一种基于学术大数据的会议影响力评估方法与流程
本发明涉及学术领域中基于学术大数据对会议影响力进行评估的方法,尤其涉及一种基于马尔可夫模型的会议影响力评估方法。
背景技术:
科学领域的高速发展使得国际学术会议的数量不断增加,对于不断增长的科学会议,影响力的评估变得越来越重要,评估结果不但能够反映会议的重要性,也可以为学术研究提供参考。会议、会议论文及引用关系组成了巨大的学术网络,学术大数据的飞速增长使得会议影响力的评估变得更加困难。PageRank、HITS等常规主流评估方法的评估结果并不能满足评估领域对准确度的需求,准确度、稳定性更高的评估方法有待于研究人员的进一步探索。
技术实现要素:
本发明的目的主要针对现有研究的一些不足之处,提出基于学术大数据的会议影响力评估方法,通过将会议的访问概率作为衡量会议重要性的关键,利用会议论文之间的引用关系,首次使用马尔可夫模型对会议进行评估,为会议影响力的评估提供一种新方法。
本发明的技术方案:
一种基于学术大数据的会议影响力评估方法,步骤如下:
1)通过统计真实的会议论文引用情况计算目标窗口年限;
2)结合随机游走模型,根据不同的记忆度进行会议网络的建模,分别对应于零阶马尔可夫模型和一阶马尔可夫模型构建引用流模型;
3)根据1)中得到的目标窗口年限统计出两种引用流模型所需的引用量;
4)将3)中得到的引用量带入2)中构建出的引用流模型,由此计算出会议访问概率的数值,进而评估出会议的影响力。
步骤1):
本发明对于会议的评估参考了影响因子和特征因子评估期刊的过程。传统的影响因子一般用两年的引用目标窗口,特征因子一般默认使用五年的引用目标窗口,这些年限的设置都是针对期刊引用量的逐年变化计算得来的。会议与期刊不同,所以会议的影响因子和特征因子对于年份的限制不能直接套用期刊的年份限制,根据真实引用数据的计算结果确定计算目标窗口年限。
采用学术大数据集中统计会议论文的真实引用量确定引用目标窗口年限,根据统计出大量会议论文自出版后每年的被引数量并观察趋势,确定目标窗口年限为两年。
步骤2)包括以下三个步骤:
2.1)对会议之间进行引用流建模,首先将会议的文章级引用数据进行汇总,之后对随机游走的网络流进行建模。本发明中提到的引用流模型是指将会议论文以及论文之间的引用关系进行抽象建模。本方法依照不同的记忆度对网络中的引文数据进行聚合,根据不同的记忆度实现引用流模型的构建,构建出的引用流模型分别对应于零阶和一阶马尔可夫模型。本发明将要评估的年份称为源年,引用目标窗口年中源年会议论文所引用到的年份称为目标年。
2.2)在零阶马尔可夫网络上的随机游走是无记忆的,下一步并不依赖于现在所访问的会议,所以对于零阶马尔可夫模型,需要计算发表在源年会议上的文章对发表在目标年会议上的文章的引用数量。为了构建会议网络,本发明将这些引文数汇总在被引文章所在的会议上,也就是说,每当一篇发表在源年会议j上的文章对一篇发表在目标年会议k上的文章存在引用关系j->k时,就对被引用的会议k的权重加1,W(k)->W(k)+1,跳转到k会议的概率计算公式如下:
其中π(0)(k)为会议k的访问概率,W(k)为会议k得到的引用数量,∑k W(k)为所有会议得到的总引用数量。
2.3)一阶马尔可夫模型的随机游走过程具有一步记忆的特征,下一步所访问的会议与现在所访问的会议有关。对于一阶马尔可夫模型,引用数是将引文和被引文成对记录在被引用的会议上。即每当一篇发表在源年会议j上的文章对一篇发表在目标年会议k上的文章存在引用关系j->k时,就对引用和被引会议之间的链接权重加1,W(j->k)->W(j->k)+1,具体如下:
Step1:根据如下公式计算从会议j跳转到会议k的概率:
其中p(j→k)为会议j跳转到会议k的概率,W(j→k)为会议k从会议j中得到的引用数量,∑k W(j→k)为会议k从所有会议所得到的总引用数量。
Step2:根据如下公式得到会议k的访问概率:
其中π(1)(k)为会议k的访问概率,为所有会议跳转到会议k概率之和,p(k)为零阶马尔可夫模型中访问会议k的概率,α和(1-α)是为了解决起始点问题而引入的变量,1-α=0.15。
步骤3):根据步骤1)中得到的目标窗口年限,统计出两种引用流模型实验所需的引用量。同时,本发明对会议的自引用进行了考虑,所以统计出的引用量分别为存在自引用的引用量和不存在自引用的引用量两种情况。
本发明考虑自引用的原因在于,自引用可能存在增加论文的引用量从而提高论文的影响力的情况,为了使本发明的方法更具客观性,我们将存在自引用和不存在自引用的两种情况进行了区分。
步骤4):将步骤3)中得到的引用量带入步骤2)中构建出的引用流模型,由此计算出会议访问概率的数值,进而评估出会议的影响力。
本发明的有益效果:本发明将马尔可夫的零阶模型和一阶模型分别应用,比较两个模型评估结果的精确性和鲁棒性,同时考虑了自引用对于会议重要性的影响,两个模型分别在有自引和无自引的情况下进行实验,实验结果表明自引用容易被动机不良者利用,无自引的实验结果相比于有自引的实验结果更具可靠性,同时也验证了马尔可夫模型被使用在评估领域的可行性以及一阶马尔可夫模型比零阶马尔可夫模型更具鲁棒性。本发明提供了会议影响力评估的一种新方法,为会议影响力的评估工作提供了一种新的解决方案。
附图说明
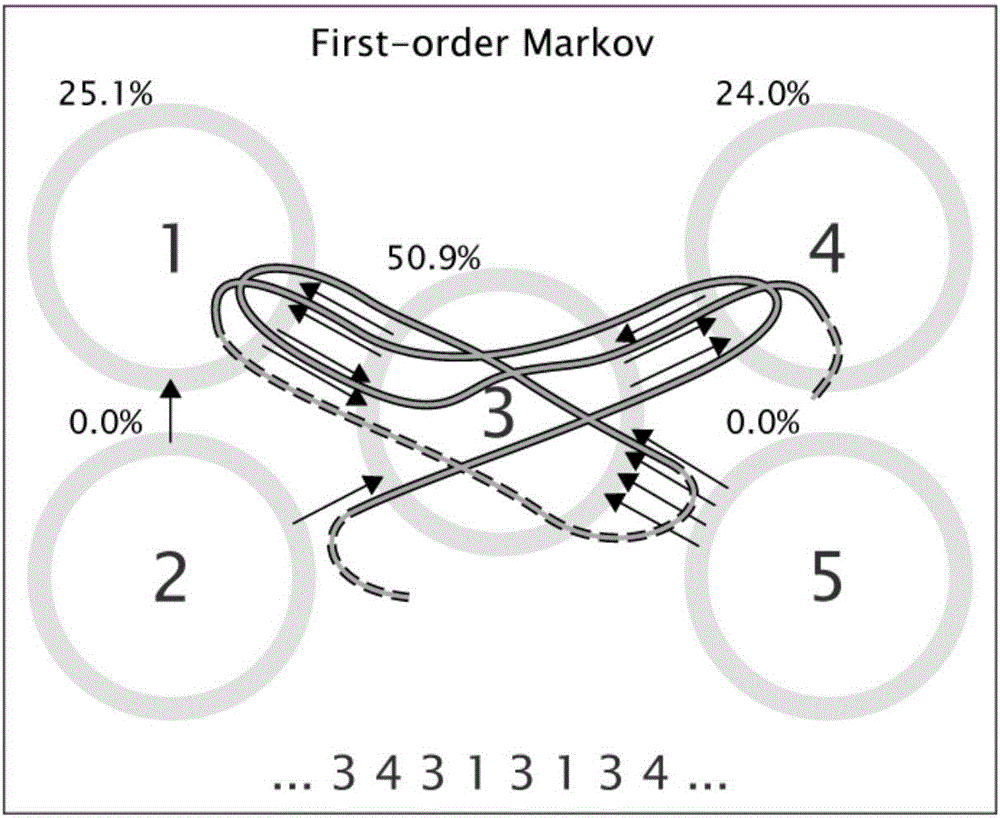
图1和图2为本发明结合随机游走模型,根据不同的记忆度进行会议网络的建模,构建出的引用流模型分别对应于零阶马尔可夫模型和一阶马尔可夫模型。
图3为在微软MAG学术数据集中筛选出的39个人工智能领域会议2006年发表的会议论文在2006年到2015年的分别引用数量,由此图可确定引用目标窗口年限。
图4和图5为对39个人工智能会议进行真实数据统计及实验后得出的会议排名与中国计算机协会(CCF)列表中的会议排名进行分段匹配后所得的匹配度,有自引和无自引的计算结果同时列出,零阶模型和一阶模型的结果分别列出。
图6为一阶马尔可夫模型无自引评估分数的计算过程,比较出一阶马尔可夫模型比零阶马尔可夫模型更具鲁棒性。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式作进一步的详细描述。
本发明实例提供了一种基于学术大数据的会议影响力评估方法,该方法包括:
步骤1:参考期刊影响因子思想,根据真实的实验数据,运用统计的方法寻找会议论文的引用目标窗口年限。
1.1)选取CCF中推荐的人工智能领域的39个会议,在微软MAG学术数据集中筛选出这39个会议2006年发表的会议论文在2006年到2015年的分别引用数量。
MAG是一个非常庞大的数据集,涵盖学术界各个领域的相关论文信息。想要获取实验所用的数据,就需要对这个庞大的数据集进行筛选过滤,数据集中的信息如表1所示。
表1 MAG数据集文件信息
Tab.1 Information of MAG dataset
对MAG数据集进行预处理。根据2015年CCF提供的列表,本发明选取了人工智能领域的会议作为实验的对象,CCF列举了该领域的39个会议并进行了等级排序。为了确定引用目标窗口年限,需要将这39个会议的文章引用情况进行分析,根据实际情况将目标窗口年限计算出来。为了使计算结果更加具有可信性,本发明将39个会议在2006年发表的论文作为目标文章,取10年期进行观察,将2006年到2015年其他发表在这39个会议上的论文对目标文章的引用根据年份的不同进行分别的数量统计,并将同一会议上发表的目标文章的引用数量进行加和。
在本发明中,之所以取10年为期进行引用量的观察,是因为考虑到会议论文之间的引用特点,学者在发表一篇新论文时,往往会引用近些年发表的论文作为参考文献。研究人员将期刊论文之间的引用进行分析,将影响因子确定为两年。会议与期刊有所不同,本发明希望用真实的数据对会议引用情况进行统计,从而得到更加准确的目标窗口年限。学者一般会引用3~5年前的论文作为参考,根据这一特点,我们年限选定为10年进行引用量的观察。这种取样的方式和思想同样适用于其他学科的研究。
1.2)将统计结果进行进一步分析,图3是统计数据后得到的引用趋势。观察图中的引用趋势可以发现,2007年之前,各个会议的论文引用数量一直呈现上升的趋势,2007年之后,论文的引用数量在不断下降,2007年是引用数量的峰值。依照真实数据分析出的结果,本发明将目标窗口年限确定为两年。
步骤2:根据会议论文的引用特点,确定使用马尔可夫模型对会议网络进行建模,并结合随机游走模型思想,根据不同的记忆度进行建模,构建出的引用流模型分别对应于零阶马尔可夫模型和一阶马尔可夫模型。
2.1)对会议之间进行引用流建模,首先要将会议的文章级引用数据进行汇总,之后对随机游走的网络流进行建模。本发明依照不同的记忆度对网络中的引文数据进行聚合,根据不同的记忆度实现引用流模型的构建,构建出的引用流模型分别对应于零阶和一阶马尔可夫模型。本发明将要评估的年份称为源年,引用目标窗口年中源年会议论文所引用到的年份称为目标年,值得注意的是,本方法只考虑同一领域会议之间的引用。图1和图2是两种模型的随机游走过程示意图。
2.2)在零阶马尔可夫网络上的随机游走是无记忆的,下一步并不依赖于现在所访问的会议,所以对于零阶马尔可夫模型,需要计算发表在源年会议上的文章对发表在目标年会议上的文章的引用数量。为了构建会议网络,我们将这些引文数汇总在被引文章所在的会议上,也就是说,每当一篇发表在源年会议j上的文章对一篇发表在目标年会议k上的文章存在引用关系j->k时,就对被引用的会议k的权重加1,W(k)->W(k)+1,跳转到k会议的概率计算公式如下:
其中π(0)(k)为会议k的访问概率,W(k)为会议k得到的引用数量,∑k W(k)为所有会议得到的总引用数量。
2.3)一阶马尔可夫模型的随机游走过程是有一步记忆的,也就是说下一步的访问与现在所访问的会议相关。对于一阶马尔可夫模型,引用数是将引文和被引文成对记录在被引用的会议上。也就是说,每当一篇发表在源年会议j上的文章对一篇发表在目标年会议k上的文章存在引用关系j->k时,就对引用和被引会议之间的链接权重加1,W(j->k)->W(j->k)+1。
Step1:根据如下公式得到从会议j跳转到会议k的概率:
其中p(j→k)为会议j跳转到会议k的概率,W(j→k)为会议k从会议j处得到的引用数量,∑k W(j→k)为会议k从所有会议处得到的总引用数量。
Step2:根据如下公式得到会议k的访问概率:
其中π(1)(k)为会议k的访问概率,为所有会议跳转到会议k概率之和,p(k)为零阶马尔可夫模型中访问会议k的概率,α和(1-α)是为了解决起始点问题而引入的变量,1-α=0.15。
步骤3:根据1)中得到的目标窗口年限统计出两种引用流模型所需的引用量,并且分别考虑有自引和无自引的情况。
在零阶马尔可夫网络上的随机游走是无记忆的,下一步并不依赖于现在所访问的会议,所以对于人工智能领域39个会议的基于零阶马尔可夫模型的评估,只需要计算每个会议在2013-2014年所有会议文章所获得引用的总量即可。本发明将存在自引用和不存在自引用的两种情况均进行实验,存在自引用的总引用量为826,不存在自引用的总引用量为416。
在一阶马尔可夫网络上的随机游走具有一步记忆,下一步访问的会议依赖于现在所访问的会议,所以对于人工智能领域39个会议的基于一阶马尔可夫模型的评估,在零阶马尔可夫模型评估分数计算出的基础上,还需要计算出每个2015年会议对2013-2014年其他会议的分别引用量以及这些分别引用量之和,同样计算有自引和无自引两种情况。
得出零阶模型和一阶模型的计算结果后,对39个人工智能会议进行排名并与CCF列表中的会议排名进行分段匹配,图4和图5给出了有自引和无自引的匹配度,零阶模型和一阶模型的结果分别列出。
通过以上步骤,我们可以得到所有会议的影响力的值并进行排名。
步骤4:通过与CCF列表进行比对从而对评估结果进行检验。图4、图5中的结果显示,无论是零阶马尔可夫模型还是一阶马尔可夫模型,无自引模型评估结果的匹配度比有自引模型评估结果的匹配度要高,这说明自引用确实可以成为会议想提高自身排名的虚假手段,有目的的通过让后续发表会议论文的作者引用本会议之前发表过文章的方法使该会议的论文排名上升。图6为一阶马尔可夫模型无自引评估分数的计算过程,可以观察出,一阶马尔可夫模型经过多次迭代后评估结果趋近于稳定,而零阶马尔可夫模型的结果并不具备稳定性,所以一阶模型相比于零阶模型更具有鲁棒性,且从匹配度可以看出,本发明提出的评估方法在会议评估方面具有可行性。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!