基于脑电信号的词向量计算方法及装置与流程
本发明属于自然语言处理技术领域,尤其涉及一种基于脑电信号的词向量计算方法及装置。
背景技术:
在自然语言处理任务中,通常使用词向量作为原有文本中的词语的表示,以便数值化的机器学习算法能应用于文本数据。词向量模型的基本思想是:通过大量语料库训练,将某种语言中的每个词语映射成一个固定长度的向量,一般而言这个长度远小于该语言词典的大小,通常在几十到几百维。所有这些向量构成了词向量空间,而每一个向量就可为该空间中的一个点。在这个空间上引入“距离”的度量,就可以据词向量的距离来判断对应词语之间在句法、语义上的相似性。传统的词向量计算方法都是试图通过当前文本向量来尽可能准确地预测其上下文的向量来优化其表示的。
在传统的词向量计算过程中,通过当前文本预测上下文是训练的首要目标。这种方法的主要缺陷有以下三点:
1、只考虑到了词语的语法级别的属性,没有考虑到词语语义级别的属性,故通常训练得到的词向量只能表达词语之间较为浅层的关系;
2、缺乏对人类语言认知过程的建模,忽略了重要的认知神经科学以及心理学特征;
3、由于人类语言认识机制的复杂性,通过简单预测上下文得到的词向量无法体现不同自然语言处理任务的特性,普适性较差。
技术实现要素:
本发明的目的在于提供一种基于脑电信号的词向量计算方法及装置,旨在提高词向量计算的准确性。
本发明是这样实现的,一种基于脑电信号的词向量计算方法,所述方法包括以下步骤:
步骤S1,收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;
步骤S2,将所述连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;
步骤S3,将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组的词向量表示为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型。
本发明的进一步的技术方案是,所述步骤S1包括以下子步骤:
步骤S11,收集文本语料库,所述文本语料库中的语料为句子或者篇章级别;
步骤S12,去除所述文本语料库中长度超过第一预设值或长度小于第二预设值的语料,得到预处理语料;
步骤S13,将所述预处理语料进行分词处理得到词;
步骤S14,利用组块分析技术,将所述词转化为词组,得到以连续短语格式的语料。
本发明的进一步的技术方案是,所述步骤S3包括以下子步骤:
步骤S31,对采集到的脑电信号进行降噪处理,得到降噪后的脑电信号;
步骤S32,对所述降噪后的脑电信号进行空间投影和降维处理;
步骤S33,将所述预处理语料中的所有词组初始化为词向量表示;
步骤S34,遍历所述预处理语料中的所有词组,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上下文的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,根据预测误差调整当前词组的词向量表示,其中,所述实际脑电信号为标注者阅读所述上下文时的脑电信号;重复本步骤,直至预测误差小于预设阈值。
本发明的进一步的技术方案是,所述步骤S31包括:
对所述采集到的脑电信号进行处理,得到信噪比高于第三预设值的脑电信号;
所述步骤S32包括:
使用共空间模式算法对所述信噪比高于第三预设值的脑电信号进行空间投影和降维,得到维度低于第四预设值的脑电信号。
本发明的进一步的技术方案是,对所述采集到的脑电信号进行降噪处理采用FASTICA算法。
本发明还提供了一种基于脑电信号的词向量计算装置,所述装置包括:
收集模块,用于收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;
采集模块,用于将所述连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;
构建模块,用于将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组的词向量表示为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型。
本发明的进一步的技术方案是,所述收集模块包括:
收集单元,用于收集文本语料库,所述文本语料库中的语料为句子或者篇章级别;
预处理单元,用于去除所述文本语料库中长度超过第一预设值或长度小于第二预设值的语料,得到预处理语料;
分词单元,用于将所述预处理语料进行分词处理得到词;
转化单元,用于利用组块分析技术,将所述词转化为词组,得到以连续短语格式的语料。
本发明的进一步的技术方案是,所述构建模块包括:
降噪单元,用于对采集到的脑电信号进行降噪处理,得到降噪后的脑电信号;
降维单元,用于对所述降噪后的脑电信号进行空间投影和降维处理;
初始化单元,用于将所述预处理语料中的所有词组初始化为词向量表示;
构建单元,用于遍历所述预处理语料中的所有词组,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上下文的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,根据预测误差调整当前词组的词向量表示,其中,所述实际脑电信号为标注者阅读所述上下文时的脑电信号;重复本步骤,直至预测误差小于预设阈值。
本发明的进一步的技术方案是,所述降噪单元还用于,对所述采集到的脑电信号进行处理,得到信噪比高于第三预设值的脑电信号;
所述降维单元还用于,使用共空间模式算法对所述信噪比高于第三预设值的脑电信号进行空间投影和降维,得到维度低于第四预设值的脑电信号。
本发明的进一步的技术方案是,所述降噪模块还用于采用FASTICA算法对所述采集到的脑电信号进行降噪处理。
本发明的有益效果是:本发明提供的基于脑电信号的词向量计算方法及装置,通过上述方案:收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型,提高了词向量计算的准确性。
附图说明
图1是本发明基于脑电信号的词向量计算方法第一实施例的流程示意图;
图2是本发明基于脑电信号的词向量计算方法第二实施例步骤S1的细化流程示意图;
图3是本发明基于脑电信号的词向量计算方法第三实施例步骤S3的细化流程示意图;
图4是本发明基于脑电信号的词向量计算装置第一实施例的功能模块示意图;
图5是本发明基于脑电信号的词向量计算装置第二实施例采集模块的细化功能模块示意图;
图6是本发明基于脑电信号的词向量计算装置第三实施例构建模块的细化功能模块示意图。
附图标记:
收集模块-10:收集单元-101;预处理单元-102;分词单元-103;转化单元-104;
采集模块-20;
构建模块-30:降噪单元-301;降维单元-302;初始化单元-303;构建单元-304。
具体实施方式
本发明实施例的解决方案主要是:收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;将所述连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型。
请参照图1,图1是本发明基于脑电信号的词向量计算方法第一实施例的流程示意图,如图1所示,本发明基于脑电信号的词向量计算方法第一实施例包括以下步骤:
步骤S1,收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;
具体地,语料是指在语言的实际使用过程中真实出现过的语言材料,语料通常储存在语料库中,语料库是以电子计算机为载体承载语料的数据库,真实语料一般需要经过分析和处理才能够成为有用的资源。
目前,中国语料库主要为现代汉语通用语料库、《人民日报》标注语料库、用于语言教学和研究的现代汉语语料库、面向语音信息处理的现代汉语语料库等,人们在需要语料时,可以从这些建好的语料库中直接获取语料。当然,本发明的实现还可以从其他的语料库中获取语料,比如获取互联网网页中的语料。
由于词向量的训练是以词组为训练数据,而语料库中的语料通常为句子或者文章,因此,需要对语料进行处理,得到以词组为单位的连续短语格式的语料。例如,语料为句子“我爱北京,北京是我国的首都”,将其处理为以词组为单位的连续短语为“我/爱/北京/北京/是/我国/的/首都”。
步骤S2,将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;其中,标注者为阅读以连续短语格式呈现的语料的用户。
具体地,本发明是通过脑电信号表示词向量,在标注者阅读以连续短语格式呈现的语料时,需佩戴脑电信号采集装置,以获得标注者阅读每一词组时的脑电信号。获得标注者阅读每一词组时的脑电信号后,将采集到的脑电信号与相应词组成对存储。
步骤S3,将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组的词向量表示为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型。
具体地,可以将所述预处理语料中的所有词组初始化为词向量表示;然后,遍历所述预处理语料中的所有词组,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上下文的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,根据预测误差调整当前词组的词向量表示,其中,所述实际脑电信号为标注者阅读所述上下文时的脑电信号;重复本步骤,直至预测误差小于预设阈值。
本实施例中上下文窗口可以为三个,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上文三个词组及下文三个词组的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,对每次产生的误差反向传播,调整当前词组的向量表示。
本实施例通过上述方案:收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型,提高了词向量计算的准确性。
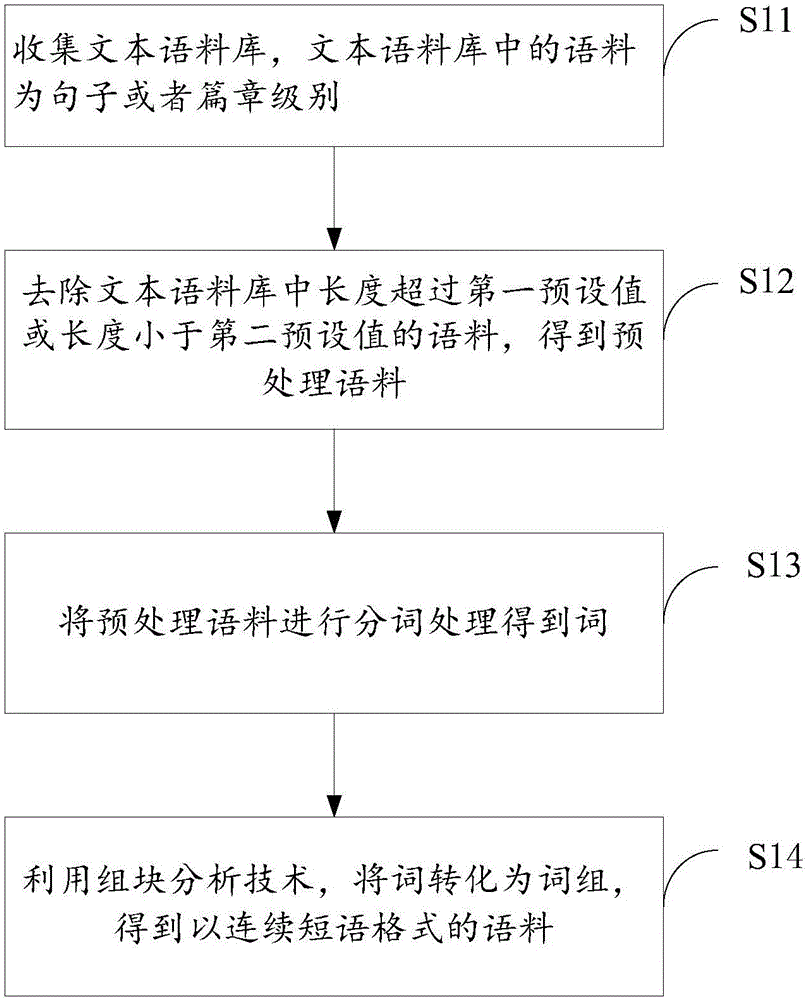
作为本发明的第二实施例,请参照图2,图2是基于图1描述的基于脑电信号的词向量计算方法中的步骤S1的细化流程示意图。所述步骤S1,收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料的步骤可以包括:
步骤S11,收集文本语料库,文本语料库中的语料为句子或者篇章级别;
步骤S12,去除文本语料库中长度超过第一预设值或长度小于第二预设值的语料,得到预处理语料;
步骤S13,将预处理语料进行分词处理得到词;
步骤S14,利用组块分析技术,将词转化为词组,得到以连续短语格式的语料。
具体地,收集到的文本语料库中的语料通常是句子或者文章,由于句子的长度可能过长或过短,因此,可以根据经验预设一个句子长度范围值,去除语料库中长度超过第一预设值或者长度小于第二预设值的语料,得到预处理语料,其中,第一预设值及第二预设值可以通过经验设定。
由于词向量的训练是以词组为训练数据,而语料库中的语料通常为句子或者文章,因此,需要对语料进行处理,得到以词组为单位的连续短语格式的语料。例如,语料为句子“我爱北京,北京是我国的首都”,将其处理为以词组为单位的连续短语为“我/爱/北京/北京/是/我国/的/首都”。
在本实施例中,可以先将预处理语料进行分词处理,得到词,然后采用组块分析技术,将词转化为词组,得到以连续短语格式的语料。
分词处理主要是依赖于分词词库实现的,分词词库的质量直接决定了分词处理的质量,目前通常采用的分词词库是通过《新华词典》或者其他类似的出版书籍为基础而建立的词库,在本实施例中,也可以依赖其他的分词词库来进行分词处理。
语言组块分析技术是浅层语法分析中常用的技术,语言组块技术能根据预定的模型将句子分解为组分,这些组分主要是短语以及较长的词组,从而使得计算机对于句子的理解可以从单个字、词的层面上升到信息量更大的短语、词组,更加接近自然语言。
作为本发明的第三实施例,请参照图3,图3是基于图1描述的基于脑电信号的词向量计算方法中的步骤S3的细化流程示意图。所述步骤S3,将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型步骤可以包括:
步骤S31,对采集到的脑电信号进行降噪处理,得到降噪后的脑电信号;
采集标注者阅读以连续短语格式呈现的语料时的脑电信号的过程中,容易受到设备噪声信号及肌电信号和眼电信号等因素的影响,因此需要对标注者阅读以连续短语格式呈现的语料时的脑电信号进行去噪处理,得到降噪后的高信噪比的脑电信号。
信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或称为信息),并且这种信号并不随原信号的变化而变化。信噪比的计量单位是dB,其计算方法是10lg(PS/PN),其中PS和PN分别代表信号和噪声的有效功率,信噪比越高,说明噪声越小。
在本实施例中,采用FASTICA算法将采集到的标注者阅读以连续短语格式呈现的语料时的脑电信号投影为多个独立分量,再采用频谱特征或者高阶交叉特征等判别噪音,然后从采集到的标注者阅读以连续短语格式呈现的语料时的脑电信号中除去噪音分量,得到降噪后的高信噪比的脑电信号,本实施例中降噪后的高信噪比的脑电信号为优选为信噪比高于15db的脑电信号。
独立成分分析(简称ICA)是非常有效的数据分析工具,它主要用来从混合数据中提取出原始的独立信号。它作为信号分离的一种有效方法而受到广泛的关注。在诸多ICA算法中,固定点算法(简称FASTICA)以其收敛速度快、分离效果好被广泛应用于信号处理领域。该算法能很好地从观测信号中估计出相互统计独立的、被未知因素混合的原始信号。
步骤S32,对降噪后的脑电信号进行空间投影和降维处理;
具体地,本实施例中,使用共空间模式算法(CSP)将不同信道的降噪后的高信噪比的脑电信号根据其空间位置进行投影和降维,得到降维后的脑电信号,本实施例中降维后的脑电信号优选为维度低于300维度的脑电信号。
步骤S33,将预处理语料中的所有词组初始化为词向量表示;
步骤S34,遍历预处理语料中的所有词组,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上下文的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,根据预测误差调整当前词组的词向量表示,其中,所述实际脑电信号为标注者阅读所述上下文时的脑电信号;重复本步骤,直至总体预测误差小于预设阈值。
本实施例中上下文窗口可以为三个,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上文三个词组及下文三个词组的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,对每次产生的误差反向传播,调整当前词组的向量表示,直至预设误差阈值可以根据经验设定为10-5。
综上所述,本发明通过上述方案,收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型,提高了词向量计算的准确性。
与上述基于脑电信号的词向量计算方法相对应的,本发明还提供了基于脑电信号的词向量计算装置。
请参照图4,图4是本发明基于脑电信号的词向量计算装置第一实施例的功能模块示意图,如图4所示,本发明基于脑电信号的词向量计算装置第一实施例包括:收集模块10、采集模块20及构建模块30。
其中,收集模块10用于收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;
具体地,语料是指在语言的实际使用过程中真实出现过的语言材料,语料通常储存在语料库中,语料库是以电子计算机为载体承载语料的数据库,真实语料一般需要经过分析和处理才能够成为有用的资源。
目前,中国语料库主要为现代汉语通用语料库、《人民日报》标注语料库、用于语言教学和研究的现代汉语语料库、面向语音信息处理的现代汉语语料库等,人们在需要语料时,可以从这些建好的语料库中直接获取语料。当然,本发明的实现还可以从其他的语料库中获取语料,比如获取互联网网页中的语料。
由于词向量的训练是以词组为训练数据,而语料库中的语料通常为句子或者文章,因此,需要对语料进行处理,得到以词组为单位的连续短语格式的语料。例如,语料为句子“我爱北京,北京是我国的首都”,将其处理为以词组为单位的连续短语为“我/爱/北京/北京/是/我国/的/首都”。
采集模块20用于将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号。
具体地,本发明是通过脑电信号表示词向量,在标注者阅读以连续短语格式呈现的语料时,需佩戴脑电信号采集装置,以获得标注者阅读每一词组时的脑电信号。获得标注者阅读每一词组时的脑电信号后,将采集到的脑电信号与相应词组成对存储。
构建模块30用于将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型。
本实施例中上下文窗口可以为三个,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上文三个词组及下文三个词组的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,对每次产生的误差反向传播,调整当前词组的向量表示,直至总体预设误差阈值可以根据经验设定为10-5。
本实施例通过上述方案:收集模块10收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;采集模块20将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型,提高了词向量计算的准确性。
作为本发明的第二实施例,请参照图5,图5是基于图4描述的基于脑电信号的词向量计算装置中的收集模块10的细化功能模块示意图。在本实施例中,收集模块10可以包括:收集单元101、预处理单元102、分词单元103及转化单元104。
其中,收集单元101用于收集文本语料库,所述文本语料库中的语料为句子或者篇章级别;
预处理单元102用于去除文本语料库中长度超过第一预设值或长度小于第二预设值的语料,得到预处理语料,其中,第一预设值及第二预设值可以通过经验设定。
分词单元103用于将预处理语料进行分词处理得到词;
转化单元104用于利用组块分析技术,将词转化为词组,得到以连续短语格式的语料。
具体地,收集模块10收集到的文本语料库中的语料通常是句子或者文章,由于句子的长度可能过长或过短,因此,可以根据经验预设一个句子长度范围值,去除语料库中长度超过第一预设值或者长度小于第二预设值的语料,得到预处理语料。
由于词向量的训练是以词组为训练数据,而语料库中的语料通常为句子或者文章,因此,需要对语料进行处理,得到以词组为单位的连续短语格式的语料。例如,语料为句子“我爱北京,北京是我国的首都”,将其处理为以词组为单位的连续短语为“我/爱/北京/北京/是/我国/的/首都”。
在本实施例中,可以先通过预处理单元102将预处理语料进行分词处理,得到词,然后通过转化单元104采用组块分析技术,将词转化为词组,得到以连续短语格式的语料。
分词处理主要是依赖于分词词库实现的,分词词库的质量直接决定了分词处理的质量,目前通常采用的分词词库是通过《新华词典》或者其他类似的出版书籍为基础而建立的词库,在本实施例中,也可以依赖其他的分词词库来进行分词处理。
语言组块分析技术是浅层语法分析中常用的技术,语言组块技术能根据预定的模型将句子分解为组分,这些组分主要是短语以及较长的词组,从而使得计算机对于句子的理解可以从单个字、词的层面上升到信息量更大的短语、词组,更加接近自然语言。
作为本发明的第三实施例,请参照图6,图6是基于图4描述的基于脑电信号的词向量计算装置中的构建模块30的细化功能模块示意图。在本实施例中,构建模块30可以包括:降噪单元301、降维单元302、初始化单元303及构建单元304。
其中,降噪单元301用于对采集到的脑电信号进行降噪处理,得到降噪后的脑电信号;
采集标注者阅读以连续短语格式呈现的语料时的脑电信号的过程中,容易受到设备噪声信号及肌电信号和眼电信号等因素的影响,因此需要对标注者阅读以连续短语格式呈现的语料时的脑电信号进行去噪处理,得到降噪后的高信噪比的脑电信号。
信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或称为信息),并且这种信号并不随原信号的变化而变化。信噪比的计量单位是dB,其计算方法是10lg(PS/PN),其中PS和PN分别代表信号和噪声的有效功率,信噪比越高,说明噪声越小。
在本实施例中,降噪单元301采用FASTICA算法将采集到的标注者阅读以连续短语格式呈现的语料时的脑电信号投影为多个独立分量,再采用频谱特征或者高阶交叉特征等判别噪音,然后从采集到的标注者阅读以连续短语格式呈现的语料时的脑电信号中除去噪音分量,得到降噪后的高信噪比的脑电信号,本实施例中降噪后的高信噪比的脑电信号优选为信噪比高于15db的脑电信号。
独立成分分析(简称ICA)是非常有效的数据分析工具,它主要用来从混合数据中提取出原始的独立信号。它作为信号分离的一种有效方法而受到广泛的关注。在诸多ICA算法中,固定点算法(简称FASTICA)以其收敛速度快、分离效果好被广泛应用于信号处理领域。该算法能很好地从观测信号中估计出相互统计独立的、被未知因素混合的原始信号。
降维单元302用于对降噪后的脑电信号进行空间投影和降维处理;
具体地,本实施例中,降维单元302使用共空间模式算法(CSP)将不同信道的降噪后的高信噪比的脑电信号根据其空间位置进行投影和降维,得到降维后的脑电信号,本实施例中降维后的脑电信号优选为维度低于300维度的脑电信号。
初始化单元303用于将预处理语料中的所有词组初始化为词向量表示;
构建单元304用于遍历预处理语料中的所有词组,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上下文的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,根据预测误差调整当前词组的词向量表示,其中,实际脑电信号为标注者阅读上下文时的脑电信号;重复本步骤,直至预测误差小于预设阈值。
本实施例中上下文窗口可以为三个,以当前词组的词向量表示为特征,使用神经网络回归模型预测其上文三个词组及下文三个词组的脑电信号,将预测的上下文的脑电信号与实际脑电信号进行对比,获取预测误差,对每次产生的误差反向传播,调整当前词组的向量表示,直至总体预设误差阈值可以根据经验设定为10-5。
综上所述,本发明通过上述方案,收集模块10收集文本语料库,对文本语料库中的语料进行处理,得到以词组为单位的连续短语格式的语料;采集模块20将连续短语格式的语料呈现给标注者,供标注者阅读,采集标注者阅读每一词组时的脑电信号;构建模块30将采集到的词组对应的脑电信号作为预测目标,训练词向量,以当前词组为特征预测其上下文的脑电信号,构建基于脑电信号的词向量表示模型,提高了词向量计算的准确性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!