一种模糊鉴别聚类的茶叶红外光谱分类方法与流程
本发明涉及一种茶叶分类方法,具体涉及一种模糊鉴别聚类的茶叶红外光谱分类方法。
背景技术:
茶是当今消费最多的饮料之一。随着生活水平的提高,对茶叶的质量要求越来越高,如何合理地选择茶叶已越来越被人们所关注。研究简单、快速和正确率较高的识别方法已经科研工作者的一个重要任务。
中红外光谱主要用于有机化合物的定性和定量分析。它的频率在4000cm-1~625cm-1之间,正是一般有机化合物基频振动频率范围,可以给出非常丰富的结构信息:谱图中的特征基团频率指出分子中官能团的存在,全部光谱图则反映整个分子的结构特征。同时,该检测技术还具有应用范围广,方式多样,仪器结构简单,操作方便,测试迅速,谱图重复性好等优点,从而快速将不同品种的茶叶进行分类。中红外光谱技术是作为一种无损检测技术,已经在农业、食品、医学、药学等领域具有广泛研究与应用。
模糊聚类是一种无监督的学习方法。模糊聚类已经被广泛应用于数字图像处理、计算机视觉和模式识别中,使用最广泛的模糊聚类算法是由Bezdek提出的模糊C-均值聚类(FCM)。建立在最小平方误差准则上的FCM可对线性可分的数据进行聚类。但是FCM在聚类过程中无法动态提取鉴别信息和改变数据维数。为了解决这个问题,本发明设计了一种模糊鉴别聚类方法(FDCM)。FDCM可实现模糊聚类过程中进行数据鉴别信息的提取和数据压缩,可以达到更高的聚类准确率。
技术实现要素:
本发明的目的在于克服现有技术存在的上述缺陷,提供一种检测速度快、分类准确率高、分类效率高的一种快速模糊鉴别聚类的茶叶红外光谱分类方法。
本发明一种模糊鉴别聚类的茶叶红外光谱分类方法的技术方案是:先用光谱仪采集不同品种茶叶的红外光谱样本数据,然后采用主成分分析方法对样本数据降维,压缩到14维,再采用线性鉴别分析方法提取14维的训练样本数据的鉴别信息得到鉴别向量,将14维的测试样本数据投影到其鉴别向量上得到二维测试样本数据,还依次按以下步骤:
A、将二维测试样本数据进行模糊C均值聚类,得到的聚类中心作为初始聚类中心;
B、根据初始聚类中心,先计算模糊类间散射矩阵,再计算模糊总体散射矩阵,然后根据模糊类间散射矩阵和模糊总体散射矩阵计算特征向量,将测试样本和初始聚类中心分别转化到特征空间,最后在特征空间中计算模糊隶属度函数值:再通过模糊隶属度函数值在特征空间中计算聚类中心值:
C、先分别计算每个14维训练样本的平均值,再分别计算测试样本的聚类中心值和训练样本的平均值的欧式距离,聚类中心值离训练样本的欧式距离最小的,则判定该聚类中心值所属茶叶品种和该训练样本的茶叶品种是相同品种。
本发明的有益效果是:
1、本发明采用红外光谱技术和模糊鉴别聚类方法来进行茶叶分类,首先用傅里叶红外光谱分析仪采集茶叶样本的红外光谱,使用多元散射校正对茶叶光谱数据进行预处理,接着对红外光谱进行降维处理;然后用特征提取方法提取茶叶样本的鉴别信息;最后用模糊鉴别聚类进行茶叶品种的分类。本发明融合了模糊C均值聚类和线性判别分析,具有检测速度快、分类效率高、无污染、所需茶叶训练样本少等优点,可实现模糊聚类过程中进行数据鉴别信息的提取和数据压缩,可以达到比模糊C均值聚类更高的聚类准确率,实现不同品种茶叶的正确分类。
2、茶叶的红外漫反射光谱包含了茶叶内部的茶多酚、咖啡碱和可溶性固形物等内部品种信息,不同品种的茶叶所对应的红外漫反射光谱也不同,因此本发明在聚类过程中压缩茶叶红外光谱,可提高茶叶分类的准确率,再根据模糊鉴别聚类的方法将不同品种茶叶进行分类,提高分类准确率。
附图说明
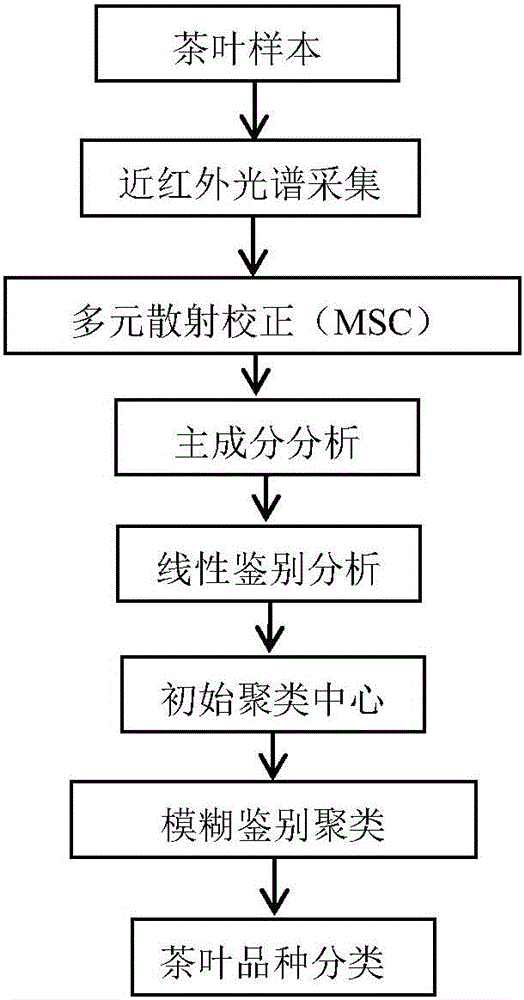
图1是本发明一种模糊鉴别聚类的茶叶红外光谱分类方法的流程图;
图2是实施例中茶叶样本的红外光谱图;
图3是实施例中样本经过多元散射校正处理后的红外光谱图;
图4是实施例中14维的测试样本数据投影到其鉴别向量上得到的二维测试样本数据示意图;
图5是实施例中经模糊鉴别聚类后得到的模糊隶属度值曲线分布图。
具体实施方式
参见图1,用光谱仪采集不同品种茶叶的红外光谱样本数据。将FTIR-7600型傅里叶红外光谱分析仪开机预热1个小时,扫描次数为32,光谱扫描的波数范围为7800cm-1~350cm-1,扫描间隔为1.928cm-1,分辨率为4cm-1。采集环境温度为25℃,相对湿度50%,取不同品种的茶叶样本研磨粉粹,再用40目筛进行过滤后,各取0.5g分别与溴化钾1:100均匀混合得到每个样本的混合物,各取每个样本取混合物1g进行压膜,然后用光谱仪扫描3次,取3次的平均值作为样本光谱数据,每个样本光谱数据都是一个1868维的数据。测试样本数为n,剩余为训练样本。
用多元散射校正(MSC)对茶叶的光谱样本数据进行预先处理,消除散射影响,增强与成分含量相关的光谱吸收信息。
经多元散射校正处理后,采用主成分分析方法(PCA)将处理后的茶叶的光谱样本数据进行特征分解,得到前14个特征向量v1,v2…v14和对应的14个特征值λ1,λ2…λ14,每个特征向量v1,v2…v14都是1868维的数据。将光谱样本数据投影到14个特征向量v1,v2…v14上得到14维的数据,对光谱样本数据进行降维,即从1868维压缩到14维。
采用线性鉴别分析(LDA)方法提取14维的训练样本数据的鉴别信息,得到鉴别向量,鉴别向量数为2,将14维的测试样本数据投影到其鉴别向量上可得到二维测试样本数据。
设置模糊C-均值聚类(FCM)的权重指数m=2,类别数c=3,迭代次数初始值r=0,最大迭代次数rmax=100,迭代最大误差上限值ε=0.00001,将得到的二维测试样本数据进行模糊C均值聚类(FCM),得到的聚类中心作为初始聚类中心
根据初始聚类中心先计算模糊类间散射矩阵SfB:
其中,为第r次迭代时第k个测试样本xk隶属于第i类的模糊隶属度,m代表权重指数;c为类别数,为第r次迭代时第i类的类中心值,为测试样本的均值,n为测试样本数,xj为第j个测试样本,T代表矩阵转置运算,1≤k≤n,1≤j≤n,1≤i≤c。
再计算模糊总体散射矩阵SfT:
其中,xk为第k个测试样本。
然后根据模糊类间散射矩阵SfB和模糊总体散射矩阵SfT计算特征向量:
其中,为模糊离散度矩阵的逆矩阵,SfB为模糊类间散列矩阵,λ是特征向量ψ所对应的特征值。
将第k个测试样本xk∈Rq转化到特征空间:
yk=xkT[ψ1,ψ2,...,ψp](yk∈Rp)
其中,p和q均为测试样本的维数,ψp为第p个特征向量。
同样将初始聚类中心也转化到特征空间:
其中,ψp为第p个特征向量。
在特征空间中计算模糊隶属度函数值:
其中,yk为特征空间里第k个样本,是第r+1次迭代时样本yk隶属于类别i的模糊隶属度值,uik(r+1)是第r+1次迭代计算的模糊隶属度值;vi'(r)和vj'(r)分别是第r次迭代计算的第i类和第j类的类中心值。
再通过模糊隶属度函数值在特征空间中计算第i类的聚类中心值
其中,是第r+1次迭代计算的第i类的类中心的值。
增加迭代数r值,即r=r+1,直到或者r>rmax为止,计算终止;否则将的值赋给变量的值赋给变量继续重新计算模糊类间散射矩阵SfB和计算模糊总体散射矩阵SfT,如此循环。
最后,分别计算每个14维训练样本的平均值分别计算测试样本的聚类中心值和训练样本的平均值的欧式距离,某个聚类中心值离哪种训练样本的茶叶品种的欧式距离最小的,则判定该聚类中心值所属茶叶品种和这种训练茶叶品种是相同品种。当计算出的聚类中心距离某种训练样本的欧式距离最小,则该聚类中心所属茶叶品种和这种训练样本茶叶品种是相同品种。
以下提供本发明的一个实施例:
实施例
取优质乐山竹叶青、劣质乐山竹叶青和峨眉山毛峰三种类别的茶叶,用光谱仪采集红外光谱样本,如图2所示。每种类别的茶叶采集32个样本,共获得96个样本,每个样本为一个1868维的数据,每种样本选取22个为测试样本,则三种类别的茶叶的测试样本共66个,剩余的30个样本作为训练样本。
用多元散射校正对茶叶红外光谱样本数据进行预处理,得到如图3所示的光谱图。再采用主成分分析方法对样本数据进行降维处理:因为前14个主成分累计可信度为100%>98%,所以将茶叶样本红外光谱进行特征分解得到前14个特征向量v1,v2…v14和对应的14个特征值λ1,λ2…λ14。每个特征向量都是1868维的数据,特征值具体如下:
λ1=293.9148,λ2=129.0279,λ3=19.0010,λ4=14.8802,
λ5=6.4349,λ6=3.8189,λ7=2.0033,λ8=1.4310,
λ9=1.0661,λ10=0.6298,λ11=0.4020,λ12=0.3169,
λ13=0.2706,λ14=0.2294。
将样本数据投影到14个特征向量上得到14维的数据,即从1868维压缩到14维。
再提取茶叶训练样本红外光谱的鉴别信息:采用线性鉴别分析提取14维训练样本数据的鉴别信息,鉴别向量数为2,将14维的测试样本数据投影到其鉴别向量上可得到二维的测试样本数据,如图4所示。
设置模糊C-均值聚类的权重指数m=2,迭代次数初始值r=0,最大迭代次数rmax=100,类别数c=3,测试样本数n=66,误差上限值ε=0.00001,对二维测试样本数进行模糊C均值聚类得到聚类中心,将该聚类中心作为初始聚类中心
先依次计算模糊类间散射矩阵SfB、模糊总体散射矩阵SfT和特征向量:
其中,xk为第k个测试样本,为第r次迭代时第k个样本xk隶属于第i类的模糊隶属度,m代表权重;c为类别数,为第r次迭代时第i类的类中心值,为测试样本的均值,n为测试样本数,xj为第j个测试样本,T代表矩阵转置运算;为模糊离散度矩阵的逆矩阵,SfB为模糊类间散列矩阵,λ是特征向量ψ所对应的特征值。再将xk∈Rq转化到特征空间(由ψ1,ψ2,...,ψp组成):
yk=xkT[ψ1,ψ2,...,ψp](yk∈Rp),
其中,p和q均为样本的维数,ψp为第p个特征向量。
同样将转化到特征空间:
其中,(i=1,2,3)为初始聚类中心ψp为第p个特征向量。
在特征空间中计算模糊隶属度函数值:
其中,yk为特征空间里第k个样本,是第r+1次迭代时样本yk隶属于类别i的模糊隶属度值,uik(r+1)是第r+1次迭代计算的模糊隶属度值;vi'(r)和vj'(r)分别是第r次迭代计算的第i类和第j类的类中心值。
然后,在特征空间中计算i类的类中心值v′i(r+1):
其中,是第r+1次迭代计算的第i类的类中心的值。
增加迭代数r值,即r=r+1;,直到或者r>rmax计算终止,否则将的值赋给变量的值赋给变量继续开始重新计算。
结果如下:p=2,q=2,迭代终止时r=27次,类中心矩阵为:
训练样本是三个品种茶叶,计算每种茶叶的训练样本的平均值为:
峨眉山毛峰平均值为
优质乐山竹叶青平均值为
劣质乐山竹叶青的平均值为
最后,判断测试样本的茶叶的三个类别分别属于哪个品种茶叶:分别计算测试样本的某个聚类中心和训练样本三类茶叶的平均值的欧式距离,某个聚类中心离哪种训练茶叶品种的欧式距离最小则判定该聚类中心所属茶叶品种和这种训练茶叶品种是相同品种,具体如下:
判断以为类中心的茶叶所属类别:
很明显距离最近,则判定为类中心的茶叶是正品优质竹叶青。
同样方法可判定为类中心的茶叶是峨眉山毛峰,为类中心的茶叶是劣质竹叶青。
对于第k个测试样本xk,判断其属于哪一类的方法是:如果其模糊隶属度则判定xk属于所属的类别,具体如下:
迭代终止后的模糊隶属度值如图5所示,第1个样本的模糊隶属度为:所以则判定第1个样本属于所属的类别,即峨眉山毛峰,其余测试样本同样方法判断其所属的茶叶种类。
根据以上方法计算和判断,对于66个测试样本,根据模糊隶属度得聚类准确率可高达95.5%。
- 还没有人留言评论。精彩留言会获得点赞!