一种GPU加速的批处理同构稀疏矩阵乘满向量的处理方法与流程
本发明属于电力系统高性能计算应用领域,尤其涉及一种GPU加速的批处理同构稀疏矩阵乘满向量的处理方法。
背景技术:
潮流计算是电力系统中应用最广泛、最基本和最重要的一种电气运算。在电力系统运行方式和规划方案的研究中,都需要进行潮流计算以比较运行方式或规划供电方案的可行性、可靠性和经济性。同时,为了实时监控电力系统的运行状态,也需要进行大量而快速的潮流计算。因此,在系统规划设计和安排系统的运行方式时,采用离线潮流计算;在电力系统运行状态的实时监控中,则采用在线潮流计算。
而实际生产过程中,无论离线潮流和在线潮流计算都对潮流的计算速度有这比较高的要求。在涉及规划设计和安排运行方式的离线潮流中,因设备落地方案等情况复杂,需要仿真运行的种类多,潮流计算量大,单个潮流计算时间影响整体仿真时长;而在电力系统运行中进行的在线潮流计算对计算时间敏感度高,需要实时给出潮流计算结果,如在预想事故、设备退出运行对静态安全的影响的潮流计算中,系统需要计算大量预想事故下潮流分布,并实时地做出预想的运行方式调整方案。
传统的牛顿拉夫逊法潮流计算中,修正方程组求解占潮流计算时间的70%,修正方程组求解的计算速度影响程序的整体性能。而随着CPU计算速度提升的放缓,现阶段的单个潮流计算计算时间已经达到一个瓶颈。目前对潮流计算的加速方法大多集中在单个潮流内部运算加速,实际生成中对批处理加速潮流计算的研究较少。
GPU是一种众核并行处理器,在处理单元的数量上要远远超过CPU。传统上的GPU只负责图形渲染,而大部分的处理都交给了CPU。现在的GPU已经法阵为一种多核,多线程,具有强大计算能力和极高存储器带宽,可编程的处理器。在通用计算模型下,GPU作为CPU的协处理器工作,通过任务合理分配分解完成高性能计算。
稀疏线性方程组求解计算具有并行性。使用迭代法求解大型稀疏线性方程已经得到广泛的关注与应用。在迭代法求解稀疏线性方程过程中有大量的稀疏矩阵乘满向量的计算需求。因为矩阵中每行与满向量相乘的计算相互独立,没有依赖关系,天然可以被并行的计算处理,适合GPU加速。
N-1静态安全分析需要计算大量的潮流,在使用迭代法求解潮流修正方程时稀疏矩阵乘满向量是其中重要的模块,耗时很多。但由于断线最多只影响稀疏矩阵四个位置的元素,因此通过冗余设计,可将所有断线故障的节点导纳阵冗余设计成和基态电网稀疏结构相同的一系列矩阵,然后再按相同的稀疏存储格式合并存储,以实现GPU读取数据的合并访问。再通过CPU和GPU之间合理的调度可以批处理同构稀疏矩阵乘满向量。国内外学者已经开始对GPU进行稀疏线性方程组加速迭代求解的方法进行了研究,但是没有对其中重要的模块稀疏矩阵乘满向量的加速求解做过专门研究,也没做过批处理同构稀疏矩阵乘满向量的工作,无法使程序充分发挥GPU的优势。
因此,亟待解决上述问题。
技术实现要素:
发明目的:针对现有技术的不足,本发明提供了一种能提高了算法并行度和访存效率,大幅减少N-1静态安全分析中迭代法求解潮流修正方程时庞大稀疏矩阵乘满向量计算需求耗时的GPU加速的批处理同构稀疏矩阵乘满向量的处理方法。
潮流计算:电力学名词,指在给定电力系统网络拓扑、元件参数和发电、负荷参量条件下,计算有功功率、无功功率及电压在电力网中的分布。
N-1静态安全分析:对运行中的网络或某一研究态下的网络,按N-1原则,研究一个个运行元件因故障退出运行后,元件有无过负荷及母线电压有无越限。
GPU:图形处理器(英语:GraphicsProcessingUnit,缩写:GPU)。
技术方案:本发明所述的一种GPU加速的批处理同构稀疏矩阵乘满向量的处理方法,大量同构稀疏矩阵A1~Abs的乘满向量操作:A1x1=b1,…,Absxbs=bbs,其中x1~xbs为被乘的满向量,b1~bbs为结果满向量,bs为批处理的矩阵数量,所述方法包括:
(1)在CPU中将所有矩阵A1~Abs存储为行压缩存储格式,矩阵A1~Abs共享相同的行偏移数组CSR_Row和列号数组CSR_Col,行偏移数组元素CSR_Row[k]中存储的是矩阵第k行之前的非零元总数,k取值范围从1到n+1;每个矩阵具体的数值存储于各自的数值数组CSR_Val1~CSR_Valbs中,被乘满向量存储于数组x1~xbs中,结果满向量存储于数组b1~bbs中,数组CSR_Val1~CSR_Valbs、数组x1~xbs和数组b1~bbs都按照矩阵编号递增顺序连续存储;
(2)CPU将GPU内核函数所需数据传输给GPU;
(3)将矩阵A1~Abs的乘满向量任务分配给GPU线程,一个线程块负责矩阵A1~Abs中特定一行的乘满向量计算,并优化内存访问模式;
(4)GPU中执行批处理同构稀疏矩阵乘满向量内核函数spmv_batch,批处理同构稀疏矩阵乘满向量内核函数定义为spmv_batch<Nblocks,Nthreads>,其线程块大小Nthread为bs,线程块数量Nblocks=n,总线程数量为:Nblocks×Nthreads;调用内核函数spmv_batch<Nblocks,Nthreads>来批处理并行计算同构稀疏矩阵乘满向量。
其中,所述步骤(2)中,其所需数据包括:稀疏矩阵的维数n,批处理的矩阵数量bs,稀疏结构数组CSR_Row和CSR_Col,稀疏矩阵数值数组CSR_Val1~CSR_Valbs,被乘满向量x1~xbs,结果满向量b1~bbs。
优选的,所述步骤(3)中,所述数值数组CSR_Val1~CSR_Valbs、被乘满向量x1~xbs、结果满向量b1~bbs的存储区域均为bs行的矩阵,并对三个矩阵进行转置操作,以实现合并访问。
再者,所述步骤(4)中,所述内核函数spmv_batch<Nblocks,Nthreads>的计算流程为:
(4.1)CUDA自动为每个线程分配线程块索引blockID和线程块中的线程索引threadID;
(4.2)将blockID和threadID赋值给变量bid和t,之后通过bid和t来索引bid号线程块中的t号线程;
(4.3)第bid号线程块负责所有矩阵第bid行的乘满向量操作;
(4.4)第bid号线程块中,每个线程负责一个矩阵的第bid行乘满向量,具体步骤如下:
1)读取当前行以及下一行的第一个非零元的索引CSR_Row[bid]和CSR_Row[bid+1],定义变量j=CSR_Row[bid];
2)判断j是否小于CSR_Row[bid+1],否则线程结束执行;
3)读取当前列CSR_Col[j],并把它赋值给变量cur_col;
4)更新结果满向量bt的bid号元素值bt[bid]+=CSR_Valt[j]×xt[cur_col];
5)j=j+1,返回2)。
有益效果:与现有技术比,本发明具有以下显著优点:本发明利用CPU负责控制程序的整体流程和准备数据,GPU负责计算密集的向量乘法,利用批处理模式提高了算法并行度和访存效率,大幅降低了批量稀疏矩阵乘满向量的计算时间,可以解决N-1静态安全性分析中迭代法求解潮流修正方程时庞大的稀疏矩阵乘满向量计算需求耗时多的问题。
附图说明:
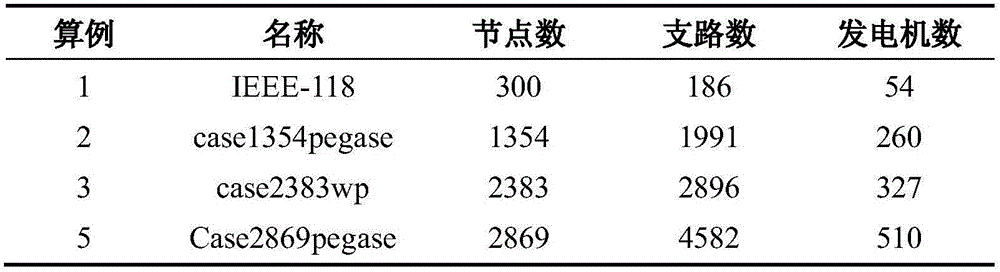
图1为本发明的实例电网的数据表;
图2为本发明的实例计算时间;
图3为本发明的流程示意图。
具体实施方式:
如图3所示,本发明一种GPU加速的批处理同构稀疏矩阵乘满向量的处理方法,大量同构稀疏矩阵A1~Abs的乘满向量操作:A1x1=b1,…,Absxbs=bbs,其中x1~xbs为被乘的满向量,b1~bbs为结果满向量,bs为批处理的矩阵数量,所述方法包括:
(1)在CPU中将所有矩阵A1~Abs存储为行压缩存储格式,矩阵A1~Abs共享相同的行偏移数组CSR_Row和列号数组CSR_Col,行偏移数组元素CSR_Row[k]中存储的是矩阵第k行之前的非零元总数,k取值范围从1到n+1;每个矩阵具体的数值存储于各自的数值数组CSR_Val1~CSR_Valbs中,被乘满向量存储于数组x1~xbs中,结果满向量存储于数组b1~bbs中,数组CSR_Val1~CSR_Valbs、数组x1~xbs和数组b1~bbs都按照矩阵编号递增顺序连续存储;
(2)CPU将GPU内核函数所需数据传输给GPU,所需数据包括:稀疏矩阵的维数n,批处理的矩阵数量bs,稀疏结构数组CSR_Row和CSR_Col,稀疏矩阵数值数组CSR_Val1~CSR_Valbs,被乘满向量x1~xbs,结果满向量b1~bbs;
(3)将矩阵A1~Abs的乘满向量任务分配给GPU线程,一个线程块负责矩阵A1~Abs中特定一行的乘满向量计算,并优化内存访问模式;其中,所述数值数组CSR_Val1~CSR_Valbs、被乘满向量x1~xbs、结果满向量b1~bbs的存储区域均为bs行的矩阵,并对三个矩阵进行转置操作,以实现合并访问;
(4)GPU中执行批处理同构稀疏矩阵乘满向量内核函数spmv_batch,批处理同构稀疏矩阵乘满向量内核函数定义为spmv_batch<Nblocks,Nthreads>,其线程块大小Nthread为bs,线程块数量Nblocks=n,总线程数量为:Nblocks×Nthreads;调用内核函数spmv_batch<Nblocks,Nthreads>来批处理并行计算同构稀疏矩阵乘满向量。
本发明内核函数spmv_batch<Nblocks,Nthreads>的计算流程为:
(4.1)CUDA自动为每个线程分配线程块索引blockID和线程块中的线程索引threadID;
(4.2)将blockID和threadID赋值给变量bid和t,之后通过bid和t来索引bid号线程块中的t号线程;
(4.3)第bid号线程块负责所有矩阵第bid行的乘满向量操作;
(4.4)第bid号线程块中,每个线程负责一个矩阵的第bid行乘满向量,具体步骤如下:
1)读取当前行以及下一行的第一个非零元的索引CSR_Row[bid]和CSR_Row[bid+1],定义变量j=CSR_Row[bid];
2)判断j是否小于CSR_Row[bid+1],否则线程结束执行;
3)读取当前列CSR_Col[j],并把它赋值给变量cur_col;
4)更新结果满向量bt的bid号元素值bt[bid]+=CSR_Valt[j]×xt[cur_col];
5)j=j+1,返回2)。
本发明所使用的GPU计算平台配备一张TeslaK20CGPU卡和IntelXeonE5-2620CPU,GPU的峰值带宽可达208GB/s,单精度浮点计算量峰值可达3.52Tflops,CPU主频为2GHz。CPU计算平台配备IntelCorei7-3520M2.90GHz的CPU。GPU计算平台上对图1中的四个实例电网的电纳矩阵进行了测试,图2为对应四个电网的不同bs下稀疏矩阵乘满向量的测试时间。
- 还没有人留言评论。精彩留言会获得点赞!