一种应用于海量数据全文检索系统的测试工具及测试方法与流程
本发明属于海量数据全文检索系统测试方法领域,具体涉及一种应用于海量数据全文检索系统的测试工具及测试方法。
背景技术:
近年,随着计算机技术和互联网的不断发展,企业信息量不断增加,信息的种类也在不断的扩展,越来越多的非结构化信息不断出现,包括企业的各种报表、帐单、电子文档、网站的各种元素、图片、传真、扫描影像,以及大量的多媒体的音频、视频信息等等。所有的存储数据中,有85%采用的是非结构化格式,非结构化信息每三个月增长一倍,导致对海量信息进行传输、存储和检索的场景日益增多。
由于信息格式的差异很大,所以基本无法整合为统一的接口供政府工作人员或广大群众方便使用。在这种背景下,全文检索技术也急需迅速发展,促使了全文检索系统的出现,
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。全文检索系统的核心则具有建立索引、处理查询返回结果集、增加索引、优化索引结构等功能。
针对海量数据全文检索系统的测试,需要精确地对此类系统进行检索,以提高准确率及性能评价尤为重要。
技术实现要素:
本发明为了解决海量数据全文检索系统在读写性能、语种识别、关键字检索性能等方面准确率低以及稳定性方面测试复杂的问题,提出了一种应用于海量数据全文检索系统的测试工具及测试方法,使测试变得简单且精确。
一种应用于海量数据全文检索系统的测试工具,包括顺序写入/读取模块、随机写入/读取模块、循环写入/读取模块、语种识别模块、关键字检索对比模块、删除模块和并发模块;每个模块单独连接海量数据全文检索系统。
顺序写入/读取模块用于在全文检索系统中,顺序写入和读取不同文件块大小、不同文件大小的数据;
随机写入/读取模块用于在全文检索系统中,随机写入和读取不同文件块大小、不同文件大小的数据;
循环写入/读取模块用于对全文检索系统,进行长时间大压力地循环写入或循环读取不同的数据文件;
语种识别模块用于对全文检索系统中写入文件的语种进行识别;
关键字检索对比模块用于对全文检索系统中,写入的原始文件与检索结果进行对比,得出全文检索系统中关键字检索的准确率,并统计全文检索系统进行关键字检索使用的时间;
删除模块用于删除指定全文检索系统中的文件;
并发模块用于模拟多用户同时对全文检索系统进行并发操作。
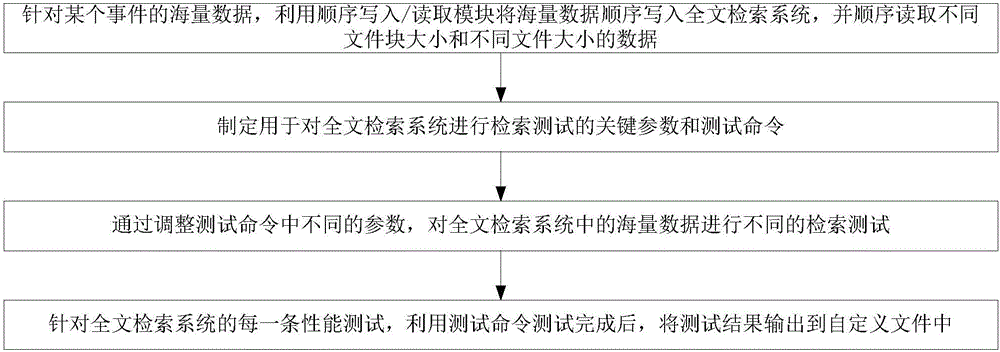
一种应用于海量数据全文检索系统的测试方法,具体步骤如下:
步骤一、针对某个事件的海量数据,利用顺序写入/读取模块将海量数据顺序写入全文检索系统,并顺序读取不同文件块大小和不同文件大小的数据;
步骤二、制定用于对全文检索系统进行检索测试的关键参数和测试命令;
测试命令为:
./Texttest[-i][-r][-s][-l][-t][-T][-K][-L][-F file1file2...][-f path][-o file];
Texttest:工具名称;
-i:读写模式,0顺序写,1顺序读,2随机写,3随机读;
-r:指定测试文件块大小,单位为KB。也可以指定单位-r#b(bytes)或-r#k(Kbytes)或-r#m(Mbytes);
-s:指定测试文件大小,单位为KB。也可以指定单位-s#K(Kbytes)或-s#M(Mbytes)或-s#G(Gbytes);
-l:循环次数;
-t:文件存储操作与关键字检索操作的间隔时间,单位为秒(s);
-T:并发进程数量;
-K:指定测试关键字,使用”括起来;
-L:输出识别到的语种类型;
-F:(file1file2...)指定并发线程下测试的文件名,与-T配合使用;
-f:(path)输入文件的存储路径;
-o:(file)输出结果文件的存储路径及名称;
步骤三、通过调整测试命令中不同的参数,对全文检索系统中的海量数据进行不同的检索测试;
测试包括以下七条:
1)、利用顺序写入/读取模块,对海量数据进行顺序写入和读取,实现全文检索系统的顺序读写性能测试;
2)、利用随机写入/读取模块,对海量数据进行随机写入和读取,实现全文检索系统的随机读写性能测试;
3)、利用语种识别模块,对海量数据进行语种识别,实现据全文检索系统文件内容的语种识别能力测试;
4)、利用关键字检索对比模块,对海量数据进行检索,实现全文检索系统文件内容的关键字检索性能测试;
5)、利用关键字检索对比模块,将海量数据与检索结果进行对比,实现全文检索系统文件内容的关键字检索准确率测试;
6)、利用关键字检索对比模块和并发模块,模拟多用户同时对海量数据进行并发操作,实现全文检索系统多进程并发关键字检索性能测试;
7)、利用循环写入/读取模块进行全文检索系统的稳定性测试;
步骤四、针对全文检索系统的每一条性能测试,利用测试命令测试完成后,将测试结果输出到自定义文件中。
本发明的优点在于:
(1)一种应用于海量数据全文检索系统的测试工具,包括对语种识别测试、关键字检索准确率测试、读写性能及稳定性测试,一个工具即可完成对上述测试项的测试,且使用简单。
(2)一种应用于海量数据全文检索系统的测试工具,具有很强的实用性,具有很广泛的应用前景。
(3)一种应用于海量数据全文检索系统的测试方法,只需输入较少的命令即可,自动收集测试结果,形成文件。
附图说明
图1是本发明一种应用于海量数据全文检索系统的测试工具示意图;
图2是本发明一种应用于海量数据全文检索系统的测试方法流程图;
图中:1-顺序写入/读取模块;2-随机写入/读取模块;3-循环写入/读取模块;4-语种识别模块;5-关键字检索对比模块;6-删除模块;7-并发模块。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明一种应用于海量数据全文检索系统的测试工具,如图1所示,包括顺序写入/读取模块1、随机写入/读取模块2、循环写入/读取模块3、语种识别模块4、关键字检索对比模块5、删除模块6和并发模块7。每个模块单独连接海量数据全文检索系统。
通过顺序写入/读取模块1可以向全文检索系统中顺序写入或者读取不同文件块大小、不同文件大小的数据;
通过随机写入/读取模块2可以向全文检索系统中随机写入或者读取不同文件块大小、不同文件大小的数据;
通过循环写入/读取模块3可以对全文检索系统长时间大压力地循环写入或读取不同文件块大小、不同文件大小的数据文件;
通过语种识别模块4可以对全文检索系统中相应的文件内容进行语种的识别,并与原始文件进行对比;
通过关键字检索对比模块5,通过全文检索系统中检索出来的关键字次数和位置,与原始文件进行对比,得出全文检索系统中关键字检索的准确率,并统计检索操作所用的时间;
通过删除模块6可以删除全文检索系统中指定的数据文件;
通过并发模块7可以模拟多用户同时对全文检索系统进行操作。
一种应用于海量数据全文检索系统的测试方法,支持对海量数据全文检索系统和类似软件的测试,可以使对此类系统和软件的测试变得简单且准确。
如图2所示,具体步骤如下:
步骤一、针对某个事件的海量数据,利用顺序写入/读取模块将海量数据顺序写入全文检索系统,并顺序读取不同文件块大小和不同文件大小的数据;
步骤二、制定用于对全文检索系统进行检索测试的关键参数和测试命令;
关键参数包括:四种读写模式参数-i,指定测试文件块大小参数-r,指定测试文件大小参数-s,循环次数-l,文件存储操作与关键字检索操作的间隔时间-t,并发进程数量-T,指定测试关键字-K,输出识别到的语种类型-L,指定并发线程下测试的文件名-F,输入文件的存储路径-f,输出结果文件的存储路径及名称-o。
通过调整测试命令中不同的参数,进行不同的测试。测试命令(字母区分大小写)为:
./Texttest[-i][-r][-s][-l][-t][-T][-K][-L][-F file1file2...][-f path][-o file];
Texttest:工具名称;
-i:读写模式,0顺序写,1顺序读,2随机写,3随机读;
-r:指定测试文件块大小,单位为KB。也可以指定单位-r#b(bytes)或-r#k(Kbytes)或-r#m(Mbytes);
-s:指定测试文件大小,单位为KB。也可以指定单位-s#K(Kbytes)或-s#M(Mbytes)或-s#G(Gbytes);
-l:循环次数;
-t:文件存储操作与关键字检索操作的间隔时间,单位为秒(s);
-T:并发进程数量;
-K:指定测试关键字,使用”括起来;
-L:输出识别到的语种类型;
-F:(file1file2...)指定并发线程下测试的文件名,与-T配合使用;
-f:(path)输入文件的存储路径;
-o:(file)输出结果文件的存储路径及名称;
步骤三、通过调整测试命令中不同的参数,对全文检索系统中的海量数据进行不同的检索测试;
测试支持的操作系统为linux、unix,具体包括:
1)、利用顺序写入/读取模块,对海量数据进行顺序写入和读取,实现全文检索系统的顺序读写性能测试;
向全文检索系统顺序写入数据文件,然后再按顺序读取数据文件,对全文检索系统进行顺序读写性能测试,测试完成后把读写性能结果输出到指定文件中;
2)、利用随机写入/读取模块,对海量数据进行随机写入和读取,实现全文检索系统的随机读写性能测试;
向全文检索系统随机写入数据文件,然后再随机读取数据文件,对全文检索系统进行随机读写性能测试,测试完成后把读写性能结果输出到指定文件中;
3)、利用语种识别模块,对海量数据进行语种识别,实现全文检索系统文件内容的语种识别能力测试;
向全文检索系统写入指定文件,然后对该文件进行语种识别,对全文检索系统进行语种识别能力测试,测试完成后把语种识别结果输出到指定文件中;
4)、利用关键字检索对比模块,对全文检索系统中的海量数据进行检索,实现全文检索系统数据内容的关键字检索性能测试;
向全文检索系统写入指定文件,然后对该文件进行关键字检索,对全文检索系统进行关键字检索性能测试,测试完成后把检索性能结果输出到指定文件中;
5)、利用关键字检索对比模块,将海量数据原始文件与检索结果进行对比,实现全文检索系统文件内容的关键字检索准确率测试;
向全文检索系统写入指定文件,然后对该文件进行关键字检索,并把检索结果与原文件进行对比,对全文检索系统进行关键字检索准确率测试,测试完成后把检索准确率结果输出到指定文件中;
6)、利用关键字检索对比模块和并发模块,模拟多用户同时对全文检索系统进行并发关键字检索操作,实现全文检索系统多进程并发关键字检索性能测试;
向全文检索系统顺序写入文件,然后模拟多用户同时对全文检索系统进行关键字检索测试,对全文检索系统进行多进程下的关键字检索性能测试,测试完成后把并发检索性能结果输出到指定文件中;
7)、利用循环写入/读取模块进行全文检索系统的稳定性测试;
根据全文检索系统的空间大小设置写入数据量,每次顺序写入不同的数据文件,每个文件写完后进行读取,读取完成后对该文件进行删除。重复对全文检索系统进行长时间的写入、读取和删除操作,以测试全文检索系统的稳定性,每一次写入、读取和删除的性能结果输出到指定的文件中,得到写入、读取和删除的性能变化曲线。
步骤四、针对全文检索系统的每一条性能测试,利用测试命令测试完成后,将测试结果输出到自定义文件中。
为了检测七条测试性能,可以用一条到七条测试命令完成。
测试结束后自动显示测试结果;
实施例:
(1)对海量数据全文检索系统进行顺序读写性能测试;
使用测试工具向海量数据全文检索系统内顺序写入数据,再按一定顺序读取这些数据,需要指定的参数如下:顺序写、顺序读、测试文件块大小、测试文件大小、循环次数、输出结果文件路径及名称;举例说明测试命令:
./Texttest-i 0-i 1-r 1024k-s 50G-l 10-o./result.log
测试完成后把测试结果输出到result.log文件中;通过调整不同的参数可达到不同的测试目的。
(2)对海量数据全文检索系统进行检索性能测试;
使用测试工具向海量数据全文检索系统写入一些文件,再按指定关键字进行检索测试,需要指定的参数如下:输入文件的存储路径、存储与检索的间隔时间、指定测试关键字、输出结果文件的存储路径及名称;举例说明测试命令:
./Texttest-f/mnt/sdb/testdata/-t 300-K'北京'-o./result.log。
- 还没有人留言评论。精彩留言会获得点赞!