基于作者的文本分类和转换的制作方法
背景技术:
本说明书描述了与基于对来自特定作者训练文本的分析来转换及分类文本有关的技术。
文本编写应用(例如,文字处理器、电子邮件客户端、web浏览器以及其它的应用)经由键盘或其它输入设备来接收来自用户的文本输入。在某些情形中,这些应用可以允许用户对文本进行格式化和布置。一些应用对输入文本进行分析以识别出通常的错误。例如,拼写错误、语法错误或者格式错误。
技术实现要素:
本说明书描述了与用请求的语言风格来重写文本有关的技术。通常,本说明书中所描述主题的一个创新方面可以体现在一种方法中,所述方法包括以下动作:接收输入文本,所述输入文本包括一个或多个词和请求作者的名称;基于编码器语言模型,生成表示所述输入文本的向量流,其中所述向量流包括一个或多个多维向量,每个所述多维向量与输入文本中的词中的一个或多个关联词相关联,并且表示上下文分布,其中关联词出现在由所述编码器语言模型所处理的多个训练文本中;以及至少部分基于解码器语言模型、所生成的向量流、以及请求作者,来产生表示所述输入文本的特定转换的输出文本,其中所述解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,所述多个训练文本使得所述编码器语言模型产生表示所述词的特定向量。
本说明书中所描述主题的另一个创新方面可以被体现在一种方法中,所述方法包括以下操作:接收输入文本,所述输入文本包括一个或多个词和请求作者的名称;基于编码器语言模型,生成表示所述输入文本的向量流,其中所述向量流包括一个或多个多维向量,每个所述多维向量与输入文本中的词中的一个或多个关联词相关联,并且表示上下文分布,其中所述关联词出现在由所述编码器语言模型所处理的多个训练文本中;以及基于解码器语言模型、所生成的向量流、输入文本和作者,来产生输入文本的分类,其中所述解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,所述多个训练文本使得所述编码器语言模型产生表示所述词的特定向量。
为了实现下述的好处中的一个或多个,可以在特定实施例中实现本说明书中所描述的主题。通过允许用户将输入文本转换成特定作者的风格,输入文本可以被改变成使用针对与目标作者相关联的特定写作风格所通用的词和短语,这样使得文本更可能被期望那种写作风格的读者所理解。进一步地,输入文本可以被转换成读者期望的针对文本的写作风格,这样,更可能使文本被读者很好地接收。例如,基于之前由预定接收者所发送的电子邮件消息,可以将输入文本转换成包括所述输入文本的电子邮件预定接收者所使用的风格。而且,通过将输入文本转换成所期望的作者的风格,输入文本的作者可以改善输入文本的质量,例如,在输入文本作者不是以输入文本的语言为母语的人的情况下。
在附图和以下描述中阐述了本说明书主题的一个或多个实施例的细节。通过描述、附图和权利要求,本主题的其它特征、方面和优势将是显而易见的。
附图说明
图1示出了用于使用利用来自不同作者的文本所训练的语言模型对文本进行转换和分类的示例系统。
图2示出了用于训练编码器语言模型和解码器语言模型的示例系统。
图3示出了用于将输入文本转换成根据特定作者的风格重写的输出文本的示例系统。
图4示出了用于产生输入文本分类的示例系统。
图5是用于将输入文本转换成根据特定作者风格重写的输出文本的示例过程的流程图。
图6是用于产生输入文本分类的示例过程的流程图。
各种附图中的相同的参考数字和标识表示相同的元件。
详细说明
本说明书描述了使用利用来自不同作者的文本所训练的语言模型对文本进行转换和分类的技术。例如,可以将由用户所提供的输入文本转换成用户所请求的以特定作者风格写作的输出文本。可以使用语言模型来执行该转换,该语言模型先前对特定作者写作的文本进行分析,并对作者在那些文本上下文中所使用的词进行建模。通过这个信息,语言模型可以预测特定作者在输入文本的上下文中最可能使用的词,并产生反映这些预测的输出文本。因此,输出文本是将输入文本向特定作者语言风格的转换。例如,给定输入文本“whatisthatlightinthewindow(窗户中的那道光是什么)”,且请求作者是“威廉·莎士比亚”,那么,基于通过对他的作品的分析所生成的语言模型,可以将该输入文本转换成表示威廉·莎士比亚最可能写作该输入文本的输出文本。在这样的情形中,例如,输入文本“窗户中的那道光是什么”可以被转换成“whatlightthroughyonderwindowbreaks(远处窗户亮起的是什么光)”。
在另一个示例中,可以执行相反的转换(如,从“whatlightthroughyonderwindowbreaks”转换成“whatisthatlightinthewindow”)。通过使用威廉·莎士比亚文本为输入文本(将莎士比亚识别为该输入文本的作者),并通过指定请求转换的人作为请求作者,就可以执行这样的转换。基于先前所分析和建模的由该用户写作的文本(如电子邮件、文章等),可以将文本转换成此人请求转换的风格。
还可以使用这些技术执行其它的转换。例如,用户可以请求将输入文本转换成特定作者组所通用的风格,例如,基于由特定公司的职员所产生的文本、在特定领域写作的作者的文本、由作者发表在特定杂志中的文本或者由其他组产生的文本。
一种用于转换输入文本的示例方法包括:接收输入文本,所述输入文本包括一个或多个词和请求作者的名称。基于编码器语言模型,产生表示所述输入文本的向量流。所述向量流包括一个或多个多维向量,每个所述多维向量与输入文本中的词中的一个或多个关联词相关联,并且表示上下文分布,其中关联词出现在由所述编码器语言模型所处理的多个训练文本中。至少部分基于解码器语言模型、所产生的向量流、以及请求的作者,来产生表示所述输入文本的特定转换的输出文本。所述解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,所述多个训练文本使得所述编码器语言模型产生表示所述词的特定向量。
使用本技术,还可以使用利用来自不同作者的文本所训练的语言模型,来对输入文本进行分类。例如,特定用户的输入文本可以被分类成“讽刺作品”或者“非讽刺作品”。在另一个示例中,可根据写作输入文本最有可能的作者来对输入文本进行分类。
用于对输入文本进行分类的一种示例方法包括:接收输入文本,所述输入文本包括一个或多个词和请求作者的名称。基于编码器语言模型,生成表示所述输入文本的向量流。所述向量流包括一个或多个多维向量,每个所述多维向量与输入文本中的词中的一个或多个关联词相关联,并且表示上下文分布,其中所述关联词出现在由所述编码器语言模型所处理的多个训练文本中。基于解码器语言模型、所生成的所述向量流、输入文本和作者,来产生输入文本的分类。所述解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,其使得所述编码器语言模型产生表示所述词的特定向量。
图1示出了用于使用利用来自不同作者的文本所训练的语言模型对文本进行转换和分类的示例系统100。系统100包括用户设备108,其通过网络112被连接至文本处理系统114。在操作中,用户设备108通过网络112向文本处理系统114发送输入文本130和请求作者132的名称。文本处理系统114中的文本处理引擎150,使用编码器语言模型162以及一个或多个解码器语言模型164,将输入文本130转换成输出文本134。在某些情况下,文本处理引擎150可以使用编码器语言模型162和解码器语言模型164,对输入文本130进行分类。编码器语言模型162和解码器语言模型164可以由文本处理系统114中的语言建模引擎170所生成。语言建模引擎170对文本源180进行分析,以生成编码器语言模型162和解码器语言模型164。下面将更加详细地描述这些过程。
系统100包括用户设备108,用户102使用该用户设备108来访问文本处理系统114。该用户设备108可以是被配置为接收来自用户102的文本输入计算设备,包括例如,桌面型计算机、膝上型计算机、电话、平板计算机、或者其它类型的计算设备。该用户设备108可以包括允许用户录入输入文本的一个或多个输入设备,包括但不限于,键盘、触摸屏、话音辨识系统、鼠标或者其它的输入设备。该用户设备108通常还包括存储器104和处理器108,所述存储器104例如随机存取存储器(ram)、闪存、或者其它用于存储指令和数据的存储设备,处理器108用于执行所存储的指令。
用户设备108还包括处理器110。虽然图1只图示了单一的处理器110,但是在系统100的特定实施方式中可以包括两个或者更多的处理器。处理器110可以是中央处理单元(cpu)、专用集成电路(asic)、现场可编程门阵列(fpga)或者另一个合适的组件。处理器110还可以是包括多个集成处理器内核的较大型处理器中的单个处理器内核。
例如,用户设备108还可以包括文本处理应用116,其被配置为通过诸如键盘的文本输入设备,或者通过对文本文档或其它文本资源的识别,来接收来自用户112的输入文本。在某些情形中,文本处理应用116可以是由处理器110执行并被存储在存储器104中软件应用,例如,文字处理器、电子邮件客户端、web浏览器、呈现应用、图形应用、或者允许用户输入或识别文本的其它类型的应用。
文本处理应用116可以允许用户选择所请求的用于转换该输入文本的语言风格。例如,文本处理应用116可以向用户呈现可用作者列表,并允许用户从该列表中选择所请求的作者。在一些情形中,列表可允许用户选择包括多个作者的作者组。
用户设备108通过数据通信网络112被连接至文本处理系统114。网络112可以是被配置为在所连接的设备之间电子地发送信息的公共的或者私人的网络。网络112可以使用一个或者多个通信协议用于发送信息,例如,以太网、互联网协议(ip)、传输控制协议(tcp)、用户数据报协议、同步光纤网、蜂窝数据协议(诸如cdma和lte)、802.11x无线协议或者其它的协议。在某些情形中,网络112可以包括局域网(lan)或者广域网(wan),例如互联网,或者网络的组合,上述中的任意都包括无线链路。
用户设备108通过网络112将输入文本130和请求作者132的名称发送至文本处理系统114。在某些情形中,文本处理应用114还可以允许用户指定整体文本中的特定部分作为输入文本130,例如,允许用户使用输入设备选择该输入文本130。当然,用户也可以直接录入输入文本130。
文本处理系统114可以包括被连接至网络112并且可操作以执行下面描述的操作的服务器或者服务器集。文本处理系统114可以包括用于执行这些操作的一个或多个处理器以及一个或多个存储器。
文本处理引擎150接收输入文本130和请求作者132的名称,并将输入文本130转换成输出文本134,该输出文本134是使用所请求的语言风格写作的。在某些情形中,文本处理引擎150可以基于语言模型162和164对输入文本130进行分类。文本处理引擎150基于编码器语言模型162和解码器语言模型164,对输入文本130进行转换。在一些实施方式中,文本处理引擎150可以是可通过文本处理系统140执行这些操作来执行的软件程序或者软件程序集。在一些情形中,文本处理引擎150可以从用户接收表示转换类型或分类类型的指示,以在输入文本130上执行,并且可以选择合适的解码器语言模型164来执行所请求的转换或分类。例如,用户可以请求,输入文本130应当被重新写成所请求作者的风格。在某些情形中,可以配置并训练每个解码器语言模型164,以执行不同类型的转换或分类。
编码器语言模型162呈现上下文分布,其中词或者词组(例如短语),出现于文本源180中,文本源180由编码器语言模型162所处理。在某些情形中,编码器语言模型162包括使用文本源180所训练的人工神经网络模型。人工神经网络模型可以将输入文本中出现的词或者短语建模成高维空间中的点。例如,人工神经网络模型可以使用word2evc库(可从网页获取https://code.google.com/p/word2evc/)来呈现文本源180中的词的上下文分布。人工神经网络模型还可以使用其它的技术,例如,词袋模型(bow)、递归神经网络(rnn)模型、长短期记忆(lstm)模型、或者其它技术或技术组合。例如,还可以对这些技术做出改变,包括更长时间跨度均值和明确的提醒机制。人工神经网络模型可以将文本作为输入,并产生输出向量,输出向量将输入文本中的每个词或短语中的每个映射成高维空间中的一个点。在训练期间,可以将来自文本源180的文本作为输入传递给编码器语言模型162。在运行时(即,在训练之后),输入文本130可以作为输入被传递,以获得输入文本130的向量流表示。
在训练期间,可以将编码器语言模型162所产生的向量流作为输入,连同对应文本源180的作者及文本本身一起,传送至一个或多个解码器语言模型164。可以配置解码器语言模型164,以针对给定的向量流、作者以及输入文本组合,来产生特定的输出文本或分类。例如,可配置并训练特定的解码器语言模型164,以产生输出文本,所述输出文本将输入文本转换成了请求作者的特定风格。在此情形中,解码器语言模型164可以表示文本源180中特定作者所使用的词分布,编码器语言模型162将该词分布映射至特定的词向量。给定特定的向量,该解码器语言模型164可以产生请求作者最可能使用的词或者短语。
运行时,解码器语言模型162处理输入文本130,以产生表示输入文本130的向量流。将向量流和请求作者132传递给解码器语言模型164。解码器语言模型检查向量流和请求作者132的名称,并且根据其被配置和训练以执行的任务,来产生合适的转换(例如,输出文本)或者合适的分类(例如,讽刺作品/非讽刺作品)。
虽然图1示出了用户设备通过网络112与文本处理系统114进行交互,但是在某些实施方式中,可以将文本处理系统114的某些或全部组件集成到用户设备108中,并且可以省略网络112。在某些情形中,文本处理系统114可以是分布式计算环境,该分布式计算环境包括通过网络相连的多个计算设备。在这样的情形中,编码器语言模型162和解码器语言模型所执行的分析至少可以部分地跨多个计算设备并行地被执行。
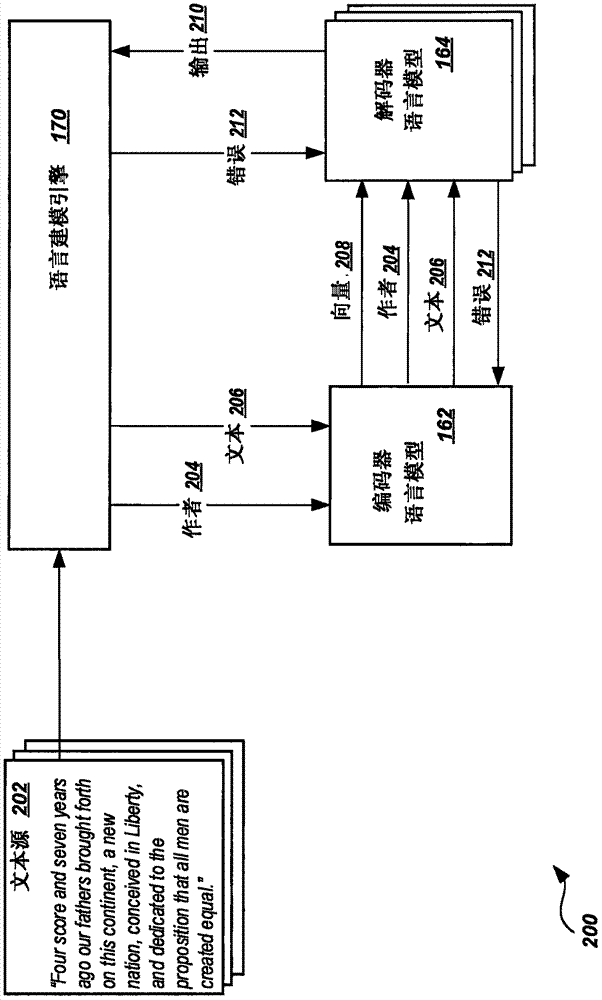
图2示出了用于训练编码器语言模型162和解码器语言模型164的示例系统200。语言建模引擎170将来自文本源202的输入文本206呈现给编码器语言模型162,所述编码器语言模型162产生表示输入文本206的向量流208。语言建模引擎170还将与输入文本206相关联的作者204呈现给编码器语言模型162。
编码器语言模型162将表示输入文本206的向量流208、作者204以及输入文本206呈现给每个解码器语言模型164。在某些情形中,语言建模引擎170直接将作者204呈现给解码器语言模型164,而在另一些情形中,是由编码器语言模型162将作者204传递给解码器语言模型164。基于上述的作者204和向量流208,每个解码器语言模型164产生一个输出210,所述输出210表示输入文本206的转换或者分类。
语言建模引擎170接收来自每个解码器语言模型164的输出210,并针对错误对它们进行分析。例如,语言建模引擎170可以针对给定输入文本206的期望输出,来对输出210进行比较。如果输入210有区别,则语言建模引擎170向产生输入210的解码器语言模型164指示错误212。响应于错误212,解码器语言模型164于是更新向量流208中的向量表示。解码器语言模型164也可以将错误212传回给编码器语言模型162,作为响应,所述编码器语言模型162来校正其表示。
文本源202可以是文档,其被选择为表示特定的作者。例如,图2中所示出的文本源202包括来自葛底斯堡演说的文本,可以表示作者“亚伯拉罕·林肯”的风格。可以通过分析大量的文本源202,来改善编码器语言模型162和解码器语言模型164的准确度。在一些实施例中,文本源202可以包括网页、书籍或期刊的扫描文本、ascii或unicode文本文件、可移植文档格式(pdf)文件、特定个人或特定人群发送或接收的电子邮件信息(表示特定人群的电子邮件风格)、或者其它类型的文本。在某些情形中,可以分析未知作者的文本源202。要对这样的文本源进行分析,可以将未知作者的所有文本源202与匿名作者相关联。这样做有助于形成英语语言中的通用词用法表示,而不是针对特定的单个作者。
图3示出了示例系统300,所述示例系统300将输入文本302转换成根据特定作者304的风格重写的输出文本306。正如图2所示,在训练编码器语言模型162和解码器语言模型164之后,通常才出现所描述的交互。系统300包括作者转换解码器310,它是解码器语言模型164中的其中一个,且被配置为执行从输入文本302到特定作者的风格的转换。
编码器语言模型162与输入文本302一起被呈现。在所图示的示例中,输入文本302是“87年前”。编码器语言模型162分析输入文本302,并产生表示输入文本302的向量流308。编码器语言模型162将向量流308和输入文本302一起呈现给作者转换解码器310。作者转换解码器还将作者304作为输入,在示例中为“亚伯拉罕·林肯”。在某些情形中,编码器语言模型162将作者304接收为输入,并将其传递给作者转换解码器310。转换解码器310产生输出文本312,所述输出文本312表示以请求作者304的风格重写的输入文本302。在所示出的示例中,输入文本“87yearsago(87年前)”已经被转换成输出文本“fourscoreandsevenyearsago(四个二十又七年前)”,这种输入文本的表示更像亚伯拉罕·林肯所写。
图4示出了示例系统400,用于产生输入文本402的分类406。例如,正如图2所示出,通常在训练编码器语言模型162和解码器语言模型164之后,发生所描述的交互。系统400包括分类解码器410,它是解码器语言模型164中的其中一个,其被配置为将输入文本分类成讽刺作品或者非讽刺作品。
编码器语言模型162与输入文本402一起被呈现。编码器语言模型162分析输入文本402,并产生表示输入文本402的向量流408。编码器语言模型162将向量流408和输入文本402一起呈现给分类解码器410。分类解码器410也将作者404视为输入。在某些情形中,编码器语言模型162将作者404接收为输入,并将其传递给分类解码器410。分类解码器410基于向量流408、输入402以及作者404,针对输入文本402产生分类406。例如,输入文本402可以是成为新故事的文本,并且分类406可以是新故事是合法新闻还是讽刺作品的指示。
图5是示例过程500的流程图,过程用于将输入文本转换成根据特定作者重写的输出文本。包括一个或多个词的输入文本以及请求作者的名称被接收(502)。使用编码器语言模型生成表示输入文本的向量流(504)。在某些情形中,向量流包括一个或多个多维的向量并且表示上下文分布,每个所述向量与输入文本的词相关联,,所述上下文分布中多个训练文本中出现的相关联的词由编码器语言模型来处理。
至少部分基于解码器语言模型、所生成的向量流、以及请求作者的名称,来产生表示输入文本特定转换的输出文本(506)。在某些情形中,解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,所述多个训练文本使得编码器语言模型产生表示词的特定向量。在一些实施方式中,输入文本的特定转换是将输入文本向用请求作者风格写成的文本的转换。在某些情形中,还可以接收输入文本的原始作者,并且部分基于原始作者,来执行产生输出文本。编码器语言模型和解码器语言模型可以是神经网络模型。
过程500还可以包括使用至少多个训练文本对编码器语言模型进行训练以及使用至少一个由编码器语言模型所生成的表示多个训练文本的向量流、多个训练文本、以及与每个训练文本相关联的特定作者,来训练解码器语言模型。特定作者可以包括相关联的训练文本的一个或多个共同作者。在某些情形中,特定作者可以是与训练文本相关联的匿名作者,所述作者是未知的。在某些情形中,请求作者可包括多个训练文本的特定作者中的一个或多个作者。
图6是示例过程600的流程图,过程用于产生输入文本的分类。接收包括一个或多个词的输入文本以及识别请求作者的数据(602)。基于编码器语言模型,生成表示输入文本的向量流(604)。所述向量流包括一个或多个多维向量,每个所述向量与输入文本词中的一个或多个关联词相关联,并且这些关联词表示上下文分布,其中关联词出现在由编码器语言模型处理的多个训练文本中。
基于解码器语言模型、所生成的向量流、输入文本和作者,产生输入文本的分类(606)。在某些情形中,解码器语言模型存储有由特定作者在多个训练文本中所使用的词的分布,其使得编码器语言模型产生表示词的特定向量。在某些情形中,输入文本的分类可包括讽刺作品指示、非讽刺作品指示、预测作者指示、或者相关性指示。在某些情形中,还可以接收输入文本的原始作者,并且至少部分基于原始作者来执行产生输出文本。编码器语言模型和解码器语言模型可以是神经网络模型。
在某些情形中,过程600包括使用至少多个训练文本来训练编码器语言模型,以及使用至少一个由编码器语言模型所生成的表示多个训练文本的向量流、多个训练文本、以及与每个训练文本相关联的特定作者,来训练解码器语言模型。特定作者可以包括一个或多个相关训练文本的共同作者。在某些情形中,特定作者可以是与训练文本相关的匿名作者,作者是未知的。请求的作者可以包括多个训练文本的特定作者中的一个或多个。
可以在数字电子电路、内置可触知计算机软件或固件、计算机硬件中实现本主题的实施例和本说明中所描述的功能操作,包括本说明书中公开的结构及结构等同物,或者它们的一个或多个的组合。本说明书中所描述的主题的实施例可以被实现为一个或多个计算机程序,即,计算机程序指令的一个或多个模块,所述程序指令在有形的非暂时性程序载体中被编码并运行,或者控制数据处理装置的操作。替选地或者另外,程序指令可以在人工产生的传播信号中被编码,例如,机器生成的电学、光学或电磁信号,其是被生成以编码信息用于传输给合适的接收器装置,用于由数据处理装置来执行。计算机存储介质可以是机器可读的存储设备、机器可读的存储基片、随机或串行存取存储器设备或者它们中的一个或多个的组合。
术语“数据处理装置”包括所有类型的用于处理数据的装置、设备和机器,例如包括可编程处理器、计算机或者多处理器和多个计算机。装置可以包括专用逻辑电路,例如,fpga(现场可编程门阵列)或者asic(专用集成电路)。除硬件之外,装置还可以包括为所讨论的计算机程序而创建运行环境的代码、例如,组成处理器固件的代码、协议栈、数据库管理系统、操作系统、或者它们中的一个或多个的组合。
可以用任何形式的编程语言来编写计算机程序(计算机程序还可以引申或描述为程序、软件、软件应用、模块、软件模块、脚本或代码),编程语言包括编译语言或者解释型语言、或说明性语言或过程式语言;并且计算机程序可以被部署成任何形式,包括独立程序或者模块、组件、子例程、或者其它适合在计算环境中使用的单元。计算机程序可以,但不是必须,与文件系统中的文件相对应。程序可以被存储在保留其它程序或数据的文件的一部分之中,例如存储在标记语言文档中的一个或多个脚本、存储在用于所讨论程序的单一文件中、或者存储在多个协同文件(例如,存储一个或多个模块、子程序或代码部分文件)之中。可以在一台计算机上或者在多台计算机上部署计算机程序以被执行,多台计算机可以位于一个站点或者跨多个站点分布并且通过通信网络互连。
可以由一个或多个可编程计算机来执行本说明书中所描述的过程和逻辑流程,所述一个或多个可编程计算机通过操作输入数据和生成输出数据来执行一个或多个计算机程序以执行功能。过程和逻辑流程还可以由专用逻辑电路来执行,并且装置也可以被实现为专用逻辑电路,例如,fpga(现场可编程门阵列)或者asic(专用集成电路)。
适合用于计算机程序的执行的计算机可包括,例如,可以基于通用或专用微处理器或两者,或者任何其它类型的中央处理单元。通常,中央处理单元从只读存储器或随机存取存储器或两者接收指令和数据。计算机的必不可少的元素是中央处理单元和一个或多个存储器设备,所述中央处理单元用于执行或运行指令,所述存储器用于存储指令和数据。通常,计算机还可以包括用于存储数据的一个或多个大容量存储器,或者被操作耦合至大容量存储器,以从其接收数据或者或者向其传输数据或者两者都有,所述大容量存储器例如磁盘、磁光盘或者光盘。然而,计算机不是必须具有这样的设备。而且,计算机可以被嵌入在另一个设备中,例如,移动电话、个人数字助理(pda)、移动音频或视频播放器、游戏机、全球定位系统(gps)接收器或者便携式存储设备(例如,通用串行总线(usb)闪存盘),仅举几例。
适用于存储计算机程序指令和数据的计算机可读的介质包括所有形式的非易失性存储器、介质和存储器设备,例如包括半导体存储器设备(例如,eprom、eeprom和闪存设备)、磁盘(例如,内部硬盘或可移动磁盘、磁光盘以及cdrom和dvd-rom盘)。处理器和存储器可以由专用逻辑电路所补充,也可被合并在专用逻辑电路中。
为了提供与用户之间的交互,可以在具有显示设备、键盘和指针设备的计算机上实现本说明书中所描述的主题实施例,所述显示设备用于向用户显示信息(例如,crt(阴极射线管)或lcd(液晶显示器)),所述指针设备例如鼠标或者轨迹球,通过它用户可以向计算机提供输入。此外,可以使用其它类型的设备来提供和用户的交互,例如,提供给用户的反馈可以是任何形式的感觉反馈,如视觉反馈、听觉反馈或触觉反馈;可用任何形式接收来自用户的输入,包括声音、语音或触觉输入。另外,通过发送文档到设备或者接收来自设备的文档的方式,计算机可以与用户产生交互;例如,响应于从web浏览器所接收的请求,可以向用户的用户设备上的web浏览器发送网页。
本说明书中所描述的主题实施例可以在包括后端组件、或者中间件组件、或者前端组件或者任何一个或多个这些后端、中间或前端组件组合的计算系统中被实现,其中所述后端组件例如作为数据服务器,所述中间件组件例如应用服务器,所述前端组件例如具有图形用户界面或者web浏览器的客户端计算机,用户可以通过web浏览器与本说明书中描述的主题实施方式进行交互。系统的组件可以通过任何形式或介质的数字数据通信进行互联,例如,通信网络。通信网络的示例包括局域网(“lan”)和广域网(“wan”),如互联网。
计算机系统可以包括客户端和服务器。通常客户端和服务器彼此远离,且典型地通过通信网络进行交互。客户端与服务器的关系通过在各自相应的计算机上运行并相互具有用户-服务器关系的计算机程序的功效发生。
虽然本说明书包括了许多特定的实现细节,但这些不应被解释为对任意发明或可以要求保护的内容的范围的限制,但可作为对特定发明的特定实施例特定的特征的描述。在单独的实施例上下文中,在本说明书中所描述的某些特征还可以在单一的实施例中组合实现。相反地,在单个实施例上下文中所描述的多个功能也可以以独立的方式或者任何合适子组合的方式在多个实施例中予以实现。而且,虽然上述特征表现为某种组合形式,甚至在最初就被要求这样保护,但在某些情形中,来自要求保护的组合的一个或多个特征可以从组合中被去除,并且所要求保护的组合是指子组合或者子组合的变化。
类似地,虽然在附图中以特定的顺序描绘了操作,但是不应当理解为,为实现所期望的结果,必须按特定的示出顺序或按照序列次序执行这些操作,或者不应当理解为必须执行所有图示的操作。在某些环境下,多任务和并行处理是有利。而且,不应当将所述实施例中各种系统模块和组件的分离理解成在所有实施例中都必须要求这样的分离,还有应当理解的是,通常可以将所描述的程序组件和系统一起集成在单一的软件产品中或者被封装在多个软件产品中。
已经描述了主题的特定实施例。其它的实施例在所附权利要求的范围之内。例如,可以按照不同的顺序来执行权利要求中陈述的操作,并也能得到期望的结果。例如,为达到期望的结果,附图中所解释的过程不必要求按照所示出的特定顺序、或顺序次序。在某些情形中,多任务和并行处理是有利的。
- 还没有人留言评论。精彩留言会获得点赞!