一种基于约瑟夫环的大数据随机存取系统和方法与流程
本发明涉及一种大数据随机存取系统和方法,尤其涉及一种基于约瑟夫环的大数据随机存取系统和方法。
背景技术:
随机数算法在当今世界有着非常广泛的应用,例如金融、机械制造、IT网络等等。这也促使人们对随机数算法进行更加深入的研究,目前甚至有提供随机数服务的真随机数网站,利用大气噪声或者某种不可预测的大范围的随机源产生随机数。
在实际应用中,应该采用什么样的随机数算法需要根据系统的不同要求进行选择。对于比较简单的需求,比如网站的随机验证码,使用操作系统自带的伪随机算法就可以满足要求。对于银行密码或数据加密,随机数的要求很严格甚至非常苛刻,一旦出问题有可能导致很大的损失。
同时,大数据分区对随机数算法的要求是很高的,它直接影响着数据存储的分散是否一致。一个好的随机算法可以减少数据的偏离,从而提高查询速度。
随着技术的进步,采用随机性非常高的伪随机算法与一系列复杂的内部逻辑机制相结合的方法产生随机数,可以满足要求。如此,虽然增加了程序的复杂度,但是不需要增加额外的硬件支持,而且在数千甚至上万年内可以保证随机数的不重复性。
因此,本领域需要开发一种采用伪随机算法与内部逻辑机制相结合的系统和方法,以产生数据偏离少且安全保密程度高的随机数。
技术实现要素:
为解决上述现有技术中的问题,本发明提供了一种基于约瑟夫环的大数据随机存取系统和方法。
为实现上述目的,本发明的一种基于约瑟夫环的大数据随机存取方法的具体技术方案如下:
一种基于约瑟夫环的大数据随机存取方法,包括以下步骤:步骤一,在UsbKey密钥的支持下,利用梅森素数旋转随机算法生成随机数和数据切片,并把随机数和数据切片加密存储到数据库;步骤二,在UsbKey密钥的支持下,根据上次关闭参数或者默认启动参数,加载数据库中存储的随机数和数据切片以组合生成随机序列,将生成的随机序列分发给n个随机队列,从数据切片中利用约瑟夫环算法把需要装载的随机序列解密并装载到随机队列中,以增加装载随机度;步骤三,根据加载的数据切片信息监控是否需要加载新的数据切片信息,当随机队列中的数据不足时,触发继续加载数据并分发给随机队列;步骤四,根据获取数据请求中的约瑟夫环参数索引,在Usbkey中获取相应的约瑟夫参数,从随机队列获取数据。
根据本发明的另一方面,还提供了一种基于约瑟夫环的大数据随机存取系统,所述系统包括以下功能模块:随机数产生单元,可在UsbKey密钥的支持下,利用梅森素数旋转随机算法生成随机数和数据切片,并把随机数和数据切片加密存储到数据库中;随机序列装载分发单元,可在UsbKey密钥的支持下,根据上次关闭参数或者默认启动参数,加载数据库中存储的随机数和数据切片以组合生成随机序列,然后将生成的随机序列分发给n个随机队列,从数据切片中利用约瑟夫环算法把需要装载的随机序列解密并装载到随机队列中,以增加装载随机度;监控单元,根据加载的数据切片信息决定是否加载新的数据切片信息,当随机队列中的数据不足时,触发继续加载数据并分发给随机队列,以监控随机队列中的数据;数据获取单元,根据获取数据请求中的约瑟夫环参数索引,在Usbkey中获取相应的约瑟夫参数,从随机队列获取数据。
在本发明的基于约瑟夫环的大数据随机存取系统和方法中,通过将梅森素数旋转随机算法(MT伪随机算法)与约瑟夫环的内部逻辑结合,产生所需随机数,在保证随机数的随机性的同时,满足数据的安全保密,即使系统设计人员也无法获得实际应用中系统产生的随机数信息。
附图说明
图1为本发明的基于约瑟夫环的大数据随机存取系统的结构示意图;
图2为本发明的基于约瑟夫环的大数据随机存取系统的工作流程示意图;
图3示出了本发明的基于约瑟夫环的大数据随机存取方法中的随机序列生成流程;
图4示出了本发明的基于约瑟夫环的大数据随机存取方法中的随机序列装载流程;
图5示出了本发明的基于约瑟夫环的大数据随机存取方法中的监控流程;
图6示出了本发明的基于约瑟夫环的大数据随机存取方法中的获取数据流程。
具体实施方式
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明的基于约瑟夫环的大数据随机存取系统和方法做进一步详细描述。
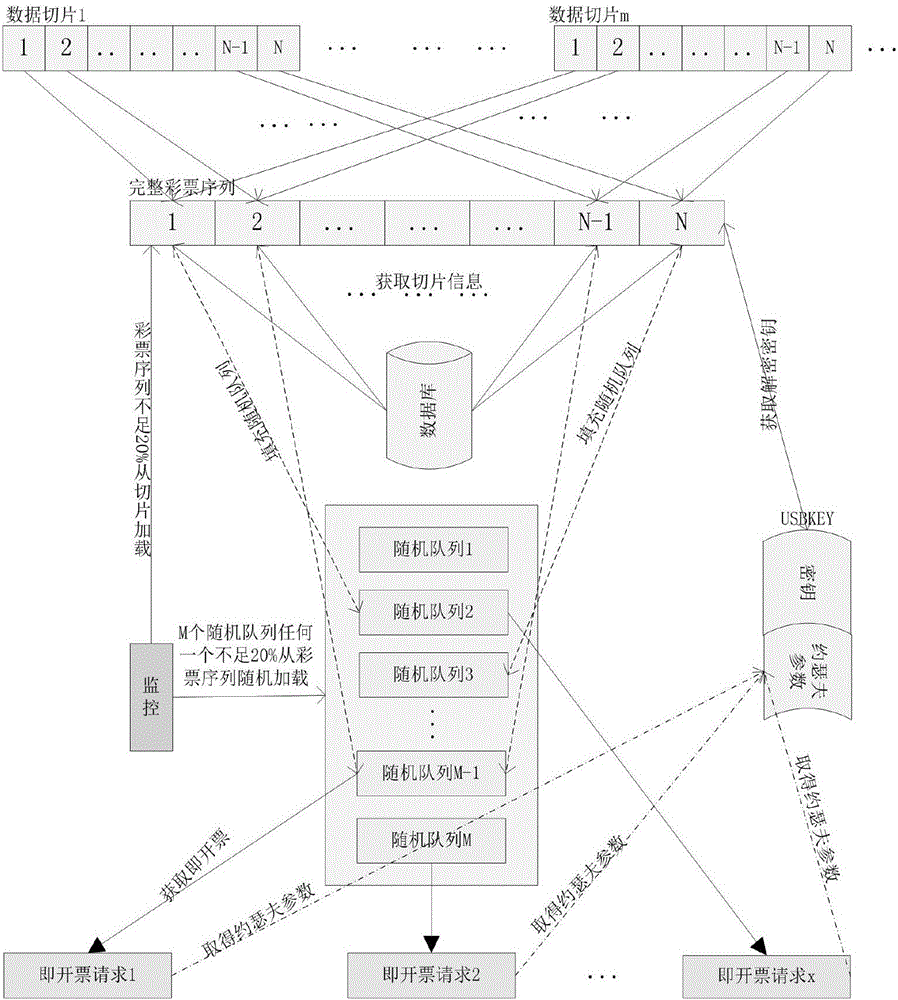
如图1-2所示,本发明的基于约瑟夫环的大数据随机存取系统包括以下功能模块:
随机数产生单元,可在UsbKey(身份认证)密钥的支持下,利用梅森素数旋转随机算法(MT算法)生成随机数和数据切片,并把随机数和数据切片加密存储到文件系统(如数据库)中。
随机序列装载分发单元,可在UsbKey密钥的支持下,根据上次关闭参数或者默认启动参数,加载数据库中存储的随机数和数据切片以组合生成随机序列,然后将生成的随机序列分发给n个随机队列,从数据切片中利用约瑟夫环算法把需要装载的随机序列解密并装载到随机队列中,以增加装载随机度。
监控单元,根据加载的数据切片信息决定是否加载新的数据切片信息,当随机队列中的数据不足时,触发继续加载数据并分发给随机队列,以监控随机队列中的数据。
数据获取单元,根据获取数据请求中的约瑟夫环参数索引,在Usbkey中获取相应的约瑟夫参数,从随机队列获取数据。
随机序列装载分发单元包括随机序列装载器,队列分发器以及随机队列。其中,随机序列装载器可在Usbkey的密钥支持下,综合随机数、数据切片以及系统上次关闭参数,从数据切片中把需要装载的随机序列解密并装载到数据库中。队列分发器负责把随机序列装载器装载的随机序列分发到相应的n个随机队列中,尽可能的达到最大随机性。随机队列存储随机序列的数据,这相当于缓存的作用,可以提高取数据速率。随机队列中一旦数据较少,会由监控单元或者数据获取单元向随机序列装载器发起装载随机队列的操作。
下面分别详细描述以上组成系统的各功能单元。
进一步,随机数产生单元中采用Mersenne Twister random number Algorithm(梅森素数旋转随机算法,MT19937)。MT算法是一个伪随机数发生算法,基于有限二进制字段上的矩阵线性递归,可以快速产生高质量的伪随机数,修正了古典随机数发生算法的很多缺陷。这个算法通常使用两个相近的变体,变体不同之处在于使用了不同的梅森素数,一个更新的和更常用的是MT19937,32位字长,还有一个变体是64位版的MT19937-64。对于一个k位的长度,梅森旋转算法会在[0,2k-1]的区间之间生成离散型均匀分布的随机数。
一般采用梅森旋转算法的一变体MT19937进行随机算,可以产生32位整数序列,具有以下的优点:
1)有219937-1的非常长的周期,足够保证我们5000亿不重复的要求;
2)在1≤k≤623的维度之间都可以均等分布;
3)除了在统计学意义上的不正确的随机数生成器以外,在所有伪随机数生成器法中是最快的。
随机数产生的同时会记录下使用该算法生成的随机数的数量,下次生成随机数据时,首先跳过已生成的数据量,这样就可以保证伪随机数的不重复性,而随机的种子是不变的。
为了保证数据的安全,降低在数据产生、存储过程中的风险,我们使用数据切片技术存储记录信息,MT算法产生完整数据存储在内存中,任何人无法知道具体的内容,但是一旦存储之后,就有泄漏的风险,所以我们除了数据打散切片之外,还要对切片的文件统一加密。
其中,记录数据的产生,是以a张数据为一组,也就是数据切片文件也以a为单元,首先把每条数据随机切成n份,组成n个文件,然后对这n个文件进行加密,然后把这n个文件分别写入文件系统中,写入文件系统之前的步骤都是在内存中进行,可以保证数据生成者没有机会查看到文件内容。在把a个记录打散为n个文件的同时,会生成相应的切片信息,在写入文件系统以后,这些信息保存到数据库中。操作期间要保证usbkey有效,能够正常取到加密密钥。期间任何环节出现任何问题,本次随机记录生成失败,失败后会回滚所做操作,保证数据的完整性。
由此,随机数产生单元负责使用MT算法生成随机数,并把数据切片存储到文件系统,相关的信息及切片信息保存如数据库中。生成随机数的操作是由人工执行并不是自动的,并且需要UsbKey的密钥支持。
进一步,随机序列装载器在每次系统启动、随机队列数据不足的时候运行。启动的时候会加载上次关闭保存的记录信息(数据不足不用加载,因为已经加载过了),根据这些信息判断需要加载哪一批数据切片文件,并判断出本批数据切片文件已经销售到了哪一张,然后从本张开始,利用队列分发器把随机序列随机装载到随机队列中,直到随机队列装载满为止。
随机序列装载器加载的数据切片文件组成随机序列是常驻内存的,除非本次序列获取完毕。一旦监控单元发现随机队列数据不足,就会触发随机序列装载器执行装载操作。随机序列装载器首先会检查目前维护的随机序列是否能满足随机队列的数据要求,如果不能满足就会装载后续的数据切片文件补充随机序列,检查完毕,调用队列分发器把随机队列充满。
进一步,队列分发器用于补充随机队列数据,在系统启动或者监控单元发现随机队列不足的情况下会执行。系统启动时随机队列刚刚生成,还没有数据,所以队列分发器把从随机序列装载器获取到的数据随机放到某一个随机队列中,此处的随机算法可以使用系统自带的随机函数也可以使用MT算法,直到所有的n个随机队列充满为止。
进一步,随机队列是为了保证取记录信息的速率而创建的,相当于一个快速缓存,另外一个目的是为了增加取数据的随机性,随机队列有n个,每次取数据的时候,根据约瑟夫环算法从某一个随机队列中跳过k个数据来获得请求的记录,增加取数据的随机度。随机队列的长度需要根据实际销售情况调整,销售量大队列长度相应调大,销售量小可以适当缩小。
进一步,当监控单元发现某个随机队列数据不足b%(10%-20%)的时候,就会触发随机序列装载器,随机序列装载器检查完自身数据之后,就会调用队列分发器分发数据到随机队列,直到随机队列充满为止。监控单元在系统启动后就会不停的循环执行,是一个定时任务。它会监控随机队列中的数据量,一旦低于规定的值,就会调用随机序列装载器装载数据。
监控单元监控随机队列中的数据,一旦随机队列中的数据不足,会请求数据装载器加载数据,从而分发给随机队列,数据装载器根据目前加载的数据切片信息决定是否加载新的数据切片信息。
另外,监控单元还会检查数据获取单元的销售日志的数量,一旦数据量达到规定值或者超过规定的最长时限就会把日志记录入库保存,避免因频繁更新造成的性能下降。监控单元保证了不会因为缺少数据而导致的失败,同时也因为不用实时更新数据库而提高了取数据的速率。
进一步,数据获取单元采用约瑟夫环获取数据,约瑟夫环是一个数学的应用问题,其数学推导公式为:f[1]=1,f[n]=(f[n-1]+k)%n(n>1)。
数据获取单元在获取数据的时候会用到约瑟夫环,我们随机规定系列的n、k、m值存放在usbkey中,获取数据的请求带有使用第几个n、k、m值的索引,这个索引值是随机的,根据这个索引从usbkey里面去的这组n、k、m值,从而在随机队列中取得要获取的记录数。约瑟夫环可以使取得的数据随机性更好,由于有usbkey加密保存参数,可以保证即使知道了随机队列中的数据,也不能计算出本次请求到底会返回哪个记录。
这里的获取数据,就是指获取一个随机序号,获取数据由数据获取单元执行,只有接收到请求才会获取数据。获取数据需要带有约瑟夫环参数的索引,这个索引是又请求随机产生的一个正整数,在从usbkey中获取约瑟夫环参数的时候,根据定义的参数组的多少取余,然后取得约瑟夫环参数,取得参数后数据获取单元根据公式计算出应该从那个随机队列第几个数据取得返回的数据。取得数据后,数据获取单元记录获取记录,然后把数据返回给请求。
数据获取单元在返回数据给相应请求之后,应该检查一下各随机队列的数据情况,一旦发现有随机队列数据不足(小于队列长度的10%-20%)应该通知监控单元,监控单元会调用随机序列装载器装载数据,不会由于数据不足而导致获取失败的问题。
进一步,在系统中,Usbkey是安全关键,用来存储切片数据的密钥和数据获取单元使用的约瑟夫环参数,一旦出现泄漏就会有严重的问题。系统使用目前比较先进的usbkey技术来加密保存我们的数据,并严格控制usbkey的使用权限,来最大限度的保证数据的安全。
由此,本发明的基于约瑟夫环的随机获取数据的系统,不单纯是产生随机序列的过程,它在获取随机序列的流程上,增加了获取数据的随机性和安全性。使用usbkey加密方法,可以保证操作者无法控制随机数的取得,即使usbkey泄漏了,由于每次取得的ID还有相当的随机性,也能保证无法任意获取想要的数据。
另外,本发明将数据切片技术、加密技术与数据库相结合,保证了数据的安全,其产生过程涉及人员很少,而且保密性能非常好,整个过程生产人员都无法获取任何的记录信息。
本发明的系统虽然安全和随机性能考虑的很周到,但是增加了系统的复杂性,势必会影响取数据的速度,而且由于大批数据驻留内存,还有冗余的情况,所以对系统的开销也较大。然而,由于目前的服务器性能已经有很大的进步,开销方面不用有过多考虑。至于取数据的速度,可以通过调整各部分的参数,提高代码编写质量来控制。
另一方面,本发明还公开了利用上述基于约瑟夫环的大数据随机存取系统进行随机存取的方法,具体如下。
本发明的基于约瑟夫环的大数据随机存取方法包括以下步骤:
步骤一,在UsbKey(身份认证)密钥的支持下,利用梅森素数旋转随机算法(MT算法)生成随机数和数据切片,并把随机数和数据切片加密存储到文件系统(如数据库)中。
步骤二,在UsbKey密钥的支持下,根据上次关闭参数或者默认启动参数,加载数据库中存储的随机数和数据切片以组合生成随机序列,然后将生成的随机序列分发给n个随机队列,从数据切片中利用约瑟夫环算法把需要装载的随机序列解密并装载到随机队列中,以增加装载随机度。
步骤三,根据加载的数据切片信息决定是否加载新的数据切片信息,当随机队列中的数据不足时,触发继续加载数据并分发给随机队列,以监控随机队列中的数据。
步骤四,根据获取数据请求中的约瑟夫环参数索引,在Usbkey中获取相应的约瑟夫参数,从随机队列获取数据。
进一步,如图3所示,在步骤二中,随机序列的生成流程如下:
1)启动数据生成客户端,检查usbkey是否正常,输入生成数据的批次、数量等参数;
2)生成记录随机序列;
3)把生成的记录序列切片,分成n份,放入n个文件,并使用从usbkey获得的密钥把这n个文件加密完成;
4)数据切片存入具体文件,与数据切片相关的信息存入数据库中。
随机数据生成流程是生成记录数据ID的流程,数据生成流程是由随机数生成器负责的,它除了负责随机数的产生,同时也负责数据的切片加密存储,数据信息的入库操作。这些操作需要Usbkey的支持(密钥是否正常),如果系统没有插入Usbkey就无法获取密钥。
进一步,如图4所示,在步骤二中,随机序列装载的流程如下:
1)检查必须的usbkey是否正常,如不正常直接失败退出;
2)获取上次系统退出时的参数,如果是第一次启动,使用默认的配置参数;
3)使用usbkey中获取的密钥解密切片文件;
4)根据切片文件和数据库中的信息生成ID序列;
5)从ID序列中顺序获取数据,随机分发给任意一个随机队列。
随机序列装载流程在每次重新启动的时候会执行,主要的功能是根据上次的参数加载数据切片文件,组合成随机序列,然后分发给随机队列待获取。涉及到的模块有随机序列装载器、队列分发器、随机队列、usbkey。
如果是第一次启动,那么上次启动参数应该是系统默认的第一次启动参数。另外在解密切片文件的时候,可能会扫描文件是否存在、数据库信息是否完整等。
进一步,如图5所示,在步骤三中,随机队列的监控流程如下:
1)判断M个随机队列中是否存在数据不足,最大数据的20%的队列;
2)如果存在随机队列数据不足最大数据的20%,则判断随机序列中加载的切片数据是否不足最大加载切片数据的20%;
3)如果随机序列中的数据不足最大加载切片数据的20%,取下一组切片数据文件,取解密密钥以组合成新的随机序列,并且续接到当前随机序列中;
4)从随机序列中顺序抽取数据随机插入到数据不足的随机队列中,直到所有随机队列充满为止;
5)判断获取数据的销售日志是否超过最大值,如果超过最大值,把销售日志记录入库;
6)判断获取数据的未写入日志时间是否超过规定值,如果超过规定值把日志记录入库;
7)判断完成,休眠一段时间,继续返回步骤1)循环判断。
监控过程是一个循环过程,从系统启动开始每隔一定时间都会执行一遍,直到系统关闭。
进一步,如图6所示,在步骤四中,获取数据的流程如下:
1)验证请求参数和usbkey是否正常,如果不正常,直接返回出错;
2)根据请求参数的随机数参数,从usbkey中获取到使用的约瑟夫环参数;
3)根据约瑟夫环参数,确定应该从m个随机队列中的哪个队列取数据;
4)根据约瑟夫环参数,在取数据的随机队列中取得要请求的信息;
5)记录信息日志;
6)判断随机队列数据是否充足,如果充足,直接返回请求数据,如果有随机队列数据不充足,调用加载队列子流程加载数据(加载队列子流程是异步过程,调用后函数返回,然后返回请求数据)。
获取数据流程设计数据获取单元、随机队列、随机序列装载器、队列分发器,其中数据获取单元和随机队列是一定会执行的,随机序列装载器和队列分发器只有在获取完数据后判断队列中数据不足的时候才会执行。
获取数据需要请求携带随机约瑟夫环索引数据,根据此索引数据在usbkey中找到相应的约瑟夫环参数,从而根据这些参数计算出应该从那个随机队列取数据,应该取第几个数据,增加取得数据的随机性。
本发明的方法充分考虑了随机数据的安全和随机性,利用现代计算机技术实现了高速度的获取随机数据,满足了大数据存取上的数据偏斜率问题。
实施例一:
本发明的系统采用MT随机数算法按照规定规则产生随机序列,使用切片技术把每条随机数记录ID切成n(5)片,随机放入n(5)个随机切片文件中,存放的顺序及规则由数据库存储,切片文件以m(1000万)张记录为一组,每个切片文件使用加密算法加密存储,加密密钥存储在usbkey加密狗中。
系统每次启动首先解密随机切片文件结合数据库存储信息组成完整记录号序列,然后根据上次关机保存参数,生成k(20)个随机队列,每个随机队列充满a(50000)个记录数据,准备好为客户端返回ID数据。
客户端请求数据时,根据请求参数按照约瑟夫环算法随机从20个随机队列中抽取一张随机ID返回。一旦队列中的数据不足满队列的20%(10000张)时,系统按照规则从随机序列中抽取数据充满队列。
加密usbkey中除了存储密钥以外,还存储约瑟夫环需要的参数数组,客户端请求随机序列时,利用系统自带随机数(或MT算法)随机一个参数,系统根据这个参数从usbkey中取得约瑟夫环参数,进而在随机队列中取得数据。一组切片数据销售剩余不足20%(200w张)的时候,系统加载另外一组切片数据,以免数据不足影响销售。
因此,本发明的系统达到了如下的效果:随机序列保证5000亿(50亿/年x1000年)以内随机数据不重复;支持至少2000张/秒取数据速率;保证数据安全,没有被窃取、篡改可能;切片文件加载记录序列时间不超过1分钟。
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本申请的权利要求范围内的实施例都属于本发明所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!