一种基于多级存储的大数据传输完整性保护机制的制作方法
本发明涉及大数据传输技术领域,特别涉及一种基于多级存储的大数据传输完整性保护机制。
背景技术:
在信息技术中,大数据是指无法在一定时间内,用常规的工具软件(如现有数据库管理工具或数据处理应用)对其内容进行抓取、管理、存储、搜索、共享、分析和可视化处理的由数量巨大、结构复杂、类型众多数据构成的大型复杂数据集合。大数据具有四大特点,即高容量(Volume)、快速性(Velocity)、多样性(Variety)和价值密度低(Value)。大数据带来的挑战在于它的实时处理,而数据本身也从结构性数据转向了非结构性数据,因此使用关系数据库对大数据进行处理是非常困难的。
在这种情况下,基于Hadoop的大数据存储和处理平台成为这种存储和处理多源异构大数据的理想工具。大数据处理的流程一般包括数据采集与预处理、数据存储和管理、数据分析和挖掘等几个方面。
在大数据的采集和预处理方面,当前普遍采用的是Sqoop或者Flume等开源的分布式数据导入导出工具,以及基于R语言来编写数据的预处理程序,经过预处理之后的数据再导入到分布式文件系统和分布式数据库中。由于大数据处理的多样性和复杂性,导致大数据平台不能够及时存储并处理实时的海量复杂异构数据。
此外,在使用sqoop等开源工具进行数据导入导出时,从数据源到大数据平台发送数据时,往往会出现网络不稳定的情况,这就导致了网络传输错误,数据的完整性为了解决网络中断或者传输错误的情况,CloudCanyon通过重传的机制来保证数据接入的完整性。但对于实时/近实时采集的数据来讲,一旦网络中断或者传输错误,数据重传机制启动时,丢失的数据往往已经丢失或者在数据源中被更新,这就会导致数据的丢失。
基于上述情况,本发明提出了一种基于多级存储的大数据传输完整性保护机制。
技术实现要素:
本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于多级存储的大数据传输完整性保护机制。
本发明是通过如下技术方案实现的:
一种基于多级存储的大数据传输完整性保护机制,其特征在于:在多源异构大数据的数据源导入大数据平台时,在数据源与大数据平台之间加入一个分布式数据缓存集群,大数据平台不直接从数据源取数据而是从分布式数据缓存集群中读取;同时,分布式数据缓存集群采用Memory Cache、SSD以及Hard Disk的三级存储架构;各级存储之间采用基于策略和事件触发的调度机制,保证大数据平台能够快速地从分布式数据缓存集群中读取数据。
所述分布式数据缓存集群的数据结构和存储方式与数据源服务器保持一致,分布式数据缓存集群以流水化、并行方式传输,支持多任务并发,能够满足了高吞吐量的需求;支持订阅和轮询两种工作模式,不同类型的数据源设有不同的接口和组件来满足数据导入的需求;
对于结构化的数据,在分布式数据缓存集群与数据源之间通过JDBC或者ODBC进行连接,从数据源读取数据后,直接插入分布式数据缓存集群中对应的数据库文件中;对于半结构化格式的数据,则通过FTP、Http协议直接进行读取;对于图像、视频格式的文件,直接通过FTP进行文件传输。
所述分布式数据缓存集群的逻辑存储架构是消息队列,分布式数据缓存集群在数据存储方面的应用包括数据源写入,大数据集群读取,元数据管理和消息队列设置四部分。
所述数据源写入分布式数据缓存集群,包括以下步骤:
(1)数据通过轮询或者订阅的方式由数据源发送到分布式数据缓存集群,当数据到达分布式数据缓存集群时,最新的数据将首先存储到Memory Cache中;为了保证数据的安全性,最开始往Memory Cache中写时,数据按照3副本的模式进行写入,同时保证数据的3个副本在不同的物理机器上,该机制通过hash算法来实现;
(2)当某个消息队列在Memory Cache中数据量到达阈值时,按照队列FIFO的规则,则将最先存入Memory Cache的m%的数据往SSD中写,由于此时m%的数据是以三副本的形式存在于Memory Cache中,在将m%的数据flush到SSD时,将其中1个副本的数据flush到SSD中,然后将对应的副本数据在内存中删除;
(3)当SSD中存储的数据量到达阈值时,同样按照FIFO的规则,将最先写入到SSD的m%的数据写入到Hard Disk中,写入时,将一份数据的一份副本写入到hard disk中。
所述大数据集群从分布式数据缓存集群读,包括以下步骤:
(1)大数据集群会向数据源发送一个数据读的请求,请求中包括请求的id,请求的格式需求;数据源根据大数据集群读的请求,生成一份按照请求id和格式的数据,推送到分布式数据缓存集群中,在分布式数据缓存集群中则根据请求id生成一个消息队列,消息队列来存储数据源推送的数据,大数据集群一直保持对消息队列的监听;
(2)根据元数据信息,大数据集群首先查询某个请求下一个要读的数据在Memory Cache中是否存在,如果Memory Cache中存在,则从内存中读取;如果Memory Cache中不存在,则查询是否存在于SSD中,如果存在于SSD中,则从SSD中读取;如果SSD中不存在,则查询是否在Hard Disk中,如果数据三个副本仅仅存在于Hard Disk中,则从Hard Disk中读取;
(3)数据一旦读取成功,将数据从消息队列中删除。
所述元数据管理是由于分布式数据缓存集群中一份数据的逻辑存储是在消息队列系统中,而实际的物理存储是三级存储的架构,因此,设置了一台元数据服务器NameNode来对分布式集群中的数据进行管理,记录每一份数据的位置信息和状态。
所述消息队列设置是每个消息队列的大小在不同级别的存储中有不同的限制,一般Memory Cache中消息队列的大小小于SSD中,SSD中消息队列的大小小于hard Disk中,可根据分布式数据缓存集群的配置进行设置。
本发明的有益效果是:该基于多级存储的大数据传输完整性保护机制,能够保证数据平台及时存储并处理实时的海量复杂异构数据,同时避免网络不稳定或者网络传输错误造成的数据丢失,保障了数据传输的完整性。
附图说明
附图1为本发明分布式数据缓存集群构架示意图。
附图2为本发明基于多级存储的大数据传输完整性保护机制数据流向示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图和实施例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
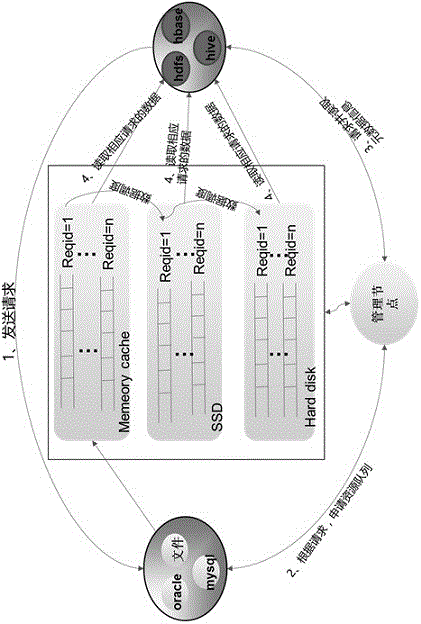
该基于多级存储的大数据传输完整性保护机制,在多源异构大数据的数据源导入大数据平台时,在数据源与大数据平台之间加入一个分布式数据缓存集群(Distributed Cache Cluster,简称DCC),大数据平台不直接从数据源取数据而是从分布式数据缓存集群中读取;同时,分布式数据缓存集群采用Memory Cache、SSD以及Hard Disk的三级存储架构;各级存储之间采用基于策略和事件触发的调度机制,保证大数据平台能够快速地从分布式数据缓存集群中读取数据。
所述分布式数据缓存集群的数据结构和存储方式与数据源服务器保持一致,分布式数据缓存集群以流水化、并行方式传输,支持多任务并发,能够满足了高吞吐量的需求;支持订阅和轮询两种工作模式,不同类型的数据源设有不同的接口和组件来满足数据导入的需求;
对于结构化的数据,如oracle、mysql等,在分布式数据缓存集群与数据源之间通过JDBC或者ODBC进行连接,从数据源读取数据后,直接插入分布式数据缓存集群中对应的数据库文件中;对于文本、csv等半结构化格式的数据,则通过FTP、Http协议直接进行读取;对于图像、视频格式的文件,直接通过FTP进行文件传输。
所述分布式数据缓存集群的逻辑存储架构是消息队列,分布式数据缓存集群在数据存储方面的应用包括数据源写入,大数据集群读取,元数据管理和消息队列设置四部分。
所述数据源写入分布式数据缓存集群,包括以下步骤:
(1)数据通过轮询或者订阅的方式由数据源发送到分布式数据缓存集群,当数据到达分布式数据缓存集群时,最新的数据将首先存储到Memory Cache中;为了保证数据的安全性,最开始往Memory Cache中写时,数据按照3副本的模式进行写入,同时保证数据的3个副本在不同的物理机器上,该机制通过hash算法来实现;
(2)当某个消息队列在Memory Cache中数据量到达阈值时,按照队列FIFO的规则,则将最先存入Memory Cache的m%的数据往SSD中写,由于此时m%的数据是以三副本的形式存在于Memory Cache中,在将m%的数据flush到SSD时,将其中1个副本的数据flush到SSD中,然后将对应的副本数据在内存中删除;
M为大于5小于20的自然数。
(3)当SSD中存储的数据量到达阈值时,同样按照FIFO的规则,将最先写入到SSD的m%的数据写入到Hard Disk中,写入时,将一份数据的一份副本写入到hard disk中。
所述大数据集群从分布式数据缓存集群读,包括以下步骤:
(1)大数据集群会向数据源发送一个数据读的请求,请求中包括请求的id,请求的格式需求;数据源根据大数据集群读的请求,生成一份按照请求id和格式的数据,推送到分布式数据缓存集群中,在分布式数据缓存集群中则根据请求id生成一个消息队列,消息队列来存储数据源推送的数据,大数据集群一直保持对消息队列的监听;
(2)根据元数据信息,大数据集群首先查询某个请求下一个要读的数据在Memory Cache中是否存在,如果Memory Cache中存在,则从内存中读取;如果Memory Cache中不存在,则查询是否存在于SSD中,如果存在于SSD中,则从SSD中读取;如果SSD中不存在,则查询是否在Hard Disk中,如果数据三个副本仅仅存在于Hard Disk中,则从Hard Disk中读取;
(3)数据一旦读取成功,将数据从消息队列中删除。
所述元数据管理是由于分布式数据缓存集群中一份数据的逻辑存储是在消息队列系统中,而实际的物理存储是三级存储的架构,因此,设置了一台元数据服务器NameNode来对分布式集群中的数据进行管理,记录每一份数据的位置信息和状态。
所述消息队列设置是每个消息队列的大小在不同级别的存储中有不同的限制,一般Memory Cache中消息队列的大小小于SSD中,SSD中消息队列的大小小于hard Disk中,可根据分布式数据缓存集群的配置进行设置。
以一次实时的数据读写为例,大数据集群首先发送一个读数据的请求给数据源,请求id为1;数据源根据请求的ID,去分布式缓存集群的管理节点请求创建一个消息队列,队列ID为1;创建队列成功之后,管理节点会发送一个确认信息给数据源,信息包括了请求队列的位置;这时候数据源根据请求的内容向分布式数据缓存集群的数据节点发送数据,发送过程就是写的过程,按照发明内容中写数据的规则进行写。大数据集群则根据请求的ID,首先去管理节点查询要读的下一个数据的位置,然后选择一个最快的队列进行读取,一旦读取成功,则将队列数据清空。
- 还没有人留言评论。精彩留言会获得点赞!