一种XML数据差异化储存对全文检索的优化方法与流程
本发明涉及一种XML数据保存的优化技术,特别涉及一种XML数据差异化储存对全文检索的优化方法。
背景技术:
随着信息化的发展,存储的数据类型不再是一种纯粹的文本、数字、日期类型。为满足日新月异的发展和数据存储要求,更多采用多种不同动态结构类型存储的方式进行存储数据,如地图数据、图数据、服务数据等。更多的是采用XML结构化的形式进行存储,面对XML的数据的处理要求日益增加,尤其对于该类庞大数据检索要求也日益增加。
现有的相关技术主要有以下几份专利文献:
1、XML-机器人,00819741.5菲利普·库特,有权;
2、存储XML数据的方法、执行XML查询的方法及其装置,200810212515.2国际商业机器公司,有权;
3、XML解析中数据块划分方法和XML解析方法,201210495961.5方跃坚,有权。
在上述“XML-机器人”专利文献1中,实现了通过分别使用文本化或图像化流程图,将XML文档、文件类型定义(DTD)或他们的代表修饰成结构树。XML文档的数据结构被重新用于处理其代码并与其合并。
在上述“存储XML数据的方法、执行XML查询的方法及其装置”专利文献2中,本发明提供一种基于简单路径在XML仓库中存储XML数据的方法,该XML仓库包括简单路径仓库和数据仓库,该方法包括:对XML文档中的每一个节点,生成用于唯一识别该节点的节点标识符;生成XML文档的简单路径;将简单路径存储到简单路径仓库中;以及以简单路径为索引将每一个简单路径中的每个节点的数据依次存储到数据仓库中,其中数据包括该节点的节点标识符和值。本方法使数据以简单路径的聚束的方式进行存储,并且一个简单路径的数据按照节点标识符的顺序进行存储。而且,本方法不需要XML文档的模式,可以处理无模式的XML数据,并且能够提高XML数据查询的性能。此外,还提供了基于简单路径在XML仓库中存储XML数据的装置以及在XML仓库中执行XML查询的方法和装置。
在上述“XML解析中数据块划分方法和XML解析方法”专利文献3中,本发明公开了XML解析中数据块划分方法和XML解析方法,其中,XML解析中数据块划分方法,包括将XML文件划分为XML数据段,并分配给多个线程并行处理;在XML数据段中确定候选边界开始符;候选边界开始符的边界符类型,记录候选边界开始符的边界符类型和位置;确定有效边界开始符;以所述有效边界开始字符为界,将所述XML数据段划分为多个数据块。通过本发明实施例中的数据块划分方法,可以使每个数据块中的XML元素保留完整,从而有效地避免了在后续的XML数据解析过程中,由于XML元素不完整而造成的,需要解析程序进行推测的过程,进而也就有效地提高了XML数据的解析效率。
由此可见,目前公知的简单数据类型的比较没有问题,但对于一种结构化存储的数据来说是不能按以往的方式进行管理,如果存储的数据是一种定义的XML结构化数据,对于此类XML数据的修改保存,采用整体保存的方式,已经不能满足当前对数据操作记录的可检控性,对于具体内容下的数据修改追踪带来很多无法解决的问题。
结构化XML数据的存储要求越来越多,对于例如图形数据的保存,服务数据等,此类数据跟传统的文本、日期、时间类型的数据有本质的区别,也不利于对XML里面的数据进行检索,尤其是全文检索。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种XML数据差异化储存对全文检索的优化方法,该优化方法采用XML数据进行差异保存方案,解决了富文本XML数据的存储的若干问题,不仅提高了数据的可查询行,也提高了数据的可分析性,适用于服务数据同步,画布数据等场景,并且,该优化方法在考虑到全文检索对XML推送的难度和数据增量处理无法得到满足的情况下,采用差异化的存储有效解决了冗余的数据推送与修改跟踪的问题。
本发明的目的可以通过下述技术方案实现:1、一种XML数据差异化储存对全文检索的优化方法,包括以下步骤:
步骤1、对XML数据进行保存;
步骤2、对XML数据主表进行保存,把XML数据序列化后保存到主表;
步骤3、对XML数据从表进行保存;
步骤4、对主表和从表进行检索设置,把主表设置成主表用于大数据整体的检索查询,把从表设置成用于不同种类类型数据的检索查询。
所述步骤3包括以下步骤:
步骤31、把统计后的分类进行分组,通过循环把不同的种类的数据类型存储到对应种类的从表中;
步骤32、在每个对应种类的从表对数据增删改进行判断:如果没有存在对应数据则采用新增的方式进行存储;如果已经存在的则采用更新的方式进行存储;如果相同的则不进行任何操作;最后会进行分类的从表保存数据和已经存储的从表数据进行差异对比,找出已经删除的不存在的数据进行物理删除。
所述步骤4中:在已经建立Lucene或Solr的全文检索的基础上,对主表和从表进行检索设置。所述全文检索的检索根据数据库的操作,即:对XML数据CURD进行判断和数据推送;所述Solr对某一数据进行检索过程,只对存在有更改的部分进行推送。
所述步骤1中,在对XML数据进行保存的过程中,对XML数据进行结构化内容的分类,对XML结构化内容的分类进行分组后,再对XML数据主表和从表数据进行保存,此过程放入事务进行操作,以保证数据的完整性和一致性。
本发明的目的也可以通过以下技术方案实现:一种XML数据差异化储存对全文检索的优化方法,包括:结构化数据库、结构化XML数据、差异化保存服务、全文检索、客户端。
结构化数据库,可以选用任何的关系型数据库,如Oracle,MySql,SqlServer等数据库;结构化XML数据是一个用户定义结构或指定固定结构的数据,如画布图元数据,服务器协议数据等;差异化保存服务,该服务是用于对XML数据进行整体比对,对每个节点的数据进行比对分析,罗列具体的数据差异项目,利用差异化对数据进行保存;全文检索采用Lucene或Solr,主要对XML数据的检索。客户端户端主要是管理数据,读取XML数据,对XML数据进行CURD的操作,调用用差异化保存服务接口实现XML数据保存。客户端可以使用基于微软的Winforn或WPF实现,服务端差异化保存采用微软的WCF或WebService提供服务接口,实现XML的差异化保存。
由于数据的存储类型XML是一个整体的数据,不能单纯采用只用拆分保存的方式来存储,例如地图数据,画布图元数据,往往是一个整体。某些XML数据渲染也是通过整体的XML进行解释渲染显示,所以有必要对XML数据进行整体的保存,一方面可以保证整体数据的安全性,一方面为具体的富文本操作带来便利;利用对XML数据的固有结构进行拆分保存到不同的数据库表,此过程是通过人为分析处理,对关键数据进行拆分存储,目标为提高数据查询和检索。
在建立对XML数据的保存结构后,XML数据整体保存部分用于业务的操作,拆分保存的细分部分用于查询和全文检索。建立一个差异化的保存服务,对XML数据CURD的操作的进行更新。
在经过差异化数据保存后的数据,可以根据拆分保存的数据一方面可以知道数据的更新情况,解决了大文本XML数据保存不利于数据分析的缺点。另一方面通过数据的增量和更新的机制,优化了Lucene和Solr的推送。
用户利用客户端对XML数据记性操作过程中,差异化保存可以提高数据的保存效率,在客户端可以实时对富文本XML下的子数据进行实时高效的全文检索。
本发明是对富文本数据XML数据的全文检索的优化存储方案。采用总分进行对XML数据的存储,利用差异化对比分析的方式对数据进行差异化保存来优化全文检索的方案。XML的存储采用总分方式对数据进行存储,采用总的XML数据的存储,利用结构化对数据进行分类后拆分到不同的数据库表进行保存。利用差异化对XML数据差异化进行优化存储,对相同部分不操作,对差异部分进行更新存储。此方案方法是一个对XML存储优化方案和提高全文检索的优化方案,解决XML数据存储的难题的同时,解决对XML的全文检索的检索性能,避免传统数据推送过程中对数据操作不当或冗余操作造成全文检索数据推送的重推操作,提高服务性能,提高数据时间操作记录的可检控性。
本发明对XML数据差异化保存对全文检索的优化方案;利用XML数据差异化进行差异化的保存,利用差异化结果优化全文检索;通过差异化的保存方案优化XML富文本的保存的同时,为提供全文检索的准确性,采用差异化保存服务对XML数据过滤保存,从而优化XML数据检索效率。是一套XML数据的保存,差异化分析保存,优化全文检索的对XML数据和元数据的检索的完整方案。
本发明与上述专利文献1的区别在于:本发明强调了XML数据差异对比,优化数据存储,提高全文检索的方案,而以上专利则只针对XML的处理,是一种单一XML文件处理行为。
本发明与上述专利文献2的区别在于:本发明强调了XML数据差异对比,优化数据存储,提高全文检索的方案,而以上专利则针对XML数据进行存储、提取、查询,是一种查询方面的动作。
本发明与上述专利文献3的区别在于:本发明强调了XML数据差异对比,优化数据存储,提高全文检索的方案,而以上专利则只是针对单一XML的结构分块,XML优化查询的过程。
与上述3篇专利文献相比,本发明的创新之处主要在于:一方面,从以上发明人提出的专利以及参考国内很多其他相关专利的研究可以看出,目前针对XML差异化对比分析,以及对XML差异化的数据结果进行冲突处理应用很少,采用利用差异化对XML数据进行处理,弥补了上述专利文献中技术方案的不足;另一方面、随着信息化的发展,对于服务数据,协议数据的要求越来越多。尤其对于大并发数据处理方面仍然很难实现同步处理,尤其对于XML结构化数据存储的整合。此方案是可以实时处理冲突数据,解决数据存储,很大程度上优化的扩展数据的可靠性和可检索性。
本发明相对于现有技术具有如下的优点及效果:
1、本发明对富文本XML数据优化保存方案。对于包括地图数据、画布数据等采用XML数据保存的,此方案有很强扩展性,有很强的场景应用性。能满足很多个性化XML数据的存储要求。
2、解决XML的数据查询问题,利用总分的结构,把XML数据进行拆分结构存储到其他数据库表中。整体部分用于业务操作,拆分保存部分用户查询和全文检索。
3、对XML数据采用差异化分析保存,解决传统数据批量更新带来的问题。对相同数据不采取操作,对差异数据进行更新。有效提高了数据的准确性。
4、XML差异化分析保存提高数据库的保存性能的同时,数据的增量操作推送得到解决。能有效提高全文检索引擎的数据推送,提高全文检索的性能和查询。
5、本发明的优化方法可以缓减大数据量的推送导致的性能和网络带宽问题的同时,又可以按需进行精确的数据推送,提高了检索的效率。
附图说明
图1是本发明的方案流程图。
图2是本发明的差异化保存流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本发明优化方法的流程图,包括结构化数据,结构化数据XML,差异化数据保存服务,全文检索和客户端,具体通过以下步骤实现:
1.客户端对XML数据的保存;
2.XML保存采用总分的形式进行存储,总体部分用于存储整体的数据部分,用于操作业务用;拆分部分用于检索用;
3.客户端通过提交XML数据到差异化保存服务,通过差异化保存服务进行差异化分析进行保存;
通过差异化得到的数据更新,可以触发全文检索服务对数据进行数据检索。
通过差异化处理后的数据可以更准确推送的内容,从而提高全文检索的效率。
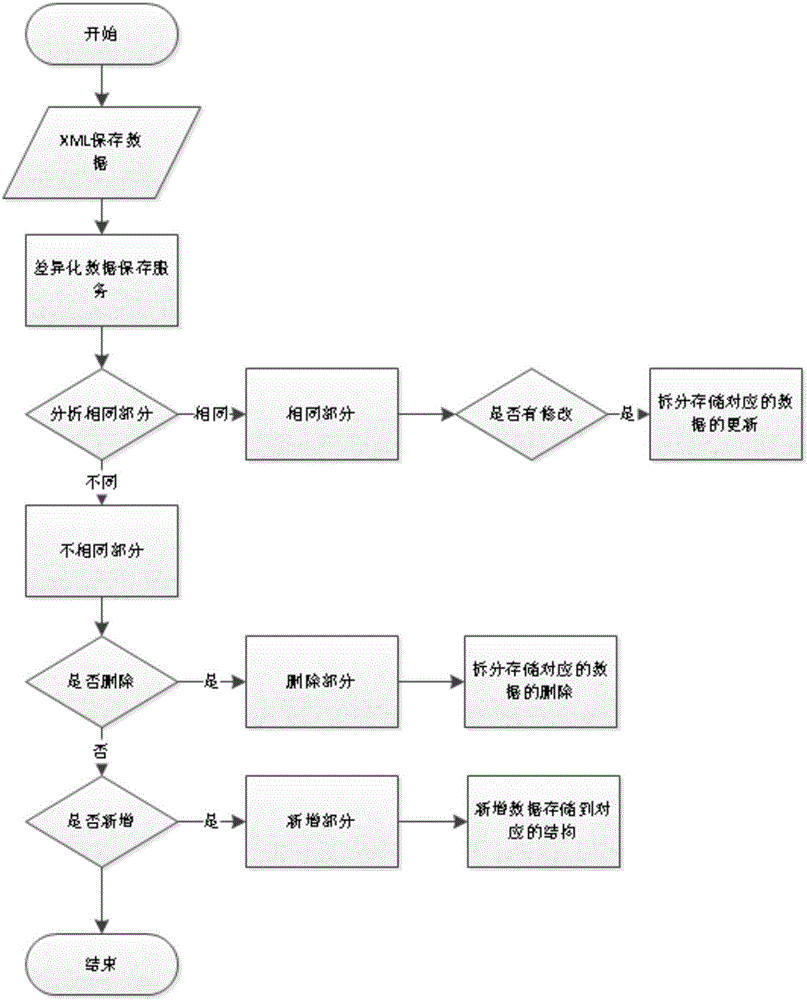
如图2所示,差异化保存方案的保存流程。
1.从客户端传输保存的XML数据,把XML数据提交到差异化保存服务;
2.差异化保存服务根据新的XML数据,对原有存储的XML数据进行数据差异化分析保存;
2-1.对XML数据进行拆分大节点模块,按照不同的模块进行划分。
2-2.根据不同的XML模块数据进行数据的升序排序。
2-3.判断该模块数据的总数是否相同。如果数据条数相同,那么对每一行的数据进行比对,把不相同的数据放到一个队列里面,相同的不用进行任何的操作。
2-4.如果判断模块总数不相同,在以上的操作步骤以上,对删除的数据进行比对,如果出现删除的数据,则把删除的数据放入到队列。如果数据没有删除,有新增的情况,把数据放到一个新增的队列里面。
2-5.得到以上修改的数据队列,一个数据新增队列,一个数据删除队列。首先对主表XML数据进行更新。接着对拆分部分的数据根据以上三个队列进行不同的操作更新,把修改的数据队列里面的数据进行数据库里面的逐条更新;对删除的数据队列的数据进行数据库里面的逐条删除;对新增队列里面的数据进行新增操作。
2-6.等以上拆分数据完成所有的操作,总的XML数据采用的是及时的更新,拆分存储的数据采用异步队列进行数据的更新。此过程中不影响整体的性能同时,提高数据查询的准确性;
3.所有的XML数据已经完成更新后,全文检索引擎触发检索机制,对数据进行检索,优化了全文检索的检索时间。
客户端可以很准确利用全文检索对数据进行一个检索,而且可以对XML数据里面的元数据进行时间更新的检索。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!