一种面向具有学习恶化效应无等待流水调度问题的方法与流程
本发明涉及一种面向具有学习恶化效应无等待流水调度问题的方法,属于复杂调度计算技术领域。
背景技术:
无等待流水调度问题是调度问题中的一类重要分支。该问题源自特定产品要求任务的各工序紧密连接的生产制造特性,也就是要求任务从开始加工到结束必须连续执行,任务在各机器上的加工均不能出现等待。这一要求有时会造成某些任务在特定机器上的开工时间推迟到前一个工序完成时。该问题具有重要的现实意义,广泛应用于如化工生产、塑模成型、食品生产和钢材轧制等生产制造领域。例如,在钢材轧制生产中,钢锭不能在各生产工序间等待,否则会造成钢锭冷却无法加工。
学习和恶化效应大多是由人类或具有学习恶化效应的机器参与生产制造而产生的,在许多实际生产制造系统中普遍存在。例如,工人们会由于多次重复操作而提高技能,从而更快地完成如机器的操作、原材料的处理等任务;与之相反,工人们可能因为工作的中断而忘记部分技能,或机器与其零部件由于老化而增加工序的处理时间。
关于具有学习恶化效应的无等待流水调度问题,目前少有研究。然而,这一效应又在现实应用场景中广泛存在,具有深入研究的意义。本发明中将提出一种面向具有学习恶化效应无等待流水调度问题的方法,以期有效地解决该问题,最小化调度的总延迟。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种面向具有学习恶化效应无等待流水调度问题的方法,结合问题本身无等待和具有学习恶化效应的特征,采用迭代局部搜索方法框架,最小化调度的总延迟目标函数。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种面向具有学习恶化效应无等待流水调度问题的方法,对加工工序利用无等待流水调度问题的特点和基于位置的学习恶化效应函数的特点,建立无等待流水调度学习恶化效应模型。基于迭代局部搜索方法最小化求解该无等待流水调度学习恶化效应模型的总延迟目标函数,得出任务在调度中处于不同位置时的实际处理时间,进而得到当前的最优加工工序。
具体包括以下步骤:
步骤1.获取待加工工序和基于位置的学习恶化效应函数,根据无等待流水调度的特点,任务的完工时间表示为该任务完工之前各任务的完工时间距离之和,而各工序的实际加工时间将根据给定的学习恶化效应得到,则根据给定的学习恶化效应得到的实际加工时间得到实际任务的完工时间,根据实际任务的完工时间建立无等待流水调度学习恶化效应模型的总延迟目标函数。
步骤2.初始解生成:将初始解π0初始化为一个空的调度,在空调度π0中插入位于起始处的虚任务π[0]。将任务集
步骤3.局部搜索:对于当前调度π,每次随机选取一个位置k,k=1,2,...,n,对当前调度π应用前向交换算子afs(π,k)和后向交换算子abs(π,k),分别得到经过前向交换算子应用后的调度πafs和经过后向交换算子应用后的调度πabs,分别将经过前向交换算子应用后的调度πafs和经过后向交换算子应用后的调度πabs与当前调度π比较,从中选取最优的调度作为新的当前调度π,直到所有位置都已被选取并操作完成。若新的当前调度π优于全局最优调度π*,则用新的当前调度π更新全局最优调度π*,并重复以上过程,否则进入步骤4。
步骤4.停止条件判断:判断方法执行过程是否达到了方法停止条件,如达到,则方法停止执行,返回全局最优调度π*,否则进入步骤5。
步骤5.扰动:对于当前调度π,利用移除插入算子ri(π,i,j)随机选取当前调度π中的任一一个任务,移除该任务并插入新的随机位置j,反复进行该操作,得到一个临时调度π′。
步骤6.局部搜索:对临时调度π′重复步骤3中过程,得到新的临时调度π″。
步骤7.接受准则:若新的临时调度π″优于当前调度π,则用新的临时调度π″更新当前调度π,否则,以一定的概率用新的临时调度π″更新当前调度π,若当前调度π优于全局最优调度π*,则用当前调度π更新全局最优调度π*。转到步骤4。
优选的:所述步骤1中得到无等待流水调度学习恶化效应模型的总延迟目标函数的方法:
获取待加工工序和给定的学习恶化效应,所述加工工序包括任务集
根据无等待流水调度的特点,任务的完工时间表示为该任务完工之前各任务的完工时间距离之和,即:
其中,c[i](π)为任务的完工时间,π表示一个包含有一个初始虚任务π[0]和n个任务的调度,di,j,r是调度中在第r个位置的任务ji和第r+1个位置的任务jj的实际完工时间距离,其定义为:
其中,pi,j,r表示任务ji在机器mj上处于调度中第r个位置时的工序实际加工时间,pi,j,r表示任务ji在机器mj上处于调度中第r个位置时的工序实际加工时间,pi,j任务ji在机器mj上处于调度中第r个位置时的工序加工时间,α,β,γ,μ为学习恶化效应函数参数。
进而得出无等待流水调度学习恶化效应模型的总延迟目标函数:
其中,tt(π)表示总延迟目标,d[i]表示第i个任务的截止期,l[i](π)和t[i](π)分别是调度π中第i个任务的完工时间差以及延迟,其定义为:
l[i](π)=c[i](π)-d[i](6)
t[i](π)=max{l[i](π),0}(7)
优选的:所述步骤7中若新的临时调度π″优于当前调度π,则用新的临时调度π″更新当前调度π,否则,以
优选的:所述前向交换算子,记为afs(π,k)。该算子将调度π的第k个任务π[k]从原位置逐个与其前方的任务交换,直到遇到虚任务π[0]为止,得出并返回所有交换产生的新调度中最优的调度π′。
后向交换算子,记为abs(π,k)。该算子将调度π的第k个任务π[k]从原位置逐个与其后方的任务交换,直到与调度中最后一个任务π[n]完成交换为止,得出并返回所有交换产生的新调度中最优的调度π′。
移除插入算子,记为ri(π,i,j)。该算子将调度π的第i个任务π[i]从原位置移除并插入新位置j中,返回新生成的调度π′。
有益效果:本发明提供的一种面向具有学习恶化效应无等待流水调度问题的方法,相比现有技术,具有以下有益效果:
本发明通过结合问题自身的特点,高质高效地求解具有学习恶化效应无等待流水调度问题,最小化总延迟目标函数。
附图说明
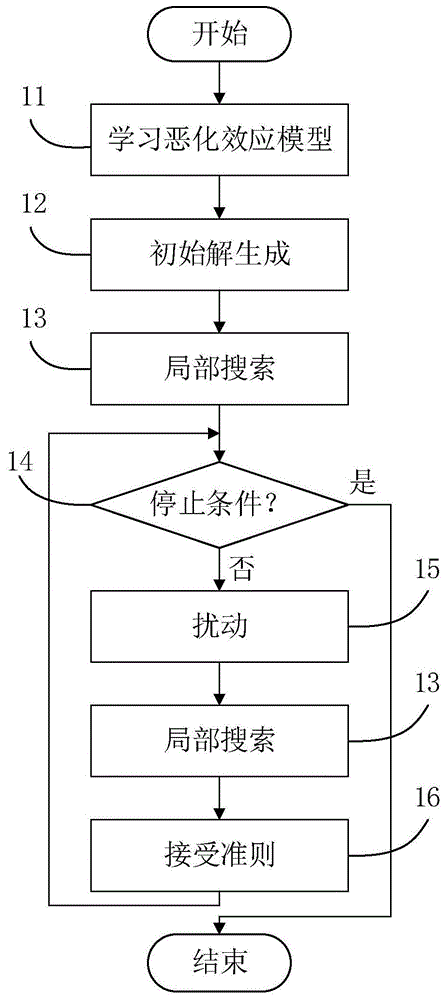
图1是本发明实施例求解具有学习恶化效应无等待流水调度问题方法的总体架构图;
图2是本发明实施例中解的初始化和初步搜索流程图;
图3是本发明实施例中解的迭代求解过程流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种面向具有学习恶化效应无等待流水调度问题的方法,如图1-3所示,对加工工序利用无等待流水调度问题的特点和基于位置的学习恶化效应函数的特点,建立无等待流水调度学习恶化效应模型。基于迭代局部搜索方法最小化求解该无等待流水调度学习恶化效应模型的总延迟目标函数,得出任务在调度中处于不同位置时的实际处理时间,进而得到当前的最优加工工序。本发明利用无等待流水调度问题的特点和基于位置的学习恶化效应函数的特点,建立问题的学习恶化效应模型;基于迭代局部搜索方法框架,提出求解具有学习恶化效应的无等待流水调度问题,最小化调度的总延迟。针对一个需要求解的问题,首先结合问题特点,建立问题的学习恶化效应模型,通过初始解生成模块生成初始调度,并对该初始调度进行初步的局部搜索之后,迭代通过扰动模块、局部搜索模块和接受准则模块对调度进行提高,直到停止条件判断达到停止标准,方法结束并返回找到最优解。
具体包括以下步骤:
步骤1.获取待加工工序和给定的学习恶化效应,根据无等待流水调度的特点,任务的完工时间表示为该任务完工之前各任务的完工时间距离之和,而各工序的实际加工时间将根据给定的学习恶化效应得到,则根据给定的学习恶化效应得到的实际加工时间得到实际任务的完工时间,根据实际任务的完工时间建立无等待流水调度学习恶化效应模型的总延迟目标函数。
获取待加工工序和给定的学习恶化效应,所述加工工序包括任务集
学习恶化效应的特点是:由人类或具有学习恶化效应的机器参与生产制造而产生的任务的实际处理时间缩短或延长的现象,在许多实际生产制造系统中普遍存在。例如,工人们会由于多次重复操作而提高技能,从而更快地完成任务;同时,机器与其零部件的老化也可能增加工序的处理时间。
无等待流水调度的特点就是:任务的完工时间表示为该任务完工之前各任务的完工时间距离之和,即:
其中,c[i](π)为任务的完工时间,π表示一个包含有一个初始虚任务π[0]和n个任务的调度,di,j,r是调度中在第r个位置的任务ji和第r+1个位置的任务jj的实际完工时间距离,其定义为:
其中,pi,j,r表示任务ji在机器mj上处于调度中第r个位置时的工序实际加工时间,进而得出无等待流水调度学习恶化效应模型的总延迟目标函数:
其中,tt(π)表示总延迟目标,d[i]表示第i个任务的截止期,l[i](π)和t[i](π)分别是调度π中第i个任务的完工时间差以及延迟,其定义为:
l[i](π)=c[i](π)-d[i](6)
t[i](π)=max{l[i](π),0}(7)
而建立无等待流水调度学习恶化效应模型,即,任务的实际处理时间仅与任务在调度中所处的实际位置有关。
步骤2.初始解生成:将初始解π0初始化为一个空的调度,在空调度π0中插入位于起始处的虚任务π[0]。将任务集
步骤3.局部搜索:对于当前调度π,每次随机选取一个位置k,k=1,2,...,n,对当前调度π应用前向交换算子afs(π,k)和后向交换算子abs(π,k),分别得到经过前向交换算子应用后的调度πafs和经过后向交换算子应用后的调度πabs,分别将经过前向交换算子应用后的调度πafs和经过后向交换算子应用后的调度πabs与当前调度π比较,从中选取最优的调度作为新的当前调度π,直到所有位置都已被选取并操作完成。若新的当前调度π优于全局最优调度π*,则用新的当前调度π更新全局最优调度π*,并重复以上过程,否则进入步骤4。
步骤4.停止条件判断:判断方法执行过程是否达到了方法停止条件,如达到,则方法停止执行,返回全局最优调度π*,否则进入步骤5。
步骤5.扰动:对于当前调度π,利用移除插入算子ri(π,i,j)随机选取当前调度π中的任一一个任务,移除该任务并插入新的随机位置j,反复进行该操作,得到一个临时调度π′。
步骤6.局部搜索:对临时调度π′重复步骤3中过程,得到新的临时调度π″。
步骤7.接受准则:若新的临时调度π″优于当前调度π,则用新的临时调度π″更新当前调度π,否则,以一定的概率用新的临时调度π″更新当前调度π,若当前调度π优于全局最优调度π*,则用当前调度π更新全局最优调度π*。转到步骤4。
优选的:若新的临时调度π″优于当前调度π,则用新的临时调度π″更新当前调度π,否则,以
优选的:所述前向交换算子,记为afs(π,k)。该算子将调度π的第k个任务π[k]从原位置逐个与其前方的任务交换,直到遇到虚任务π[0]为止,得出并返回所有交换产生的新调度中最优的调度π′。
后向交换算子,记为abs(π,k)。该算子将调度π的第k个任务π[k]从原位置逐个与其后方的任务交换,直到与调度中最后一个任务π[n]完成交换为止,得出并返回所有交换产生的新调度中最优的调度π′。
移除插入算子,记为ri(π,i,j)。该算子将调度π的第i个任务π[i]从原位置移除并插入新位置j中,返回新生成的调度π′。
下面以一具体实施进行说明。
表1本发明实施例
包括学习恶化效应模型的建立11、初始解生成12、局部搜索13、停止条件14、扰动15和接受准则16。假设任务集合
pi,j,r=pi,j-pi,j[1-(r+1)-α]μ+γ[1-(βr+1)e-βr]×pi,j[1-(r+1)-α]μ(8)
其中,pi,j,r表示任务ji在机器mj上处于调度中第r个位置时的工序实际加工时间,pi,j任务ji在机器mj上处于调度中第r个位置时的工序加工时间,α,β,γ,μ为学习恶化效应函数参数,其中,α=0.65,β=0.01,
图2是本发明实施例中解的初始化和初步搜索流程图。如图2所示,具体步骤如下:
步骤s201,令j0为一个在各机器上加工时间均为0且截止期为0的虚任务,初始化初始解π0=(j0);
步骤s202,将任务集合
步骤s203,从排序中移除有最小截止期的任务,当前情况下为j1,利用afs(π0,|π0|)算子将之插入初始解π0中,得到最优部分调度π0=j0,j1);
步骤s204,判断排序中是否还有任务,若是,转步骤s203,否则,转步骤s205;
经过多次迭代后,由步骤s204转s205时,已生成初始解π0=(j0,j4,j3,j2,j1),其对应的总延迟为33.20。
步骤s205,用初始解π0对当前调度π和全局最优调度π*进行赋值,即得到:π=(j0,j4,j3,j2,j1),π*=(j0,j4,j3,j2,j1);
步骤s206,生成(1,2,3,4)的随机序列v=(3,2,1,4);
步骤s207,初始化循环计数器i=1;
步骤s208,选取随机序列中v[1]对应的数值3,对当前调度π应用算子afs(π,3)和abs(π,3),分别得到新的调度πafs=(j0,j2,j4,j3,j1)和πabs=(j0,j4,j3,j1,j2);
步骤s209,πafs与π相比的目标增量是12.15,而πabs与π相比的目标增量是4.83,因此新的当前调度π=π;
步骤s210,循环计数器i=i+1;
步骤s211,判断i是否大于n=4,若是,转步骤s213,否则转步骤s208;
步骤s212,更新全局最优调度π*←π,转步骤s206;
经过多次循环后,i>(n=4),由步骤s211转s213时,已生成当前调度π=(j0,j4,j3,j2,j1),其对应的总延迟为33.20。
步骤s213,判断当前调度π是否优于全局最优调度π*,若是,转步骤s212,否则转步骤s301。
在此实施例中,由于tt(π)=tt(π*),故由步骤s213转步骤s301。
图3是本发明实施例中解的迭代求解过程流程图。如图3所示,该过程具体步骤如下:
步骤s301,判断方法停止条件是否满足,若是,则转步骤s318,否则转步骤s302;
步骤s302,对于当前调度π,多次应用移除插入算子随机移除再插入任务,从而得到调度π′;假设此处得到的调度π′=(j0,j1,j4,j3,j2);
步骤s303,生成(1,2,3,4)的随机序列v=(1,2,4,3);
步骤s304,初始化循环计数器i=1;
步骤s305,选取随机序列中v[1]对应的数值1,对当前调度π应用算子afs(π,1)和abs(π,1),分别得到新的调度πafs=(j0,j1,j4,j3,j2)和πabs=(j0,j4,j3,j2,j1);
步骤s306,πafs与π′相比的目标增量是0,而πabs与π′相比的目标增量是-14.99,因此新的当前调度π″=πabs;
步骤s307,循环计数器i=i+1;
步骤s308,判断i是否大于n=4,若是,转步骤s310,否则转步骤s305;
步骤s309,更新全局最优调度π*←π″,转步骤s303;
经过多次循环后,i>(n=4),由步骤s308转s310时,已生成当前调度π″=(j0,j4,j3,j2,j1),其对应的总延迟为33.20。
步骤s310,判断当前调度π″是否优于全局最优调度π*,若是,转步骤s309,否则转步骤s311;
在此实施例中,由于tt(π″)=tt(π*),故由步骤s310转步骤s311。
步骤s311,判断调度π″是否优于调度π,若是,转步骤s312,否则转步骤s313;
在此实施例中,转步骤s313;
步骤s312,更新当前调度π←π″,转步骤s316;
步骤s313,生成一随机数μ;
步骤s314,判断是否有
在此实施例中,假设判断条件不满足,转步骤s316;
步骤s315,更新当前调度π←π″;
步骤s316,判断当前调度π是否优于全局最优调度π*,若是,转步骤s317,否则转步骤s301;
在此实施例中,由于tt(π)=tt(π*),故由步骤s316转步骤s301。
步骤s317,更新全局最优调度π*←π,转步骤s301;
步骤s318,返回全局最优解π*;方法结束。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!