一种基于数据挖掘技术的气动特性数据处理方法与流程
本发明涉及一种基于数据挖掘技术的气动特性数据处理方法,适用于面对称高速再入飞行器,属于飞行器气动设计领域。
背景技术:
在航天工程研制、运行的全过程中,都会产生大量数据。航天数据不仅具有一般大数据的特点,而且要求高可靠、高精度和更高的处理速度。目前气动设计中的气动特性分析大多还是依赖传统的曲线分析,弹道、姿控等专业对气动数据的使用也大多采用数据表和线性插值的方式,一方面需要根据数据格式专门编制程序处理数据,另一方面插值方法也会带来基本数据和高阶导数的误差,对气动特性分析的效率和使用准确度都造成了影响,需要用更高准确度且更易使用的气动数据处理方法加以改进。
技术实现要素:
本发明解决的技术问题是:克服现有技术的不足,提供了一种基于数据挖掘技术的气动特性数据处理方法,有效提高了气动特性分析的效率和使用准确度。
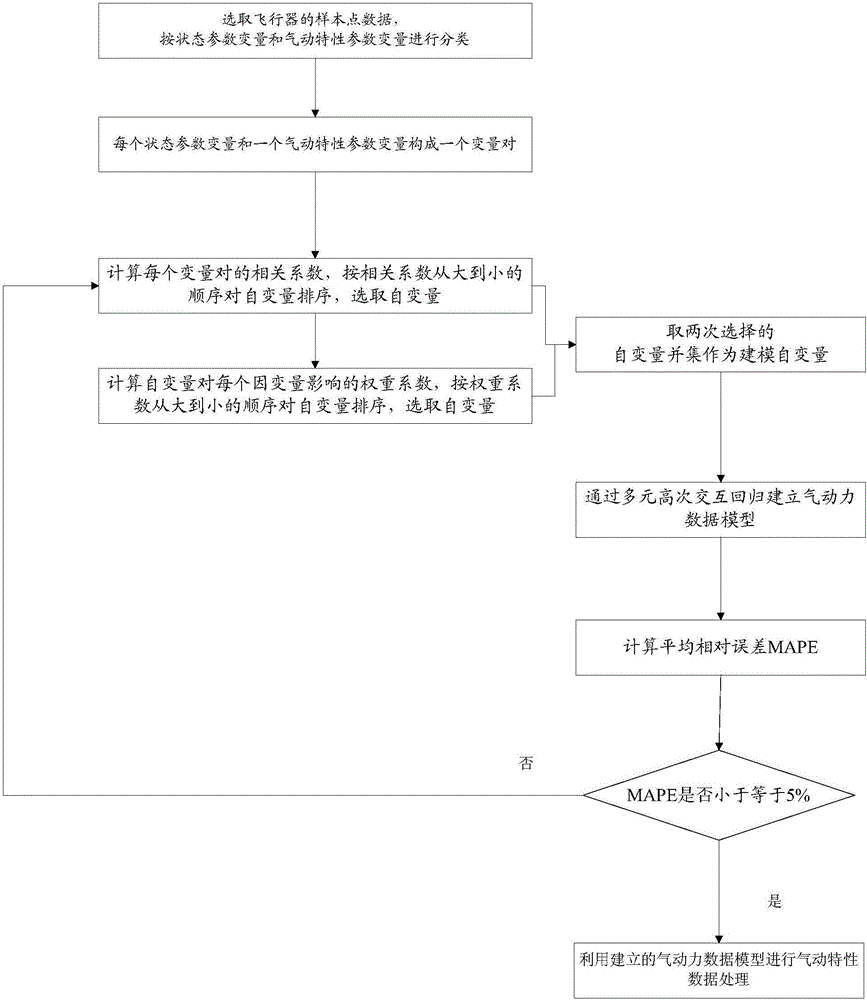
本发明的技术解决方案是:一种基于数据挖掘技术的气动特性数据处理方法,包括以下步骤:
(1)选取飞行器的样本点数据,将其按状态参数变量和气动特性参数变量进行分类,其中状态参数变量包括马赫数Ma、攻角α、侧滑角β、舵偏角δj、高度H、雷诺数Re、努森数Kn,气动特性参数变量包括气动力六分量,即气动力分量(Cx,Cy,Cz)和气动力矩分量(U,V,W),每个状态参数变量和一个气动特性参数变量构成一个变量对;
(2)计算每个变量对的相关系数,记状态参数变量为自变量,气动特性参数变量为因变量,按相关系数从大到小的顺序对自变量排序,选取前2/3的自变量;
(3)计算自变量对每个因变量影响的权重系数,按权重系数从大到小的顺序对自变量排序,选取前2/3的自变量;
(4)取步骤(2)和步骤(3)选取自变量的并集作为建模自变量;
(5)通过离群点分析法剔除气动力六分量明显不合理的数据点,根据剩余数据点通过多元高次交互回归建立气动力数据模型;
(6)从样本点数据集合中选取80%为训练集,剩余的20%为测试集,根据训练集中的数据,利用气动力数据模型计算预测值,并与测试集比对,利用如下公式计算平均相对误差MAPE:
其中predi为第i个样本的预测值,truei为第i个样本在实际测试集中的值,N为样本总数;
(7)如果MAPE小于等于5%,则气动力数据模型达到要求,根据气动力数据模型以及样本点数据获得飞行器设计空间的所有气动特性数据,如果MAPE大于5%,则气动力数据模型不符合要求,返回步骤(2),在步骤(2)中补充选取抛弃自变量中前2/3的自变量,在步骤(3)中补充选取抛弃自变量中前2/3的自变量,直到MAPE小于等于5%。
所述步骤(2)中计算每个变量对相关系数的方法如下:
(2.1)为每对变量对中所有样本点涉及的自变量编秩,为所有样本点涉及的因变量编秩;
(2.2)利用公式计算每个变量对的相关系数ρ,其中dk代表第k组变量对因变量和自变量的排行差,dk=因变量的秩次-自变量的秩次。
所述步骤(3)中计算自变量对每个因变量影响的权重系数的方法如下:
(3.1)设样本点数据中第j个因变量的数值为n×1的向量y,自变量数值对应n×M的矩阵x,M为自变量个数;
(3.2)对矩阵x利用公式x=pΔq'进行分解,其中矩阵p由xx'的特征向量组成,q由x'x的特征向量组成,Δ为对角线矩阵,对角线为矩阵x的特征值;
(3.3)利用公式W=qp'y计算自变量对第j个因变量的影响权重W。
在步骤(6)中分五次选取不同的数据作为测试集,分别计算MAPE,如果五次的MAPE均小于等于5%,则气动力数据模型合适,否则认为气动力数据模型不合适。
当气动力数据模型不合适时,通过步骤(2)和步骤(3)补充选取自变量后,在步骤(5)中采用更高次的回归方法进行建模。
本发明与现有技术相比的优点在于:
(1)采用了数据挖掘中的相关分析法分析状态参数变量和气动特性参数变量之间的关联关系,能够基于大量数据以单幅图显示变量间的影响关系,相对传统的曲线图,可以快速直观的展示出飞行器气动特性随各状态参量的变化规律和气动特性本身的三通道耦合规律,提高了气动特性分析的效率。
(2)通过高次交互回归方法,结合状态参数影响权重分析方法,高效准确的给出气动模型,利用该气动力数据模型获得的气动数据精确度更高,避免了传统的气动数据库线性插值以及高阶导数缺失带来的准确度下降问题,有效提高了气动数据的使用准确度。
(3)通过气动模型将气动数据转化为简单的公式形式,各专业对气动数据的使用无需再通过读入庞大的数据表实现,明显提升了气动数据的分析和使用效率。
(4)通过计算状态参数对气动特性的相关系数和权重系数,可以明确各状态参数在建模中的重要度,方便使用者根据模型精度要求进行建模参数选取;并且,通过五重交叉验证和模型迭代修正,确保了气动力数据模型的高精准度,获得准确度可控的适用于工程设计的气动模型。
附图说明
图1为本发明方法流程图;
图2为本发明实施例飞行器示意图;
图3为气动特性参数变量与状态参数变量之间的相关性示意图;
图4为各个自变量对气动力Cx的影响权重示意图;
图5为本发明方法与传统差值方法得到的预测值与实际值的平均相对误差对比图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
一般飞行器研制过程中会产生大量的气动数据,对气动特性变化规律和影响因素的快速掌握对飞行器设计有着重要意义,鉴于传统气动数据处理方法对气动特性分析的效率和使用准确度的影响,本发明考虑引入数据挖掘技术进行气动特性变化规律方面的研究,并在掌握规律的基础上进行气动建模,提升气动数据使用的精准度和效率。
在气动特性参数与飞行状态参数的相关性分析中,基于样本点数据整理了气动专业数据,按照自变量和因变量分为两类,自变量主要指状态参数,因变量主要指气动特性参数。状态参数有马赫数、攻角、侧滑角、舵偏角、高度、Re、Kn、气动布局参数等;气动特性参数主要指气动力六分量、气动不确定度等。根据提供的气动数据,开展状态参数和气动特性参数之间规律的研究。
如图1所示,本发明的具体步骤如下:
(1)选取飞行器的样本点数据,将其按状态参数变量和气动特性参数变量进行分类,其中状态参数变量包括马赫数Ma、攻角α、侧滑角β、舵偏角δj、高度H、雷诺数Re、努森数Kn;气动特性参数变量包括气动力六分量,即气动力分量(Cx,Cy,Cz)和气动力矩分量(U,V,W),每个状态参数变量和一个气动特性参数变量构成一个变量对。
(2)计算每个变量对的相关系数,按相关系数从大到小的顺序对自变量排序,选取前2/3的自变量,记状态参数变量为自变量,气动特性参数变量为因变量。
计算每个变量对相关系数的方法如下:
(2.1)为每对变量对中所有样本点涉及的自变量编秩,为所有样本点涉及的因变量编秩,数值相同的自变量秩次相同,数值相同的因变量秩次相同;例如,某变量对(x1,y)中,x1对应的样本点为(1,1,3,5,7,11),则其对应的秩次为(1,1,2,3,4,5);y对应的样本点为(0.1,0.3,0.3,0.2,0.4,0.6),则其对应的秩次为(1,3,3,2,4,5)。
(2.2)利用公式
计算每个变量对的相关系数ρ,其中dk代表第k组变量对样本点因变量和自变量的排行差,dk=因变量的秩次-自变量的秩次,N为样本总数。ρ的范围在-1到1之间,当ρ为1,说明该变量对中两个变量正相关。当ρ为-1,说明该变量对中两个变量呈负相关。当ρ为0,说明该变量对中两个变量不相关。利用-1到1之间的系数值,量化地表示出变量之间的相关关系,便于分析和比较。
(3)采用影响权重分析获得各个变量间的相关程度,计算自变量对每个因变量影响的权重系数,按权重系数从大到小的顺序对自变量排序,选取前2/3的自变量。
计算自变量对每个因变量影响的权重系数的方法如下:
(3.1)设样本点数据中第j个因变量的数值为n×1的向量y,自变量数值对应n×M的矩阵x,M为自变量个数;
(3.2)对矩阵x利用公式
x=pΔq' (2)
进行分解,其中矩阵p由xx'的特征向量组成,q由x'x的特征向量组成,Δ为对角线矩阵,对角线为矩阵x的特征值;
(3.3)利用公式
W=qp'y (3)
计算自变量对第j个因变量的影响权重W。
(4)取步骤(2)和步骤(3)选取自变量的并集作为建模自变量。
(5)通过离群点分析法剔除气动力六分量明显不合理的数据点,根据剩余数据点通过多元高次交互回归建立气动力数据模型。
多元二次交互回归建立气动力数据模型的实现方式如下:
其中,[x1 x2 x3 x4]为选取的自变量,对应于马赫数Ma、攻角α、舵偏角L、舵偏角R,y为因变量Cx,w0、ws、分别为方程零次项系数、一次项系数、二次项系数、交互项系数,M为自变量个数,等式右侧第三项交互项中s≠j。可以通过最大似然法,基于样本点数据,求解最优化问题(其中X是自变量xs的一次项、二次项和交互项组成的向量、W是方程系数组成的矩阵)得到模型的方程系数,从而模拟自变量和因变量之间关系的数学表达形式。
(6)从样本点数据集合中选取80%为训练集,剩余的20%为测试集,根据训练集中的数据,利用气动力数据模型计算预测值,并与测试集比对,利用如下公式计算平均相对误差MAPE:
其中predi为第i个样本的预测值,truei为第i个样本在实际测试集中的值,N为样本总数。
(7)如果MAPE小于等于5%,则气动力数据模型合适,气动特性处理结束,如果MAPE大于5%,则气动力数据模型不合适,返回步骤(2),在步骤(2)中补充选取抛弃自变量中前2/3的自变量,在步骤(3)中补充选取抛弃自变量中前2/3的自变量,直到MAPE小于等于5%。
为了进一步保证气动模型的精准度,可以在步骤(6)中分五次选取不同的数据作为测试集,分别计算MAPE,如果五次的MAPE均小于等于5%,则气动力数据模型合适,否则认为气动力数据模型不合适。
当气动力数据模型不合适时,通过步骤(2)和步骤(3)补充选取自变量后,在步骤(5)中采用更高次的回归方法进行建模,可以以1为步进量逐渐增加次数。
实施例:
以某面对称高速再入飞行器为例,该飞行器如图2所示:
表1列出了该飞行器气动数据中的马赫数、攻角、侧滑角和舵偏角度,共计15360个状态点(马赫数8个*攻角40个*侧滑角3个*舵偏角16个=15360个样本点)。
表1气动数据状态表
本实施例中考虑的自变量X(状态参量)包括马赫数Ma、攻角a、侧滑角b、舵偏角L、R、r,考虑的因变量y包括气动力三分量Cx、Cy、Cz和气动力矩三分量U、V、W。自变量和因变量之间组成变量对。
通过公式(1)进行气动特性相关系数计算,使用热力图对相关系数矩阵进行可视化,结果如图3所示。图中展示的是相关系数矩阵(对称矩阵)的元素值的大小,左下角为饼图展示,对应的右上角为数值展示。左下角,饼图的阴影面积越大,表明相关系数越大,每一个饼图表示其所在列的变量对其所在行的变量的相关性;右上角,正系数代表正相关,负系数代表负相关,括号中的范围为相关系数95%的置信区间。
通过公式(2)(3)计算自变量对因变量的权重系数。以自变量对气动力Cx的权重系数计算为例,从图4可见,对于给定的气动数据,变量r和b对气动力Cx的相对重要性较小,因此考虑在建模的过程中忽略其对因变量的影响,以提高建模的效率。
按相关系数从大到小的顺序对自变量排序,选取前2/3的自变量作为集合1,按权重系数从大到小的顺序对自变量排序,选取前2/3的自变量作为集合2,取集合1和集合2的并集作为建模自变量,剔除不合理数据点后通过多元高次交互回归算法,建立多元、高次、且考虑了交互项的回归模型,定量分析因变量和自变量之间的关系,把自变量的高次幂与因变量之间的关系考虑到模型中,并对自变量内部之间的关联关系对因变量造成的影响进行建模。
为了保证预测结果的可信度,进行5重交叉验证,每次取数据集的80%为训练集,剩余20%的部分为测试集,五次测试集均不相同。并使用公式(4)计算平均相对误差MAPE,如果五次的MAPE均小于等于5%,则气动力数据模型合适,否则认为气动力数据模型不合适。当气动力数据模型不合适,补充选取抛弃的自变量,直到MAPE小于等于5%。
下面分别采用了几种回归模型进行建模,并进行误差分析。首先给出最简单的一阶回归模型,不考虑交互项,参数估计结果如下:
根据该参数构建气动力数据模型,进行预测,最终得到MAPE值为10.37%。
考虑了交互项的一阶回归预测:有些自变量之间是具有很强的相关性的,因此在进行回归分析时考虑它们的相关性可以提高预测的精度。参数估计结果如下所示:
根据该参数构建气动力数据模型,进行预测,MAPE值降低到了8.42%。
考虑了交互项的高阶回归预测:进一步增加模型的复杂度,考虑自变量的幂次,构造高阶回归预测模型,参数估计结果如下所示:
MAPE值降低到了4.67%。
上述过程说明考虑了交互项的高阶回归模型预测精度更高,因此,当气动力数据模型不合适时,应该采用更高次的回归方法进行建模,以降低平均相对误差。
应用本发明方法建立的气动力数据模型得到的预测值与实际值的平均相对误差以及应用传统气动数据处理方法得到的预测值与实际值的平均相对误差对比图如图5所示,图中HORAC对应于本发明方法,线性回归、高阶线性以及支持向量基对应于传统气动数据处理方法,可以看出,本发明显著提高了气动数据使用的准确度。
本发明基于空气动力学原理和数据挖掘算法给出了飞行器的气动特性数据处理算法。该方法通过分析气动特性变化的主要影响因素和飞行器整体气动特性变化规律,给出了高精度的气动力数据模型,根据给出的气动力数据模型以及样本点数据能够获得飞行器设计空间的所有气动特性数据,且与实际值误差较小,从而显著提高气动特性分析的效率和使用准确度。
本发明说明书中未作详细描述的内容属本领域技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!