一种基于学术大数据的期刊影响力评估方法与流程
本发明涉及学术领域中基于学术大数据对期刊影响力进行评估的方法,尤其涉及一种将PageRank算法与H指数相结合的期刊影响力评估方法。
背景技术:
随着科技的不断发展,从事科研工作的人数越来越多,他们的研究成果通常以学术论文、专利、书籍等形式呈现,数量庞大的科研人员产生了数以亿计的数据。这些数据统称为学术大数据。学术大数据的用途广泛,期刊影响力评估是学术大数据的一个重要应用。期刊的影响力是以期刊的学术水平、学术特色为根本,以社会信誉度为标志所体现出来的一种综合性效果,期刊的质量决定着期刊的影响力。目前期刊影响力评估所采用的方法都是基于引用(citation-based)分析的,包括Impact Factor(影响因子)、Eigenfactor(特征因子)、PageRank等算法。但是上述算法也存在评价指标过于单一、无法跨领域评估期刊影响力等问题。
技术实现要素:
本发明的目的主要针对上述现有研究的一些不足之处,提出基于学术大数据的期刊影响力评估方法,通过对期刊上论文的引用信息进行分析,提出一种加权的PageRank算法——AR-PageRank算法,该算法考虑了两篇论文的参考文献重合度,通过该重合度来表征这两篇论文的相似性,同时加入了对作者H指数的考量,一篇论文的作者H指数一定程度上代表了该论文的影响力。
本发明的技术方案:
一种基于学术大数据的期刊影响力评估方法,步骤如下:
1)将论文作者的H指数作为影响因素作用于期刊论文影响力的评估;
2)通过比较两篇论文的参考文献的“重合度”来计算文章的相似性;
3)通过分析论文引用网络的特点,将PageRank算法进行改进,将1)中的H指数和2)中的“重合度”作为“权重”元素结合到PageRank算法中,由此得出AR-PageRank算法,计算每篇论文的AR-PageRank值;
4)将期刊中所有论文的AR-PageRank值进行加和,得到期刊的评估值。
步骤1):H指数是作者层面的一个指标,它是一个学者或科学家的出版物的数量和影响力方面的度量,H指数能够比较准确地反映一个学者的学术成就,一个学者的H指数越大,该学者的论文影响力越大。
本发明中使用如下公式定义一篇论文的H指数:
其中pj代表论文,A(pj)表示pj的H指数,an是文章pj上的作者,H(an)表示an的作者H指数。
为了区分论文在论文集中的重要程度,本发明利用求得的论文H指数及如下公式对论文在网络中的重要程度进行定义:
其中P代表论文数据集,Max({A(pz)|pz∈P})表示论文数据集中论文H指数的最大值,θ的值为0.01,θ的作用是使δ(pj)不为0。
步骤2):通过一篇文章的参考文献能够获得该文章的研究内容和方向,出于这个考虑,本发明通过比较两篇论文的参考文献的“重合度”来计算文章的相似性,并使用如下公式计算两篇论文的参考文献“重合度”:
其中pi,pj代表数据集中的任意两篇论文,OUT(pi)和OUT(pj)表示pi和pj的参考文献集合,代表pi,pj两篇文章的相似度,两篇论文越相似,的值越大。
步骤3):经研究发现,无论是最原始的PageRank算法还是变形后的PageRank算法,都是“无权重”的算法。所谓“无权重”是指一篇文章在给其引用的文章“投票”时是“平均主义”的,它没有区分引用文章的特殊性,而是“一视同仁”。本发明根据步骤2)中得出的“相似度”,将其作为引用文章的特征值对PageRank算法进行修改,新的算法在原有PageRank算法基础上加入了“权重”元素。同时,将步骤1)中计算的文章在网络中的重要程度也融入PageRank算法中,得到AR-PageRank算法。
AR-PageRank算法的表达式如下所示:
其中d是“阻尼系数”,通常被设为0.85,IN(pi)表示所有引用pi的文章集合,PR(pi)表示pi的PageRank得分,是PageRank算法的基本公式。的加入使得该算法成为“加权”的PageRank算法。因为论文pj在给它的每篇参考文献“投票”时会对该参考文献进行“分析”,相似度不同的参考文献会区别对待。
步骤4):根据步骤3)得到的论文AR-PageRank值,将这些论文得分以期刊为单位进行累加,把累加分求平均,将这个平均分作为最后的期刊评分。
期刊的评分公式如下所示:
其中Publish(ji)代表发表在期刊ji上的论文集合,|Publish(ji)|表示该论文集合的大小,PR(pk)是论文pk的AR-PageRank得分。
本发明的有益效果:计算论文影响力的方法是一种基于PageRank的算法:AR-PageRank,该算法考虑了论文与引用它的论文之间的相似度、作者H指数等因素,前者使得该算法成为“加权”的算法,在算法迭代过程中,每篇论文在对其引用的论文“投票”时,会因为论文间的相似度而给予不同的贡献;后者使得每篇论文的“重要性”大大增加,通过作者H指数的加和计算得到每篇论文的H指数,该指数作为该论文的一个标签,使得每篇论文的差异性在计算过程中逐渐显现出来,从而能够较为准确地区分每篇论文的影响力,最终获得每个期刊的影响力。
附图说明
图1为PageRank、A-PageRank、AR-PageRank算法分别应用在DBLP数据集上所得到的排序结果。
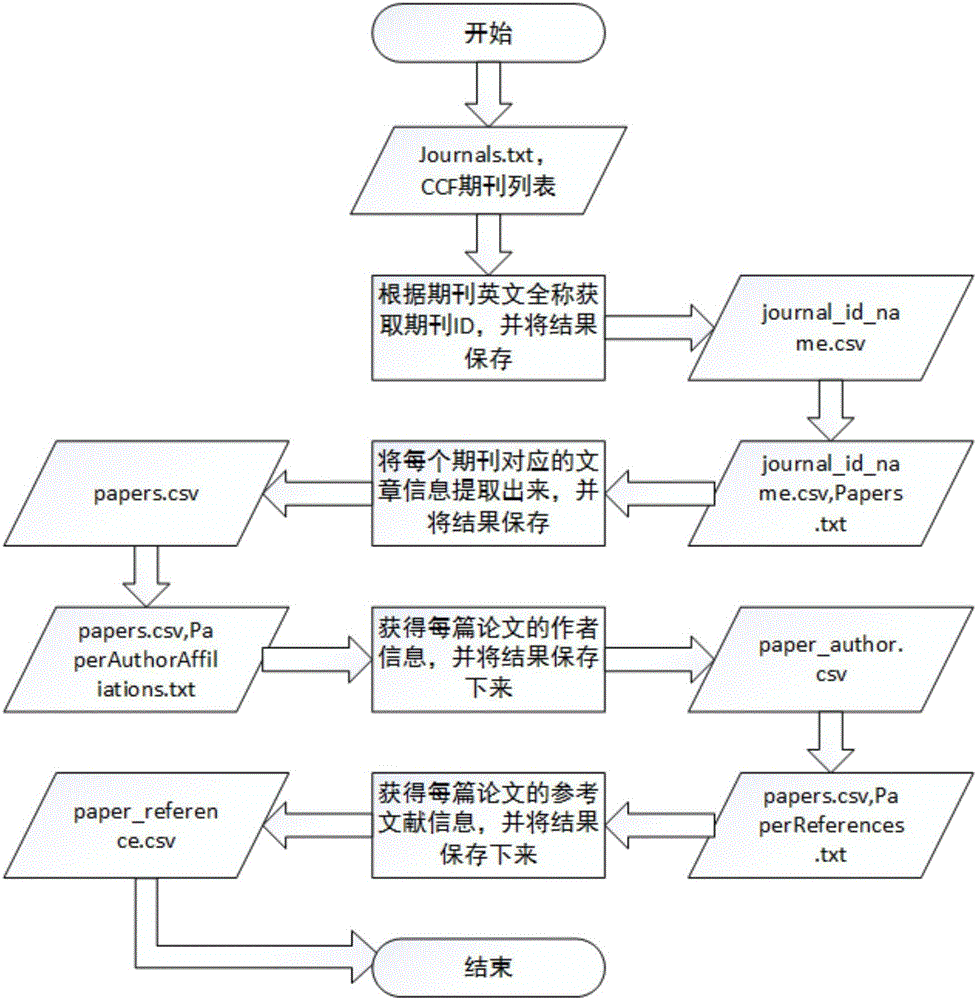
图2为根据实验要求对微软MAG数据集进行的数据处理流程。
图3、图4和图5为四种算法分别应用在DBLP、DBLP(2011-2015)、MAG数据集上,并且采用斯皮尔曼相关系数计算后得到的各个算法的相关系数情况。
图6、图7、图8和图9为四种算法在DBLP、DBLP(2011-2015)数据集上处理结果的对比图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式作进一步的详细描述。
本发明实施例提供了一种基于学术大数据的期刊影响力评估方法,该方法包括:
步骤1:选取DBLP、MAG数据集作为本方法的实验数据集,对DBLP和MAG数据集进行预处理。
本发明参考了中国计算机学会2015年推荐的期刊排名,并选取了“人工智能”领域的42个期刊作为评价标准(MAG数据集选取了45个人工智能领域期刊)。根据实验要求对两个数据集进行预处理,图2给出了对MAG数据集进行处理的流程图。
预处理后两个数据集的信息分别如下:
表1MAG数据集
Tab.1MAG dataset
表2DBLP数据集
Tab.2DBLP dataset
从表格中可以看出MAG中论文的数量要明显小于DBLP论文的数量,因为抽取得到的MAG数据集中的论文数量过少,本发明爬取了DBLP数据集,并把该数据集作为“主”数据集,把MAG数据集作为“对比”数据集。
为了计算期刊影响因子(5-year IF),本发明从DBLP数据集中单独抽取了2011-2015共5年的数据,组成了第3个数据集。
表3DBLP数据集(2011-2015)
Tab.3DBLP dataset(2011-2015)
步骤2:本发明的算法实现部分采用了3个数据集,分别是MAG、DBLP、DBLP(2011-2015)。在MAG、DBLP数据集上分别应用了Eigenfactor、PageRank、A-PageRank、R-PageRank、AR-PageRank算法。
AR-PageRank,即Author Reference PageRank,Author意味着该算法考虑了H指数这一因素,Reference表示考虑了论文与其参考文献的关系。因此,A-PageRank算法就是只考虑H指数的因素,P-PageRank算法就是只考虑论文与参考文献的关系。
AR-PageRank算法的表达式为:
A-PageRank算法的表达式为:
R-PageRank算法的表达式为:
PageRank算法的表达式为:
图1中列出的是PageRank、A-PageRank、AR-PageRank算法分别应用在DBLP数据集上所得到的排序结果。
步骤3:将步骤2)中得到的结果采用斯皮尔曼相关系数进行计算,得到各个算法的相关系数情况。
本发明采用数学方法把列表间的相似性进行计算。斯皮尔曼相关系数是衡量两个变量依赖性的非参数指标,它利用单调方程评价两个统计变量的相关性。计算公式如下所示:
其中,ρ表示斯皮尔曼相关系数,Ji代表期刊列表中的一个期刊,R1、R2是期刊列表,R1(Ji)表示期刊Ji在列表R1中的位置。
图3、图4和图5给出了四种算法在不同数据集中的相关系数情况。可以看出在DBLP数据集中,算法AR-PageRank在期刊数等于42时的相关系数是最大的,该算法在DBLP数据集上表现最好;在DBLP数据集(2011-2015)中,AR-PageRank算法依然是各个算法中评估效果较好的;在MAG数据集中,A-PageRank算法的相关系数要略高于AR-PageRank算法,R-PageRank算法和PageRank算法的处理结果十分接近。出现上述两种情况的原因与MAG数据集的特点有关,通过观察我们发现,MAG数据集的论文数、被引用论文数、作者数等都低于其它两个数据集,数据集的“好坏”对实验结果会有重要的影响。
图6、图7、图8和图9是四个算法在DBLP、DBLP(2011-2015)数据集上处理结果的对比图,红色的折线表示算法应用在DBLP(2011-2015)数据集上的处理结果,黑色的折线表示算法应用在DBLP数据集上的处理结果。从图中不难看出同样的算法在DBLP数据集上的处理效果要优于DBLP(2011-2015)数据集,后者是前者的子集,相比较而言,前者的数据规模更大、数据种类更多,其实验结果也更为准确可靠。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!