基于模型匹配的非常规突发事件动态优先方法与流程
本发明涉及一种基于模型匹配的非常规突发事件动态优先方法,属于数据处理技术领域。
背景技术:
我国自然科学基金委员会于2008年启动实施“非常规突发事件应急管理研究”重大研究计划以来,众多的学者与科技工作者对非常规突发事件进行了研究。
非常规突发事件识别与发现是非常规突发事件研究的重要环节,学者与技术工作者通过不断研究,在非常规突发事件识别与发现方面取得不少进展。
通过众多学者与科技工作者的努力,在非常规突发事件研究方面,取得了不少的成果。在现有的研究成果中,非常规突发事件识别方法与模型方面的研究有一个共同特征,就是这些研究成果的聚焦点是算法与模型本身,如何把现有的研究成果有效应用于在线信息处理,相应的研究还有所缺失。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明把非常规突发事件的数据称为关键数据,关键数据对应关键信息,重点围绕非常规突发事件在线信息处理中的数据流的识别、数据权重、数据出现的频率以及优先级开展分析、研究,提出一种基于模型匹配的非常规突发事件动态优先方法,使用本发明提出的方法,为非常规突发事件应用于在线信息处理提供了一种可供选择的思路与方案。
技术方案:一种基于模型匹配的非常规突发事件动态优先方法,包括关键数据识别、关键信息权重计算、关键信息频率计算和关键信息优先级计算的过程。
关键数据识别过程
关键信息模型KMODEL:标识关键信息的各种关键信息规则的集合,对实时处理数据流进行匹配,通过匹配过滤出满足规则的关键信息。
KMODEL=M(KRULE)={x|x∈KRULE} (4)
实时数据流通过关键信息模型进行匹配,通过关键信息逻辑规则计算与识别,过滤出满足关键信息规则的数据集合。
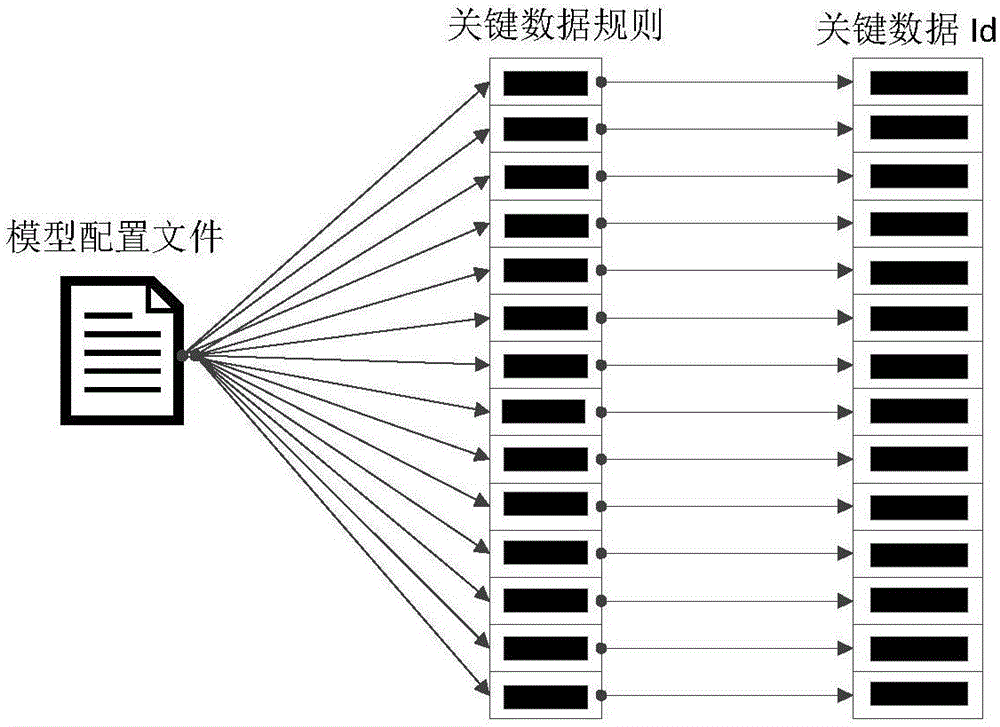
关键信息模型是一个动态模型,在不同系统中,关键信息的识别规则不一样,通过模型配置文件记录、描述关键信息规则,构建关键信息模型。
在识别关键数据前,首先对关键信息模型配置文件进行加载并进行解析,获得关键信息模型数据MS,关键信息模型数据是一个关键信息规则集合,一个关键信息规则解析结果对应一个关键信息标志。
关键信息权重
关键信息权重:不同种类的关键信息,在系统中的重要程度不一样,对不同关键信息赋予不同的数值,通过赋予数值的大小表示关键信息在系统中的重要程度。
原始数据经过关键信息模型进行匹配,识别出关键信息,关键信息被映射成具有不同权重的区间。
关键信息权重动态变化,在不同系统、不同业务中,关键信息的权重值不一样,通过关键信息权重配置文件记录、描述关键信息数据权重与关键信息的关系。
在识别关键数据前,加载权重配置文件,对权重配置文件进行解析,计算权重标志,获得权重标志集合WS,并把WS放入内存。具体实现步骤如下:
1)加载权重配置文件;
2)对权重配置文件进解析;
3)计算权重标志;
4)权重标志放入内存列表。
一种权重类型对应一个权重标志,通过不同数值(权重值)表示不同权重标志,通过不同权重值表示不同关键信息的权重类型,二者关系一一对应。
权重标志配置文件与关键信息配置文件通过关键信息规则标志进行关联。
结合MS与WS,对原始数据流、处理后的数据流进行识别,识别结果通过1、0二值表示,1表示识别数据属于关键信息,0表示识别数据是非关键信息,如果数据满足关键信息规则,则被识别的数据是关键信息,否则不是,算法如(5):
其中:
KSn是关键信息规则在识别周期开始到当前时间内,系统识别出的每类关键信息的次数的集合,DATA是被识别的数据,MS是模型数据。
关键信息频率
关键信息频率:关键信息单位时间内出现的次数。即关键信息规则在关键信息时间窗内,每类关键信息出现频率。频率公式如(6):
Pre=FFrequency(KSn,t)=KSn/t (6)
其中:
KSn是每类关键信息识别出来的次数的集合,t是关键信息规则在识别周期开始到当前时间的时间长度。
关键信息优先级
关键信息优先级:关键信息频率与权重积的算数平均值,关键信息频率与权重,决定了关键信息在系统中的重要程度。
在一个时间片段中,随着时间的变化,大量数据的持续分析,关键信息的优先级不断发生变化,通过对可视化显示的关键信息优先级进行动态调整,实时、优先显示优先级高的数据,通过对关键信息的频率与权重的乘积取平均,均值大,优先级高,优先级数据计算是一个持续的过程,优先级动态调整公式如(7):
其中:
Pre是关键信息的频率,是权重初始值,WS是权重标志。
实时分析系统中,大量数据在实时、源源不断进入系统,Pri值大的,则关键信息优先级越高,数据越关键。
附图说明
图1为关键信息规则与关键信息模型关系图;
图2为模型、关键信息规则与关键信息规则标志;
图3为关键信息到权重映射;
图4为关键信息识别内存逻辑图;
图5为频率内存关系图;
图6为关键信息优先级形成过程内存关系图;
图7为阈值法结果图;
图8为关键信息频率;
图9为关键信息优先级。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于模型匹配的非常规突发事件动态优先方法,简称模型匹配动态优先算法(PMADP),包括关键数据识别、关键信息权重计算、关键信息频率计算和关键信息优先级计算的过程。其中关键数据识别环节,现有的算法与模型可以作为数据识别规则应用于本发明方法。
关键数据识别过程
关键信息时间窗:关键信息开始计算到关键信息被处理为结束点的时间区间,这是关键信息的生命期,关键信息一旦被处理(使用关键信息识别规则来识别数据以获得各类关键信息,通过关键信息频率计算公式计算每类关键信息的频率,设计每类关键信息的权重,由关键数据权重、计算获得的频率来计算每类关键信息的优先级。)后,关键信息的标记就要复位到初始状态。
关键信息规则KRULE:标识关键信息的逻辑关系,逻辑关系包含了实时数据流中数据的计算关系、关联关系、判断准则、算法以及具有单独功能的计算模型。逻辑关系可分为:
简单逻辑关系:只有单个逻辑运算关系的逻辑关系。
DATA={data|data∈R} (1)
式(1)中,R是一种简单关系,DATA是满足某种关系R的所有数据集合,式(1)表示满足关系R的所有数据集合。
式(1)的产生式逻辑可表示为:
R—>DATA IF R THEN DATA (2)
其中:R是单一逻辑关系,DATA是满足R关系的数据。
复合逻辑关系:由多个简单逻辑运算关系通过或、并、异或等构成的复合关系。
式(3)中,R1、R2、R3、R4是一种简单关系,DATAC是满足这些关系的所有数据集合,式(3)表示所有满足关系R1、R2、R3、R4各种组合的所有数据集合。
关键信息模型KMODEL:标识关键信息的各种关键信息规则的集合,对实时处理数据流进行匹配,通过匹配过滤出满足规则的关键信息。
KMODEL={x|x∈KRULE} (4)
关键信息规则与关键信息模型是分总关系,关键信息规则与关键信息模型的关系如图1。实时数据流通过关键信息模型进行匹配,通过关键信息逻辑规则计算与识别,过滤出满足关键信息规则的数据集合。
关键信息模型是一个动态模型,在不同系统中,关键信息的识别规则不一样,通过模型配置文件记录、描述关键信息规则,构建关键信息模型。
在识别关键数据前,首先对关键信息模型配置文件进行加载并进行解析,获得关键信息模型数据MS,关键信息模型数据是一个关键信息规则集合,一个关键信息规则解析结果对应一个关键信息标志,解析逻辑如图2。
关键信息模型性质:
关键信息模型是关键信息规则集合,也就是关键信息模型由众多关键信息规则与描述这些关键信息规则关联关系的规则组成;
一个关键信息规则对应一个关键信息规则标志,模型配置文件加载后,规则与标识的一一对应被表示在计算机内存中。
关键信息权重
关键信息权重:不同种类的关键信息,在系统中的重要程度不一样,对不同关键信息赋予不同的数值,通过赋予数值的大小表示关键信息在系统中的重要程度。
原始数据经过关键信息模型进行匹配,识别出关键信息,关键信息被映射成具有不同权重的区间,如图3。
关键信息权重动态变化,在不同系统、不同业务中,关键信息的权重值不一样,通过关键信息权重配置文件记录、描述关键信息数据权重与关键信息的关系。
在识别关键数据前,加载权重配置文件,对权重配置文件进行解析,计算权重标志,获得权重标志集合WS,并把WS放入内存。具体实现步骤如下:
1)加载权重配置文件;
2)对权重配置文件进解析;
3)计算权重标志;
4)权重标志放入内存列表。
一种权重类型对应一个权重标志,通过不同数值(权重值)表示不同权重标志,通过不同权重值表示不同关键信息的权重类型,二者关系一一对应。关键信息与权重类型、权重值关系如图4。
权重标志配置文件与关键信息配置文件通过关键信息规则标志进行关联。
结合MS与WS,对原始数据流、处理后的数据流进行识别,识别结果通过1、0二值表示,1表示识别数据属于关键信息,0表示识别数据是非关键信息,如果数据满足关键信息规则,则被识别的数据是关键信息,否则不是,算法如(5):
其中:
KSn是关键信息规则在识别周期开始到当前时间内,系统识别出的每类关键信息的次数的集合,DATA是被识别的数据,MS是模型数据。关键信息识别内存逻辑见图4。
关键信息频率
关键信息频率:关键信息单位时间内出现的次数。即关键信息规则在关键信息时间窗内,每类关键信息出现频率。频率公式如(6):
Pre=KSn/t (6)
其中:
KSn是每类关键信息识别出来的次数的集合,t是关键信息规则在识别周期开始到当前时间的时间长度,频率内存关系见图5。
关键信息优先级
关键信息优先级:关键信息频率与权重积的算数平均值,关键信息频率与权重,决定了关键信息在系统中的重要程度。
在一个时间片段中,随着时间的变化,大量数据的持续分析,关键信息的优先级不断发生变化,通过对可视化显示的关键信息优先级进行动态调整,实时、优先显示优先级高的数据,通过对关键信息的频率与权重的乘积取平均,均值大,优先级高,优先级数据计算是一个持续的过程,优先级动态调整公式如(7):
其中:
Pre是关键信息的频率,是权重初始值,WS是权重标志,Prei表示第i个关键信息的频率。
实时分析系统中,大量数据在实时、源源不断进入系统,Pri值大的,则关键信息优先级越高,数据越关键,关键信息优先级形成过程内存关系见图6。
实验分析
根据国家自然科学基金重大研究计划“非常规突发事件应急管理研究”中的成果统计,我国2001至2010年特别重大的自然灾害中,森林火灾居首。阈值法是告警系统中研究、应用较多的方法之一,实验以森林火灾为参考对象对本算法与阈值法进行比较分析。
阈值法的处理逻辑如式(8)
IF R>=X THEN Doing (8)
假如R大于等于X,那么做逻辑处理。式8中,X是设置的阈值,R是原始数据或各种算法计算的结果值。
空气湿度、温度、空气中的含烃量、风力、雷电是决定森林火灾发生的重要因素。森林中的烟、火光是森林火点的直接体现。
数据构造情况说明:
空气湿度:小于61.6%时,可能发生火灾;
面积与气温系数:R=0.367,P>0.01,可能发生火灾;
空气中的含烃量:大于0.2%时,易发生火灾;
风力:小于2级时,可能发生火灾;
雷电:大于50千安时,易引发火灾;
烟:是火点;
火光:是火点。
森林面积大,且温度、湿度、风力、气体浓度、烟、火数据随时改变,这就需要传感器数量多,采集时间间隔短,因此信息量大,要对森林火灾进行有效监测,应用系统需要做到:
告警干扰少;
优先级高的信息重点、优先显示。
数据类型、权重以及阈值关系见表1。
通过模拟方式构建空气湿度、面积与气温系数、含烃量、风力、雷电、烟、火数据。期望实验数据能够在200分钟的时间维度中尽量反映一个长时间段的实际数据变化情况,因此实验数据具有较大的波动性。
图7是空气湿度、面积与气温系数、含烃量、风力、雷电、烟、火阈值法的结果。
依据公式8,使用图7的相同数据,空气湿度、面积与气温系数、含烃量、风力、雷电、烟、火的频率见图8。
依据公式9,使用图7的相同数据,空气湿度、面积与气温系数、含烃量、风力、雷电、烟、火的优先级见图9。
通过图7可以看出,使用阈值法,告警干扰多,关键信息重点不突出。
通过图8、9可以看出,使用新算法,无效告警信息减少,最关键的信息优先级最高,被优先显示与关注。
表3.1数据类型、权重以及阈值关系
- 还没有人留言评论。精彩留言会获得点赞!