘和正文提取的要求,在标签信息提取过程中针对特殊情况采用三种处理方式,分别为标签自补全处理、标签自修正处理和标签自过滤处理。标签自补全处理是为了解决“未知消息”的提取及在全字符串中准确定位而添加的,当获取左标签div后,紧接着会获取左标签h1时,此时为了保证后续标签坐标的准确性,需要将“未知消息”信息提取出来,做为一个div标签信息,就类似于在<h1>之前加入了“</div><divid=article>”,将左标签h1的起始坐标都减去“未知消息”的长度,如果“未知消息”信息为空,则跳过这一步。标签自修正处理是为了解决各个网站中网页自带的网站信息标签,如果标签内容中含有“AllRightsReserved”、“【免责声明】”、“allrightsreserved”等任一字符串,方法中将自动将标签名改为a标签,因为在后续的机器学习过程中,a标签不参与训练,也就不会对正文簇选择造成影响,从而避免将网站信息规划到正文簇中。标签自过滤处理是为解决空标签、标签内容全为标点符号或者且标签名为i且标签内容含有“http://….sohu.com…”的情况,此类标签信息对正文提取没有任何作用。在标签信息提取过程中将对此类标签进行过滤,并在预处理后的网页源码字符串中将其删除。如图3所示,本发明的文本标签特征提取包括以下子步骤:S21、将字符串标签遍历开始位findIndex置0,标签内容查询开始位PostIndex置0,定义标签特征栈LableStack,左标签Flag置为Flase;S22、遍历查询是否已经获取标签信息,若是则进行步骤S23,否则结束文本标签特征提取操作;S23、查询是否具有右标签,若是则进行步骤S24,否则进行步骤S26;S24、检查标签栈是否为空,若是则进行步骤S241,否则进行步骤S242;S241、删除右标签之前的所有内容并将findIndex置0,然后返回步骤S22;S242、检测栈顶标签名是否等于右标签名并且检测栈顶标签是否为左标签,若是则取标签时间的文本内容,然后进行步骤S243;否则将findIndex置为右标签结束位,然后返回步骤S22;S243、检查文本内容是否为空或全字符,若文本内容为空或全字符则进行步骤S25,否则进行步骤S244;S244、构建标签结构体对象,标签进行自修正处理,将PostIndex置为标签内容的结束位;S245、检查标签是否具有自过滤机制,若是则进行步骤S25,否则进行步骤S246;S246、将标签结构体对象加入标签信息队列,然后进行步骤S25;S25、删除标签对之间的内容字符,将findIndex置为左标签开始位,将标签栈进行出栈操作,然后返回步骤S22;S26、检查标签栈是否为空,若是则进行步骤S261,否则进行步骤S262;S261、将左标签进行入栈操作并返回步骤S22;S262、取栈顶标签和左标签之间的文本内容;S263、检查文本内容是否为空或者全字符,若是则进行步骤S269,否则进行步骤S264;S264、构建标签结构体对象,将PostIndex置为标签内容结束位;S265、进行标签自补全处理和标签自修正处理;S266、检查标签是否具有自过滤机制,若是则进行步骤S268,否则进行步骤S267;S267、将标签结构体对象加入标签信息队列,然后进行步骤S268;S268、删除栈顶标签TopLable与左标签之间的内容tmpContent,利用左标签起始位参数减去tmpContent长度值;S269、将栈顶标签TopLable的LeafLabFlag参数置为Flase,将左标签进行入栈操作,并返回步骤S22。S3、标签特征聚类挖掘及正文簇选择;通过文本特征提取过程获取到网页文本的所有标签信息以及后文中将根据标签ID的连续性进行文本簇的经验性调整,故标签特征向量中需要保留标签ID作为标识,本发明将文本向量定为6维,分别为标签ID、标签文本长度、左标签长度、右标签长度、标签文本标点符号个数和标签层次数。遍历标签信息列表,将满足上诉规则的标签添加到标签向量矩阵中,获得一个N行6列的特征向量矩阵,然后将各维数据做归一化处理。HTML网页的不同部分文本信息的特征不同,本发明比较了以下几个聚类算法的优缺点:K-Means及其演变的K-Means++聚类算法,二分K均值聚类算法和AGENS层次聚类算法。在经过对比实验后,层次聚类算法进行聚类能更多的把正文标签聚到一个标签簇中。对实验结果统计后,选择AGENS层次聚类算法生成正文簇,对后文的文本正文提取正确率提升最大也最稳定。正文簇的选择采用以下策略:本发明针对网页正文簇的选择提供两种策略,如下所述:策略一:根据各个聚类簇中心向量的标签文本平均长度与平均标点数之和来确定,取和最大的聚类簇做为正文簇,在网页文本标签特征聚类完成后,各个聚类簇都有一个聚类中心向量,在标签层次聚类过程中K值的选取会影响到最终的聚类结果,当新闻文本标签数很少且特征不是特别明显的时候,K值选取就变的尤其重要,选择合适的K值才能很好的将正文标签聚到同一个簇中,当K值选取不合理时,则包含文本标签的簇中会含有很多噪声标签,此时根据聚类中心向量进行正文簇选择,其选取正文簇的错误概率将增大。策略二:根据新闻网页正文标签文本的长文性和具有分段分句的特点,各个聚类簇中文本长度和标点符号数之和作为判断依据,取各个聚类簇中文本长度和标点符号数之和最大的Top标签信息,经对比实验后将Top选定为5,再计算取出的Top标签的加权平均值,获取对应的加权向量,如果某个聚类簇中的标签特征向量数量小于Top个,则取该聚类簇的中心向量作为加权向量,最后取加权向量中文本平均长度与平均标点数之和最大的聚类簇做为正文簇。对于上述两种选择策略进行试验的结果如表2所示。表2策略网页数量(个)选择正确数(个)选择错误数(个)正确率一5004831796.6%二500498299.6%故本发明选择策略二进行对正文簇进行选择。S4、正文簇内标签经验性调整;如图4所示,具体包括以下子步骤:S41、获取正文标签名、标签层次数和确定为正文标签的标签ID,把确定为正文标签的标签ID作为中心扩展标签ID组;S42、遍历查询中心扩展标签ID组是否完成扩展,若是则进行步骤S45,否则进行步骤S43;S43、分别以标签ID为中心向前后扩展正文标签范围,形成待测标签子中心块;S44、对S43得到的待测正文标签子中心块进行合并以及选择:通过S43的正文中心扩展,理论而言S43确定多少个正文标签ID就会形成多少个正文标签子中心块,但有些子中心块的ID是连续的,实现过程中将连续的子中心块合并为一个;由于S41判定为正文标签ID只是通过特征聚类后按照一定规则获取的,会出现误判情况,这种情况下通过误判的“正文标签ID”进行中心扩展获取的子中心块将不是真正的正文标签子中心块,故在正文标签子中心块合并的过程中需要添加适当的选择策略。具体方法为:将ID连续的待测标签子中心块合并为一个待测标签子中心块;判断合并后的待测标签子中心块是否为确定为正文标签的正文标签子中心块,若是则对该待测标签子中心块进行合并,否则删除该待测标签子中心块;然后返回步骤S42;对于待测正文标签子中心块是否为确定为正文标签的正文标签子中心块的判定方法为:(1)针对合并后只有一个待测正文标签子中心块的情况,若待测正文标签子中心块内标签ID数量小于4个且标签ID分布在全标签信息ID的尾部,此时求取待测正文标签子中心块中标签文本的平均长度,如果标签文本平均长度小于预设值且网页的总标签数大于预设值时,判定该待测正文标签子中心块为非正文标签子中心块,将该子中心块删除;(2)针对合并后存在多个待测正文标签子中心块的情况,判定并清理单标签ID的子中心块:遍历所有子中心块,若某子中心块只有一个标签ID,且这个标签ID与其前后的标签ID不具有连续性,则将此待测正文标签子中心块判定为非正文标签子中心块,删除该待测正文标签子中心块。S45、组合所有正文子中心,并返回新的正文簇标签ID,结束调整。S5、正文簇标签文本提取,提取步骤S4得到的正文标签。下面是用本发明的方法进行的三组实验,其结果如表3所示:表3正文提取正确率实验组网页数(个)正确数(个)错误数(个)正确率(个)一10009693196.9二10009663496.6三10009752597.5通过实验结果可以得出以下结论:(1)在正文提取正确率方面,三组实验结果的正确率都保持在96%以上,平均正确率未97%,相比于其他的正文提取方法而言,正确率已经很可观;再进一步对出错的网页进行分析,可以发现大约一半出错的网页有相似的特征,它们的正文标签中的文本都很短而且整个网页的正文文本也很短,有的正文只有一句话简单的语句,有的网页属于图片新闻,其中含有一小部分描述图片的文字信息,这类网页含的正文文本信息较少,与通常的新闻网页的特征差异很大,如果排除这类网页,总体的正确率可以达到98%以上,如果单纯的考虑新闻文本的采集,这个正确率已相当可观。(2)测试数据集是从不同网站随机选择的网页,网页的解析正确率都能保持在一个很高水准,说明该方法适用于各类网站的网页,而不是只适用于特定网页,所以方法具有通用性也得以验证。综合上面的实验结果可以看出,该基于文本标签特征挖掘的网页正文提取方法具有通用性的同时,又保证很高的正确率。在实际应用中,对来自100多个网站的网页进行正文提取,其正确率依旧保持在96%以上,网页处理效率可观,进一步验证了该网页正文提取方法具有实用性和可靠性。目前比较常用的非模版正文解析方法的正确率大约在89%到95%左右。可见本方法的正确率很可观,适用于新闻文本采集过程中。通过对网页源码进行标签挖掘,运用机器学习相关算法进行聚类,提取出正文标签所在的簇,再根据经验对标签簇内的标签进行调整,再根据调整后的正文簇特征进行文本提取。本方法相对于其他新闻网页文本抽取方法而言,具有更好的通用性、高准确率、易用性,不用针对特定网页做任何特殊设定。本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1