文本表示方法及系统与流程
本发明涉及自然语言处理技术领域,尤其涉及一种文本表示方法及系统。
背景技术:
随着基于深度神经网络的表示学习技术的发展,自然语言处理领域很多问题都归结于文本的表示学习,即:如何通过表示学习的相关方法,将文本片段,如词语、短语、句子、篇章等表示为一个连续的低维向量。而在上述问题之中,词语作为语言最基本的片段,如何对其进行连续的低维向量表示则成为了自然语言处理中最基本的问题之一。
目前,关于词语的连续低维向量表示(简称为词向量)在自然语言处理领域有着广泛的应用,如:利用词向量以及词的序列关系,对一个句子进行基于词向量的建模,即学习获得句子的连续低维表示;利用词向量形成的序列,建模多个句子,甚至是不同语言的句子之间词语的对应关系,服务于问答系统、机器翻译系统等自然语言处理领域的应用系统;利用组成短语的词语的词向量,进行短语级别的语义推断,自动化判别短语所表达的语义等等。
传统的词向量表示方法很多,例如:用上下文词语预测当前词语进行词向量建模的连续词袋模型(Continues Bag Of Words,CBOW),以及利用当前词语对上下文进行预测的跳跃多元文法(Skip n-gram)等等。但是,上述方法大多数利用结构语言学中的上下文相关假设,即词语的含义由其上下文决定,来进行词语的词向量学习。在这个过程中,其忽视了语言的主体,即人在语言中所起的作用,具体而言,其缺点在于:
1、在对词语进行连续低维表示的过程中,忽视了社交因素,没有表现出词语的社交属性;
2、在对词语进行连续低维表示的过程中,忽视了其评论对象的因素,没有表现出词语的评论习惯属性。
技术实现要素:
本发明的主要目的在于提出一种文本表示方法及系统,旨在提高文本表示学习的精准性。
为实现上述目的,本发明提供的一种文本表示方法,包括:
步骤S10,获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;其中,所述词语发布者低维连续向量表示的维度不高于300维度,所述词语评论对象低维连续向量表示的维度不高于300维度;
步骤S20,使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维空间表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;
步骤S30,将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的文本分类模型。
可选地,所述步骤S10包括:
步骤S101,统计所述文本中每个词语对应的发布者信息,得到每个词语发布者使用频数,并且将所述发布者使用频数作为发布者-词语边的权重;
步骤S102,统计所述文本中每个词语对应的评论对象,得到每个词语的评论对象使用频数,并且将所述评论对象使用频数作为评论对象-词语边的权重;
步骤S103,统计所述文本中每个词语出现在哪些词语的上下文中,得到每个词语的上下文出现频数,并且将所述上下文出现频数作为词语-词语边的权重;
步骤S104,基于得到的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,构建基于主体间性的异质网络。
可选地,所述步骤S20包括:
步骤S201,基于所述主体间性的异质网络中的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,优化预设的损失函数,所述损失函数为:
其中,wij表示节点i和节点j之间的边的权重,logp(vj|vi)为两个节点之间的条件概率,定义如下:
其中,ui表示节点i的低维连续向量表示,表示节点j的相邻节点的低维连续向量表示。
可选地,所述步骤S30包括:
采用旁路链接的方法,将所述发布者低维连续向量表示和所述评论对象低维连续向量表示链接到学习获得的文本表示结果中。
可选地,所述步骤S30包括:
步骤S301,采用文本建模方式学习文本的低维连续向量表示;
步骤S302,对学习获得的文本低维连续向量表示,顺序的接入所述发布者低维连续向量表示和所述评论对象低维连续向量表示,得到对应的表示特征;
步骤S303,将得到的对应的表示特征输入分类模型中,最终得到相应的文本分类模型。
本发明实施例还提出一种文本表示系统,包括:
构建模块,用于获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;
表示学习模块,用于使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;其中,所述词语发布者低维连续向量表示的维度不高于300维度,所述词语评论对象低维连续向量表示的维度不高于300维度;
文本分类模块,用于将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的词向量分类模型。
可选地,所述构建模块,还用于统计所述文本中每个词语对应的发布者信息,得到每个词语发布者使用频数,并且将所述发布者使用频数作为发布者-词语边的权重;统计所述文本中每个词语对应的评论对象,得到每个词语的评论对象使用频数,并且将所述评论对象使用频数作为评论对象-词语边的权重;统计所述文本中每个词语出现在哪些词语的上下文中,得到每个词语的上下文出现频数,并且将所述上下文出现频数作为词语-词语边的权重;基于得到的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,,构建基于主体间性的异质网络。
可选地,所述表示学习模块,还用于基于所述主体间性的异质网络中的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,优化预设的损失函数,所述损失函数为:
其中,wij表示节点i和节点j之间的边的权重,logp(vj|vi)为两个节点之间的条件概率,定义如下:
其中,ui表示节点i的低维连续向量表示,表示节点j的相邻节点的低维连续向量表示。
可选地,所述文本分类模块,还用于采用旁路链接的方法,将所述发布者低维连续向量表示和所述评论对象低维连续向量表示链接到学习获得的文本表示结果中。
可选地,所述文本分类模块,还用于采用文本建模方式学习文本的低维连续向量表示;对学习获得的文本低维连续向量表示,顺序的接入所述发布者低维连续向量表示和所述评论对象低维连续向量表示,得到对应的表示特征;将得到的对应的表示特征输入分类模型中,最终得到相应的文本分类模型。
本发明提出的一种文本表示方法及系统,获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的文本分类模型,该方案在对词语进行连续低维表示的过程中,综合考虑词语的社交属性以及词语的评论习惯属性,即考虑人在语言中所起的作用,利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,从而提高了词向量表示学习的精准性,获得更加准确的文本分类结果。
附图说明
图1是本发明文本表示方法实施例的流程示意图;
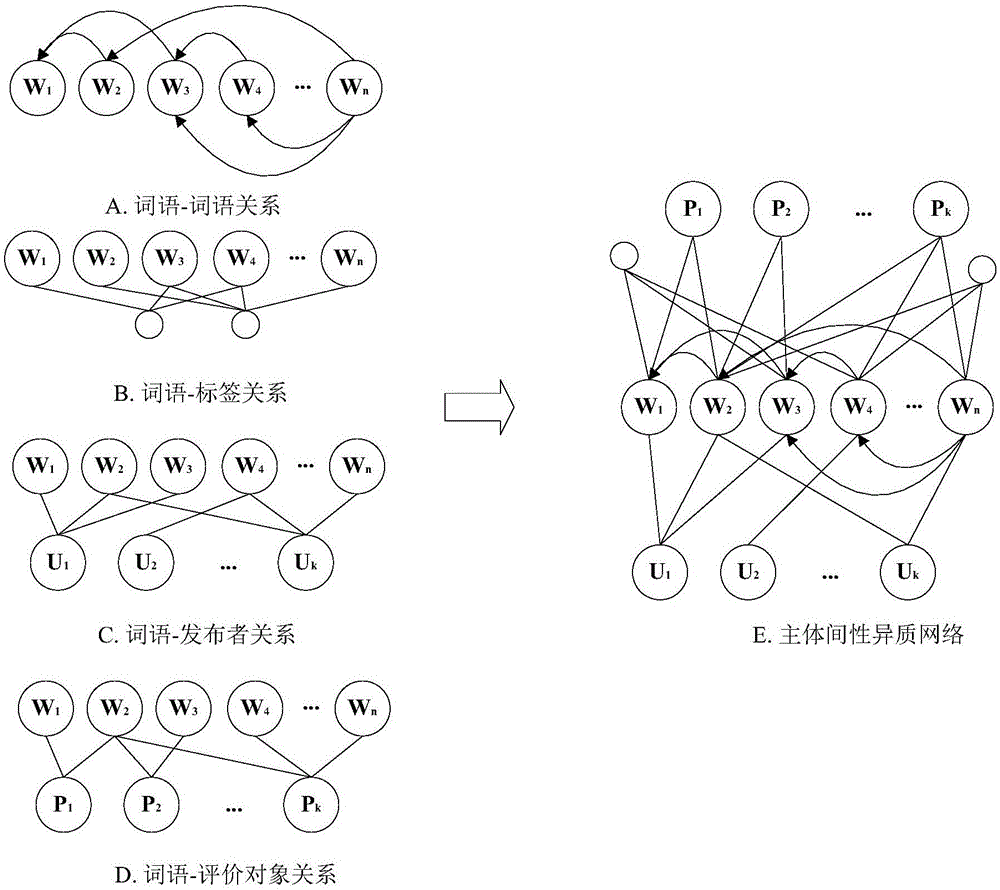
图2是本发明实施例中基于主体间性的异质网络构建示意图;
图3是本发明实施例中结合表示学习的文本分类示意图;
图4是本发明文本表示系统实施例的结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
由于现有技术中,在对词语进行连续低维表示的过程中,大多数利用结构语言学中的上下文相关假设,即词语的含义由其上下文决定,来进行词语的词向量学习。在这个过程中,其忽视了语言的主体,即人在语言中所起的作用,从而降低了词向量表示学习的精准性。
为此,本发明提出一种解决方案,综合考虑词语的社交属性以及词语的评论习惯属性,即考虑人在语言中所起的作用,利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,从而提高词向量表示学习的精准性。
具体地,如图1所示,本发明实施例提出一种文本表示方法,包括:
步骤S10,获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;
本实施例中,主要利用文本中的发布者信息、评论对象信息等建立基于主体间性的异质网络,在对词语进行连续低维向量表示的过程中,体现出语言主体—人的作用,结合词语的社交属性和评论习惯属性,以提高词向量表示学习的精准性。
具体地,结合图2所示,在建立基于主体间性的异质网络时,需要汇总文本中词语-词语关系、词语-标签关系、词语-发布者关系、词语-评论对象关系,具体构件过程包括如下步骤:
步骤S101,统计所述文本中每个词语对应的发布者信息,得到每个词语发布者使用频数,并且将所述发布者使用频数作为发布者-词语边的权重;
其中,所述文本中每个词语对应的发布者信息,指所述文本中的每个词语被哪些发布者使用过。
步骤S102,统计所述文本中每个词语对应的评论对象,得到每个词语的评论对象使用频数,并且将所述评论对象使用频数作为评论对象-词语边的权重;
其中,所述文本中每个词语对应的评论对象,指所述文本中的每个词语被用于评论哪些对象。
步骤S103,统计所述文本中每个词语出现在哪些词语的上下文中,得到每个词语的上下文出现频数,并且将所述上下文出现频数作为词语-词语边的权重;
步骤S104,基于得到的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,构建基于主体间性的异质网络。
步骤S20,使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;其中,所述词语发布者低维连续向量表示的维度不高于300维度,所述词语评论对象低维连续向量表示的维度不高于300维度;
具体地,包括步骤S201,基于所述主体间性的异质网络中的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,优化预设的损失函数,所述损失函数可以表示如下:
其中,wij表示节点i和节点j之间的边的权重,logp(vj|vi)为两个节点之间的条件概率,定义如下:
其中,ui表示节点i的低维连续向量表示,表示节点j的相邻节点的低维连续向量表示。
由此,通过对上述损失函数的优化,可以得到发布者低维连续向量表示、评论对象的低维连续向量表示等。
步骤S30,将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的词向量分类模型。
本实施例中,采用旁路链接的方法,将所述发布者低维连续向量表示和所述评论对象低维连续向量表示链接到学习获得的文本表示结果中。
具体地,如图3所示,其处理方法包括如下步骤:
步骤S301,采用文本建模方式学习文本的低维连续向量表示;
步骤S302,对学习获得的文本低维连续向量表示,顺序的接入所述发布者低维连续向量表示和所述评论对象的低维连续向量表示,得到对应的表示特征;
步骤S303,将得到的对应的表示特征输入分类模型中,最终得到相应的词向量分类模型。由于利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,使得基于此表示学习的结果,可以获得更加准确的文本分类结果。
本实施例通过上述方案,获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的词向量分类模型,该方案在对词语进行连续低维表示的过程中,综合考虑词语的社交属性以及词语的评论习惯属性,即考虑人在语言中所起的作用,利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,从而提高了词向量表示学习的精准性,获得更加准确的文本分类结果。
如图4所示,本发明实施例还提出一种文本表示系统,包括:构建模块201、表示学习模块202及文本分类模块203,其中:
构建模块201,用于获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;
表示学习模块202,用于使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;其中,所述词语发布者低维连续向量表示的维度不高于300维度,所述词语评论对象低维连续向量表示的维度不高于300维度;
文本分类模块203,用于将所述发布者低维连续向量表示及评论对象低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的词向量分类模型。
进一步地,所述构建模块201,还用于统计所述文本中每个词语对应的发布者信息,得到每个词语发布者使用频数,并且将所述发布者使用频数作为发布者-词语边的权重;统计所述文本中每个词语对应的评论对象,得到每个词语的评论对象使用频数,并且将所述评论对象使用频数作为评论对象-词语边的权重;统计所述文本中每个词语出现在哪些词语的上下文中,得到每个词语的上下文出现频数,并且将所述上下文出现频数作为词语-词语边的权重;基于得到的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,构建基于主体间性的异质网络
所述表示学习模块202,还用于基于所述主体间性的异质网络中的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,优化预设的损失函数。
所述文本分类模块203,还用于采用旁路链接的方法,将所述发布者低维连续向量表示和所述评论对象低维连续向量表示链接到学习获得的文本表示结果中。
具体地,本实施例中,主要利用文本中的发布者信息、评论对象信息等建立基于主体间性的异质网络,在对词语进行连续低维向量表示的过程中,体现出语言主体—人的作用,结合词语的社交属性和评论习惯属性,以提高词向量表示学习的精准性。
具体地,结合图2所示,在建立基于主体间性的异质网络时,需要汇总文本中词语-词语关系、词语-标签关系、词语-发布者关系、词语-评论对象关系,具体构件过程如下:
首先统计文本中每个词语对应的发布者信息,即统计每个词语被哪些发布者使用过,得到每个词语发布者使用频数,并且将所述发布者使用频数作为发布者-词语边的权重;
统计所述文本中每个词语对应的评论对象,即统计每个词语被用于评论哪些对象,得到每个词语的评论对象使用频数,并且将所述评论对象使用频数作为评论对象-词语边的权重;
统计所述文本中每个词语出现在哪些词语的上下文中,得到每个词语的上下文出现频数,并且将所述上下文出现频数作为词语-词语边的权重;
最后,基于得到的各权重,构建基于主体间性的异质网络。
在构建基于主体间性的异质网络后,使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示。
具体地,基于所述主体间性的异质网络中的发布者-词语边的权重、评论对象-词语边的权重及词语-词语边的权重,优化预设的损失函数,所述损失函数可以表示如下:
其中,wij表示节点i和节点j之间的边的权重,logp(vj|vi)为两个节点之间的条件概率,定义如下:
其中,ui表示节点i的低维连续向量表示,表示节点j的相邻节点的低维连续向量表示。
由此,通过对上述损失函数的优化,可以得到发布者低维连续向量表示和评论对象的低维连续向量表示。
最后,将学习获得的发布者低维连续向量表示和评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总。
本实施例中,采用旁路链接的方法,将所述发布者低维连续向量表示和所述评论对象连续向量表示链接到学习获得的文本表示结果中。
具体地,如图3所示,其处理方法如下:
首先,采用文本建模方式学习文本的低维连续向量表示;
然后,对学习获得的文本低维连续向量表示,顺序的接入发布者低维连续向量表示、评论对象的低维连续向量表示,得到对应的表示特征;
最后,将得到的对应的表示特征输入分类模型中,最终得到相应的词向量分类模型,由于利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,使得基于此表示学习的结果,可以获得更加准确的文本分类结果。
本实施例通过上述方案,获取文本中词语的相关属性,利用所述文本中词语的相关属性构建基于主体间性的异质网络,所述相关属性至少包括所述词语的社交属性和评论习惯属性;使用网络节点嵌入的学习算法对所述异质网络中不同属性的节点进行连续低维向量表示,得到词语发布者低维连续向量表示及词语的评论对象的低维连续向量表示;将所述发布者低维连续向量表示及评论对象的低维连续向量表示,应用于文本分类的具体任务并汇总,得到相应的词向量分类模型,该方案在对词语进行连续低维表示的过程中,综合考虑词语的社交属性以及词语的评论习惯属性,即考虑人在语言中所起的作用,利用了发布者信息和评论对象信息,给予了词向量更丰富的语义信息,从而提高了词向量表示学习的精准性,获得更加准确的文本分类结果。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!