一种基于Email网络的开源软件项目开发者预测方法与流程
本发明涉及网络科学、机器学习领域,特别是涉及一种基于Email网络的开源软件项目开发者预测方法。
背景技术:
随着科技发展,开源软件(Open Source Software,OSS)项目的众多优势逐渐被人们所认可,参考文献1(Q.Xuan,M.Gharehyazie,P.T.Devanbu,and V.Filkov,"Measuring the Effect of Social Communications on Individual Working Rhythms:A Case Study of Open Source Software,"in International Conference on Social Informatics,2012,pp.78-85.1,即Q.Xuan,M.Gharehyazie,P.T.Devanbu,and V.Filkov,社交情况对工作节奏的影响研究:以开源软件项目为例,in International Conference on Social Informatics,2012,pp.78-85.1)。为有效地保持一个OSS项目的成功,利用其公开的项目数据信息进行可靠的判断和预测显得尤为重要。近些年网络科学的发展,可以让我们更好地计算人与人之间的社会行为信息,比如链路预测,参考文献2(M.Fire,L.Tenenboim,O.Lesser,R.Puzis,L.Rokach,and Y.Elovici,"Link Prediction in Social Networks Using Computationally Efficient Topological Features,"in PASSAT/SocialCom 2011,Privacy,Security,Risk and Trust(PASSAT),2011 IEEE Third International Conference on and 2011 IEEE Third International Confernece on Social Computing(SocialCom),Boston,MA,USA,9-11 Oct.,2011,2011,pp.73-80.0,即M.Fire,L.Tenenboim,O.Lesser,R.Puzis,L.Rokach,and Y.Elovic,在社交网络中使用计算有效的拓扑特性的链路预测,in PASSAT/SocialCom 2011,Privacy,Security,Risk and Trust(PASSAT),2011 IEEE Third International Conference on and 2011 IEEE Third International Confernece on Social Computing(SocialCom),Boston,MA,USA,9-11 Oct.,2011,2011,pp.73-80.0),节点重要性判断,参考文献3(L.Lü,D.Chen,X.-L.Ren,Q.-M.Zhang,Y.-C.Zhang,and T.Zhou,"Vital nodes identification in complex networks,"Physics Reports,2016.0,即L.Lü,D.Chen,X.-L.Ren,Q.-M.Zhang,Y.-C.Zhang,and T.Zhou,复杂网络中的重要节点识别,Physics Reports,2016.0),社区发现,参考文献4(B.Cai,H.Wang,H.Zheng,and H.Wang,"An improved random walk based clustering algorithm for community detection in complex networks,"in IEEE International Conference on Systems,Man,and Cybernetics,2011,pp.2162-2167,即B.Cai,H.Wang,H.Zheng,and H.Wang,一种改进的基于随机游走的复杂网络聚类检测算法,in IEEE International Conference on Systems,Man,and Cybernetics,2011,pp.2162-2167)等,然而很多时候这些单一的分析方法在复杂的环境中均不能很好地适用。因此,结合其他领域的技术来进行分析预测成为当前较为有效的方法。
如今,机器学习已应用于多个领域。例如:Bing N曾利用机器学习方法预测医药领域中药物与酶相互作用网络关系,参考文献5(Bing N,Zhang Y,Ding J,et al.Predicting network of drug–enzyme interaction based on machine learning method[J].Biochimica Et BiophysicaActa,2014,1844(1):214-223,即Bing N,Zhang Y,Ding J,et al.,基于机器学习方法的药物-酶相互作用的网络预测,Biochimica Et BiophysicaActa,2014,1844(1):214-223);Robles J A T利用机器学习对股票市场的波动性进行分析从而预警金融危机的出现,参考文献6(Son I S,Oh K J,Kim T Y,et al.An early warning system for global institutional investors at emerging stock markets based on machine learning forecasting[J].Expert Systems with Applications,2009,36(3):4951-4957,即Son I S,Oh K J,Kim T Y,et al.,基于机器学习的全球新兴股票投资预警系统,Expert Systems with Applications,2009,36(3):4951-4957);Facebook,亚马逊等网页利用机器学习识别出用户真正感兴趣的信息等等。只要给定的数据集覆盖的范围足够广,数量足够大,机器学习就能训练出很好的模型,从而能够更好的实现分析预测。
因此,结合网络科学中的节点排序算法以及机器学习算法来对OSS项目中开发者的预测成为一种可行性较高的方法。
技术实现要素:
为了克服现有的机器学习方法的无法准确预测某位程序员是否晋升为项目实际开发者的不足,本发明的目的是基于OSS项目中的Email通讯数据来预测项目当前晋升的开发者(从一个单纯的讨论者变成一个实际的代码贡献者)。本发明提出一种基于Email网络的开源软件项目开发者预测方法,根据Apache项目中程序员之间的邮件交流信息,搭建不同种类的网络,应用不同的网络节点排序算法获得多个特征,然后应用机器学习算法训练分类器,用于预测某位程序员是否晋升为项目实际开发者。
本发明实现上述发明目的所采用的技术方案为:
一种基于Email网络的开源软件项目开发者预测方法,包括以下步骤:
S1:根据OSS项目获得的Email数据,同时结合项目的时效特性,分别搭建六种不同的网络:无向无权网络、无向有权网络、无向时效网络、有向无权网络、有向有权网络和有向时效网络;
S2:采用节点排序算法Degree-Based,PageRank,LeaderRank,Hits得出不同网络中各个节点的分值,同时利用网络拓扑结构,得到每个节点的特征向量中心性和聚类系数;
S3:将同种类型的Email网络合并,每个节点即作为一个样本,将上述步骤S2不同算法和网络特性得到的分值排名作为特征,样本标签为是或者不是开发者,构成一个分类器,同时,用欠采样的方法预处理样本数据;
S4:随机抽取处理后的总样本的80%作为训练样本,20%作为测试样本,采用Bayesian算法进行机器学习,并对测试样本进行测试。
进一步,所述步骤S1中,无向无权网络Nc(V,L,A,T),V表示网络中n个节点集合,L表示节点与节点的连边集合,A表示网络的邻接矩阵,T表示每个开发者出现的时刻;
无向有权网络Nc(V,L,W,T)中V,L,T与上述相同,W表示网络的权重邻接矩阵,与矩阵A不同在于,Wij等于节点i与节点j之间的Email数量;
无向时效网络Nσ(V,L,Uσ,T)中V,L,T与上述相同,Uσ是时间窗σ内的一个矩阵
对于给定的σ,主要考虑[T-σ,T]的时间段内节点之间的相互通信;
有向无权网络中V,T与上述相同,表示有向边集合,即表示的是节点i存在指向节点j的有向边,而仅且表示节点j存在指向节点i的有向边,在中如果仅有节点i向节点j发送邮件,则
有向有权网络中与上述相同,表示节点j向节点i发送的邮件数,表示的是节点i向节点j发送的邮件数;
有向时效网络中与上述相同,表示在时间窗σ内的一个矩阵,其中
再进一步,所述步骤S2中,在算法Degree-Based中,考虑节点的直接影响力,节点的度指与该节点直接相连的边的数目,度的大小即作为该项特征的分值;
在算法PageRank中,以有向无权网络为例,特征分值为
其中
为节点j的出边的数量,则
X=PX
其中X=[x1,x2,…,xn],P=[pij]n×n
为了防止非连通网络引起的非唯一排列问题,矩阵P被替换为Q:
其中得到X=QX。为得更一般的结果,同时防止数值过大,对该式采用如此迭代计算:
在算法LeaderRank中,以有向无权网络为例,在原有网络中增加一个背景节点,与其他所有节点做双向连接,特征分值为
同样的经过迭代运算:
得到一般性结果,之后将增加的背景节点分值平均分配个原网络中的所有节点,得到特征分值:
在Hits算法中,给每个节点赋予了两个参数:权威中心性xi和核心中心性yi
其中α,β均为常数;
因为两个参数都与指向性有关,所以Hits算法只针对有向网络进行分析。为使结果归一化,同时保持数量级不变,进行迭代计算:
在无向网络中,由于节点的边没有方向性,指向一个节点与被一个节点指向并没有区别,定义一个等同于权威中心性和核心中心性的重要分数zi,zi在无向无权网络、无向有权网络、无向时效网络中,分别表示为:
在特征向量中心性中,特征分值为
为得到一般性结果同时保持数量级相等,进行迭代计算:
在聚类系数中,描述的是网络中节点的邻居中实际存在的边与该点邻居中可能存在的边的比值,特征分值为
更进一步,所述步骤S3中,网络合并后的节点个数多于原有所有项目用户数总和,因为不同时刻网络存在同一个节点。考虑到了在一个时刻里只存在一个刚晋升的开发者,即在一个时刻,正标签的样本只有一个,导致数据样本不均衡,因此采用欠采样随机删除部分负标签样本。同时,对特征分值进行归一化处理来消除不同算法分值不同而影响结果,采用的是每个分值排名的百分比作为样本的特征值。
所述步骤S4中,利用Matlab机器学习工具包,对预处理之后的数据样本总量的80%采用Bayesian算法进行学习,然后对剩余数据进行测试,测试预测准确率。
本发明的技术构思为:鉴于网络节点排序算法预测准确性不高,本发明提出一种基于Email网络的开源软件项目开发者预测方法,利用多种网络节点排序算法得到各个节点相应算法的特征分值,同时结合网络的拓扑性质得到参数特征向量中心性和聚类系数,对特征分值和参数排名分别做归一化处理,将处理后的分值排名作为每个节点的特征值,输入机器学习分类器,采用Bayesian算法对样本进行学习,达到良好的预测效果。
与现有的技术相比,本发明的有益效果是:采用网络节点排序算法和机器学习方法相结合的方法,通过对现有的数据进行分析,有效的预测出开源软件项目中的开发者,相比单一的节点排序算法,显著的提高了预测的准确率。
附图说明
图1为本发明实施例的基于Email网络的开源软件项目开发者预测方法流程图。
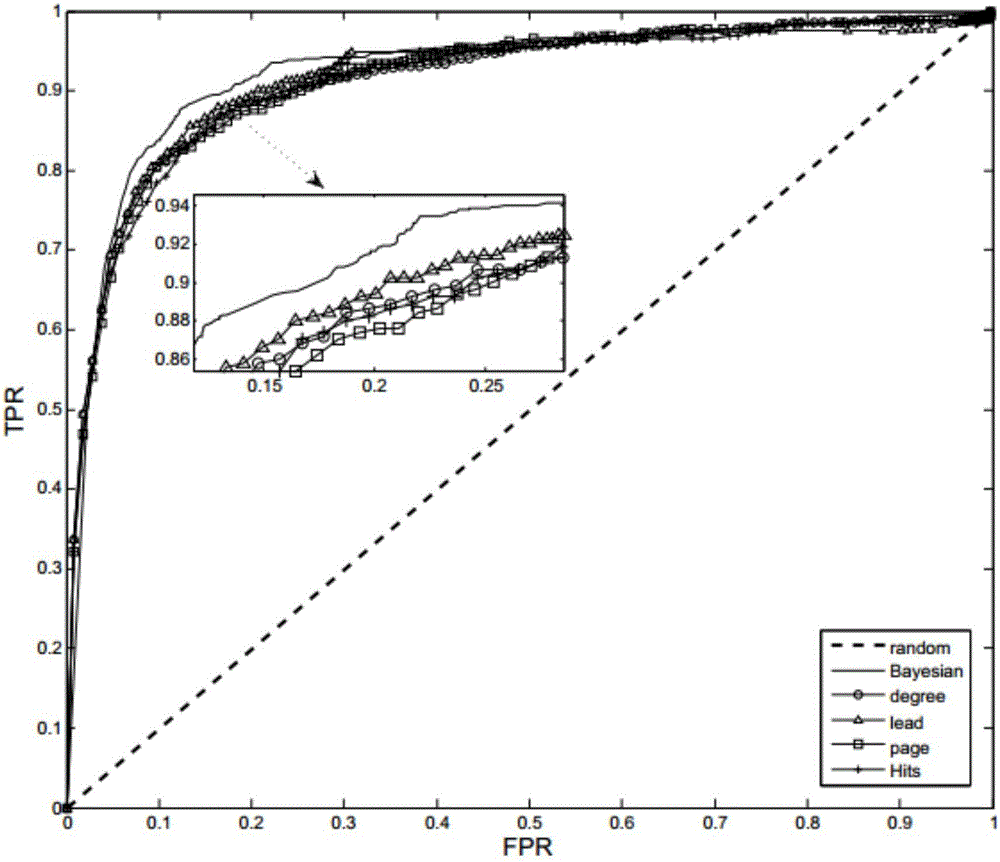
图2为Bayesian算法和节点排名算法在无向时效网络(时间窗1月)下的ROC。
图3为Bayesian算法和节点排名算法在无向时效网络(时间窗1月)下的误差率。
具体实施方式
下面结合说明书附图对本发明做进一步说明。
参照图1~图3,一种基于Email网络的开源软件项目开发者预测方法,本发明使用Apache上的OSS项目相关数据预测项目的开发者。表1为OSS项目主要数据信息,其中To是项目第一封邮件发送时刻,Tf是项目目结束时刻,Nu是项目总程序员数量,Nd开发者数量,Ne是邮件总数量。附图2中采用ROC曲线和曲线下的面积AUC作为评价指标的各种算法预测结果图,其中X轴为“假正例率”(False Positive Rate,简称FPR),Y轴为“真正例率”(True Positive Rate,简称TPR),预测效果更好的算法将会有更大的AUC值。
表1
本发明包括以下步骤:
S1:根据OSS项目获得的Email数据,同时结合项目的时效特性,分别搭建六种不同的网络:无向无权网络、无向有权网络、无向时效网络、有向无权网络、有向有权网络、有向时效网络。
S2:采用节点排序算法Degree-Based,PageRank,LeaderRank,Hits得出不同网络中各个节点的分值,同时利用网络拓扑结构,得到每个节点的特征向量中心性和聚类系数。
S3:将同种类型的Email网络合并,每个节点即作为一个样本,将上述步骤S2不同算法和网络特性得到的分值排名作为特征,样本标签为是或者不是开发者,构成一个分类器。同时,用欠采样的方法预处理样本数据。
S4:随机抽取处理后的总样本的80%作为训练样本,20%作为测试样本,采用Bayesian算法进行机器学习,并对测试样本进行测试。
进一步,所述步骤S1中,无向无权网络Nc(V,L,A,T),V表示网络中n个节点集合,L表示节点与节点的连边集合,A表示网络的邻接矩阵,T表示每个开发者出现的时刻;
无向有权网络Nc(V,L,W,T)中V,L,T与上述相同,W表示网络的权重邻接矩阵,与矩阵A不同在于,Wij等于节点i与节点j之间的Email数量;
无向时效网络Nσ(V,L,Uσ,T)中V,L,T与上述相同,Uσ是时间窗σ内的一个矩阵
对于给定的σ,主要考虑[T-σ,T]的时间段内节点之间的相互通信;
有向无权网络中V,T与上述相同,表示有向边集合,即表示的是节点i存在指向节点j的有向边,而仅且表示节点j存在指向节点i的有向边,在中如果仅有节点i向节点j发送邮件,则
有向有权网络中与上述相同,表示节点j向节点i发送的邮件数,表示的是节点i向节点j发送的邮件数;
有向时效网络中与上述相同,表示在时间窗σ内的一个矩阵,其中
所述步骤S2中,在算法Degree-Based中,考虑节点的直接影响力,节点的度指与该节点直接相连的边的数目,度的大小即作为该项特征的分值;
在算法PageRank中,以有向无权网络为例,特征分值为
其中
为节点j的出边的数量,则
X=PX
其中X=[x1,x2,…,xn],P=[pij]n×n
为了防止非连通网络引起的非唯一排列问题,矩阵P被替换为Q:
其中得到X=QX。为得更一般的结果,同时防止数值过大,对该式采用如此迭代计算:
在算法LeaderRank中,以有向无权网络为例,在原有网络中增加一个背景节点,与其他所有节点做双向连接,特征分值为
同样的经过迭代运算:
得到一般性结果,之后将增加的背景节点分值平均分配个原网络中的所有节点,得到特征分值:
在Hits算法中,给每个节点赋予了两个参数:权威中心性xi和核心中心性yi
其中α,β均为常数。
因为两个参数都与指向性有关,所以Hits算法只针对有向网络进行分析。为使结果归一化,同时保持数量级不变,进行迭代计算:
在无向网络中,由于节点的边没有方向性,指向一个节点与被一个节点指向并没有区别,定义一个等同于权威中心性和核心中心性的重要分数zi,zi在无向无权网络、无向有权网络、无向时效网络中,分别表示为:
在特征向量中心性中,特征分值为
为得到一般性结果同时保持数量级相等,进行迭代计算:
在聚类系数中,描述的是网络中节点的邻居中实际存在的边与该点邻居中可能存在的边的比值,特征分值为
所述步骤S3中,网络合并后的节点个数多于原有所有项目用户数总和,因为不同时刻网络存在同一个节点。考虑到了在一个时刻里只存在一个刚晋升的开发者,即在一个时刻,正标签的样本只有一个,导致数据样本不均衡,因此采用欠采样随机删除部分负标签样本。同时,对特征分值进行归一化处理来消除不同算法分值不同而影响结果,采用的是每个分值排名的百分比作为样本的特征值。
所述步骤S4中,利用Matlab机器学习工具包,对预处理之后的数据样本总量的80%采用Bayesian算法进行学习,然后对剩余数据进行测试,测试预测准确率。
如上所述为本发明在OSS项目开发者预测的实施例介绍,本发明通过OSS项目中的Email数据搭建网络,利用多种网络节点排序算法得到各个节点相应算法的特征分值,同时结合网络的拓扑性质得到参数特征向量中心性和聚类系数,对特征分值和参数排名分别做归一化处理,将处理后的分值排名作为每个节点的特征值,输入机器学习分类器,采用Bayesian算法对样本进行学习,而后对测试样本进行预测。最终的预测结果相比当前各类网络节点排序算法在准确率上有了显著的提高。对发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!