CPU+MIC异构平台下的大涡模拟算法优化处理方法与流程
本发明属于高性能计算技术领域,特别涉及一种CPU+MIC异构平台下的大涡模拟算法优化处理方法。
背景技术:
无论是在自然界还是在工程中,流体的流动很多都是湍流流动。湍流是一种非常复杂的流动,表现有旋性、随机性等方面。研究湍流的主要方法是数值模拟。但是由于有些实验难以实现,例如机翼附近的空气流动,故数值模型的方法得到了研究人员的青睐。
现有的湍流数值模拟方法包括直接数值模拟,雷诺平均模拟和大涡数值模拟。直接数值模拟不需要对湍流建立模型,采用数值计算直接求解流动的控制方程。工程中广泛应用的湍流数值模拟方法采用雷诺平均模型,这种方法将流动的质量、动量和能量输运方程进行统计平均后建立模型。目前计算机的计算能力仍对数值模拟紊流时所采用的网格尺度提出了严格的限制条件。人们可以获得尺度大于网格尺度的紊流结构,但却无法模拟小于该网格尺度的紊动结构。大涡模拟的思路是直接数值模拟大尺度紊流运动,而利用次网格尺度模型模拟小尺度紊流运动对大尺度紊流运动的影响。
大涡模拟较直接数值模拟占计算机的内存小,模拟需要的时间也短,并且能够得到较雷诺平均模型更多的信息。所以随着超级计算机的发展,大涡模拟越来越受到国内外研究者的关注,并且认为大涡模拟将是最有前景的湍流模型。
技术实现要素:
针对现有技术中的不足,本发明提供一种CPU+MIC异构平台下的大涡模拟算法优化处理方法,解决大涡模拟算法在异构众核架构运行时性能低,且受限于模拟范围模拟时长问题,针对异构平台下的大涡模拟程序,依次进行核心分析改进、CPU端优化、MIC端优化,以及异构协同优化,有效提升程序的运行效率和执行性能。
按照本发明所提供的设计方案,一种CPU+MIC异构平台下的大涡模拟算法优化处理方法,包含如下步骤:
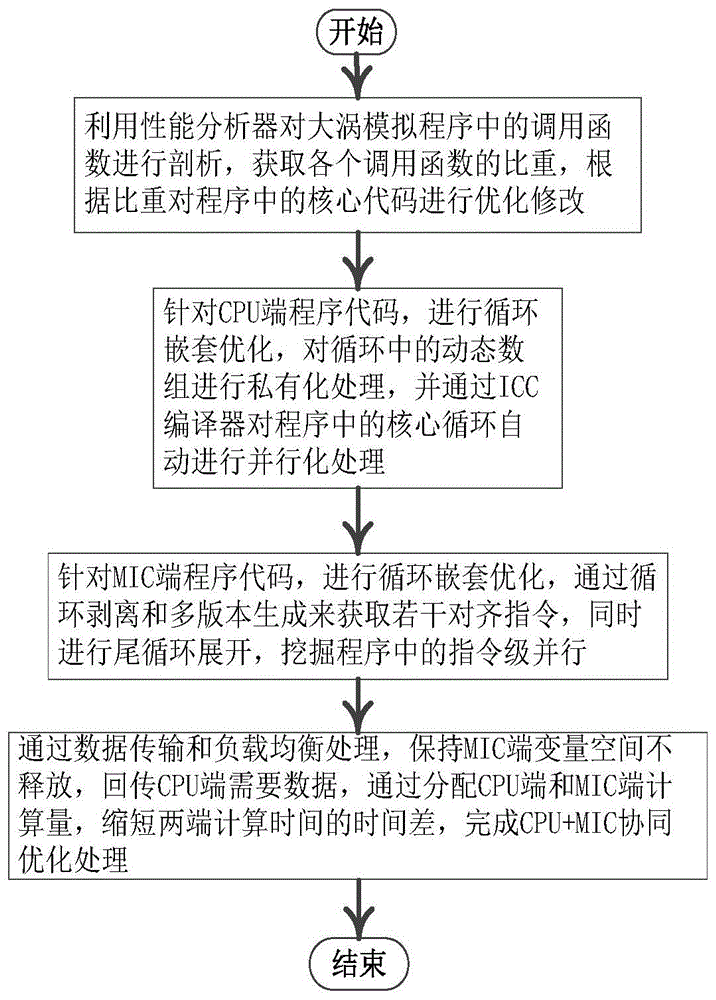
步骤1、利用性能分析器对大涡模拟程序中的调用函数进行剖析,获取各个调用函数的比重,根据比重对程序中的核心代码进行优化修改;
步骤2、针对CPU端程序代码,进行循环嵌套优化,对循环中的动态数组进行私有化处理,并通过ICC编译器对程序中的核心循环自动进行并行化处理;
步骤3、针对MIC端程序代码,进行循环嵌套优化,通过循环剥离和多版本生成来获取若干对齐指令,同时进行尾循环展开,挖掘程序中的指令级并行;
步骤4、通过数据传输和负载均衡处理,保持MIC端变量空间不释放,回传CPU端需要数据,通过分配CPU端和MIC端计算量,缩短两端计算时间的时间差,完成CPU+MIC协同优化处理。
上述的,步骤1中的根据比重对程序中的核心代码进行优化修改具体包含如下内容:根据比重对程序中的核心代码进行内联替换、死代码删除、循环展开、循环合并,及应用前向替换和常数传播修改。
上述的,步骤2中还包含对CPU端程序代码的多线程优化、SIMD向量化。
优选的,步骤2中的并行化处理还包含:通过OpenMP编译,对核心循环自动并行化,通过循环交换和循环合并,扩展并行区,选用动态调度类型执行线程任务,并进行循环分块、循环展开。
上述的,步骤3中还包含对MIC端程序代码的多线程优化、SIMD向量化、流存储优化、乘加融合优化。
本发明的有益效果:
本发明解决现有技术中大涡模拟算法在异构众核架构运行性能低,且受限于模拟范围模拟时长问题,针对异构平台下的大涡模拟程序,依次进行核心分析改进、CPU端优化、MIC端优化,以及异构协同优化,实现3D线性大涡模拟程序在异构平台的移植,有效提升程序的运行效率和执行性能,相对原始代码,优化后的程序在异构平台上获得24X加速效果,对其他大涡模拟等程序在异构平台上的优化具有指导意义。
附图说明:
图1为本发明的流程示意图;
图2为大涡模拟程序运行流程图;
图3为大涡模拟程序结构图。
具体实施方式:
内联替换:在程序中耗时排名前6的核心分别是FLUXI,FLUXJ,FLUXK以及EXTRAPI,EXTRAPJ,EXTRAPK,通过源代码发现函数EXTRAPI仅被函数FLUXI调用,函数EXTRAPJ仅被函数FLUXJ调用,函数EXTRAPK仅被函数FLUXK调用,通过内联合并为更大的函数。
死代码删除:程序中有许多PARAMETER变量,如ISGSK=0,而在代码中存在许多条件分析如IF(ISGSK.EQ.1)THEN,分支中的语句为死代码,将其删除。
循环展开,循环合并:函数FLUXI中的核心为一个嵌套循环,L层循环的上下界是固定的,分别是1和5,因此,可以将L层完全展开,这样L内层的I循环就可以和后面的I层循环进行合并,实例代码如下,
多线程优化:ICC(version 14.0)的自动并行化模块并不能直接对核心循环并行化,其认为最内层循环I的计算量不够,而在循环K和J层存在依赖,分析后发现需要对循环中QS等动态数组私有化,以解决其引起依赖,此为ICC的自动并行化失败的原因。通过手工添加OpenMP编译指示实现了最外层循环K的自动并行化。此外,若将每个嵌套循环单独处理,线程开销较大,且循环内计算量较小,因此通过循环交换和循环合并,扩展并行区。最后通过测试发现动态调度比静态调度具有更好的性能,因此选用dynamic调度。
SIMD向量化:Intel Xeon支持256bit的向量操作,由于核心满足ICC自动向量化的要求,因此利用编译选项-O3–xAVX便可生成256位的向量代码,其可同时执行4个double类型的浮点计算,向量化技术的使用获得了1.3X的加速效果。
Intel Xeon Phi支持512bit的向量操作,可同时执行8个double类型的浮点计算,在面向MIC向量化时通过查看汇编发现编译器生成了不对齐指令,通过循环剥离和多版本生成更多对齐指令,同时将尾循环完全展开,提高了指令级并行,程序被向量化后获得2.4X的加速。
流存储:应用MIC平台的流存储、预取以及2MB存储页优化共获得2%的性能提升
乘加融合:利用MIC平台提供的乘加融合指令实现一条指令计算a+b*c操作,利用编译选项-fma提升了3%的性能提升。
大涡模拟程序Leslie3d程序运行可以分为三个阶段,分别是初始化阶段,核心计算阶段和后处理阶段,如图2和图3所示,初始化阶段负责处理数值模型计算前的准备工作,包括申请内存空间、初始化全局变量、参数读取、输出初始测试信息,核心计算阶段从三个维度对参数指定场景进行模拟计算,后处理阶段就是输出程序运算结果并资源释放等,Leslie3d运行时流程如图2所示。
下面结合附图和技术方案对本发明作进一步详细的说明,并通过优选的实施例详细说明本发明的实施方式,但本发明的实施方式并不限于此。
实施例一,参见图1所示,一种CPU+MIC异构平台下的大涡模拟算法优化处理方法,包含如下步骤:
步骤1、利用性能分析器对大涡模拟程序中的调用函数进行剖析,获取各个调用函数的比重,根据比重对程序中的核心代码进行优化修改;
步骤2、针对CPU端程序代码,进行循环嵌套优化,对循环中的动态数组进行私有化处理,并通过ICC编译器对程序中的核心循环自动进行并行化处理;
步骤3、针对MIC端程序代码,进行循环嵌套优化,通过循环剥离和多版本生成来获取若干对齐指令,同时进行尾循环展开,挖掘程序中的指令级并行;
步骤4、通过数据传输和负载均衡处理,保持MIC端变量空间不释放,回传CPU端需要数据,通过分配CPU端和MIC端计算量,缩短两端计算时间的时间差,完成CPU+MIC协同优化处理。
本发明解决现有技术中大涡模拟算法在异构众核架构运行性能低,且受限于模拟范围模拟时长问题,针对异构平台下的大涡模拟程序,程序优化从4个方面展开,分别是核心的分析和改进、CPU端优化、MIC端优化以及异构协同(CPU+MIC)优化,实现3D线性大涡模拟程序在异构平台的移植。
实施例二,参见图1~3所示,一种CPU+MIC异构平台下的大涡模拟算法优化处理方法,具体包含如下内容:
首先,利用性能分析器对大涡模拟程序中的调用函数进行剖析,获取各个调用函数的比重,有针对性修改核心代码,提高程序的优化效果,在分析结果的基础上,利用内联替换、死代码删除、循环展开、循环合并,及应用前向替换和常数传播对核心代码进行修改,程序运行效率得到有效提升,经测试,通过核心分析和修改,运行效率提升7.9%;
然后,针对CPU端程序代码,进行多线程优化、SIMD向量化、循环嵌套优化,对循环中的动态数组进行私有化处理,已解决其引起的依赖,通过ICC编译器对程序中的核心循环自动进行并行化处理;通过OpenMP编译,对核心循环自动并行化,通过循环交换和循环合并,扩展并行区,选用动态调度类型执行线程任务,并进行循环分块、循环展开,提高访存局部性,提高指令级并行。通过手工添加OpenMP编译指示实现了核心循环的最外层循环K的自动并行化,若将每个嵌套循环单独处理,线程开销较大,且循环内计算量较小,因此通过循环交换和循环合并,扩展并行区;选用dynamic调度获取更好的性能。由于核心满足ICC自动向量化的要求,利用编译选项-O3–xAVX便可生成256位的向量代码,其可同时执行4个double类型的浮点计算;通过循环分块可以提高访存的局部性,通过循环展开可以提高指令级并行,以提高程序的执行效率。经测试,CPU端优化后运行效率提升了948.1%。
接着,针对MIC端程序代码,进行多线程优化、SIMD向量化、循环嵌套优化,包括流存储优化、乘加融合优化等MIC平台特有的优化处理,通过循环剥离和多版本生成来获取若干对齐指令,得到更多对其指令,同时进行尾循环展开,挖掘程序中的指令级并行。Intel Xeon Phi支持512bit的向量操作,可同时执行8个double类型的浮点计算,在面向MIC向量化时通过查看汇编发现编译器生成的不对齐指令,通过循环剥离和多版本生成更多对齐指令,同时将尾循环完全展开,提高了指令级并行。经测试验证,MIC平台的L1cache的大小为32KB,当循环分块大小tile size=128时效果最好循环分块提升了2%。利用MIC平台提供的乘加融合指令实现一条指令计算a+b*c操作,利用编译选项-fma提升了3%的性能提升;此外应用MIC平台的流存储、预取以及2MB存储页优化共获得2%的性能提升。
最后,通过数据传输和负载均衡处理,保持MIC端变量空间不释放,回传CPU端需要数据,通过分配CPU端和MIC端计算量,缩短两端计算时间的时间差,完成CPU+MIC协同优化处理。保持MIC端变量空间不释放,仅传回少量CPU端需要使用的数据,虽然首次传输时数据传输至MIC上的变多,但是后面平均每次传输的数据变少;并通过分配CPU端和MIC端的计算量,使得两端的计算时间相近,同时将任务计算完毕。
本发明不局限于上述具体实施方式,本领域技术人员还可据此做出多种变化,但任何与本发明等同或者类似的变化都应涵盖在本发明权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!