基于评论文本挖掘的产品特征结构树构建方法与流程
本发明属于产品质量管理领域,涉及一种基于评论文本挖掘的产品特征结构树构建方法。
背景技术:
:
产品的质量安全问题是当今社会的永恒课题,它不仅包含产品的本质安全,也包含了产品的使用安全。产品的质量安全问题不仅影响消费者的权益(生命、财产、健康等),也会给制造企业带来巨大的经济损失,关系到制造企业的生存和发展。运用科学的、高效的管理方法和手段,尽早发现各种潜在的产品质量安全问题,通过技术创新和技术突破,对产品存在的问题进行改进和提升,提高产品在市场上的竞争力和影响力。
随着互联网技术的发展与普及,网络正逐渐改变着人们的生活和表达方式。由于不同的用户有不同的质量、安全需求,也可能在不同的环境、工况、负载下,产品在使用过程中会暴露出很多意料之外的质量安全问题,用户通常会选择借助网络平台进行交流,发表使用评价信息。这些用户的评价信息蕴含着丰富的、有价值的信息。制造企业如果能够快速、有效地从中提取反映产品质量的信息,将会为改进、完善产品开发设计提供重要的依据,提高用户的满意度,增强企业的市场竞争力,同时,也会降低由于产品质量问题造成事故给企业带来的经济损失。
然而,由于互联网的开放性,用户对产品质量安全的评价信息具有多源、异构的特点,面对纷繁复杂的海量网络评论数据,亟需一种机制做正确的监测,科学地分析各种潜在的质量问题,建立完善的质量安全监管技术体系,从而有效规避产品质量安全问题给企业带来的经济、信誉等损失,增强制造企业应对产品质量安全风险的能力。
技术实现要素:
:
为了能快速、有效地从多源异构的海量产品质量安全信息中提取产品特征,且对其进行产品特征结构树构建、定量描述、结构树扩展等操作,本发明提供了一种基于评论文本挖掘的产品特征结构树构建方法,是一种高效的、便捷的产品质量管理的方法,也是对传统产品质量管理方法的一种扩充。
本发明解决其技术问题所采用的技术方案如下述内容:
基于评论文本挖掘的产品特征结构树构建方法,其特征在于:该方法包括下述步骤:
步骤1,语料库获取:利用网络爬虫软件,制定爬取规则,抓取与指定产品相关的电商网站以及论坛上的用户评论文本进行预处理并以结构化形式保存到数据库中;
步骤2,产品特征提取:2.1利用分词器对语料库进行分词及词性标注,从初次分词结果中通过新词发现方法,识别领域新词,添加到用户词典中,再基于用户词典对语料库进行优化分词;2.2将优化分词结果进行词性标注集转换,用中文自然语言处理工具包对转换后的优化分词结果进行依存关系分析;2.3用整理的情感词词典对依存关系分析结果中的支配词进行标注,得到以词语为基本记录单元的结构化数据;2.4将情感分析的结果分为训练集和测试集,制定条件随机场特征模板,利用开源工具包,对已经标注产品特征的训练集进行训练,生成条件随机场模型,再利用该模型对测试集进行产品特征标注,并对测试结果进行评测;2.5从语料库中将标记的产品特征提取出来;
步骤3,产品特征结构树的构建:3.1定义产品特征的类型,构建特征类型的层次结构;3.2对于每个产品特征,定位它在优化分词结果中的位置,对于位置的前面的信息,统计在同一条评论语句中、且是第一个能与产品特征表匹配的、不是本产品特征的产品特征出现的频数,将匹配的非本产品特征、非本产品特征的类型、非本产品特征频数统计结果保存到结果数组中;对于位置的后面的信息,与位置前面的信息处理结果相同;3.3对结果数组中的信息按照出现的频数从大到小进行排序,基于特征类型的层次结构,在结果数组中寻找本产品特征的类型的上层类型,则对应的非本产品特征就是寻找的关联特征;3.4遍历产品特征结构树,当不存在本产品特征时,将本产品特征-关系-关联特征这个分支保存到分支数组中;当存在本产品特征时,先判断产品特征树中是否存在该分支,当不存在该分支时,将关联特征作为本产品特征的子节点,添加到产品特征结构树中;否则,不变;3.5将分支数组中的本产品特征与产品特征结构树中的节点进行匹配,当存在时,将该分支添加到树中对应节点上,并删除分支数组中的该分支,整理数组;否则,不变;
步骤4,产品特征的定量分析:4.1统计优化分词结果中所有产品特征出现的频数;4.2基于产品特征结构树和已统计的产品特征频数,统计产品特征中部件特征的频数;4.3分析句法分析结果中产品特征的支配词和上下文,查找情感词、程度副词和否定词语素,计算产品特征的情感得分;4.4可视化产品特征频数的统计结果和情感得分,分析用户对产品的关注点;
步骤5,产品特征结构树的扩展:5.1对同义子节点的扩展,通过定量计算特征相似度的方法,计算新产生的产品特征与产品特征结构树中的节点之间的相似度,来确定新产品特征的父节点,并将其添加到产品特征结构树中;5.2对隶属子节点的扩展,通过定量计算特征相关度的方法,计算新产生的产品特征与产品特征结构树中的节点之间的相关度,来确定新产品特征的父节点,并将其添加到产品特征结构树中。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤1中,对保存到本地数据库的原始评论文本进行预处理,其中预处理包括删除冗余评论文本,删除无中文的评论文本,删除重复标点,修改错别字等操作。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤2中,对初次分词结果通过新词发现方法,识别领域新词,其中新词发现方法包括构造重复串、频率过滤、内聚性过滤和左右熵过滤操作。其中,构造重复串操作是以初始分词结果为基础,利用N-Gram模型(N表示重复串的最大长度,由用户设定),对初始分词结果进行词频统计、过滤、构造操作;频率过滤操作是将构造的重复串中频率低于设定值的部分过滤掉;内聚性过滤操作是将频率过滤后的重复串计算内聚性,过滤掉内聚性低于阈值的部分;左右熵过滤操作是计算内聚性过滤后的重复串的左熵和右熵,若某一个熵值低于阈值,则将其过滤掉。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤2中,训练集是对从情感分析结果里随机抽取的实验语料中出现的产品特征进行人工标注。训练集的字段共六列,按顺序排列分别是:词形、词性、依存关系、支配词、支配词的情感判断、人工标注的产品特征标记。其中,产品特征的标注符号集为{B,I,L,O,U},它们分别表示产品特征开头(B),产品特征内部(I),产品特征结尾(L),非产品特征(O)和单个产品特征(U)。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤2中,条件随机场特征模板的制定,采用的模板类型是Unigram Template,特征模板分为两类,为词形特征对应的特征模板(原子型)和依存关系特征、支配词特征、支配词的情感判断特征对应的特征模板(复合型)。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤3中,产品特征可分为五大类,分别表示“产品的整体”、“产品的部件”、“产品的属性”、“产品的功用”和“产品的问题”,相应地,我们将其命名为产品特征、部件特征、属性特征、功用特征、问题特征。从产品的角度来看,这五类词语之间是存在联系的。在特征结构树中,用四种关系符描述五类产品特征之间的语义关系,分别是part-of、use-of、attribute-of和problem-of。另外,结合产品特征可能存在多个同义词的实际情况,再定义一种关系符equal-to表示描述同义产品特征之间的关系。产品特征是从产品特征表中选取的,产品特征表是由产品特征和产品特征类型组成的。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,计算产品特征中部件特征的频数是基于产品特征结构树,从叶子节点往根节点的方向计算的;除叶子节点外,部件特征的频数计算公式为:
Sum部件=Sum同义+μ×(Sum属性+Sum功用+Sum问题)
其中,Sum部件表示部件特征的频数;Sum同义表示子节点上与部件特征之间是equal-to关系的产品特征频数之和;Sum属性、Sum功用、Sum问题分别表示子节点上与部件特征之间是use-of、attribute-of、problem-of关系的产品特征频数之和;μ表示隶属节点的转换率,范围为[0,1]。以柱状图的形式将产品特征频数统计结果进行可视化。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,用户的褒贬态度可以用词语的情感倾向表达;情感词典中词语来源于互联网,人工挑选了网络中常用的情感词。经过情感极性判断,将情感词分为三类:褒义、中性、贬义,并对其进行情感强度定义。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,1)如果一个产品特征在一条评论中出现多次,则只讨论情感强度最大的情感词;2)不同极性的情感词,产品特征情感得分的计算方法是不同的;3)在计算一条用户评论中的产品特征的情感得分时,根据情感词极性的不同分为三种情况:
第一种情况:修饰产品特征的是褒义情感词,情感得分为情感词的情感强度;
第二种情况:修饰产品特征的是贬义情感词,情感得分为情感词的情感强度的负值;
第三种情况:修饰产品特征的是中性情感词,情感得分的计算采用结合上下文语境的方法:以本条评论中所有情感词的情感强度均值作为该产品特征的情感得分。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,程度副词会影响情感词的情感强度;程度副词词典是基于知网的程度级别词语集,从中选取了部分词语,并另外加入了一些网络评论中常出现的程度副词。人工地对程度副词词典中的词语进行强度定义。当某个产品特征的支配词是情感词,且情感词的前面3个词语中存在程度副词时,该产品特征的情感得分变为情感得分和程度副词强度的乘积;否则,情感得分不变。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,否定词词典中词语来源于评论文本数据和网络中常用的否定词;在计算某条评论中产品特征的情感得分时,当句子表达的是否定的意思时,仅依靠情感词典往往会得到相反的结果,所以需要考虑句子中存在的否定词。当某个产品特征的支配词是情感词,且情感词的前面4个词语中存在否定词时,该产品特征的情感得分变为情感得分的负值;否则,情感得分不变。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤4中,产品特征情感得分计算方法如下:
从语料库中提取的产品特征组成了特征集合{fw1,fw2,...,fwn},对于每个产品特征fwi,定义了一个产品特征的情感得分Sco(fwi),范围为[0,100],Sco(fwi)分值越高,说明用户对该产品特征的评价越高,Sco(fwi)的计算公式为:
其中,a、b、c分别表示修饰产品特征fwi的情感词为褒义、贬义、中性情感词的评论条数,ScoP(fwi)、ScoN(fwi)、ScoM(fwi)分别是计算褒义、贬义、中性情感词得到的情感得分,它们的计算公式如下:
其中,PW(k)表示第k条评论中修饰产品特征fwi的褒义情感词,Str(i,PW(k))表示产品特征fwi的第k个褒义情感词的情感强度;NW(k)表示第k条评论中修饰产品特征fwi的贬义情感词,Str(i,NW(k))表示产品特征fwi的第k个贬义情感词的情感强度;p(k)、n(k)分别表示在修饰产品特征的情感词为中性的第k条评论中,褒义情感词的个数和贬义情感词的个数,PW(k,j)表示在修饰产品特征的情感词为中性的第k条评论中的第j个褒义情感词,NW(k,t)表示在修饰产品特征的情感词为中性的第k条评论中的第t个褒义情感词。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤5中,采用基于字面相似度的词语相似性算法和基于语境的词语相似性算法,计算两个产品特征之间的相似性。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤5中,基于字面相似度的词语相似性算法受数量因素和位置因素影响,其中,数量因素指两个词语之间含有相同汉字的个数,位置因素指相同汉字在各个词语中的位置权重。字面相似度的相似性计算方法如下:
假设A和B表示需要计算相似度的两个产品特征,A和B之间的字面相似度记为SimWord(A,B),且0≤SimWord(A,B)≤1。则SimWord(A,B)的计算公式为:
其中,α和β分别表示数值因素相似度和位置因素相似度在整个词语相似度中所占的权重系数,且α+β=1;dp表示为两个产品特征的汉字个数之比,且Weight(A,i)表示A中第i个汉字的权重,且|A|和|B|分别表示特征A和特征B所包含的汉字个数;A(i)表示A中的第i个汉字;SameHZ(A,B)表示特征A和B中共同包含的相同汉字的集合,|SameHZ(A,B)|表示SameHZ(A,B)集合的大小,即特征A和B中共同包含的相同汉字的个数。
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤5中,基于语境的词语相似度计算方法如下:产品特征Featurei用一个n维的向量表示为Featurei=(Si1,Si2,...,Sij,...,Sin),其中,Sij是Featurei与常用情感词组中的第j个情感词的共现频率。将词语相似度计算转化为向量的相似度计算,两个向量之间的相似度用夹角余弦来衡量,计算公式为
在上述的基于评论文本挖掘的产品特征结构树构建方法中,在所述的步骤5中,通过计算新产生的产品特征与产品结构树中特征的相关度来确定新特征的父节点,相关度的计算公式为:
其中,Fab表示产品特征Featurea和Featureb的共现频数,Fa和Fb表示每个产品特征单独出现的频数。
本发明可以获取海量与指定产品相关的、多源异构的网络评论文本,经过浅层和深层的中文文本信息处理技术,提取产品特征;对提取的产品特征进行构建特征结构树、定量描述、产品特征结构树扩展等。利用本发明的方法,制造企业可以快速、有效的了解用户使用产品过程中对产品各个方面的评价,可以有效减少及预防产品质量安全事件对制造企业带来的经济损失,全面提高制造企业对潜在的产品质量安全危害的主动管理能力,提高企业在市场中的竞争力。
附图说明:
图1是本发明的整体流程图。
图2是本发明的语料库获取流程图。
图3是本发明的产品特征提取技术路线图。
图4是本发明的产品特征提取的数据表字段变化图。
图5是本发明的产品特征提取的评测结果图。
图6是本发明的产品特征类型的层次结构图。
图7是本发明的产品特征结构树构建原理图。
图8是本发明的产品特征结构树构建示例流程图。
图9是本发明的部分产品特征结构树示例图。
图10是本发明在不同大小窗口的情况下,否定词识别的实验测评结果。
图11是本发明的产品特征情感得分计算流程图。
图12是本发明的部分产品特征分布的定量描述柱状图。
图13是本发明的部分产品特征分析的定量描述柱状图。
具体实施方式:
下面结合具体附图对本发明作进一步的说明。
本发明是对多源异构的海量用户评论文本进行中文文本信息处理,提取产品特征,且对提取的特征进行一系列分析操作,挖掘评论文本中蕴含的有价值的信息,提高制造企业的市场竞争力。
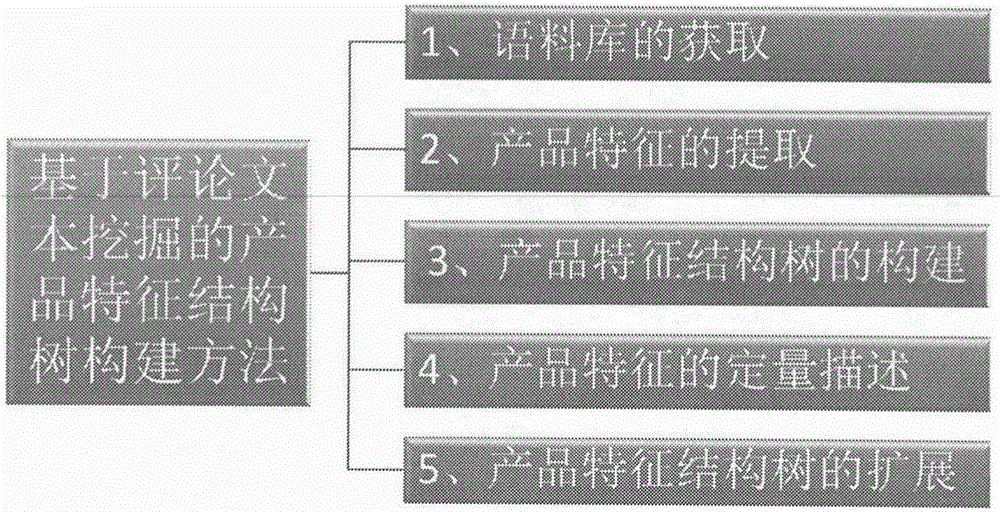
基于评论文本挖掘的产品特征结构树构建方法,包括语料库的获取、产品特征的提取、产品特征结构树的构建、产品特征的定量分析和产品特征结构树的扩展五个方面,如图1所示。下面分别对这各个步骤进行详细的说明。
步骤1,语料库的获取:利用网络爬虫软件,制定爬取规则,抓取与指定产品相关的电商网站以及论坛上的用户评论文本,并对原始评论文本进行预处理,以结构化形式保存到数据库中。
语料库获取的流程如图2所示。制定网络爬虫的爬取规则,抓取相关的电商网站、论坛等平台,获得原始评论文本并存储到本地数据库中,对原始评论文本进行删除冗余评论文本,删除无中文的评论文本,删除重复标点,修改错别字等的预处理操作,得到语料库。
步骤2,产品特征的提取:2.1利用分词器对语料库进行初次分词及词性标注,从初次分词结果中通过新词发现方法,识别领域新词,并将其添加到用户词典中,再基于用户词典对语料库进行优化分词;2.2将优化分词结果进行词性标注集转换,用中文自然语言处理工具包对转换后的优化分词结果进行依存关系分析;2.3用整理的情感词词典对依存关系分析结果中的支配词进行标注,得到以词语为基本记录单元的结构化数据;2.4将情感分析的结果分为训练集和测试集,制定条件随机场特征模板,利用开源工具包,对已经标注产品特征的训练集进行训练,生成条件随机场模型,再利用该模型对测试集进行产品特征标注,并对测试结果进行评测;2.5从语料库中将标记的产品特征提取出来。
本发明提供了从多源异构的海量评论文本语料库中快速、高效提取产品特征的方法,方法的技术流程图如图3所示。对语料库依次进行分词及词性标注(初次分词、识别领域新词和优化分词操作)、句法分析(词性标注集转换和依存关系转换操作)、情感分析(情感词标注)、产品特征标注(条件随机场模型训练和利用模型处理数据)和产品特征提取等操作,各操作步骤结束后数据库表的字段变化如图4所示,具体分析各个操作步骤如下:
分词及词性标注操作是现代自然语言处理工作的基础。随着社会的发展,出现了很多新词,未更新的分词器就不能识别词语,一般要将它分开成为2个词,这使得分词结果不能满足实验的要求。为了解决这个问题,我们引入新词发现技术,在对语料库通过分词器进行初次分词后(评论记录被分成一个一个的词语记录,表格字段共2列,分别是词形和词性),对初次分词结果进行构造重复串、频率过滤、内聚性过滤和左右熵过滤等四步操作,识别出部分领域新词,再通过人工删选、词性标注,将新词添加到用户词典中;用扩充的用户词典,再对语料库进行优化分词(基于用户词典,评论记录被分成词语记录,表格字段也是词形和词性这2列),从而提高分词的准确率。
由于分词器与中文自然语言处理工具包使用的词性标注集不同,在进行依存关系分析之前,要先对经过词性标注的语料库进行词性标注集转换,为接下来的操作做准备工作。中科院的分词器采用教育部语用所词性标记集(共计99个,22个一类,66个二类,11个三类),而中文自然语言处理工具包采用863词性标注集,共划分出28种词性。根据人工整理的一套标注集的转换规则进行转换,使词性符合实验要求。
依存句法分析认为:句子中的述语动词或形容词是句子的核心词,它不受其它任何词语的支配,而除核心词之外的所有词语都受另一个词语的支配,这种支配用词与词之间的依存关系来表示。一个依存关系连接两个词,其中一个是支配词,另一个是从属词,依存关系的类型表明了支配词与从属词之间的依存关系类型。依存句法分析可以反映出句子各成分之间的语义修饰关系,可以获得长距离的搭配信息,并与句子成分的物理位置无关。依存关系对产品特征的识别起到了一定的帮助作用。此时表格的字段共4列,分别是词形、词性、依存关系和支配词。
通过人工整理的情感词典对依存关系分析结果中的支配词进行情感标注,判断该支配词是否是情感词,当是情感词时,则将它标记为“Y”,反之则标记为“N”。此时表格的字段共5列,分别是词形、词性、依存关系、支配词和支配词的情感判断。
将情感分析结果随机抽取一些记录成为训练集,则剩余记录为测试集。对训练集进行人工标注产品特征,利用训练集训练出条件随机场模型,再利用模型对测试集进行特征标记,然后删选、提取出产品特征。训练集的字段共6列,分别是词形、词性、依存关系、支配词、支配词的情感判断和人工标注的产品特征标记,其中产品特征的标注符号集为{B,I,L,O,U},它们分别表示产品特征开头(B),产品特征内部(I),产品特征结尾(L),非产品特征(O),单个产品特征(U)。利用条件随机场开源工具包进行训练,训练出Model文件,对测试集进行特征标注。而测试集的字段共7列,分别是词形、词性、依存关系、支配词、支配词的情感判断、计算机程序自动标注的产品特征标记和训练出的模型标注的产品特征标记。
为了对产品特征的提取效果进行测评,采用了三个最常用的测评指标:准确率(P)、召回率(R)和F指标。一般情况下,准确率和召回率是相互制约的,提高准确率的同时会使召回率降低,反之亦然,所以只用准确率和召回率这两个测评指标无法综合衡量产品产品特征的提取效果,还需要使用两者的调和均值:F指标。三个指标的公式如下:
其中,N1表示在测试语料中,人工标记为产品特征的词语总个数;N2表示在测试语料中,模型标记为产品特征的词语总个数;N3表示在测试语料中,人工标记和模型标记均为产品特征,且标记符号相同的词语总个数,也就是说,人工标记和模型标记必须同时是B、I、L、U中的一种,如果人工标记为B,而模型标记为U,则不计入N3。图5就是通过PER测评工具对使用了CRF++进行产品特征提取数据库进行的效果测评结果图。
步骤3,产品特征结构树的构建:3.1定义产品特征的类型,构建特征类型的层次结构;3.2对于每个产品特征,定位它在优化分词结果中的位置,对于位置的前面的信息,统计在同一条评论语句中、且是第一个能与产品特征表匹配的、不是本产品特征的产品特征出现的频数,将匹配的非本产品特征、非本产品特征的类型、非本产品特征频数统计结果保存到结果数组中;对于位置的后面的信息,与位置前面的信息处理结果相同;3.3对结果数组中的信息按照出现的频数从大到小进行排序,基于特征类型的层次结构,在结果数组中寻找本产品特征的类型的上层类型,则对应的非本产品特征就是寻找的关联特征;3.4遍历产品特征结构树,当不存在本产品特征时,将本产品特征-关系-关联特征这个分支保存到分支数组中;当存在本产品特征时,先判断产品特征树中是否存在该分支,当不存在该分支时,将关联特征作为本产品特征的子节点,添加到产品特征结构树中;否则,不变;3.5将分支数组中的本产品特征与产品特征结构树中的节点进行匹配,当存在时,将该分支添加到树中对应节点上,并删除分支数组中的该分支,整理数组;否则,不变。
如图6所示,产品特征分为产品特征、部件特征、属性特征、功用特征、问题特征五大类;在特征结构树中,用五种关系符描述各类产品特征之间的语义关系,分别是part-of、attribute-of、use-of、problem-of和equal-to。下面对每种关系符的含义和适用范围进行说明:
(1)part-of:如“A part-of B”,表示B是A的部件特征,其中B是部件产品特征,A是部件产品特征或产品产品特征;
(2)attribute-of:如“A attribute-of B”,表示A是B的属性特征,其中A是属性产品特征,B是部件产品特征或产品产品特征;
(3)use-of:如“A use-of B”,表示A是B的功用特征,其中A是功用产品特征,B是部件产品特征或产品产品特征;
(4)problem-of:如“A problem-of B”,表示A是B的问题特征,其中A是问题产品特征,B是部件产品特征或产品产品特征;
(5)equal-to,如“A equal-to B”,表示A是B的同义词。
图7是产品特征结构树构造的原理图,概括地描述就是在优化分词结果中找到每个产品特征的关联特征,并保存到特征结构树数据库表中。如图7所示,遍历分词结果,定位产品特征的位置,找到与产品特征A在同一条评论中、在A的位置前面、且是第一个非A的产品特征Ai,统计各个Ai出现的频数,将Ai、Ai的类型、Ai的频数保存到list结构中;找到与产品特征A在同一条评论中、在A的位置后面、且是第一个非A的产品特征Ai,统计各个Ai出现的频数,将Ai、Ai的类型、Ai的频数保存到list结构中;遍历完优化分词结果后,Ai按出现的频数从大到小的顺序进行排序,根据特征类型层次结构和产品特征A的类型T,从排序结果中找到第一个T的上一层类型T1,则该T1所对应的产品特征A1就是产品特征A的关联特征;根据产品特征A、A和A1之间的关系relation、关联特征A1组成结构树的分支,判断特征结构树是否存在产品特征A,当不存在时,将A-relation-A1分支保存到分支数组中;当存在时,判断特征结构树是否存在该分支,当不存在时,将A1添加到A的子节点上;当存在时,不变;再次遍历特征结构树和分支数组,判断分支数组中的产品特征A是否能与产品特征结构树上的节点匹配,当能匹配时,将匹配的分支添加到结构树上,删除分支数组中的该条记录;当不匹配时,则不变。
图8是以产品特征之一的“屏幕”为例说明寻找关联特征步骤的流程图,使我们能详细的了解每个步骤的执行。如图8所示,寻找关联特征步骤如下:从featureword表(存放产品特征的表)中取出产品特征---屏幕和它的类型---部件,对total_fenci表(存放优化分词结果的表)进行遍历,定位屏幕在total_fenci表中的位置---第j条评论的第k位置,在第j条评论中,从第k-1位置开始往前寻找第一个产品特征Af,遍历featureword表,找到Af的类型lx,将Af存到data的list中,当data中存在Af时,则将频数结果+1;当data中不存在Af时,将Af、lx和1保存到data中;从第k+1位置开始往后的操作与往前操作相同;然后,判断第j条评论中是否还有存在屏幕,当存在时,操作与前一个屏幕的操作相同;当不存在时,则判断优化分词结果是否遍历完,当没有遍历完时,继续向下遍历,定位下一个屏幕的位置;当遍历完时,将data中的信息按Af出现的频数从大到小排序;接着,遍历data,当出现Af的类型lx为产品名时,lx对应的Af就是屏幕的关联特征。
图9是部分产品特征结构树的示例图,反映了数据库表中记录的存储形式,为接下来的产品特征定量分析和特征结构树的扩展提供研究对象,特征结构树的节点表示产品特征,枝干方向是从根节点到叶子节点,枝干表示两个节点之间的关系。
步骤4,产品特征的定量分析:4.1统计优化分词结果中所有产品特征出现的频数;4.2基于产品特征结构树和已统计的产品特征频数,统计产品特征中部件特征的频数;4.3分析句法分析结果中产品特征的支配词和上下文,查找情感词、程度副词和否定词语素,计算产品特征的情感得分;4.4可视化产品特征频数的统计结果和情感得分,分析用户对产品的关注点。
在提取句子中的否定词时,我们以情感词为中心,在其情感词的前面查找否定词,当找到否定词时,情感词的极性取反;否则,不变。查找范围是由以情感词为中心的检测窗口决定。为了确定窗口的大小,我们选取了评论数据中一定数量的带有否定词的用户评论作为实验语料,进行了六组不同大小窗口的否定词识别实验,实验结果用准确率(P)、召回率(R)和F值进行测评,其中,准确率(P)、召回率(R)和F值的计算方法如下:
其中,F1表示测试集中存在的否定句总数,F2表示程序识别出的否定句总数,F3表示程序正确识别的否定句总数。
如图10所示,根据测试结果,我们可以发现准确率(P)随着窗口的增大而减小,召回率(R)随着窗口的增大而变大,当窗口大小为4时,综合指标F值最大,所以最佳窗口的大小为4。由此,我们设定查找情感词的否定词是在情感词位置的上面四个词语的范围内。同理,我们可以通过实验知道程度副词的最佳窗口是3,所以设置查找情感词的程度副词是在情感词位置的上面三个词语的范围内。
图11是产品特征情感得分的计算流程图。如图11所示,从Featurewordtree表(保存产品特征结构树节点信息的表)中取一个节点A,对jufafenxi表(保存句法分析结果的表)进行遍历,定位A在句法分析中的位置,寻找A相应的支配词Z;判断Z是否是情感词,当Z不是情感词时,定位下一个A的位置,重复上述步骤;当Z是情感词时,遍历情感词词典,获得Z的类型和情感强度S,判断Z的类型,当Z的类型是P(褒义)时,Z的情感强度就是S;当Z的类型是N(贬义)时,Z的情感强度就是-S;当Z的类型是P(中性)时,Z的情感强度就是A所在评论的全部情感词的情感强度的算术平均数;在A所在位置的后面且在一条评论中寻找离A最近的情感词Q,判断Q的前面三个词语是否有程度副词D,当有程度副词D时,遍历程度副词表获得D的强度SD,则产品特征A的情感得分S变为SD×S;当没有程度副词D时,不变;接着判断Q的前面四个词语是否有否定词N,当有否定词N时,产品特征A的情感得分S变为-S;当不存在否定词N时,不变;然后,判断该条评论中是否还存在A,当存在时,计算出A的情感强度Si,比较各个Si的大小,取最大的S作为产品特征A的情感得分;当不存在时,则不执行操作;接着,将情感得分S存到Featurewordtree表中相对应的位置,判断jufafenxi表是否已经遍历完,当没遍历完时,重复以上步骤;当遍历完时,判断是否遍历完Featurewordtree表,当遍历完时,结束程序;当没有遍历完时,从Featurewordtree表中取下一个产品特征,重复上述步骤,直到遍历完Featurewordtree表。
图12是产品特征的定量描述的结果,我们将之进行可视化,让我们直观地了解各种统计结果。柱状图的横坐标表示产品特征,纵坐标表示产品特征出现的频数,在每个柱形条上显示了产品特征对应的频数结果。图13是产品特征分析的定量描述,柱状图的横坐标表示产品特征,纵坐标表示产品特征的情感得分,在每个柱形条上显示了产品特征对应的情感得分计算结果。
步骤5,产品特征结构树的扩展:5.1对同义子节点的扩展,通过定量计算特征相似度的方法,计算新产生的产品特征与产品特征结构树中的节点之间的相似度,来确定新产品特征的父节点,并将其添加到产品特征结构树中;5.2对隶属子节点的扩展,通过定量计算特征相关度的方法,计算新产生的产品特征与产品特征结构树中的节点之间的相关度,来确定新产品特征的父节点,并将其添加到产品特征结构树中。
在评论数据更新时,会产生新的产品特征,这时候需要对产品特征结构树进行扩展。特征结构树的扩展分为两类,一类是基于词语相似性的同义子节点扩展,同义子节点指与父节点词义相同的产品特征,所以新加入的产品特征与其父节点的语义关系为equal-to,另一类是基于词语相关性的隶属子节点扩展,隶属子节点指与父节点是上下位关系的产品特征,隶属子节点与其父节点的语义关系为part-of、attribute-of、use-of和problem-of中的一种,具体的取值由产品特征的种类确定。
本发明能够利用爬虫软件抓取网络上与指定产品相关的用户评论数据,并从中发现蕴含着的有价值的产品信息,改进产品的设计,使得产品更符合人机关系。利用本发明的方法,制造企业可以快速、有效地了解用户反馈的使用产品信息,有助于进行用户与企业之间的对话,帮助企业进行产品设计的改进。
- 还没有人留言评论。精彩留言会获得点赞!