多媒体文档概括的制作方法
本公开涉及多媒体文档概括。
背景技术:
概括包括多媒体内容(诸如文本和图像)的文档(诸如文章等)通常包含提供文本摘录和图像,该图像被假定为提供对文档的概述。然而,当前的很多方法趋向于仅关于文档的文本部分处理概括任务。对于图像部分,这些方法使用第一幅或者顶部全尺寸图像作为缩略图,而不考虑图像部分的上下文以及其可以如何关联到文本部分。因此,实际上未包含关于图像的概括方面。这忽略了如下事实,即其它图像或者部分可能与文本部分更相关,使得集体地,其它图像部分和文本部分将提供更好的、更相关的信息内容。
技术实现要素:
对多媒体文档概括技术进行了描述。即,给定包括不同内容类型(例如文本和一组图像)的文档,各种实施方式通过以下方式来生成概括:提取文档中的相关文本区段和图像的相关区段,其中对概括中的文本的量和图像的数目/尺寸进行约束。
在一个或者多个实施方式中,利用模型来产生考虑了诸如文本和图像之类的不同内容类型的文档概括。对于文本和图像上下文,该模型产生了在概括的图像区段和文本区段之间具有高结合度的多模式概括,而同时将概括中的信息量(对文档内容的覆盖范围和由概括提供的信息的多样性两者而言)最大化。
在第一方法中,给定的文档被分割成元素。元素的一个类涉及诸如文本单元之类的第一内容类型,而元素的另一类涉及诸如图像单元之类的第二不同的内容类型。增益值和成本被分配到每个元素。与元素关联的预算约束被确立,并且可以包括图像的尺寸/数目、和句子、单词、或者字符的数目。增益值是对于文档的信息内容而言元素所具有的覆盖范围和对于当前概括而言元素所具有的信息多样性的函数。制定目标函数,其考虑了信息内容的覆盖范围、信息内容的多样性、以及概括的图像和文本部分之间的结合度。对目标函数进行数学操作,以便就预算而言迭代地将目标函数最大化。在一个实施方式中,这通过选择元素包括在概括中来实现,该元素提供目标函数的增加相对于元素成本的最大比率。元素的增益可以在每个迭代之后改变。解是在预算约束内具有针对目标函数的近似最大值的概括。
在第二方法中,利用了基于图的方法。特别地,创建了如下图,其节点表示不同内容类型,例如文本元素或者图像元素。每个元素具有基于该元素的固有值的对应奖励,而不考虑对应文档中的其它元素。每个元素具有关联的成本。例如,文本元素的成本可以在字符、单词、或者句子的数目方面给出。每个图像区段的成本可以基于其尺寸或者作为单位成本来分配。图中的边缘权重(edge weight)表示由一个元素捕获的关于另一元素的信息量的概念。目标函数被限定并且测量原始文档中留下——即未被当前概括捕获——的剩余奖励。对该目标函数进行数学操作以将该目标函数最小化。
本发明内容以简化形式介绍了概念选择,下面在具体实施方式中对它们进行进一步描述。因此,本发明内容不旨在标识所要求保护的主题的基本特征,也不旨在用于帮助确定所要求保护的主题的范围。
附图说明
参照附图描述了具体实施方式。在图中,附图标记的最左边的位标识附图标记首先出现的图。相同附图标记在描述和图中的不同实例中的使用可以指示相似或者相同的项。图中表示的实体可以指示一个或者多个实体,并且因此可以互换地参照所讨论的实体的单数或者复数形式。
图1是可操作为采用本文中描述的多媒体文档概括技术的示例实施方式中的环境的图示。
图2描绘了更详细地示出了图1中的多媒体文档概括模块的示例实施方式中的系统。
图3是描绘其中处理多媒体文档以提供概括的示例实施方式中的过程的流程图。
图4是描绘其中处理多媒体文档以提供概括的示例实施方式中的过程的流程图。
图5是描绘其中处理多媒体文档以提供概括的示例实施方式中的过程的流程图。
图6图示了其中节点表示文本元素和图像元素的基于图的示例方法。
图7图示了包括示例设备的各种部件的示例系统,该示例设备可以被实施为如参照图1至图6描述和/或利用以实施本文中描述的技术的任何类型的计算设备。
具体实施方式
综述
描述了多媒体文档概括技术。即,给定包括不同内容类型(例如,文本和一组图像)的文档,各种实施方式通过提取文档中的相关文本区段和图像的相关区段来生成概括,其中约束了概括中的文本的量和图像的数目/尺寸。
在一个或者多个实施方式中,利用模型产生考虑了诸如文本和图像之类的不同内容类型的文档概括。对于文本和图像上下文,该模型产生在概括的图像区段和文本区段之间具有高结合度的多模式概括,而同时将概括中的信息量最大化(就文档内容的覆盖范围和由概括提供的信息的多样性两者而言)。
在本文档的上下文中,“结合度”指代在概括中出现的不同内容类型之间的相关性,例如在概括中出现的文本和图像之间的相关性。“覆盖范围”指代在概括中出现的不同内容类型将文章中的相应的对应内容类型覆盖得多好。“多样性”指代对于每个内容类型而言基于文章中的对应内容类型在概括中出现的多样性信息的量。下文描述的每个方法都利用了所谓的目标函数,目标函数包括考虑了与文章的不同内容类型有关的结合度、覆盖范围、以及多样性的项。对目标函数进行数学操作以产生具有对结合度、覆盖范围、以及多样性的期望测量的概括。
在第一方法中,给定文档被分割成元素。元素的一个类涉及诸如文本单元(诸如句子、句子片段、段落、或者任何其它合适的文本单元)之类的第一内容类型。元素的另一类涉及诸如图像单元(全图像或者图像区段)之类的第二不同内容类型。增益值和成本被分配给每个元素——文本元素和图像元素两者。针对图像元素和文本元素两者的增益可以表示为跨文本和图像类型可比较的实数。针对两个类型的元素的成本可以或者不可以比较或者互换。确立与元素关联的预算约束。预算约束可以从用户确立并且可以包括诸如图像的尺寸/数目、以及句子、单词、或者字符的数目之类的东西。增益值是就文档的信息内容而言元素所具有的覆盖范围和就当前概括而言元素所具有的信息多样性的函数。由“当前概括”意指因为所描述的解是迭代解,所以下一迭代依赖于该解的“当前”状态。
制定考虑到信息内容的覆盖范围、信息内容的多样性、以及概括的图像部分和文本部分之间的结合度的目标函数。对目标函数进行数学操作,以就预算而言迭代地将目标函数最大化。在一个实施方式中,这通过选择元素包括在概括中来实现,这提供目标函数的增加相对于其成本的最大比率。元素的增益可以在每个迭代之后改变。通常,如果同一类(即文本类或者图像类)的元素被选择为被包括在概括中并且如果两个元素相关,则元素的增益将减少。这有助于保证具有相似信息内容的来自同一类的元素更不可能在解中,从而增加解的多样性。如果元素是从另一类选择的,并且两个元素相关,则元素的增益将增加。这有助于保证具有相似信息内容的来自不同类的元素更可能在解中,从而增加解的相关性。解是在预算约束内具有针对目标函数的近似最大值的概括。
在第二方法中,利用了基于图的方法。特别地,创建了如下图,其节点表示不同内容类型,例如文本元素或者图像元素。每个元素具有基于该元素的固有值的对应奖励,而不考虑对应文档中的其它元素。在一个方法中,文本元素的奖励使用如在下文更详细描述的词性(POS)标签确定。每个元素具有关联的成本。例如,文本元素的成本可以在字符、单词、或者句子的数目方面给出。每个图像区段的成本可以基于其尺寸或者作为单位成本分配。图中的边缘权重表示由一个元素捕获的关于另一元素的信息量的概念(notion)。目标函数被定义并且测量原始文档中留下——即未被当前概括捕获——的剩余奖励。对该目标函数进行数学操作以将该目标函数最小化,从而提供得到的概括。
在下文的讨论中,文本和图像形式的特定内容类型被用作讨论不同方法的基础。然而,要领会和理解的是,可以利用除了文本和图像之外的不同内容类型,而不脱离所要求保护的主题的精神和范围。例如,一组内容类型可以涉及视频和文本。
上文和下文描述的各种方法考虑了用于概括的文档中的文本和图像两者,并且因此构成对仅考虑文本的之前的方法的改善。因此,所创建的概括不仅呈现信息的覆盖范围和信息内容的多样性,而且并入了组成概括的图像和文本之间的结合度。通过查看恰当的视觉图像区段和对应的相关文本,使用所描述的技术生成的概括促进了对关联文档的更好理解。这些技术足够稳健以单独执行对两个分立媒体(即文本和图像)的概括。特别地,这些技术可以被应用在仅有图像或者仅有文本的概括的上下文中,并且因此,可以创建文本文档和图像册的概括。
在所描述的方法中,可以通过对文本部分中的句子的数目、单词的数目、字符的数目等进行约束,连同对图像部分中的图像的数目、图像的尺寸等进行约束,来限制概括的大小。这称为预算。因此,用户可以限定这一概括将是多大。
优化问题以如下方式限定,即如果原始文档包含图像和句子,则将总是产生至少图像区段和至少句子/单词/字符(依赖于预算)。属于文档的不相关图像可以在多模式概括中被避免,从而保证关于文档,读者未被文档的概括误导。还可以修改与句子和图像关联的奖励,以将概括向着一组主题偏置。例如,可以检测用户的情趣,并且用户的情趣可以被用于偏置奖励并且针对读者生成个性化的概括。
在以下讨论中,首先描述了可以采用本文中描述的技术的示例数字媒体环境。接着描述了可以在示例环境以及其它环境中执行的示例过程。因此,示例过程的执行不限于示例环境,并且示例环境不限于示例过程的执行。
示例数字媒体环境
图1是对示例实施方式中的示例数字媒体环境100的图示,该示例数字媒体环境100可操作为采用可用于执行本文中描述的多媒体文档概括的技术。如本文中所使用那样,术语“数字媒体环境”指代可以用于实施本文中描述的技术的各种计算设备和资源。所图示的数字媒体环境100包括可以以各种方式配置的计算设备102。
例如,计算设备102可以被配置为台式计算机、膝上型计算机、移动设备(例如假设为诸如所图示的平板电脑或者移动电话之类的手持式配置)等。因此,计算设备102的范围可以从具有大量存储器和处理器资源的全资源设备(例如个人计算机、游戏控制台)到具有有限的存储器和/或处理资源的低资源设备(例如移动设备)。此外,示出了单个计算设备102,但是计算设备102可以表示多个不同设备,诸如商用的用于如联系图7进一步描述那样“在云上”执行操作的多个服务器。
计算设备102包括各种硬件部件,各种硬件部件的示例包括处理系统104、图示为存储器106的计算机可读存储介质、以及显示设备108。处理系统104表示通过对存储在存储器106中的指令的执行以执行操作的功能。虽然分开图示,但是这些部件的功能可以被进一步分割、组合(例如,在专用集成电路上)等。
计算设备102被进一步图示为包括多媒体文档概括模块110,多媒体文档概括模块110在这一示例中被体现为存储在存储器106中并且可由处理系统104执行的计算机可读指令。多媒体文档概括模块110表示如下功能,该功能可以处理包括诸如文本和一组图像之类的不同内容类型的多媒体文档112,以及通过提取文档中的相关文本区段和图像的相关区段来生成概括114(具有对概括114中的文本量和图像的数目/尺寸的约束)。如将在下文变得明显的,多媒体文档概括模块110使得文本和图像内容两者能够被并入在捕获相关信息的概括中,并且提供包含在概括中的信息的多样性和相关性两者。多媒体文档概括模块110可以使用允许并入针对文档的文本部分和图像部分两者的信息覆盖范围和多样性、以及利用文档的文本部分和图像部分之间的结合度的任何合适的方法实施。
虽然多媒体文档概括模块110被图示为被本地包括在计算设备102处,但是如联系图7进一步描述那样,这一功能可以被分割和/或以分布方式实施或者单独在云116上实施。
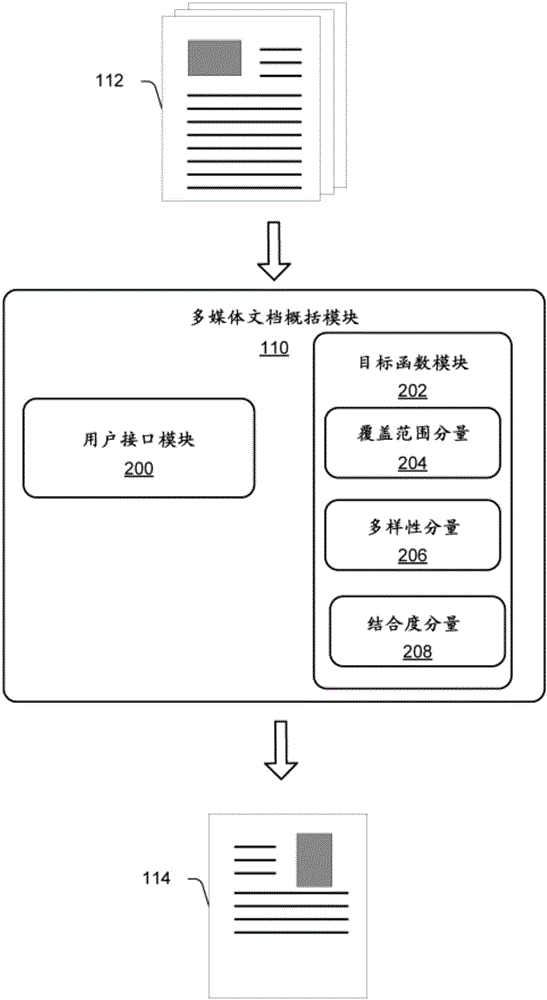
图2更详细地图示了多媒体文档概括模块110。在这一示例中,多媒体文档概括模块110包括用户接口模块200和目标函数模块202。
用户接口模块200使得用户能够与多媒体文档概括模块110交互。特别地,用户接口模块200允许用户选择一个或者多个文档用于处理和指定当处理文档时要被用作预算的概括参数(诸如一组参数)。用户可以指定诸如特定概括将具有的句子、单词、或者字符的数目之类的参数。此外,用户可以指定将被包含在概括中的图像的数目和尺寸。
目标函数模块202表示处理多媒体文档112以提供概括114的功能。在至少一些实施方式中,目标函数模块202被配置为通过采用目标函数来执行对多媒体文档的优化处理,该目标函数被设计为考虑包含在概括中的文本和图像的覆盖范围、包含在概括中的信息的多样性、以及特定概括中的文本和图像之间的结合度或相关性。因此,目标函数模块202使用包括覆盖范围分量204、多样性分量206、以及结合度分量208的目标函数。
覆盖范围分量204提供对包含在特定概括中的文本和图像的覆盖范围的测量。多样性分量206提供对包含在特定概括中的信息的多样性的测量。结合度分量208提供对包含在概括中的文本和图像之间的结合度或相关性的测量。下文描述了可以如何应用覆盖范围、多样性、以及结合度的概念的示例。
图3描绘了根据一个实施方式的用于概括多媒体文档的过程300。该过程的方面可以在硬件、固件、或者软件、或者其组合中实施。在至少一些实施方式中,该过程通过诸如关于图1和图2描述的适当配置的多媒体文档概括模块来实施。该过程被示出为一组块,一组块指定由一个或者多个设备执行的操作并且不必限于所示的由相应块执行操作的顺序。
接收多媒体文档用于处理以生成概括(块302)。这可以以任何合适的方式执行,诸如通过使用适当配置的用户接口以使得用户能够选择多媒体文档用于处理。接收与用于处理多媒体文档的预算关联的一组参数(块304)。这可以以任何合适的方式执行,在上文和下文提供了其示例。该组参数对概括的大小进行约束并且限定概括可以包含第一内容类型和第二内容类型中的多少内容类型。例如,该组参数可以指定概括将包含3个句子和1幅图像。过程接着确立用于处理多媒体文档的任何预算是否可用(块306)。例如,可以确定是否满足对概括的大小的约束。如果没有预算可用,则最终概括被视为完成(块308)。另一方面,如果用于处理多媒体文档的预算可用,则执行目标函数(其提供对概括的质量的测量)以生成概括。这可以包括以将目标函数在期望的结果方向上移动的方式将元素(例如文本和图像)添加到概括。可以如何执行这一点的示例在下文提供。过程接着返回到块306以尝试迭代地改善概括(只要预算剩余)。
在下文的讨论中,描述了两个示例方法。每个方法使用了不同的目标函数。示例方法旨在用作示例并且因此不旨在进行限制。因此,可以利用其它目标函数而不脱离所要求保护的主题的精神和范围。
已经考虑了其中可以实践各种实施方式的示例系统,现在考虑用于概括多媒体文档的第一方法。
第一方法
在下面的讨论中,提供了对第一方法的简要概括,并且更具体地,提供了对被最大化以便提供质量概括的目标函数的简要概括。该简要概括陈述了目标函数并且提供了对其项的各种定义。其后,针对关于可以如何采用目标函数的附加上下文,提供了对目标函数的更详细解释。
第一方法——简要概括
第一方法利用考虑了三个因素的目标函数:覆盖范围、多样性、以及相关性。在这一示例中,测量概括的质量的以下目标函数被最大化:
F(S,I)=f(CT(S),RT(S),CV(I),RV(I),COH(S,I))
其中
T是要概括的文档的文本内容
V是要概括的文档的图像内容
S是“当前”概括的文本部分
I是“当前”概括的图像部分
F(S,I)是其值依赖于与文本和图像部分对应的当前概括的目标函数
f(.)是其所有变量的单调非减函数
CT(S)通过S来测量文档的文本部分的覆盖范围。覆盖文档的更多文本信息的概括将获得更高的得分。
CV(I)是针对图像部分的相似的函数。其通过I来测量文档的图像部分的覆盖范围。覆盖文档的更多图像的概括将获得更高的得分。
RT(S)是测量包含在S中的多样性信息的量的多样性奖励。提供更多的多样性信息的概括将得到更高的得分。
RV(I)是针对图像部分的相似的函数。其是测量包含在I中的多样性信息的量的多样性奖励。
COH(S,I)是对S和I的元素之间的结合度(相关性)的测量。更加紧密结合的概括将得到更高的得分。
要注意的是,函数的单调性保证了当其任何变量的值增加时,函数值不减少。这意味着当五个变量中的任何变量增加时,目标函数的值增加并且因此概括的质量增加。
对于预算约束而言,在这一特定示例中使用了以下预算约束:
针对文本部分
针对图像部分
其中
·di和dk分别是针对文本元素和图像元素的决策变量。如果在概括中选择了对应的句子/图像区段,则其取值1,否则取值0。
·Ci和Ck分别是添加对应句子的成本和添加对应图像的成本。文本区段的成本可以被限定为句子的数目、或者单词的数目、或者字符的数目。图像区段的成本被设置为每区段为1。虽然图像的区段可以具有变化的尺寸,但是它们通常被设定尺寸以适配期望的图像尺寸。然而,可以针对图像区段限定更全面的成本函数。
·Bs和BI分别是与文本部分和图像部分对应的预算。注意,可以针对概括的图像部分和文本部分分开固定预算。
为了在以上约束下解决这一优化问题,所谓的迭代贪婪(greedy)方法被用于将这一目标函数最大化。
现在考虑对第一方法的更详细讨论,其提供对目标函数的进一步润色和目标函数在概括多媒体文档中的使用。
第一方法——详细讨论
在以下讨论中,以下符号将贯穿使用:
ri:将元素i包含在概括中的奖励
Inf(i;j):由元素i捕获的元素j的信息量
Infi(X):由元素i捕获的集合X的信息量。例如,这可以被限定为
S:包含概括的文本部分的所有元素的集合
I:包含概括的图像部分的所有元素的集合
这一方法在概括中并入了图像以及文本和图像区段的结合度。在这一方法中,如上文所述,测量概括的质量的目标函数F(S,I)被最大化。目标函数如下:
F(S,I)=f(CT(S),RT(S),CV(I),RV(I),COH(S,I))
其中
f(.)如上文所述是其所有变量而言的单调非减函数。作为示例,f(.)可以是具有正系数的线性组合函数,使得
F(S,I)=CT(S)+αRT(S)+βCV(I)+γRV(I),+δCOH(S,I)
其中α,β,γ,δ是正的常数。
CT(S)通过S测量文档的文本部分的覆盖范围或者保真度。覆盖文档的更多文本部分的概括将获得更高的得分。这一覆盖范围函数的示例可以为
其中T是文档的整个文本部分。对于文档中的每个文本元素i,这一函数捕获该元素关于S的信息内容,上限为依赖于文档的常数。这一上限是为了保证覆盖范围不因为在概括中存在很多相似的句子而上涨。这是子模函数,即其满足报酬递减性质。其获得的直觉是,增加S中的区段的数目增加原始文档的覆盖范围。覆盖范围的其它定义也可以在这里使用而不脱离所要求保护的主题的精神和范围。
CV(I)是针对图像部分的相似函数,并且通过I测量文档的图像部分的覆盖范围或者保真度。覆盖文档的图像部分中的更多部分的概括将获得更高的得分。作为示例,我们可以将以上定义延伸,使得
其中V是文档的整个图像部分。在这一情形下,覆盖范围函数对于文本和图像部分而言是相似的。然而,可以针对两者选择不同的函数。在过去,未就此考虑过图像部分。
RT(S)是测量包含在S中的多样性信息的量的多样性奖励。提供更多信息的概括将获得更高的得分。普通方法惩罚概括中的信息的重复。然而,在所图示和描述的实施方式中,奖励所提供的信息内容的多样性。作为示例,文档的文本部分可以被划分成集群:
其中Pi是使基集合(即,整个文档的文本部分)成为不相交集群的划分。集群可以基于项频率-反向文档频率(tf-idf)距离或者文本区段之间的任何其它距离量度来获得。平方根函数保证更加有益于从其任何元素都未被选择的集群来选择元素。这改善了最终的概括的文本部分中的信息的多样性。
RV(I)是针对图像部分的相似函数。引入这一项以便并入针对I的多样性奖励。以前的方法未将这种项包括在概括模型中。作为示例,可以将与上文相同的定义延伸到集合I以得到
其中Pi是使基集合(即,整个文档的图像部分)成为不相交集群的划分。集群可以基于图像区段之间的距离获得。作为示例,针对每个区段获得4096维的神经编码,并且获得了作为针对集群的距离量度的矢量之间的余弦距离。这改善了最终的概括的图像部分中的信息的多样性。
COH(S,I)是对S和I的元素之间的结合度的测量。以前的方法不考虑以这一方式进行的结合度测量。将这一项包括在内以便并入结合度,使得更紧密结合的概括将获得更高的得分。作为示例,我们限定
这一定义考虑了由概括中的文本区段和图像区段提供的信息内容的相似性。在由文本和图像提供的信息之间具有更高重叠的概括将获得更高的结合度值。
目标函数并入了以下这些因素:文本和图像两者对文档的覆盖范围;与概括的文本和图像关联的多样性奖励;以及概括中的S和I的元素之间的结合度。将这些因素包括在目标函数中使得能够获得对文档的更好概括。
上文描述了所利用的预算约束。预算针对概括的图像部分和文本部分分别固定。这是因为期望在概括中具有特定数目的文本区段和图像区段。如果要以考虑中的不同预算来生成概括,则还可以通过适当地修改预算约束来实现。
将文本区段和图像区段包括在内的成本可以按需要限定。作为示例,文本区段的成本可以被限定为句子的数目、或者单词的数目、或者字符的数目。图像区段的成本设置为每区段为1。
为了实施这一点,利用所谓的迭代贪婪方法将目标函数最大化。已经示出“贪婪”算法是一种好的近似解。
图4描绘了根据利用上文的目标函数的一个实施方式的用于概括多媒体文档的示例实施方式中的过程400。该过程的方面可以以硬件、固件、或者软件、或者其组合实施。在至少一些实施方式中,过程由诸如关于图1和图2描述的适当配置的多媒体文档概括模块实施。该过程被示出为一组块,该一组块指定由一个或者多个设备执行的操作并且不必限于所示的由相应块执行操作的顺序。下文的讨论假设已经接收了要经历如描述的处理的多媒体文档。
确立用于执行对多媒体文档的概括的可用预算(块402)。该预算涉及概括的文本和图像内容并且用作对概括可以包含的文本内容和图像内容的量的约束。这可以以任何合适的方式执行。例如,可以通过经由适当配置的用户接口而从用户输入的方式确立可用预算。该预算可以允许用户指定包括文本概括的长度以及图像的数目和尺寸在内的概括参数。接着,过程确立在可用预算内的文本内容或者图像内容的特定元素是否存在(块404),使得未满足对概括可以包含的文本内容和图像内容的量的约束。这可以针对概括的文本部分或者图像部分来执行。如果不存在在可用预算内的元素,则最终的概括被认为完成(块406)。另一方面,如果存在在可用预算内的特定元素,则针对多媒体文档中的每个可用元素计算目标函数的值(块408)。即,针对可用的并且可以在预算内被添加到概括的每个元素(即元素的成本不多于用于该元素类型的可用预算)的,计算目标函数的值。
接着在多媒体文档中选择元素,该元素的计算值将目标函数的增加与所选择的元素的成本的比率最大化(块410)。所选择的元素可以是图像区段或者文本区段。所选择的元素接着被添加到概括(块412)并且针对每个元素的增益被更新(块414)。接着通过将所选择的元素的成本从用于对应部分的预算中减掉,来更新预算(块416)。过程接着返回到块404并且迭代通过该过程,直到预算被用尽——即直到没有留下具有低于或者等于可用预算的成本的未使用元素。此时,最终的概括可以被认为完成。
在考虑第一方法之后,现在考虑使用基于图的方法来提供多媒体文档概括的第二方法。
第二方法
在下面的讨论中,提供了对第二方法的简要概括,并且更具体而言,提供了对目标函数(其被最小化以便提供质量概括)的简要概括。此后,针对关于可以如何采用目标函数的附加上下文,提供了对目标函数的更详细解释。
第二方法——简要概括
在第二方法中,利用了基于图的方法。特别地,创建了如下图,其节点表示文本元素或者图像元素。每个元素具有基于该元素的固有值而分配的对应奖励,而不考虑对应文档中的其它元素。在一个方法中,如在下文更详细地描述的,使用词性(POS)标签确定文本元素的奖励。每个元素还具有关联的成本。例如,文本元素的成本可以在字符、单词、或者句子的数目方面给出。每个图像区段的成本可以基于其尺寸或者作为单位成本来分配。图中的边缘权重表示由一个元素捕获的关于另一元素的信息量的概念。目标函数被限定并且测量原始文档中留下——即未被当前概括捕获——的剩余奖励。对目标函数进行数学操作以将该目标函数最小化。即,以力求将剩余奖励最小化的方法对目标函数进行操作。
在所图示和描述的实施方式中,目标函数被限定如下:
其中
m是图像区段的数目
n是文本区段的数目
S是“当前”概括的文本部分
I是“当前”概括的图像部分
ri表示将第i个文本区段包括在概括中的奖励
表示将第k个图像区段包括在概括中的奖励
di是∈{0,1}的决策变量,其告知第i个文本区段是否被包括在S中
是∈{0,1}的决策变量,其告知第k个图像区段是否被包括在I中
是∈{0,1}的决策变量,其告知第p个图像区段是否被包括在I中
dq是∈{0,1}的决策变量,其告知第k个文本区段是否被包括在S中
wij是由第i个文本区段覆盖的第j个文本区段的信息量,即基于相似性的重量(weightage)
是由第k个图像区段覆盖的第j个文本区段的信息量
是由第p个图像区段覆盖的第l个图像区段的信息量
是由第q个文本区段覆盖的第l个图像区段的信息量
以上方程的第一部分是
方程的这一部分处理剩余奖励,即与文本部分一起存在的剩余信息。如果选择了文本区段,则与该区段关联的剩余奖励应该为零。这是通过被更新到1的di因子实现的,并且当i=j时wij将为1。因此,(1-diwij)项将为零并且这一项将没有贡献。
当选择了(从信息的意义上说)相似的文本区段时,(1-diwij)项变小,因为wij高。这保证了与选择这一文本区段关联的增益是低的。这使得更多样性的一组句子能够出现在概括中。因此,显示出概括中的多样性。
当选择了(从信息的意义上说)相似的文本区段时,项增加相似图像区段的权重。因为目标函数正在被最小化,该项的权重的增加将实现挑选与文本区段高度相关的图像区段,从而显示出概括中的类(文本和图像)之间的结合度。
在图像区段的上下文中,相似的细节也适用于第二项。
现在,与第i个元素关联的增益被限定为:
预算约束与在上文的第一方法中使用的相同。
考虑到以上信息,迭代贪婪方法被用于将目标函数G最小化,因为其是对剩余奖励的测量。
考虑了第二方法的简要概括之后,现在来考虑包括说明性示例的详细讨论。
第二方法——详细讨论
如上文所述,第二方法是力求将测量留在原始文档中的剩余奖励的目标函数最小化的基于图的方法。回忆一下,目标函数被限定如下:
更详细地查看这一方程,方程的第一部分涉及与文档的文本部分关联的剩余奖励。方程的第二部分涉及与文档的图像部分关联的剩余奖励。
如果选择了文本区段,则与该区段关联的剩余奖励应该为零。这是通过被更新到1的di因子来实现的,并且当i=j时wij将为1。因此,(1-diwij)项将为零并且这一项将没有贡献。
当选择了(从信息的意义上说)相似的文本区段时,(1-diwij)项变小,因为wij高。这一因子对文本元素的奖励具有乘法作用。这保证了与选择这一文本区段关联的增益是低的。这使得更多样性的一组句子能够出现在概括中,因此显示出概括中的多样性。
当选择了(从信息的意义上说)相似的图像区段时,项大于1。这一乘法因子增加相似的文本区段的奖励。因为目标函数正在被最小化,该项的增加将实现选择与图像区段相关的该文本区段。这带来了概括中的结合度。在图像区段的上下文中,相似的细节适用于第二项。
为了实现这一点,如上文所述,迭代贪婪方法被用于将目标函数最小化。因此,如上文所述,我们首先将与第i个元素关联的增益限定为:
图5描绘了用于根据第二方法概括多媒体文档的示例实施方式中的过程500。该过程的方面可以以硬件、固件、或者软件、或者其组合来实施。在至少一些实施方式中,该过程由诸如关于图1和图2描述的适当配置的多媒体文档概括模块来实施。该过程被示出为一组块,该一组块指定由一个或者多个设备执行的操作并且不必限于所示的由相应块执行操作的顺序。下文的讨论假设,要经历如所描述那样的处理的多媒体文档已经被接收。
确立用于执行对多媒体文档的概括的可用预算(块502)。这可以以任何合适的方式执行。例如,可以通过经由适当配置的用户接口从用户输入的方式来确立可用预算。该预算可以允许用户指定包括文本概括的长度以及图像的数目和尺寸在内的概括参数。接着,该过程确立是否存在在可用预算内的元素(块504)。这可以针对概括的文本部分或者图像部分来执行。如果不存在在可用预算内的元素,则最终的概括被认为完成(块506)。另一方面,如果存在在可用预算内的元素,则针对可以添加的每个可用元素,计算元素的增益与元素的成本的比率(块508)。
接着,选择提供块508的增益和成本的最大比率的元素(图像区段或者文本区段)(块510)。所选择的元素接着被添加到概括(块512)并且用于对应的分类的剩余预算被更新(块514)。
不在概括中的相同类型的所有区段的奖励被更新,不在概括中的其它类型的所有区段的奖励也被更新(块516)。例如,在一个实施方式中,不在概括中的相同类型的所有元素的奖励按如下方式更新:
Rj=(1-wkj)Rj
相似地,不在概括中的其它类型的所有区段的奖励按如下方式更新:
Rj=(1+wkj)Rj
该过程接着通过循环回到块504进行迭代,直到预算被用尽并且最终的概括完成。
这一过程被设计为将项(原始奖励–剩余奖励)最大化,其中原始奖励是所有区段的奖励的总和,并且剩余奖励按上文限定并且力求最小化。这一基于图的方法试图保证不同类型(文本和图像)的区段之间的最大交叉结合度,同时也从整体上保证内容的多样性和信息的覆盖范围。现在考虑描述这一方法的各种实施方式方面的讨论,包括如何获得针对在这一方法中使用的各个项的值。
实施方式细节
首先考虑涉及将第i个文本区段包括在概括中的奖励的ri项。为了奖励文本区段,使用了句子的词性(POS)标签。包含言语的重要部分(诸如名词、动词、形容词、以及副词)的文本区段被给予单位值1,而忽略介词和连词。其它方法可以向不同的POS元素给予不同的值,包括负值。还可以使用奖励文本区段的其它方法,诸如基于tf-idf的那些方法。
考虑涉及将第j个图像区段包括在概括中的奖励的项。为了奖励图像元素,就区段多么不同做出确定。在一个方法中,这可以通过将4096维的神经编码分集群来实现,如在Girshick,Ross等人的“Rich feature hierarchies for accurate object detection and semantic segmentation.”Computer Vision and Pattern Recognition(CVPR),2014IEEE Conference on.IEEE,2014中描述的那样。当然可以使用其它方法。
考虑涉及由第i个文本区段覆盖的第j个文本区段的信息量的wij项。在所图示和所描述的实施方式中,使用连续矢量表示来获得对句子的语义感知表示,作为用于测量所捕获的信息量的基础。所生成的矢量表示使用递归自动编码器(RAE)的概念,如在Socher,Richard等人的“Dynamic pooling and unfolding recursive autoencoders for paraphrase detection.”Advances in Neural Information Processing Systems.2011中描述的那样。无监管RAE基于非折叠目的并且学习语法树中的短语的特征矢量。用于句子的非折叠递归自动编码器具有解析树(其中树被反向)的形状。非折叠自动编码器实质上尝试编码每个隐藏层,使得其最好地重建其整个子树直到叶节点。
解析树的根的矢量表示接着被取为使用训练矩阵生成的句子的表示矢量。这些矢量接着可以被用于计算两个句子之间的余弦相似性,以便理解两个句子在语义上多么相关。
这一相似性被用作由另一句子捕获的一个句子的信息的测量。这一测量是对称测量。还可能使用其它测量,诸如使用如技术人员将领会的单词包模型。还可能使用导向信息测量。
考虑涉及由第q个文本区段覆盖的第l个图像区段的信息量的项。为了获得这一测量,从句子和图像提取了矢量。可以利用任何合适的处理以用于提取矢量,其示例在Karpathy,Andrej,Armand Joulin和Fei Fei F.Li的“Deep fragment embeddings for bidirectional image sentence mapping.”Advances in neural information processing systems.2014中进行了描述。该处理包括首先将可能是对象的图像的部分分割成区段,并且接着运行RCNN以提取对应于这些区段中的每个区段的4096维的矢量。该网络与在Girshick,Ross等人的“Rich feature hierarchies for accurate object detection and semantic segmentation.”Computer Vision and Pattern Recognition(CVPR),2014IEEE Conference on.IEEE,2014中使用网络的相同。在操作中,使用由这一处理计算的区段,并且取任何两个区段之间的交集,使得图像的更多相关区段也作为候选出现。基于每个区段作为对象的可能性,选择这些区段中的前20个。对象被限制为每类十个对象,以避免对任何类的过度表示(例如,图像的挑选出的前20个区段中,13个可以属于“背景”类。然而,我们不想让图像区段中只有背景。因此,选择了每类十个对象的上限)。这一步骤之后,执行非最大抑制,使得输入到概括中的区段不是冗余的,而是多样性的。我们接着将“整幅图像”添加到该组区段中。
在所图示和所描述的实施方式中,句子矢量通过以下方式来构建:获得来自句子的类型依赖度,并且使用对应于句子的这些依赖度中的每个依赖度的矢量来生成针对该句子的矢量。我们接着进行以下两者:用RCNN矢量(用于图像区段)乘以一个矩阵、以及还用句子矢量乘以一个矩阵,以将它们投影到共同的矢量空间中。这些矩阵已经在图像数据集上被训练,使得对图像的描述可能接近共同空间中的图像,如在Karpathy,Andrej,Armand Joulin和Fei Fei F.Li的“Deep fragment embeddings for bidirectional image sentence mapping.”Advances in neural information processing systems.2014中描述的那样。接着计算这些矢量之间的余弦相似性。我们将这一测量定义为由文本区段捕获的图像区段的信息量,并且还用于由图像区段捕获的文本区段的信息,即我们的测量是对称的。然而,情况不需要是这样的。即,还可以使用测量的其它定义,而不脱离所要求保护的主题的精神和范围。
考虑涉及由第p个图像区段覆盖的第l个图像区段的信息量的项。这里,我们取用在之前步骤中针对图像提取的共同空间矢量,并且我们计算这些矢量之间的余弦相似性。使用共同空间投影而非直接使用RCNN矢量的原因是,4096维的矢量可以具有对应于图像的颜色、亮度、以及相关特征的额外特征;然而,我们仅关注图像中存在的语义和概念。这一测量也是对称的。还可以使用对该度量的其它定义,而不脱离所要求保护的主题的精神和范围。
在考虑了第二方法的详细讨论之后,现在考虑说明第二方法的应用的示例。
第二方法示例
为了理解这一方法,考虑一个基础示例,其中从包含3个句子和1个图像区段的文档构建出2个句子和1个图像区段的概括。在这一示例中,句子的成本被认为是单位1,并且图像区段的成本被认为是单位1。
考虑图示了具有作为节点的3个文本区段和1个图像区段的初始图的图6,并且认为由这些区段捕获的信息是对称的。文本区段由节点400、402、以及404表示,并且图像区段由节点406表示。相同元素的相似性与边缘408、410、以及412关联,并且不同类型的区段之间的相似性与边缘414、416、以及418关联。自身权重取为1。现在考虑与区段关联的奖励为:
句子1:50
句子2:35
句子3:75
图像区段1:70
此外,假设可用预算为2个句子和1个图像区段。在第一迭代中,概括中什么都不存在。因此,预算可用。与所有区段关联的增益被限定如下:
并且当针对上面的句子和图像区段计算时,产生以下值:
句子1:=1.0*50+0.9*35+0.5*75+0.7*70=168.0
句子2:=0.9*50+1.0*35+0.2*75+0.8*70=151.0
句子3:=0.5*50+0.2*35+1.0*75+0.1*70=114.0
图像区段1:=0.7*50+0.8*35+0.1*75+1.0*70=140.5
这些值与相同,因为关联的成本为1。这里,句子1将增益最大化,因此句子1被包括在概括中,并且所有句子的奖励被更新为
Rj=(1-wkj)Rj
以便产生以下值:
句子1:=(1-1)*50=0
句子2:=(1-0.9)*35=3.5
句子3:=(1-0.5)*75=37.5
由此,观察到句子2(在信息的上下文中,其与句子1非常相似)现在呈现较低的奖励。这是为了在概括中提供内容的多样性。图像区段的奖励被更新为
Rj=(1+wkj)Rj
以便产生以下值:
图像区段1:=(1+0.7)*70=119
由此,观察到图像区段1(在信息的上下文中,其与句子1非常相似)现在呈现更高的奖励。这是为了提供概括的文本部分和图像部分之间的结合度。
继续进行,注意,存在1个句子和1幅图像的可用预算。如上文描述那样,该处理从而继续以找到下一元素。特别地,针对剩余句子和图像区段的增益被计算如下:
句子2:=0.9*0+1.0*3.5+0.2*37.5+0.8*119=106.2
句子3:=0.5*0+0.2*3.5+1.0*37.5+0.1*119=50.1
图像区段1:=0.7*0+0.8*3.5+0.1*37.5+1.0*119=125.55
注意,图像区段将增益最大化。因此,图像区段被包括在概括中,并且所有句子的奖励被更新为
Rj=(1+wkj)Rj
这是因为包括了图像,并且句子是文本类型的。计算奖励产生了以下结果:
句子1:=(1+0.7)*0=0
句子2:=(1+0.8)*3.5=6.3
句子3:=(1+0.1)*37.5=41.25
我们将图像区段的奖励更新为Rj=(1-wkj)Rj以得到:
图像区段1:=(1-1)*119=0
注意,仍然有一个句子的可用预算。因此,该处理继续进行以便如之前那样找到下一元素。
句子2:=0.9*0+1.0*6.3+0.2*41.25+0.8*0=14.55
句子3:=0.5*0+0.2*6.3+1.0*41.25+0.1*0=42.51
这里,句子3将增益最大化,并且因此被包括在概括中。
所有句子的奖励都被更新为
Rj=(1-wkj)Rj
以便产生:
句子1:=(1-5)*0=0
句子2:=(1-0.2)*6.3=5.04
句子3:=(1-1)*41.25=0
图像区段的奖励被更新为
Rj=(1+wkj)Rj
以便产生:
图像区段1:=(1+0.1)*0=0
因为没有更多可用的预算,概括被输出为句子1、句子3、以及图像区段1。通过在每个步骤处将增益最大化,文档中留下的剩余奖励已经被最小化。
在考虑了上文的各种实施方式之后,现在考虑对可以实施上文描述的实施方式的示例系统和设备的讨论。
示例系统和设备
图7在700处大体上图示了示例系统,该示例系统包括表示可以实施本文中描述的各种技术的一个或者多个计算系统和/或设备的示例计算设备702。这是通过将多媒体文档概括模块110包括在内图示的。例如,计算设备702可以是服务提供商的服务器、与客户端关联的设备(例如客户端设备)、芯片上系统、和/或任何其它合适的计算设备或者计算系统。
所图示的示例计算设备702包括通信地耦合到彼此的处理系统704、一个或者多个计算机可读介质706、以及一个或者多个I/O接口708。虽然未示出,但是计算设备702可以进一步包括将各种部件耦合到彼此的系统总线或者其它数据和命令传输系统。系统总线可以包括不同的总线结构(诸如存储器总线或者存储器控制器、外围总线、通用串行总线、和/或利用了各种总线架构中的任何总线架构的处理器或者本地总线)中的任何一个或者组合。还设想各种其它示例,诸如控制和数据线路。
处理系统704表示使用硬件执行一个或者多个操作的功能。因此,处理系统704被图示为包括可以被配置为处理器、功能块等的硬件元件710。这可以包括作为专用集成电路或者使用一个或者多个半导体形成的其它逻辑设备的以硬件的实施方式。硬件元件710不受形成它们的材料或者其中采用的处理机制的限制。例如,处理器可以由半导体和/或晶体管(例如电子集成电路(IC))组成。在这种上下文中,处理器可执行指令可以是电子可执行指令。
计算机可读存储介质706被图示为包括存储器/存储设备712。存储器/存储设备712表示与一个或者多个计算机可读介质关联的存储器/存储设备容量。存储器/存储设备部件712可以包括易失性介质(诸如随机访问存储器(RAM))和/或非易失性介质(诸如只读存储器(ROM))、闪存、光盘、磁盘等)。存储器/存储设备部件712可以包括固定介质(例如RAM、ROM、固定硬盘驱动器等)以及可移除介质(例如闪存、可移动硬盘驱动器、光盘等)。如在下文进一步描述的,计算机可读介质706可以以各种其他方式配置。
输入/输出接口708表示允许用户将命令和信息输入到计算设备702的功能,以及还允许使用各种输入/输出设备将信息呈现给用户和/或其它部件或设备的功能。输入设备的示例包括键盘、光标控制设备(例如鼠标)、麦克风、扫描仪、触摸功能(例如,被配置为检测物理触摸的电容式传感器或者其它传感器)、相机(例如,其可以采用可见光波长或者诸如红外频率之类的非可见光波长将移动识别为不包含接触的手势)等。输出设备的示例包括显示设备(例如,监视器或者投影仪)、扬声器、打印机、网络卡、触觉响应设备等。因此,如在下文进一步描述的,计算设备702可以以各种方式配置以支持用户交互。
在本文中可以在软件、硬件元件、或者程序模块的一般上下文中描述各种技术。通常,这种模块包括执行特定任务或者实施特定抽象数据类型的例程、程序、对象、元件、部件、数据结构等。如本文中使用的术语“模块”、“功能”、以及“部件”通常表示软件、固件、硬件、或者其组合。本文中描述的技术的特征是不依赖于平台的,这意味着这些技术可以在具有各种处理器的各种商用计算平台上执行。
所描述的模块和技术的实施方式可以存储在某种形式的计算机可读介质上或者跨某种形式的计算机可读介质传输。计算机可读介质可以包括可以由计算设备702访问的各种介质。通过示例并且非限制性的方式,计算机可读介质可以包括“计算机可读存储介质”和“计算机可读信号介质”。
“计算机可读存储介质”可以指代相比于仅信号传输、载波、或者信号本身而言实现信息的永久性和/或非瞬态存储的介质和/或设备。因此,计算机可读存储介质指代不承载信号的介质。计算机可读存储介质包括硬件,诸如易失性和非易失性、可移除和非可移除介质和/或存储设备,它们以适合存储诸如计算机可读指令、数据结构、程序模块、逻辑元件/电路、或者其它数据之类的信息的方法或者技术来实施。计算机可读存储介质的示例可以包括但不限于RAM、ROM、EEPROM、闪存、或者其它存储器技术、CD-ROM、数字通用盘(DVD)或者其它光学存储设备、硬盘、磁盒、磁带、磁盘存储设备或者其它磁存储设备、或者其它存储设备、有形介质、或者适合存储期望的信息并且可以由计算机访问的制品。
“计算机可读信号介质”可以指代被配置为向计算设备702的硬件传输指令(诸如经由网络)的承载信号的介质。信号介质通常可以体现计算机可读指令、数据结构、程序模块、或者调制数据信号(诸如载波、数据信号、或者其它传送机制)中的其它数据。信号介质还包括任何信息递送介质。术语“调制数据信号”意指使其特性中的一个或者多个特性被设置或者改变以便编码信号中的信息的信号。通过示例并且非限制性的方式,通信介质包括:诸如有线网络或者直接有线连接之类的有线介质;和诸如声学、RF、红外、以及其它无线介质之类的无线介质。
如之前所述,硬件元件710和计算机可读介质706表示可以在一些实施方式中采用以实施本文中描述的技术的至少一些方面(诸如用于执行一个或者多个指令)的以硬件形式实施的模块、可编程设备逻辑、和/或固定设备逻辑。硬件可以包括集成电路或者芯片上系统、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、复杂可编程逻辑设备(CPLD)、以及硅或者其它硬件中的其它实施方式的部件。在这一上下文中,硬件可以作为执行由通过硬件体现的指令和/或逻辑限定的程序任务的处理设备,以及作为被利用于存储用于执行的指令的硬件(例如,之前描述的计算机可读存储介质)进行操作。
以上内容的组合也可以被用于执行本文中描述的各种技术。因此,软件、硬件、或者可执行模块可以被实施为在某种形式的计算机可读存储介质上体现的和/或由一个或者多个硬件元件710体现的一个或者多个指令和/或逻辑。计算设备702可以被配置为执行对应于软件和/或硬件模块的特定指令和/或功能。因此,可由计算设备702作为软件执行的模块的实施方式可以至少部分地在硬件中实现,例如通过使用计算机可读存储介质和/或处理系统704的硬件元件710。指令和/或功能可以由一个或者多个制品(例如,一个或者多个计算设备702和/或处理系统704)执行/操作以实施本文中描述的技术、模块、以及示例。
本文中描述的技术可以由计算设备702的各种配置支持并且不限于本文中描述的技术的特定示例。这一功能还可以全部或者部分地通过使用分布式系统(诸如如下文描述那样经由平台716在“云”714上)实施。
云714包括和/或表示用于资源718的平台716。平台716把云714的硬件(例如服务器)和软件资源的底层功能抽象出来。资源718可以包括可以在计算机处理在远离计算设备702的服务器上被执行时利用的应用和/或数据。资源718还可以包括在因特网上提供和/或通过订户网络(诸如蜂窝网络或者Wi-Fi网络)提供的服务。
平台716可以将资源和功能抽象出来以将计算设备702与其它计算设备连接。平台716还可以用于将资源的缩放抽象出来,以向经由平台716实施的资源718所遇到的需求提供对应的缩放水平。因此,在互连设备实施方式中,本文中描述的功能可以遍布系统700分布。例如,功能可以在计算设备702上以及经由将云714的功能抽象出来的平台716来部分地执行。
结论
描述了多媒体文档概括技术。即,给定包括文本和一组图像的文档,各种实施方式通过以下方式来生成概括:提取文档中的相关文本区段和图像的相关区段,其中对概括中的文本量和图像的数目/尺寸进行约束。
虽然用特定于结构特征和/或方法动作的语言描述本发明,但是要理解的是,在所附权利要求中限定的本发明不必限于所描述的特定特征或者动作。更确切地说,特定特征和动作是作为实施所要求保护的发明的示例形式公开的。
- 还没有人留言评论。精彩留言会获得点赞!