一种基于上下文窗口的词语语义相似度求解方法与流程
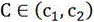
本发明涉及语义网络
技术领域:
,具体涉及一种基于上下文窗口的词语语义相似度求解方法。
背景技术:
:自从进入21世纪以来,全球的互联网行业进入了一个高速发展的新时期,各种新技术不断涌现出来。作为联系计算机与人之间重要技术的自然语言处理也取得了长足的发展。国内外对词语语义相似度的计算方法大体可以分为两类:第一,基于语义词典的词语语义相似度计算方法,这种方法简单有效、易于理解,但是它依赖于比较完备的按照概念间结构层次关系组织的大型语义词典;第二,基于语料库的词语语义相似度计算方法,这种方法利用大规模语料库,将词语的上下文信息作为语义相似度计算的参照依据。基于语料库的方法建立在两个词语语义相似当且仅当它们处于相似的上下文环境中这一假设的基础上。词语的上下文是语料库语言学中自然语言知识获取和解决自然语言处理中多种实际应用问题依靠的资源和基础,但上下文“窗口”开多大为宜,为克服当前仅凭主观经验或通过某一特定应用问题中最终结果正确率界定上下文有效范围的不足,以及实现词语语义相似度的量化计算,本发明提供了一种基于上下文窗口的词语语义相似度求解方法。技术实现要素:针对当前仅凭主观经验或通过某一特定应用问题中最终结果正确率界定上下文有效范围的不足,为实现词语语义相似度的量化计算,本发明提供了一种基于上下文窗口的词语语义相似度求解方法。为了解决上述问题,本发明是通过以下技术方案实现的:步骤1:初始化统计方法模块。步骤2:将待比较词C∈(c1,c2)输入初始化统计方法模块中。步骤3:分别确定待比较词C∈(c1,c2)的上下文词语范围“窗口”。步骤4:根据步骤3得到的上下文词范围,分别找到待比较词C∈(c1,c2)所对应的权重最大的两句子maxweight(C∈(c1,c2))。步骤5:计算这两句子maxweight(C∈(c1,c2))的相似度步骤6:由步骤5得到的两句子相似度计算待比较词(c1,c2)的相似度sim(c1,c2)。本发明有益效果是:1、对上下文语境有效范围的确定提供了非常有价值的定量化的描述,克服了前人主观描述的不足。2、上下文对关键词的描述能力相对位置由近及远逐渐递减,符合人们一般认识。4、权重贡献值weight(C,Cij∈(1,2,…2n))的线性与信噪比要更好,易于后续计算简便。5、权重贡献值weight(C,Cij∈(1,2,…2n))的归一化曲线准确率更高6、考虑了关键词左右窗口中的句子成分关系对上下文有效窗口界定的影响。7、应用基于上下文窗口技术求解词语语义相似度得以实现,计算精度、准确度都更高。附图说明表1为-j映射到weight(C,Cij∈(1,2,…2n))的离散表格。图1为一种基于上下文窗口的词语语义相似度求解方法构造流程图。图2为上下文位置权重贡献值离散图与归一化处理后的连续函数f(-j)曲线。具体实施方式针对当前仅凭主观经验或通过某一特定应用问题中最终结果正确率界定上下文有效范围的不足,为实现词语语义相似度的量化计算,结合图1对本发明进行了详细说明,其具体实施步骤如下:步骤1:初始化统计方法模块步骤2:将待比较词C∈(c1,c2)输入初始化统计方法模块中。步骤3:分别确定待比较词C∈(c1,c2)的上下文词语范围“窗口”,需先求出位置信息Jsx、上下文位置权重值weight(C,Cij∈(1,2,…2n)),其具体计算过程如下:3.1)先假设待比较词C∈(c1,c2)上下文语境的位置信息Jsx从语料中提取每个待比较词C∈(c1,c2)上下文左右各n个位置的上下文词语构成其“待比较词上下文矩阵Jsx”,其矩阵如下所示:上式矩阵行i∈(1,2,…,m),i为第i个上下文语境,列j∈(1,2,…,n)为C∈(c1,c2)上下文左边n个位置,列j∈(n+1,n+2,…,n+n)为C∈(c1,c2)上下文右边n个位置。Cij为第i个上下文语境中第j个位置词。3.2)计算每个上下文位置对待比较词C∈(c1,c2)的权重weight(C,Cij∈(1,2,…2n))上式weight(C,Cij∈(1,2,…2n))分别为第i语境中位置为j时的上下文词对关键词的权重贡献值,p(C/Cij∈(1,2,…2n)为每个上下文位置已知对应的关键词C的条件统计概率,fre(C,Cij∈(1,2,…2n))为上下文位置词与C共现的概率,T为语料或文本中所有出现词的总个数,这些都可以基于语料库很容易统计出。3.3)对待比较词C∈(c1,c2)语境中上下文词位置权重值weight(C,Cij∈(1,2,…2n))进行归一化曲线处理,其具体描述过程如下:3.3.1)先对待比较词语境中的上下文词位置j进行归一化处理以待比较词C∈(c1,c2)为原点,上下文词位置距离待比较词的相对距离如下式:上式左边位置相对距离为负值,右边位置相对距离为正值。3.3.2)利用相对误差法对误差点丢弃上述左右位置相对距离d为自变量横坐标x,根据上述步骤3得到的为对应weight(C,Cij∈(1,2,…2n))为纵坐标值,其为一离散图,连接一条包含点最多的直线——即参考直线,如下:ax+by+c=0计算不在这条直线上的点(x′,y′)到它的距离:设置误差边界条件:d>θ当满足上述边界条件则丢弃这一点(x′,y′),反之,连接成曲线。3.3.3)归一化曲线根据自变量横坐标d可得两条曲线,即f(-j)、f(j′-n)。例如:表1上下文位置(-j)-1-2-3-4-5-6-7-8-9weight(C,Cij∈(1,2,…2n))2.181.991.871.771.601.501.301.201.10其曲线如图2所示根据图2中的数据可得令x=-jf(-j)=ax3+bx2+cx+d同理可得令x′=j′-nf(j′-n)=a′(x′)3+b′(x′)2+c′x′+d′3.4)基于上下文信息损失量计算关键词语境中上下文窗口的左右窗口n值,其具体计算过程如下:上式P左为左边窗口允许的一个信息损失量的边界条件,α为用户允许的一个阈值,只有满足这个边界条件,就可以确定左边窗口的n值。同理右边窗口的确定,有下式:上式P右为右边窗口允许的一个信息损失量的边界条件,α为用户允许的一个阈值,只有满足这个边界条件,就可以确定右边窗口的n值。这里左窗口的n值大小不一定等于右边窗口大小,主要根据上两式计算可得。步骤4:根据步骤3得到的上下文词范围,分别找到待比较词C∈(c1,c2)所对应的权重最大的两句子maxweight(C∈(c1,c2)),需先知每个语境窗口下的权重值weight(C),其具体计算过程如下:4.1)每个语境窗口下的权重值weight(C)4.2)待比较词C∈(c1,c2)所对应的权重最大的两句子maxweight(C∈(c1,c2))maxweight(C∈(c1,c2))=max[weight(C)i=1,2,…,m]步骤5:计算这两句子maxweight(C∈(c1,c2))的相似度根据上下文本计算得出的maxweight(C)∈(maxweight(c1),maxweight(c2))、词性、与待比较词C∈(c1,c2)成分关系、以及在文本中所处的位置分别构成一向量,即得则两句子相似度为步骤6:由步骤5得到的两句子相似度计算待比较词(c1,c2)的相似度sim(c1,c2)上式α为一调节因子,α∈(0,1),由相应专家给定其值。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1