用于云计算环境的树结构操作方法和系统与流程
本发明涉及数据库
技术领域:
,特别是涉及一种用于云计算环境的树结构操作方法和系统。
背景技术:
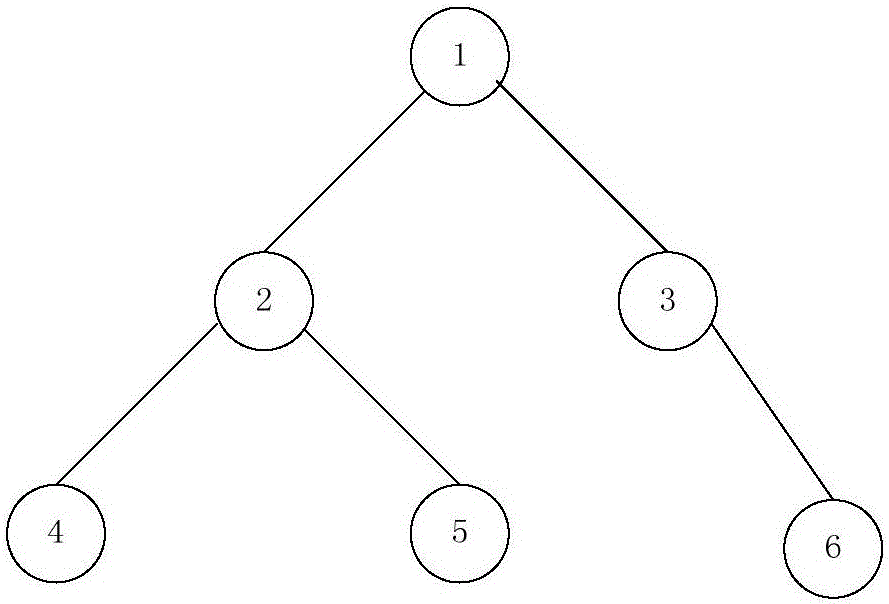
:云计算应用的不断深入和大数据处理需求的不断扩大,通过计算资源共享池提供网络化服务的云计算技术得到了普及,云计算数据中心就是云计算在存储领域的产物。在云计算数据中心,数据库应用是云计算环境中一种非常重要的应用。为了使数据层级展现更加明显,树结构展现的使用越来越多,而树结构表的数据在增删改查及统计时,经常使用递归操作。在对云计算环境下采用树状结构的节点数据操作时,由于递归操作效率低下,导致对树结构进行任何一个操作都会对其中的节点数据进行多次频繁调用,尤其是对节点数据进行层级统计时,需要进行多次递归查询,导致操作树结构中相关节点数据的效率低。技术实现要素:基于此,有必要针对传统方案操作树结构中相关节点数据效率低的技术问题,提供一种用于云计算环境的树结构操作方法和系统。一种用于云计算环境的树结构操作方法,包括如下步骤:根据树结构中各个节点的节点信息建立节点关系表;所述节点关系表包括节点标识符以及节点-父节点序列;所述节点-父节点序列记录节点、节点的父节点序列;获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列;按照更新后的节点-父节点序列更改所述树结构。一种用于云计算环境的树结构操作系统,包括:建立模块,用于根据树结构中各个节点的节点信息建立节点关系表;所述节点关系表包括节点标识符以及节点-父节点序列;所述节点-父节点序列记录节点、节点的父节点序列;获取模块,用于获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列;更新模块,用于按照更新后的节点-父节点序列更改所述树结构。上述用于云计算环境的树结构操作方法和系统,可以建立包括节点-父节点序列的节点关系表,通过其中的节点-父节点序列可以获取相应节点的层级、父节点等信息,从而利用上述节点关系表可以对相应的节点进行增加、删除、编辑以及移动等操作,从而实现对相应树结构的操作,上述针对树结构的各类操作,无需进行节点的递归查询,具有较高的操作效率。附图说明图1为一个实施例的用于云计算环境的树结构操作方法流程图;图2为一个实施例的树结构示意图;图3为一个实施例的用于云计算环境的树结构操作系统结构示意图。具体实施方式下面结合附图对本发明的用于云计算环境的树结构操作方法和系统的具体实施方式作详细描述。参考图1,图1所示为一个实施例的用于云计算环境的树结构操作方法流程图,包括如下步骤:S10,根据树结构中各个节点的节点信息建立节点关系表;所述节点关系表包括节点标识符以及节点-父节点序列;所述节点-父节点序列记录节点、节点的父节点序列;上述树结构可以如图2所示,包括6个节点,上述6个节点分为4层。树结构中的节点信息可以包括节点标识符(名称或者序号等可以唯一表示节点的标识符)、层级、节点的父节点以及节点的子节点等信息,如图2所示,节点4的节点信息包括:节点标识符为4,层级为3,父节点为2,子节点为6。图2所示树结构的节点关系表可以如表1所示,其包括节点名称(name)、节点标识符(id)、节点层级(pid)以及节点-父节点序列(node_relation)。上述节点-父节点序列包括记录节点、节点的父节点、父节点的父节点,以此类推直至最后一个父节点为树结构的根节点的序列,即记录节点以及节点的所有父节点;通常情况下,子节点记录在节点-父节点序列的后面,父节点记录在节点-父节点序列的前面。其中,各个节点通过相应的节点标识符在上述node_relation中表达,两个结点(节点与相应的父节点)之间通过符号“#”进行间隔,根节点之前,以及最后一个子节点后均可以记载符号“#”,如节点1的node_relation为#1#,节点2的node_relation为#1#2#,节点3的node_relation为#1#3#,节点4的node_relation为#1#2#4#,节点5的node_relation为#1#2#5#,节点6的node_relation为#1#3#6#等等。表1节点关系表idpidnode_relationname10#1#节点121#1#2#节点231#1#3#节点342#1#2#4#节点452#1#2#5#节点563#1#3#6#节点6S20,获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列;上述步骤中,若需要对某个节点进行操作(如删除、增加节点等),先获取上述进行操作的节点所对应的节点标识符,利用上述节点标识符在节点关系表中查找出进行操作的节点所对应的节点-父节点序列,以便对上述节点-父节点序列中的节点进行相应的操作,以实现树结构中对应节点的操作。S30,按照更新后的节点-父节点序列更改所述树结构。上述步骤中,依据操作内容对节点-父节点序列进行更新后,再根据更新后的节点-父节点序列更改树结构中的节点,使节点-父节点序列中的更新操作映射至相应的树结构,以实现对树结构的操作。本实施例提供的用于云计算环境的树结构操作方法,可以建立包括节点-父节点序列的节点关系表,通过其中的节点-父节点序列可以获取相应节点的层级、父节点等信息,从而利用上述节点关系表可以对相应的节点进行增加、删除、编辑以及移动等操作,从而实现对相应树结构的操作,上述针对树结构的各类操作,无需进行节点的递归查询,具有较高的操作效率。在一个实施例中,上述获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列的过程可以包括:获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找包括所述节点标识符的所有节点-父节点序列;根据操作的内容从查找的所有节点-父节点序列中识别待操作节点-父节点序列;针对所述待操作节点-父节点序列执行操作。本实施例中,可以先确定需要进行操作(待操作)的目标节点,获取上述待操作的目标节点对应的目标节点标识符,根据上述目标节点标识符在所述节点关系表中查找包括所述目标节点标识符的所有节点-父节点序列,获取操作的内容,根据上述操作的内容从所有节点-父节点序列中识别待操作节点-父节点序列,比如,若操作的内容为增加节点,则待增加节点的节点标识符位于最后的节点-父节点序列为待增加节点的节点-父节点序列;若操作的内容为删除节点,则包括待删除的节点标识符的所有节点-父节点序列为待删除节点对应的节点-父节点序列。识别待操作的节点-父节点序列后,针对上述待操作的节点-父节点序列进行操作内容的更新,便可以将上述待操作节点-父节点序列更新为执行操作后的目标节点-父节点序列。在一个实施例中,上述操作的内容可以为增加节点;所述获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列的过程包括:获取进行增加节点的节点标识符,根据所述节点标识符在所述节点关系表中查找包括所述节点标识符的所有节点-父节点序列;从查找的所有节点-父节点序列中识别节点标识符在设定位置的待操作节点-父节点序列;对待操作节点-父节点序列中设定位置处的节点增加一个子节点。操作内容为增加节点时,所增加的节点在目标节点后,因而,只需要获取进行增加节点的目标节点标识符在node_relatio中设定位置(最后的位置)的node_relatio。上述设定位置可以根据相应节点-父节点序列的结构进行设置,如表1所示,若node_relation中,父节点在前,子节点在后,则上设定位置可以设置为node_relation中的最后一个节点标识符位置,比如#1#3#6#中节点标识符6所在的位置。本实施例在增加节点的过程中,node_relation只需要取此节点的父节点的node_relation再加#号和此数据的id加#号,如果没有上级节点,则node_relation为#号加此数据的id再加#号。例如在节点3下增加一个节点,增加的节点id为7,则node_relation为#1#3#7#。在一个实施例中,操作的内容可以为删除节点;所述节点-父节点序列中父节点在前,子节点在后;所述获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列的过程包括:获取进行删除节点的目标节点标识符,根据所目标述节点标识符在所述节点关系表中查找包括所述目标节点标识符的所有节点-父节点序列;分别将所有操作节点-父节点序列中的目标节点标识符以及目标节点标识符之后的节点标识符进行删除。上述操作的内容为删除节点,即将目标节点标识符以及上述目标节点标识符之后的节点标识符从所有节点-父节点序列中进行删除,此时所有节点-父节点序列为待操作的节点-父节点序列。本实施例在删除节点的过程中,为保证删除此节点及此节点下的所有节点,只需要删除node_relation中包含加相应节点标识符的node_relation的所有数据,无需进行递归删除。例如删除节点2及以下所有节点时,只需执行DELETEFROMt_treeWHEREt_tree.node_relationlike'#1#2#%';(#1#2#为节点2的node_relation)sql语句就可以将节点2以下的所有节点都删除。而使用普通树结构表进行删除节点2及以下所有节点时,需要进行多次递归删除,需要对数据库进行多次操作。在一个实施例中,上述操作的内容可以为编辑节点;所述获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列的过程包括:获取进行编辑节点的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找包括所述目标节点标识符的所有节点-父节点序列;分别将所有操作节点-父节点序列中的目标节点标识符替换为设定标识符。上述设定标识符为相应编辑内容所对应的标识符,将所有操作节点-父节点序列中的目标节点标识符替换为设定标识符表明,上述所有操作节点-父节点序列中的目标节点标识已实现相应的编辑。上述编辑过程中,将所有node_relation中含有目标节点标识符的node_relation的目标节点标识符替换为编辑后的设定标识符,以对上述所有node_relation进行更新。在一个实施例中,上述操作的内容为移动节点;所述获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列的过程包括:获取进行待移动的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找包括所述目标节点标识符的所有节点-父节点序列;分别在所有节点-父节点序列中,将所述目标节点标识符移动至目标位置。上述目标位置即为移动后的位置,例如将节点3移动到节点2下,只需要执行UPDATEt_treeSETnode_relation=replace(node_relation,'#1#3#','#1#2#3#'),(#1#3#为节点3的node_relation,'#1#2#3#为节点2的node_relation加节点3的id加#号)这一sql语句就可以把节点2的所有节点统一移动到节点3下。在一个实施例中,上述用于云计算环境的树结构操作方法,还可以包括:获取各个节点-父节点序列的节点标识符个数,根据最大的节点标识符个数确定所述树结构的层级。各个节点-父节点序列对应的节点标识符个数中节点标识符个数的最大值等于树结构的层数,从而最大的节点标识符个数即为所述树结构的层级数。在一个实施例中,上述用于云计算环境的树结构操作方法,还可以包括:获取目标节点标识符对应的任一个节点-父节点序列;根据查找的节点-父节点序列确定目标节点标识符所在的层级。此处的目标节点标识符为待查询的节点标识符(待查询标识符),上述目标节点标识符所在的层级可以为相应节点-父节点序列中目标节点标识符的位置数,若目标节点标识符在相应节点-父节点序列的第2个符位置,则上述目标节点标识符的层级为2在一个实施例中,上述用于云计算环境的树结构操作方法,还可以包括:获取目标节点标识符对应的任一个节点-父节点序列;根据查找的节点-父节点序列确定目标节点标识符的所有上级节点。目标节点标识符(待查询标识符)的所有上级节点为包括目标节点标识符的任一个节点-父节点序列中,在目标节点标识符之前而所有节点标识符。作为一个实施例,在查询每个层级的所有节点时,也可以统计node_relation中#的个数,就可以知道所有数据(节点)层级,无需递归查询,具有较高的查询效率。例如查询层级为3的所有节点只需要执行:select*fromt_treewherelength(node_relation)-length(replace(node_relation,'#',”))=(3+1);sql;就可以查询出层级为3的所有节点。查询单个节点层级,点击节点-父节点序列中任意一个节点标识符,可根据node_relation直接显示出它的所有上级,无需递归查询,统计相应节点的父节点时也是如此。例如查询节点3的层级,只需要执行selectlength(node_relation)-length(replace(node_relation,'#',”))-1ASNUMfromt_treewheret_tree.id='3';sql;便可以统计此节点的父节点。查询单个节点的所有子节点,例如查询节点2下的所有节点只需执行select*fromt_treewheret_tree.node_relationlike'#1#2#%';(#1#2#为节点2的node_relation)sql;就可以查询出此节点下的所有节点。查询单个节点的所有父节点时,只需要查看此节点所对应的node_relation,就可以直观的看到此节点的所有父节点。在进行每个层级的所有节点,单个节点的所有子节点的统计时,中需要将select*改为selectcount(*);即可。表2树结构表idpidname10节点121节点231节点342节点452节点563节点6在云计算环境的实际应用中,如果采用传统的设计方法,即表2所示的普通树结构表设计方式,包括节点名称(name)、节点标识符(id)、节点层级(pid);树结构表的数据在查询及统计时需要迭代操作,而采用如表1所示树结构的节点关系表,其中数据在查询及统计时需要迭代操作不需要迭代操作。如果将表中的6条数据按照表2,可能会影响到查询效率和程序运行的速率。如何存储数据,针对上述树型数据库存储结构的设计,本发明做了如下的实验测试:(1)测试软硬件条件软件:操作系统为Windows2007,数据库为Mysql.硬件:工作站为Dell3020,CPU为3.60GHz,内存为8GB(2)测试方案设计思想在数据需要层级展现时,在表中添加node_relation字段,用#1#2#的方式展示层级关系。(3)数据库设计为了验证本文的设计方案,使用表2、表1进行实验,并在表1中添加字段node_relation.(4)测试步骤和结果插入6条数据表2SQL:insertintoc_treevalues('1','0','节点1');insertintoc_treevalues('2','1','节点2');insertintoc_treevalues('3','1','节点3');insertintoc_treevalues('4','2','节点4');insertintoc_treevalues('5','2','节点5');insertintoc_treevalues('6','3','节点6');表1SQL:insertintot_treevalues('1','0','节点1','#1#');insertintot_treevalues('2','1','节点2','#1#2#');insertintot_treevalues('3','1','节点3','#1#3#');insertintot_treevalues('4','2','节点4','#1#2#4#');insertintot_treevalues('5','2','节点5','#1#2#5#');insertintot_treevalues('6','3','节点6','#1#3#6#');1)在表2中插入6条数据:总用时约0.172s。2)在表1中插入6条数据:总用时约0.187s。实验结论:对插入效率几乎没有影响。删除1条数据表2SQL:deletefromc_treewhereid='6';表1SQL:deleteformt_treetwhereid='6'1)在表2中删除1条数据:用时约0.029s。2)在表1中删除1条数据:用时约0.026s。实验结论:对删除效率几乎没有影响。根据层级关系查询所有数据表2SQL:--查询一级select*fromc_treecwherec.pid='0';--查询二级节点为1的子节点select*fromc_treecwherec.pid='1';--查询三级节点为2的子节点select*fromc_treecwherec.pid='2';--查询四级节点为4的子节点select*fromc_treecwherec.pid='4';--查询四级节点为5的子节点select*fromc_treecwherec.pid='5';--查询三级节点为3的子节点select*fromc_treecwherec.pid='3';--查询四级节点为6的子节点select*fromc_treecwherec.pid='6';表1SQL:--一次查询出所有,并以树结构顺序展现select*fromt_treetORDERBYt.node_relation;1)从表2中根据层级关系查询一组具有层级关系的数据,总用时约0.45s。2)从表1中根据层级关系查询一组具有层级关系的数据,总用时约0.07s。实验结论:对表1的查询效率明显提升,如果节点层级更多,表2中的效率会明显降低;表1中的效率几乎未受影响。统计三级节点数据表2SQL:--查询一级select*fromc_treecwherec.pid='0';--查询二级select*fromc_treecwherec.pid='1';--统计三级级节点数据selectcount(*)fromc_treecwherec.pidin('2','3');表1SQL:--统计所有三级节点数据selectlength(node_relation)-length(replace(node_relation,'#',”))-1ASNUMfromt_treewheret_tree.id='3'1)从表2中根据层级关系查询三级节点的数据,总用时约0.45s。2)从表1中根据层级关系查询三级节点的数据,总用时约0.15s。实验结论:对表1的查询效率明显提升,如果节点层级更多,表2中的效率会明显降低。表1中的效率几乎未受影响。查询id为2所有子节点:表2SQL:--查询节点2的子节点select*fromc_treecwherec.pid='2';--查询节点4下的子节点select*fromc_treecwherec.pid='4';--查询节点5下的子节点select*fromc_treecwherec.pid='5';表1SQL:--查询节点二下面的所有子节点:select*fromt_treewheret_tree.node_relationlike'#1#2#%';1)从表2中根据层级关系查询三级节点的数据,用时约0.36s。2)从表1中根据层级关系查询三级节点的数据,用时约0.18s。实验结论:对表1的查询效率明显提升,如果节点层级更多,表2中的效率会明显降低。表1中的效率几乎未受影响。从以上实验可知,表中添加node_relation字段提高了查询效率。从结果对比发现,当在查询数据的时候按照表2需要执行三次查询语句才能找到三层节点,而查询表1只需要一条查询语句,效率提高三倍,如果表中层级关系更加复杂,按照表2设计结构做查询效率更低,但是按照表1没有任何性能影响。可以确定核心设计方案为给表中添加node_relation字段,对于树形数据的展现和统计有明显的效率提升,同时也很好的避免了递归的复杂性问题。上述用于云计算环境的树结构操作方法适用于云计算环境的树结构数据库表高效实现,只需对数据库进行一次查询,即可将数据以树形展示,同时在表中也直接记录了数据在树结构和层级中的关系。参考图3所示,上述用于云计算环境的树结构操作系统,包括:建立模块10,用于根据树结构中各个节点的节点信息建立节点关系表;所述节点关系表包括节点标识符以及节点-父节点序列;所述节点-父节点序列记录节点、节点的父节点序列;获取模块20,用于获取进行操作的目标节点标识符,根据所述目标节点标识符在所述节点关系表中查找节点-父节点序列,根据操作的内容更新所述节点-父节点序列;更新模块30,用于按照更新后的节点-父节点序列更改所述树结构。本发明提供的用于云计算环境的树结构操作系统与本发明提供的用于云计算环境的树结构操作方法一一对应,在所述用于云计算环境的树结构操作方法的实施例阐述的技术特征及其有益效果均适用于用于云计算环境的树结构操作系统的实施例中,特此声明。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1