一种基于深度学习的Web服务QoS预测方法与流程
本发明涉及一种Web服务QoS预测方法,特别是一种基于深度学习的服务质量预测方法。
背景技术:
面向服务系统越来越多地通过互联网访问第三方Web服务,质量保证和软件维护由第三方控制,软件本身执行和管理也取决于第三方。面向服务系统的执行能力以及服务质量越来越依赖于第三方提供的服务,然而在复杂多变的Internet环境中,这种对于第三方服务的依赖会带来不确定的问题,使得服务无法满足QoS(Quality of Service,服务质量)需求。因此,需要对服务质量进行预测,通过预测判断是否可能发生服务失效,提前采取行动消除或减轻对系统质量的负面影响,避免威胁发生。近年来,Web服务QoS预测技术受到越来越多的关注,很多模型被提出并用于运行时QoS的预测,如神经网络模型、时间序列分析等。
目前针对Web服务,主要采用机器学习、数据挖掘的方法来预测QoS值,可以归纳划分为以下几类:(1)基于相似度的QoS预测方法。(2)基于神经网络的QoS预测方法。(3)基于时间序列预测的QoS预测方法。(4)其他QoS预测方法。Web服务QoS预测虽然能够提高Web服务QoS准确度,但当候选Web服务数量较大时,对所有的Web服务进行预测将会耗费一定的时间,而用户往往要求能够尽快选出最优的Web服务,如何选出一个能够处理大批量数据的模型是另一个关键问题。因此本专利提出了深度学习预测模型,将原始QoS数据分解为多个高频序列和一个低频序列,并对分解出的序列做相空间重构和进行深度循环型神经网络训练,然后再将各个子序列训练出的预测结果进行叠加,得到最终的预测结果。该方法不仅具有稳定良好的预测精度,同时节约了运行时间,降低了成本。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种Web服务深度学习模型预测的方法,通过将小波分解和深度学习模型结合的方法,对原始的QoS数据进行预测,并给出预测模型评估标准,对响应时间、吞吐量进行预测实验。以提前发现软件的异常和一些QoS状况,为软件系统的动态自适应调整和演化等活动提供决策依据,从而保证软件系统的安全可靠运行。
技术方案:一种基于深度学习的Web服务QoS预测方法,包括以下步骤:
步骤1:QoS属性数据(响应时间、可靠性等)归一化处理。设时间序列x中的最大值和最小值分别为xmax和xmin,对于序列中所有元素xi有公式:使得新序列x’中所有元素都在[0,1]区间内。
步骤2:通过实验选取合适的分解尺度,合适的分解尺度既去掉了噪声又不会抹掉原本的数据特征,之后通过小波函数对经步骤1归一化后的QoS属性数据(响应时间、可靠性)进行单支重构。
步骤3:建立DRNN模型。
步骤4:由DRNN模型对进行过小波分解重构的数据进行预测。
步骤5:预测模型精度评估及有效性评估
精度评估:
1)、相对误差均值:其中N为预测时段中预测量的个数,yi表示第i个实际观测值,y′i为第i个预测值。MSPE反映预测值偏离实际值的程度。
2)、均方根误差:其中N为预测时段中预测量的个数,yi表示第i个实际观测值,y′i为第i个预测值。RMSE不仅反映相对误差的大小,还反映预测结果的稳定性。
3)、相对误差概率分布:其中N为预测时段中预测量的个数,为相对误差小于阈值p的预测量个数,yi表示第i个实际观测值,y′i为第i个预测值。其中误差概率分布表示预测结果的可信度。以上误差值越小,意味着模型预测越准确。
有效性评估:
引入“二进制”预测评估指标,QoS属性是否违反约束,服务是否发生失效,这个问题本身要么为肯定,要么为否定,实例要么属于肯定类,要么属于否定类,因而QoS失效预测属于二分问题。二分问题会出现四种情况,如果一个实例是肯定类且被预测为肯定类,则称为真肯定(True positive,TP),如果实例是肯定类被预测为否定类,则称为假否定(False positive,FP),如果实例是否定类被预测为否定类,则称为真否定(True negative,TN),如果实例是否定类被预测为肯定类,则称为假肯定(False negative,FN)。列联表表示为:
根据联表,引入尺度评价:
真肯定率(r)描述实际失效的样本被预测为真肯定的概率:精度(p)描述预测真肯定占肯定的比率:假肯定率(fpr)描述被预测为假肯定的实例占所有否定类的比例:正确率(a)描述正确预测的概率:F值(Fβ)描述p和r的调和均值:对于失效预测来说,p值用来评估正确自适应行为在所有自适应中的比率,p值越大,误报的可能性越低。r值用来评估正确预报失效的概率,r值越大,漏报概率越低。p和r都要高,才能取得较高的F值。因此F值越高,预测越准确。
步骤6:对比单个DRNN模型、小波—神经网络组合模型与QoS属性真实值的误差。
附图说明
图1为构建小波分析的流程图;
图2为DRNN的建模流程图;
图3为本发明的整体框架图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本实例提供的基于深度学习的Web服务QoS预测方法包含了两个主要部分:对QoS历史属性进行小波分解和单支重构,再用DRNN模型对分解出的序列进行训练,叠加得到最终的预测值。
如图1所示:小波分析模型建模步骤如下:
步骤101:QoS属性数据归一化处理。设时间序列x中的最大值和最小值分别为xmax和xmin,对于序列中所有元素xi有公式:使得新序列x’中所有元素都在[0,1]区间内。
步骤102:通过实验选择合适的分解尺度,合适的分解尺度既去掉了噪声又不会抹掉原本的数据特征,之后通过小波函数对经过步骤101归一化后的QoS属性数据值进行多尺度小波分解和单支重构,获得该时间序列的近似系数和各细节系数。
步骤103:对步骤102获取的序列的近似系数和各细节系数分别进行单支重构,获得一条能够描述原始序列趋势变化的低频序列和多条保留了不同信息的高频序列。
步骤104:设置相空间重构的延迟数值,分别对低频序列和各个高频序列进行相空间重构,以此形成相应的训练数据和测试数据。
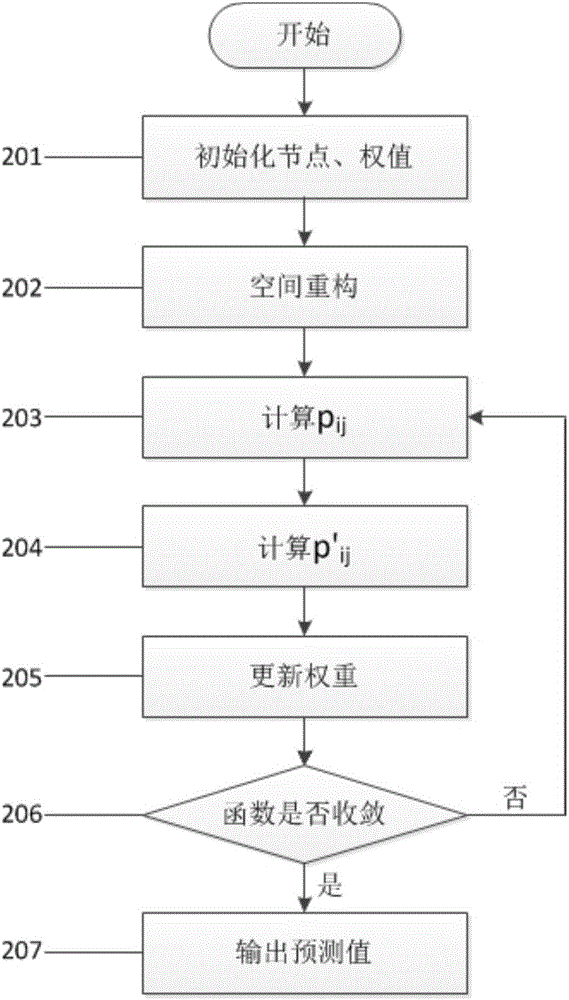
如图2所示,对于一个由两个二值型玻尔兹曼机构成的深度信任网络模型(用RBM1和RBM2表示第一层和第二层RBM)训练方法如下:
步骤201:初始化。每一层RBM的二值节点都随机赋值为0或者1,RBM层之间的均等互连的权值wij在(0,1)区间内随机赋值。同层RBM内部的节点之间互不相连。
步骤202:空间重构。对于时间序列数据x(t)重构的时间序列数据为x(t-τ),x(t-2τ),…x(t-nτ)作为RBM1的输入层节点,t=1,2,…T。τ为正整数,i=1,2,…,n,n为输入空间的维度数,也就是输入层节点的数目。当t-τ≤0时,x(t-τ)=x(t);另外t-nτ≤T。
步骤203:计算期望pij=<x(t-iτ)hj>data,即整个数据集的期望值。hj代表隐层一个节点的数值,也是特征提取的一个单元,有一定概率被设置成1,这个概率表示为:其中bj是隐层节点hj的基底,j=1,2,…m.
步骤204:计算期望p′ij=<vihj>recon,即所有隐层节点的期望,其中输入节点vi设为1的概率表示为:bi是输入层节点vi的基底,i=1,2,…n。
步骤205:通过公式Δwij=ε(pij-p′ij)(p′ij为步骤204的输出值)更新权重wij,其中ε就是学习速率。
步骤206:判断能量函数E(v,h)是否减少到收敛状态(这里用阀值α来判断能量函数的收敛情况),判断公式如下:|Q(v,h)-Q′(v,h)|<α。其中E(v,h)为能量函数,收敛判断阀值α为足够小的正数,k是迭代次数,K是表示迭代总数为常数。
步骤207:由DRNN模型对进行过小波分解重构的数据进行预测,输出的时间序列是对未来真实值x(t)的预测估计值。
预测模型精度评估及有效性评估
精度评估:
1)、相对误差均值:其中N为预测时段中预测量的个数,yi表示第i个实际观测值,y′i为第i个预测值。MSPE反映预测值偏离实际值的程度。
2)、均方根误差:其中N为预测时段中预测量的个数,yi表示第i个实际观测值,y′i为第i个预测值。RMSE不仅反映相对误差的大小,还反映预测结果的稳定性。
3)、相对误差概率分布:其中N为预测时段中预测量的个数,为相对误差小于p值的预测量个数,p为阈值,yi表示第i个实际观测值,y′i为第i个预测值。其中误差概率分布表示预测结果的可信度。以上误差值越小,意味着模型预测越准确。
有效性评估:
引入“二进制”预测评估指标,QoS属性是否违反约束,服务是否发生失效,这个问题本身要么为肯定,要么为否定,实例要么属于肯定类,要么属于否定类,因而QoS失效预测属于二分问题。二分问题会出现四种情况,如果一个实例是肯定类且被预测为肯定类,则称为真肯定(True positive,TP),如果实例是肯定类被预测为否定类,则称为假否定(False positive,FP),如果实例是否定类被预测为否定类,则称为真否定(True negative,TN),如果实例是否定类被预测为肯定类,则称为假肯定(False negative,FN)。列联表表示为:
根据联表,引入尺度评价:
真肯定率(r)描述实际失效的样本被预测为真肯定的概率:精度(p)描述预测真肯定占肯定的比率:假肯定率(fpr)描述被预测为假肯定的实例占所有否定类的比例:正确率(a)描述正确预测的概率:F值(Fβ)描述p和r的调和均值:对于失效预测来说,p值用来评估正确自适应行为在所有自适应中的比率,p值越大,误报的可能性越低。r值用来评估正确预报失效的概率,r值越大,漏报概率越低。p和r都要高,才能取得较高的F值。因此F值越高,预测越准确。
步骤6:对比BP神经网络模型、组合模型与QoS数据真实值的误差。
- 还没有人留言评论。精彩留言会获得点赞!