一种基于分层超限学习机的运动想象脑电信号分类方法与流程
本发明属于模式识别和脑-机接口(Brain-Computer Interface,BCI)领域,涉及一种应用分层超限学习机对脑-机接口系统装置中运动想象脑电信号进行分类的方法。
背景技术:
当今社会,人口老龄会问题凸显,随着科技的不断进步,人工智能在医疗方面的研究不断深入,尤其脑-机接口技术的应用和发展对疾病的诊断治疗以及康复有着深远意义。脑-机接口技术为人脑和外部设备搭建起了沟通的桥梁,在获取人脑信息的同时允许人脑支配控制外部设备。运动想象脑电信号在脑-机接口领域应用较为广泛,通过分析人脑进行想象活动时的脑电信号,识别大脑状态,进而达到控制外部设备的目的,该技术能够给神经损伤的病人提供很大的帮助。
脑-机接口技术可分为五个部分,分别是:信号提取、信号预处理、特征提取、特征分类以及接口控制。脑电信号分类识别是其中的关键技术之一,主要包括特征提取和特征分类。脑电信号因其高维度、随机性、不平稳性等复杂特性,给分类识别提出很大挑战,因此寻找有效的特征提取和分类方法是提高脑电信号识别准确率的关键。同时,脑-机接口的实际应用对设备响应的时效性提出了要求。因此,分类准确率和时间消耗都是评价脑电信号分类识别系统的重要指标。
Huang提出的基于单隐层前馈神经网络(Single-hidden Layer Feed forward Neural Network,SLFN)的超限学习机(Extreme Learning Machine,ELM)方法,其训练速度与BP神经网络以及支持向量机(SVM)相比有明显提升。在此基础上,引入基于ELM的稀疏自编码进行多层次的特征提取,并通过ELM对最后的高层特征进行分类,该结构即为分层超限学习机(Hierarchical Extreme Learning Machine,HELM)。HELM在保持ELM训练速度快的优势的基础上,将其扩展为深层结构,增加了处理复杂信号的能力,提升了分类性能。
技术实现要素:
针对上述问题,本发明采用一种基于HELM的分类方法对运动想象任务的脑电信号进行分类,提高其分类的准确率和分类速度。
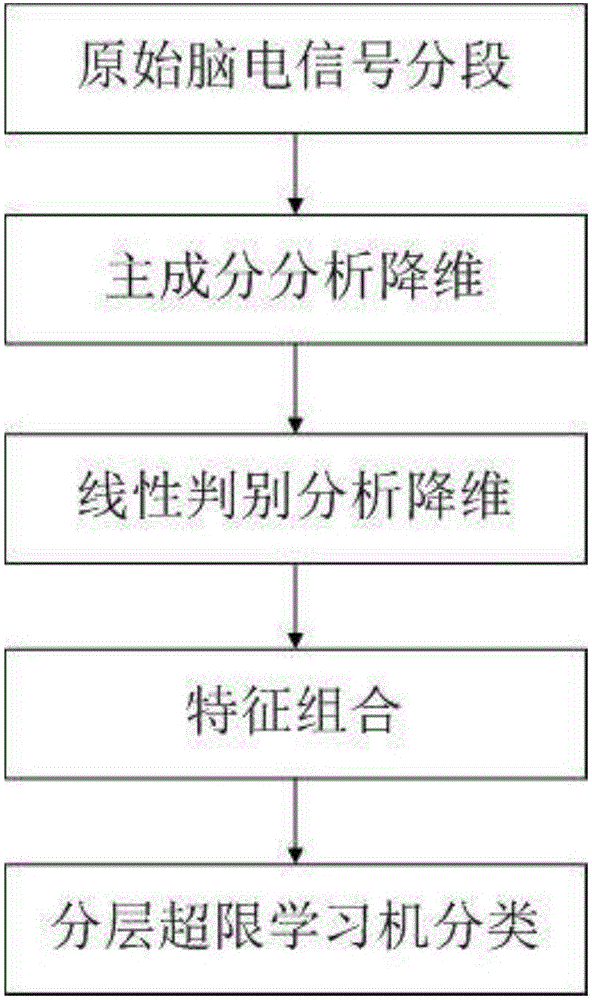
实现本发明方法的主要思路是:首先,对每一样本的原始信号进行加窗分段,得到S段子信号;然后,分别对该S段子信号进行主成分分析和线性判别分析,并将最终的S个K-1维特征向量进行组合,得到S*(K-1)维的特征;最后,将所有样本的特征送入分层超限学习机分类器中,得到最后的分类结果。
基于分层超限学习机的运动想象脑电信号分类方法,包括以下步骤:
步骤一,采用固定的滑动时间窗将原始运动想象脑电信号分为S段子信号。S的取值取决于滑动时间窗的长度与原始脑电信号的长度。
步骤二,对步骤一所得到的每一段子信号通过主成分分析(Principal Component Analysis,PCA)方法进行降维,降低信号中冗余信息,即用主成分表示特征相近的信号,最终得到降维后的特征向量。
步骤三,将步骤二中得到的特征向量通过线性判别分析(Liner Discriminate Analysis,LDA)方法进行二次降维,对于K个类别的脑电数据,得到K-1维的特征向量。对于二分类问题,得到的是一个一维的特征向量。
步骤四,对每个子信号均按步骤二和步骤三进行处理,对于S段子信号,所以最终会得到S个K-1维的特征向量,将S个K-1维的特征向量进行组合,得到最终为S*(K-1)维的特征。
步骤五,将步骤四所得到的S*(K-1)维特征送入HELM分类器,得到最终分类结果。
与现有技术相比,本发明的方法具有以下优点:
传统的ELM算法是单隐层结构,在分析复杂信号方面有很大的局限性,本发明采取HELM进行分类识别,利用基于ELM的稀疏自编码将单隐层的ELM改造成深层网络结构,通过层次化的特征提取和分类,提取深层信息,提高了分类正确率,并且保持了ELM低耗时的优势。
附图说明
图1是本发明所涉及方法的主流程图;
图2是本发明所涉及的HELM分类方法示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的说明。
假设有训练数据集TrainData和一组测试数据集TestData,TrainData的样本量为N,维度为D;TestData的样本量为M,维度同样为D。其中TrainData与TestData中样本属于K个类别的。
基于分层超限学习机的运动想象脑电信号分类方法,流程图如图1所示。
步骤一,通过固定时间窗划分的方式把TrainData和TestData均分成S段脑电子信号。TrainDatai代表训练数据集中第i段子信号,每段子信号的维度为Di(i=1,2,…,S)。TestDatai代表测试数据集中第i段子信号,每段子信号的维度为Di(i=1,2,…,S)。因为采用的固定时间窗,窗口大小是固定的,所以D1=D2=…=Di。
固定的滑动时间窗分为两种:一种是无叠加时间窗,每一段子信号之间没有重叠部分,即另一种是有叠加的时间窗,每两段相邻的子信号之间是有部分重叠的,即
步骤二,对步骤一所得到的每一段子信号TrainDatai和TestDatai通过主成分分析方法进行降维。将特征值从大到小进行排序后,再根据累计贡献率,只保留前m个最大特征值对应的特征向量组合MPCA作为投影空间向量,MPCA=[Φ1,Φ2,...,Φm],Φ1,Φ2,...,Φm分别为通过主成分分析方法进行降维后得到的最大特征值所对应的特征向量。将TrainDatai和TestDatai同时投影到MPCA上,得到PCA降维后的训练数据Traini和测试数据Testi:
Traini=TrainDatai·MPCA
Testi=TestDatai·MPCA
步骤三,将步骤二中得到的特征向量通过LDA方法进行二次降维,具体方法如下:
(1)根据LDA准则,利用Traini中不同类别样本的类间离散度矩阵以及同一类别样本的类内离散度矩阵计算出LDA的投影空间向量w*。
(2)把Traini与Testi投影到w*上,得到第i段脑电子信号的特征:
Trainfeaturei=Traini·w*
Testfeaturei=Testi·w*
步骤四,计算出所有的Trainfeaturei与Testfeaturei,并进行组合,得到最终的特征TrainFeature与TestFeature:
TrainFeature={TrainFeature1,TrainFeature2,…,Trainfeaturex}
TestFeature={TestFeature1,TestFeature2,…,TestFeaturex}
整个特征提取的流程如图1所示。
步骤五,用步骤四所得到的特征TrainFeature训练HELM分类器模型,将TestFeature送入训练好的模型进行分类,得出最终分类结果。流程图如图2所示,具体方法如下:
(1)给定隐层个数K、隐层节点个数L={L1,L2,…,LK}和激励函数g(x)。随机产生输入权值ai和偏置值bi。xi代表输入的第i个训练样本,ti对应第i个训练样本的标签,Hi是第i个隐层的输出矩阵,Ai为第i个稀疏自编码器的隐层输出矩阵。因为送入分类器是已经提取好的特征,故在本发明中,xi实际上代表TrainFeaturei。
(2)逐层计算基于ELM的稀疏自编码器的隐层权值βi,i={1,2,…,K-1,K},其中H0=X,具体计算步骤如下:
a)计算稀疏自编码器的隐层输出Ai:
Ai=g(ai·Hi-1+bi)
g(·)为选定的激励函数g(x)。
b)计算李普希茨常数Li:
Li=λmax(AiT·Ai)
λmax为最大特征值。
c)迭代计算隐层权值βi,其中迭代次数j=1:50,初始时间点t1=1,βi的特定值初始为y1=βi0,计算过程如下:
βj={‖cj‖,0}max*sign(cj)
βi=βj
d)计算隐层输出矩阵Hi:
(3)计算分类部分的隐层输出矩阵HK+1。
(4)求分类部分的最优权β:
根据神经网络的目标输出T=HK+1β。如果HK+1是列满秩的,通过最小二乘法得到最佳权值,其解为:
是HK+1的广义逆矩阵,如果HK+1是非列满秩的,则使用奇异值分解求解HK+1的广义逆矩阵来计算最优权β。
(5)将TestFeature送入该模型,逐层进行计算,得到一组M维的预测标签,将预测标签与真实标签进行比较求出分类正确率。
本实施例选择BCI2003Ia标准数据集,该数据集是两类运动想象脑电数据,分类结果的正确率最高为94.54%。本发明实施例的正确率比研究该数据的其他学者采用的方法的正确率都要高。并且同样特征的情况下,分类效果优于SVM的92.15%和ELM平均结果89.04%。与同样是深度网络结构的多层超限学习机相比,分类结果提高0.34%,耗时缩短一半左右。该发明同样适用于多分类问题,可将其先转化为两类分类,继续使用本发明所使用的方法。
- 还没有人留言评论。精彩留言会获得点赞!