一种基于深度哈希的医学图像分布式检索方法与流程
本发明涉及医学图像检索技术领域,具体涉及一种基于深度哈希的医学图像分布式检索方法。
背景技术:
目前,医学成像系统在各个医学领域都产生了越来越多的数字化图像,比如X射线图,核磁共振图,CT图等,这些图像大多数存储在数据库中。以医学图像检索为基础,高效组织和管理这些图像来提供临床诊断服务,是医学诊断的新模式。基于内容的医学图像检索主要包括两个阶段,医学图像特征提取和特征匹配。
图像灰度直方图特征提取是医学图像特征提取的常用方法,该方法用的统计量来反映图像的直方图特征的方法主要包括:
(1)均值:反映一幅医学图像的灰度平均值。
其中,H(i)是像素值为i的像素点个数。
(2)方差:方差反映的是一幅图像的灰度在数值上的离散分布情况。
(3)倾斜度:倾斜度反映的是图像直方图分布的不对称程度,歪斜度越大表示直方图分布越不对称,反之越对称。
(4)峰态:峰态反映的是灰度分布于平局值的相近度。
但是,本发明的发明人经过研究发现,现有的算法在实际应用中存在以下缺陷:(1)无法描述图像中颜色的局部分布及每种色彩所处的空间位置,导致无法描述图像中的某一具体的对象或物体;(2)视觉特征一般是对图像统计信息的描述,仅仅从某些方面描述了图像特征,远不能准确表达一幅图像;(3)特征匹配过程,是图像检索最耗时的部分,当图像库存储图像很大时,单节点服务器会遇到存储空间消耗大及检索速度慢的问题,不具有良好的扩展性。
技术实现要素:
针对现有技术中人工图像特征提取方法和单节点图像检索存在的技术问题,本发明提供一种基于深度哈希的医学图像分布式检索方法,该检索方法可以更好的让图像特征与视觉或者语义相似,从而提高检索的精确度,并通过Hadoop框架实现分布式存储和检索。
为了解决上述技术问题,本发明采用了如下的技术方案:
一种基于深度哈希的医学图像分布式检索方法,所述分布式检索方法包括深度哈希提取图像特征和基于Hadoop批量图像特征匹配并行化计算;其中,
所述深度哈希提取图像特征包括以下步骤:
S11、设计一个卷积神经网络模型,该模型包括顺序设置的第一卷积层、第一采样层、第二卷积层、第二采样层、第三卷积层、第三采样层、第一全连接层和第二全连接层;
S12、以相似或者不相似图像对作为训练输入,经过所述卷积神经网络模型对图像进行多次卷积层,下采样层,全连接层传输,得到整体代价函数如下:
其中,C是整体代价函数,N是图像对对数,yi是第i对图像是否相似,且0代表相似,1代表不相似,ai,1是第i对图像中第一个图像的输出结果,ai,2是第i对图像中第二个图像的输出结果,且a=σ(z),z=wx+b,σ为ReLU激活函数,w为权值矩阵,x为模型外部输入值即图像像素值,b为调整参数,θ为阈值;
S13、根据整体代价函数按极小化误差的方法反向传播调整权值矩阵,直到损失函数值变化量小于很小的阈值或者达到指定的迭代次数,训练则终止,具体为将式(1)看作前后两个部分seg1和seg2,权值变化量为:
因此,w的更新式子为:
其中,η为学习率,
S14、将图像库中的每个图像输入到训练好的步骤S11所设计的卷积神经网络模型中,将输出结果作为图像特征,并将输出的向量二值化作为哈希编码;
所述基于Hadoop批量图像特征匹配并行化计算包括以下步骤:
S21、将需要检索的批量图像输入到训练好的步骤S11所设计的卷积神经网络模型中,得到图像特征文件并上传到Hadoop中,Hadoop会对图像特征文件进行分块,并将分块分到不同的Mapper任务中,假设图像特征文件大小为fileSize MB,每个分块平均大小为splitSize MB,则有:
其中,Hadoop2.X的默认块大小为128MB,n表示有n个Mapper任务;
S22、每个Mapper的输入块中包含待检索图像的特征和哈希编码,首先根据哈希编码确定相似图像候选集,然后访问候选图像特征数据库,进行检索并计算与待检索图像特征向量的相似度大小,即计算两个特征向量的欧式距离;
S23、将所有Mapper的输出结果合并到一个Reducer中,对每个待检索图像的集合,按照相似度大小对检索的图像进行降序排序。
进一步,所述分布式检索方法还包括图像特征存储,所述图像特征存储包括以下步骤:在MySQL分别建哈希表和图像特征表两张表,先将图像库中的每个图像通过训练好的网络模型,将输出结果作为图像特征,并以图像名作为行关键字,图像特征作为内容存储在图像特征表中,再把图像特征二值化后的结果作为行关键字,图像名作为内容存储在哈希表中;在HBase中也分别建哈希表和图像特征表两张表,通过Sqoop将MySQL中两个表的数据导入到HBase的大表中。
进一步,所述步骤S11中设计的卷积神经网络模型中各层参数描述如下:
第一卷积层:输出数量:32,卷积核大小:11,跨步:4,权值初始化类型:xavier;
第一采样层:类型:MAX,输出数量:32,卷积核大小:3,跨步:2;
第二卷积层:输出数量:32,卷积核大小:5,跨步:1,权值初始化类型:xavier;
第二采样层:类型:AVE,输出数量:32,卷积核大小:3,跨步:2;
第三卷积层:输出数量:64,卷积核大小:5,跨步:1,权值初始化类型:xavier;
第三采样层:类型:AVE,输出数量:64,卷积核大小:3,跨步:2;
第一全连接层:输出数量:500;
第二全连接层:输出数量:10。
进一步,所述步骤S14中将输出的向量二值化具体为:若输出的向量大于0则为1,反之则为0。
与现有技术相比,本发明提供的基于深度哈希的医学图像分布式检索方法,包括深度哈希提取图像特征和基于Hadoop批量图像特征匹配并行化计算,深度哈希提取图像特征是通过卷积神经网络模型,以相似或者不相似图像对作为训练输入,利用反向传播算法计算目标函数相对多层网络权值的梯度,最终引导每张图像多个输出值近似离散的0或者1;基于Hadoop批量图像特征匹配并行化计算是将批量图像的特征文件分成多个块,块与块之间是相互独立的,这些块通过Apache Hadoop YARN(Yet Another Resource Negotiator)资源管理器,分配到不同节点上执行,最后所有Mapper执行完后的结果全部输入到一个Reducer中,这样检索结果与特征文件分块无关。因此,本发明的分布式检索方法可以减少图像表示与语义之间的鸿沟,从而提高检索精确度,同时通过并行化特征匹配加速检索过程,增强批量医学图像检索的效率。
附图说明
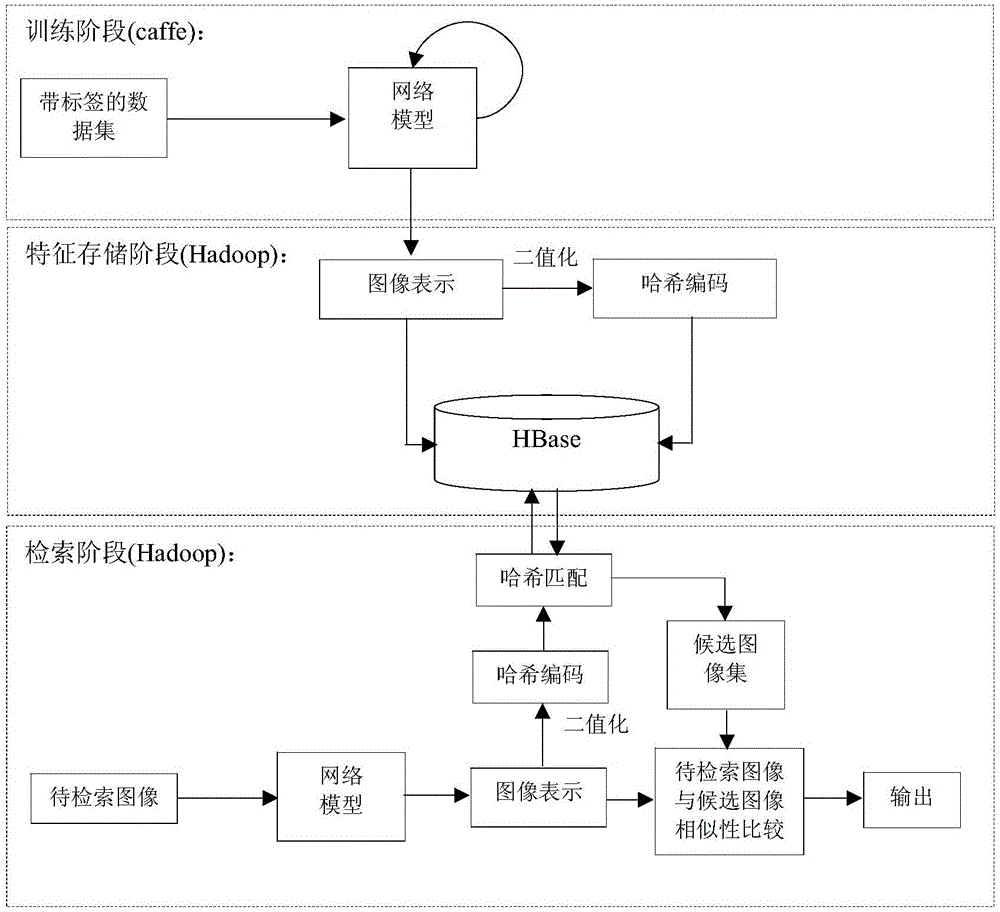
图1是本发明提供的基于深度哈希的医学图像分布式检索方法整体设计示意图。
图2是本发明提供的卷积神经网络CNN模型结构示意图。
图3是本发明提供的基于Hadoop批量图像特征匹配并行化计算方法示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明。
在本发明的描述中,需要理解的是,术语“纵向”、“径向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
请参考图1-3所示,本发明提供一种基于深度哈希的医学图像分布式检索方法,所述分布式检索方法包括深度哈希提取图像特征和基于Hadoop批量图像特征匹配并行化计算;其中,
所述深度哈希提取图像特征包括以下步骤:
S11、设计一个卷积神经网络模型(Convolutional Neural Network,简称CNN),请参考图2所示,该模型包括顺序设置的第一卷积层conv1、第一采样层pool1、第二卷积层conv2、第二采样层pool2、第三卷积层conv3、第三采样层pool3、第一全连接层ip1和第二全连接层ip2,所述卷积神经网络模型中各层参数描述如下:
第一卷积层conv1:输出数量:32,卷积核大小:11,跨步:4,权值初始化类型:xavier;
第一采样层pool1:类型:MAX,输出数量:32,卷积核大小:3,跨步:2;
第二卷积层conv2:输出数量:32,卷积核大小:5,跨步:1,权值初始化类型:xavier;
第二采样层pool2:类型:AVE,输出数量:32,卷积核大小:3,跨步:2;
第三卷积层conv3:输出数量:64,卷积核大小:5,跨步:1,权值初始化类型:xavier;
第三采样层pool3:类型:AVE,输出数量:64,卷积核大小:3,跨步:2;
第一全连接层ip1:输出数量:500,即第一全连接层ip1包含500个节点;
第二全连接层ip2:输出数量:10,即第二全连接层ip2包含10个节点;
采用如上描述的各层参数,通过卷积层和采样层来模拟人的视觉过程——人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种方法可以自动抽取图像中的特征,将高维的图像特征转化为低维的特征,最后使用全连接神经网络,这样就会达到很好的性能。
分别选取颅脑、胸、腹、脊柱及四肢1000例,每个类随机抽选80%作为训练集,剩下的20%作为测试集。
S12、以相似或者不相似图像对作为训练输入即向前传播,图像从输入层(即第一卷积层conv1)经过逐级变换,传送到输出层(即第二全连接层ip2),这个过程包括经过所述卷积神经网络模型对图像进行多次卷积层,下采样层,全连接层传输,得到整体代价函数如下:
其中,C是整体代价函数,N是图像对对数,yi是第i对图像是否相似,且0代表相似,1代表不相似,ai,1是第i对图像中第一个图像的输出结果,ai,2是第i对图像中第二个图像的输出结果,且a=σ(z),z=wx+b,σ为ReLU激活函数,w为权值矩阵,x为模型外部输入值即图像像素值,b为调整参数,θ为阈值。
S13、向后传播:每一批图像经过步骤S11所设计的卷积神经网络模型后会得到损失函数值,即根据整体代价函数按极小化误差的方法反向传播调整权值矩阵,直到损失函数值变化量小于很小的阈值或者达到指定的迭代次数,训练则终止。将式(1)看作前后两个部分seg1和seg2,权值变化量为:
因此,w的更新式子为:
其中,η为学习率,
进行参数优化,调整包括学习率、迭代次数等在内的网络参数,并对网络输出的结果进行统计,试探出比较合适的参数作为最优值。
S14、将图像库中的每个图像输入到训练好的步骤S11所设计的卷积神经网络模型中,将输出结果作为图像特征,并将输出的向量二值化作为哈希编码,所述将输出的向量二值化具体为:若输出的向量大于0则为1,反之则为0。
请参考图1所示,在MySQL建两张表,分别为哈希表和图像特征表,先将图像库中的每个图像通过训练好的网络模型,将输出结果作为图像特征,并以图像名作为行关键字,图像特征作为内容存储在图像特征表中,其具体存储形式为:<imageidi,feature>;再把图像特征二值化后的结果作为行关键字(即哈希编码),图像名作为内容存储在哈希表中,其具体存储形式为:<hashcode,imageid1imageid2...imageidk>,其中k为哈希编码长度,即第二全连接层ip2所包含的节点个数,在前述实施方式中k被设置成10;同时,在HBase中也建两张表,分别为哈希表和图像特征表,通过Sqoop将MySQL中两个表的数据导入到HBase的大表中,由此可以保证HBase中的数据能不断扩充。
请参考图3所示,所述基于Hadoop批量图像特征匹配并行化计算包括以下步骤:
S21、将需要检索的批量图像输入到训练好的步骤S11所设计的卷积神经网络模型中,得到图像特征文件并上传到Hadoop中,Hadoop会对图像特征文件进行分块,并将分块分到不同的Mapper任务中,假设图像特征文件大小为fileSize MB,每个分块平均大小为splitSize MB,则有:
其中,Hadoop2.X的默认块大小为128MB,n表示有n个Mapper任务,式(5)意味着是平均分块的,每个任务获得一个分块,因此整个集群完成搜索的总时间消耗最少;
作为一种具体实施方式,所述图像特征文件的格式为:mageid_hashcode_features,其中,imageid是图像识别唯一标识符(图像名称),hashcode是该图像的索引编号,features是该图像的特征向量。
S22、每个Mapper的输入块中包含待检索图像的特征和哈希编码,首先根据哈希编码hashcode在HBase哈希表中进行索引,得到相似图像候选集,然后访问候选图像特征数据库,进行检索并计算与待检索图像特征向量的相似度大小dist,即计算两个特征向量的欧式距离;且dist越大,表示两特征向量距离越远,即相似度越低,同理,dist越小,相似度越高;
S23、将所有Mapper的输出结果合并(combine)到一个Reducer中,对每个待检索图像的集合,按照相似度大小对检索的图像进行降序排序,即可以根据dist大小(dist越小相似度越高)对相似图像(similar imageid)进行升序排序并输出检索结果,例如可显示前20张最相似的图像。
其中,Hadoop分布式计算平台包括有最核心的分布式文件系统HDFS(Hadoop distributed file system)、MapReduce和HBase,HDFS是Hadoop使用的一个分布式的文件系统,HBase是一个分布式的NoSQL数据库,MapReduce是一种简单但功能强大的编程模型,能并行处理大型数据集。而MapReduce的操作包含两个步骤:Map阶段处理完输入数据后,输出<key,value>键值对;在Reduce阶段,收集和处理键值相同的<key,value>键值对。
与现有技术相比,本发明提供的基于深度哈希的医学图像分布式检索方法,包括深度哈希提取图像特征和基于Hadoop批量图像特征匹配并行化计算,深度哈希提取图像特征是通过卷积神经网络模型,以相似或者不相似图像对作为训练输入,利用反向传播算法计算目标函数相对多层网络权值的梯度,最终引导每张图像多个输出值近似离散的0或者1;基于Hadoop批量图像特征匹配并行化计算是将批量图像的特征文件分成多个块,块与块之间是相互独立的,这些块通过Apache Hadoop YARN(Yet Another Resource Negotiator)资源管理器,分配到不同节点上执行,最后所有Mapper执行完后的结果全部输入到一个Reducer中,这样检索结果与特征文件分块无关。因此,本发明的分布式检索方法可以减少图像表示与语义之间的鸿沟,从而提高检索精确度,同时通过并行化特征匹配加速检索过程,增强批量医学图像检索的效率。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!