海量平台往hadoop平台自动化导入增量数据的方法与流程
本发明涉及一种海量平台往hadoop平台自动化导入增量数据的方法。
背景技术:
中国的电力工业经过几十年来的高速发展,随着下一代智能化电力系统建设的全面展开,中国的电力系统已经成为了世界上最大规模关系国计民生的专业物联网,甚至在某种程度上,这张遍及生产经营各环节的生产关系网,构筑起了中国最大规模的大数据计算平台,为从时间和空间等多个维度进行大范围的能源资源调配奠定了基础。对于电力行业而言,电力大数据将贯穿未来电力工业生产及管理等各个环节, 起到独特而巨大的作用、是中国电力工业在打造下一代电力工业系统过程中有效应对资源有限、环境压力等问题,实现厚积厚发 、绿色可持续性发展的关键 。
近几年,电力行业信息化也得到了长足的发展,我国电力企业信息化起源于20世纪60 年代,从初始电力生产自动化到80年代以财务电算化为代表的管理信息化建设,再到近年大规模企业信息化建设,特别是伴随着下一代智能化电网的全面建设,以电力大数据为代表的新一代 IT技术在电力行业中的广泛应用,电力数据资源开始急剧增长并形成了一定的规模。从长远来看,作为中国经济社会发展的“ 晴雨表”, 电力数据以其与经济发展紧密而广泛的联系,将会呈现出无以伦比的正外部性,对我国经济社会发展 以至人类社会进步也将形成更为强大的推动力。
对于电力行业不断产生的海量数据,该采用何种技术来处理呢?毫无疑问,Hadoop成为众多企业的首选,Hadoop因其在大数据处理领域具有广泛的实用性以及良好的易用性,自2007年推出后,很快在工业界得到普及应用,同时得到了学术界的广泛关注和研究。在短短的几年中,Hadoop很快成为到目前为止最为成功、最广泛接受使用的大数据处理主流技术和系统平台,并且成为一种大数据处理事实上的工业标准,得到了工业界大量的进一步开发和改进,并在业界和应用行业尤其是互联网行业得到了广泛的应用。
有了海量数据和相应的Hadoop大数据处理技术,就需要我们考虑该如何将这些海量数据导入到Hadoop平台,在这样一个背景下,本专利提出了一种高效而稳定的解决方法。
技术实现要素:
本发明的目的在于提供一种高效而稳定的海量平台往hadoop平台自动化导入增量数据的方法。
本发明的技术解决方案是:
一种海量平台往hadoop平台自动化导入增量数据的方法,其特征是:以海量平台为源数据库,以Hadoop大数据平台为目标数据库,并结合Java开发的自动化增量数据导入方法,来实现源数据库中的增量数据导入到目标数据库的目的;
在Hadoop大数据平台中,以MapReduce作为大数据的计算引擎,以HDFS分布式文件系统存储非结构化和半结构化的数据,以HBase分布式数据库存储结构化数据; Java自动化增量数据导入程序需要每天执行一次, Java程序功能的实现分为两个部分:
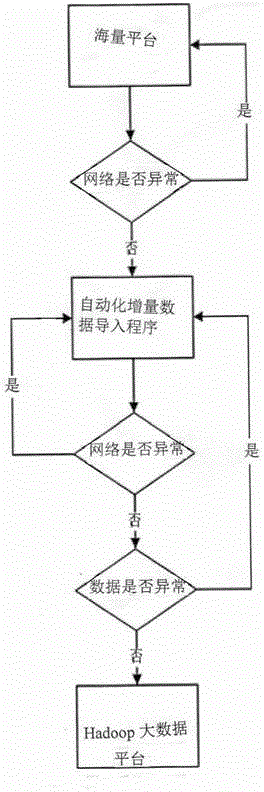
(1)Java程序实现对海量平台增量数据采集的功能;海量平台提供查询数据的接口,此接口包含时间范围、表名、查询条件参数,Java程序通过配置相应的参数来调用海量平台接口,获取相应的数据;由于Java程序是采用调用远程接口的方式来获取海量平台上的数据,所以会存在网络异常的情况,针对这种情况,Java程序在执行获取数据的方法之前,先判断网络连接是否正常,如果不正常则记录相应的日志,并记录相应的时间标签,等网络环境正常时,Java程序再根据记录的日期标签,重新执行程序,并重新获取此日期对应的数据;另外,如果出现Java程序在执行获取数据方法时,就出现网络异常的情况,那么已经获取的数据,不导入到大数据平台,同样记录日志和标签;
(2)在Java程序将海量平台中的增量数据获取之后,将数据导入到大数据平台;但在做这个操作之前,先校验一下获取的数据,是否正常,异常数据将被舍弃,Java程序获取的数据采用追加的方式导入到大数据平台,在数据导入之前,Java程序同样需要先判断网络连接是否正常,网络异常时,记录日志和日期标签,该程序的导入方法将不会被执行;另外,如果在执行导入方法时出现网络异常的情况,则记录日志、日期标签以及数据标签,这样就可以知道当前日期哪些数据已经导入到大数据平台中,已经导入大数据平台的数据,将不会被重复导入。
所述先校验一下获取的数据,是否正常,是判断一下数据是否存在空值、负值的情况。
借助Eclipse3.6开发工具,采用Java语言开发并实现导出功能、导入功能以及异常处理功能。
借助Eclipse3.6开发工具,采用Java语言开发并实现导出功能、导入功能以及异常处理功能。
实现导出功能需要确定Java程序和海量平台之间的网络端口是否开放,并且Java程序可以成功调用海量平台所提供的查询接口。
实现导入功能需要确定Java程序和大数据平台之间的网络端口是否开放,并且Java程序可以成功使用Hadoop大数据平台所提供的命令,将获取的数据追加至Hdfs文件系统中。
实现网络异常判断和数据校验的功能,在海量平台导出数据和大数据平台导入数据的时候,都需要判断网络是否异常,并记录相关日志和日期标签,用以标识哪天的数据出现问题,并在网络正常的情况下,重新把这些有问题的数据导出或者导入;在数据导入的时候,判断数据是否有问题,当出现空值、负值异常数据时,程序本身过滤掉,这样可以提高导入数据的整体质量,为后面的质量评价提供了优质数据。
本发明与传统Hadoop平台数据导入方法相比,本方法不仅能够大大提高数据导入效率,同时还能提高导入数据的质量,为后续大数据统计分析的准确性提供了良好基础。解决了传统数据导入方法效率低、误差大、实时差的问题,提出的基于Hadoop平台自动化导入增量数据的方法,大大提高了往Hadoop平台导入数据的效率,而且确保了导入数据的准实时性、准确性。
附图说明
下面结合附图和实施例对本发明作进一步说明。
图1是本发明的系统流程图。
具体实施方式
一种海量平台往hadoop平台自动化导入增量数据的方法,以海量平台为源数据库,以Hadoop大数据平台为目标数据库,并结合Java开发的自动化增量数据导入方法,来实现源数据库中的增量数据导入到目标数据库的目的;
在Hadoop大数据平台中,以MapReduce作为大数据的计算引擎,以HDFS分布式文件系统存储非结构化和半结构化的数据,以HBase分布式数据库存储结构化数据; Java自动化增量数据导入程序需要每天执行一次,由于海量平台在晚上使用频次较少,所以程序的执行时间设定在24点, Java程序功能的实现分为两个部分:
(1)Java程序实现对海量平台增量数据采集的功能;海量平台提供查询数据的接口,此接口包含时间范围、表名、查询条件参数,Java程序通过配置相应的参数来调用海量平台接口,获取相应的数据;由于Java程序是采用调用远程接口的方式来获取海量平台上的数据,所以会存在网络异常的情况,针对这种情况,Java程序在执行获取数据的方法之前,先判断网络连接是否正常,如果不正常则记录相应的日志,并记录相应的时间标签,等网络环境正常时,Java程序再根据记录的日期标签,重新执行程序,并重新获取此日期对应的数据;另外,如果出现Java程序在执行获取数据方法时,就出现网络异常的情况,那么已经获取的数据,不导入到大数据平台,同样记录日志和标签;
(2)在Java程序将海量平台中的增量数据获取之后,将数据导入到大数据平台;但在做这个操作之前,先校验一下获取的数据,是否正常,异常数据将被舍弃,Java程序获取的数据采用追加的方式导入到大数据平台,在数据导入之前,Java程序同样需要先判断网络连接是否正常,网络异常时,记录日志和日期标签,该程序的导入方法将不会被执行;另外,如果在执行导入方法时出现网络异常的情况,则记录日志、日期标签以及数据标签,这样就可以知道当前日期哪些数据已经导入到大数据平台中,已经导入大数据平台的数据,将不会被重复导入。
所述先校验一下获取的数据,是否正常,是判断一下数据是否存在空值、负值的情况。
部署硬件环境和软件环境,集群服务器安装CentOS 6.5的操作系统,装好之后,需要配置网络环境,由于Java程序以Hadoop大数据平台为基础支撑软件,所以需要在服务器集群上面安装Hadoop相关软件。
借助Eclipse3.6开发工具,采用Java语言开发并实现导出功能、导入功能以及异常处理功能。
借助Eclipse3.6开发工具,采用Java语言开发并实现导出功能、导入功能以及异常处理功能。
实现导出功能需要确定Java程序和海量平台之间的网络端口是否开放,并且Java程序可以成功调用海量平台所提供的查询接口。
实现导入功能需要确定Java程序和大数据平台之间的网络端口是否开放,并且Java程序可以成功使用Hadoop大数据平台所提供的命令,将获取的数据追加至Hdfs文件系统中,
代码如下:
String hdfs_path = "hdfs://mycluster/home/wyp/wyp.txt";//文件路径
Configuration conf = new Configuration();
conf.setBoolean("dfs.support.append", true);
String inpath = "/home/wyp/append.txt";
FileSystem fs = null;
try {
fs = FileSystem.get(URI.create(hdfs_path), conf);
//要追加的文件流,inpath为文件
InputStream in = new
BufferedInputStream(new FileInputStream(inpath));
OutputStream out = fs.append(new Path(hdfs_path));
IOUtils.copyBytes(in, out, 4096, true);
} catch (IOException e) {
e.printStackTrace();
}
实现网络异常判断和数据校验的功能,在海量平台导出数据和大数据平台导入数据的时候,都需要判断网络是否异常,并记录相关日志和日期标签,用以标识哪天的数据出现问题,并在网络正常的情况下,重新把这些有问题的数据导出或者导入;在数据导入的时候,判断数据是否有问题,当出现空值、负值异常数据时,程序本身过滤掉,这样可以提高导入数据的整体质量,为后面的质量评价提供了优质数据。
- 还没有人留言评论。精彩留言会获得点赞!