基于脸部动作识别的音乐数据处理方法及系统与流程
本发明涉及数据处理领域,尤其涉及基于脸部动作识别的音乐数据处理。
背景技术:
现有技术中,多是利用鼠标、键盘、游戏杆、触控屏幕、外部传感器(如Wii、跳舞机踏板等)、人体姿势(如Kinect)等方式操作,实现人与相应场景的交互。其中,人体姿势操作方式,需要深度空间等信息,必须使用特定装置;因此需要侦测全身,需要较大的空间才能游戏。另外还有准确率低、偏移量高等问题,造成交互过程中的趣味性降低;另外此类形的场景交互大部份用于人体动作侦测(例:举手、踢脚),较少与真实影像结合。
目前脸部关键点识别的应用主要与图像合成技术结合,将脸部变成其他动物、戴上不同饰品、并结合脸部动作产生动画等等。
提供瘦脸与脸部复健等脸部运动时的应用:传统脸部运动透过文字的流程描述或透过学习影片中的人脸运动示范达到脸部运动的效果,但此类脸部运动过程并没有与真实影像结合,体验度低。
因此,现有技术中的缺陷是,对于人与相应场景的交互,需要通过外部设备辅助实现,实现方式单一,用户体验低。无法将脸部关键点识别技术和真实影像相结合。
技术实现要素:
针对上述技术问题,本发明提供一种基于脸部动作识别的音乐数据处理方法及系统,采用了基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
为解决上述技术问题,本发明提供的技术方案是:
第一方面,本发明提供一种基于脸部动作识别的音乐数据处理方法,包括:
步骤S1,获得背景音乐数据和前景音乐数据,所述背景音乐数据和所述前景音乐数据分别为一段数秒钟至数分钟长的音乐;
步骤S2,将所述前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
步骤S3,在前景音乐时间内检测人的面部动作,获得在所述前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;
步骤S4,将所述背景音乐数据进行持续播放,并将所述每个脸部动作数据与其对应的所述一小节时间长度的前景音乐数据进行匹配,与所述背景音乐结合,生成新的音乐。
本发明的技术方案是:先获得背景音乐数据和前景音乐数据,所述背景音乐数据和所述前景音乐数据分别为一段数秒钟至数分钟长的音乐;然后将所述前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
接着在前景音乐时间内检测人的面部动作,获得在所述前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;最后将所述背景音乐数据进行持续播放,并将所述每个脸部动作数据与其对应的所述一小节时间长度的前景音乐数据进行匹配,与所述背景音乐结合,生成新的音乐。
本发明基于脸部动作识别的音乐数据处理方法,采用了基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
进一步地,所述步骤S2之后,还包括:
将所述背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应唯一一小节前景音乐;
根据所述目标脸部动作数据,获得在所述每小节开始的前后一拍时间内的脸部动作数据;
将所述脸部动作数据与所述目标脸部动作数据进行匹配判定,进行一小节前景音乐播放的选取:
当所述脸部动作数据与所述目标脸部动作数据匹配,播放所述一小节前景音乐,所述一小节前景音乐为与所述目标脸部动作数据唯一对应的前景音乐;
当所述脸部动作数据与所述目标脸部动作数据不匹配,不播放所述脸部动作数据对应的一小节前景音乐。
进一步地,所述步骤S2之后,还包括:
将所述背景音乐数据进行持续播放,获得虚拟场景数据,所述虚拟场景数据为向人面部中各个部位移动物体的虚拟场景数据;
根据所述向人面部中各个部位移动物体的虚拟场景数据,获得对应的脸部动作数据,所述对应的脸部动作数据的获取在所述移动物体到达所述人面部中的部位之前;
将所述脸部动作数据与所述虚拟场景数据进行匹配判定,进行所述虚拟场景数据中对应移动物体的处理:
当所述脸部动作数据与所述虚拟场景数据匹配,将所述虚拟场景数据中对应移动物体移除;
当所述脸部动作数据与所述虚拟场景数据不匹配,对所述虚拟场景数据中对应移动物体不作处理;
在所述每小节开始的后一拍时间后,没有对应的脸部动作与目标脸部动作数据匹配,将所述虚拟场景数据中对应移动物体移除。
进一步地,将所述虚拟场景数据中对应移动物体移除之后,包括:
获得所述虚拟场景数据中对应移动物体移除的效果数据;
根据所述虚拟场景数据中对应移动物体移除的效果数据,对与所述虚拟场景数据匹配的所述脸部动作数据进行评价,得到评价结果。
进一步地,通过人脸关键点识别和模糊控制理论进行脸部动作的识别。
本发明一种基于脸部动作识别的音乐数据处理方法,基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,即通过人脸不动作的识别,与对应场景的音乐数据进行匹配,实现音乐的创作,音乐的播放及场景中对应虚拟物品的消除,以动画的方式展现在用户眼前,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
进一步地,还包括:
将所述背景音乐数据进行持续播放,获得目标脸部动作数据,所述目标脸部动作数据对应一小节前景音乐,所述前景音乐分为第一前景音乐和第二前景音乐,所述第一前景音乐与所述背景音乐匹配播放,所述第二前景音乐与所述背景音乐不匹配播放;
根据所述目标脸部动作数据,获得在所述每小节开始的前后一拍时间内的脸部动作数据;
将所述脸部动作数据与所述目标脸部动作数据进行匹配判定,进行所述目标脸部动作数据对应一小节前景音乐的播放选取:
当所述脸部动作数据与所述目标脸部动作数据匹配,播放所述目标脸部动作数据对应一小节前景音乐,且所述一小节前景音乐为与所述目标脸部动作数据对应的第一前景音乐;
当所述脸部动作数据与所述目标脸部动作数据不匹配,播放所述目标脸部动作数据对应一小节前景音乐,且所述一小节前景音乐为与所述目标脸部动作数据对应的第二前景音乐。
在脸部动作数据与目标动作数据匹配目标脸部动作数据成功匹配后,对应播放该目标脸部动作对应的一小节前景音乐,并且,第一前景音乐与背景音乐相匹配和谐的播放,反之,如果用户做出的脸部动作数据与目标脸部动作数据不匹配,则对应播放目标脸部动作对应的第二前景音乐,第二前景音乐与背景音乐是不相匹配和谐播放的,这样通过播放音乐的不同就可判断出用户做出的脸部动作数据是否与目标脸部动作数据匹配成功,提高了用户体验。
第二方面,本发明提供了一种基于脸部动作识别的音乐数据处理系统,包括:
音乐数据获取模块,用于获得背景音乐数据和前景音乐数据,所述背景音乐数据和所述前景音乐数据分别为一段数秒钟至数分钟长的音乐;
音乐数据处理模块,用于将所述前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
脸部动作获取模块,用于在前景音乐时间内检测人的面部动作,获得在所述前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;
音乐创作模块,用于将所述背景音乐数据进行持续播放,并将所述每个脸部动作数据与其对应的所述一小节时间长度的前景音乐数据进行匹配,与所述背景音乐结合,生成新的音乐。
本发明的技术方案为:先通过音乐数据获取模块,获得背景音乐数据和前景音乐数据,所述背景音乐数据和所述前景音乐数据分别为一段数秒钟至数分钟长的音乐;然后通过音乐数据处理模块,将所述前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
接着通过脸部动作获取模块,在前景音乐时间内检测人的面部动作,获得在所述前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;最后通过音乐创作模块,将所述背景音乐数据进行持续播放,并将所述每个脸部动作数据与其对应的所述一小节时间长度的前景音乐数据进行匹配,与所述背景音乐结合,生成新的音乐。
本发明一种基于脸部动作识别的音乐数据处理系统,采用了基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
进一步地,所述音乐数据处理模块之后,还包括音乐选择播放模块,用于:
将所述背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应唯一一小节前景音乐;
根据所述目标脸部动作数据,获得在所述每小节开始的前后一拍时间内的脸部动作数据;
将所述脸部动作数据与所述目标脸部动作数据进行匹配判定,进行一小节前景音乐播放的选取:
当所述脸部动作数据与所述目标脸部动作数据匹配,播放所述一小节前景音乐,所述一小节前景音乐为与所述目标脸部动作数据唯一对应的前景音乐;
当所述脸部动作数据与所述目标脸部动作数据不匹配,不播放所述脸部动作数据对应的一小节前景音乐。
进一步地,所述音乐数据处理模块之后,还包括音乐虚拟场景模块,用于:
将所述背景音乐数据进行持续播放,获得虚拟场景数据,所述虚拟场景数据为向人面部中各个部位移动物体的虚拟场景数据;
根据所述向人面部中各个部位移动物体的虚拟场景数据,获得对应的脸部动作数据,所述对应的脸部动作数据的获取在所述移动物体到达所述人面部中的部位之前;
将所述脸部动作数据与所述虚拟场景数据进行匹配判定,进行所述虚拟场景数据中对应移动物体的处理:
当所述脸部动作数据与所述虚拟场景数据匹配,将所述虚拟场景数据中对应移动物体移除;
当所述脸部动作数据与所述虚拟场景数据不匹配,对所述虚拟场景数据中对应移动物体不作处理;
在所述每小节开始的后一拍时间后,没有对应的脸部动作与目标脸部动作数据匹配,将所述虚拟场景数据中对应移动物体移除。
进一步地,所述音乐虚拟场景模块中,包括效果评价子模块,在将所述虚拟场景数据中对应移动物体移除之后,所述效果评价子模块用于:
获得所述虚拟场景数据中对应移动物体移除的效果数据;
根据所述虚拟场景数据中对应移动物体移除的效果数据,对与所述虚拟场景数据匹配的所述脸部动作数据进行评价,得到评价结果。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。
图1示出了本发明第一实施例所提供的一种基于脸部动作识别的音乐数据处理方法的流程图;
图2示出了本发明第一实施例所提供的一种基于脸部动作识别的音乐数据处理方法中时间轴的第一示意图;
图3示出了本发明第一实施例所提供的一种基于脸部动作识别的音乐数据处理方法中时间轴的第二示意图;
图4示出了本发明第二实施例所提供的一种基于脸部动作识别的音乐数据处理系统的示意图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只是作为示例,而不能以此来限制本发明的保护范围。
实施例一
图1示出了本发明第一实施例所提供的一种基于脸部动作识别的音乐数据处理方法的流程图;如图1所示,本发明实施例一提供一种基于脸部动作识别的音乐数据处理方法,包括:
步骤S1,获得背景音乐数据和前景音乐数据,背景音乐数据和前景音乐数据分别为一段数秒钟至数分钟长的音乐;
步骤S2,将前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
步骤S3,在前景音乐时间内检测人的面部动作,获得在前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;
步骤S4,将背景音乐数据进行持续播放,并将每个脸部动作数据与其对应的一小节时间长度的前景音乐数据进行匹配,与背景音乐结合,生成新的音乐。
本发明的技术方案是:先获得背景音乐数据和前景音乐数据,背景音乐数据和前景音乐数据分别为一段数秒钟至数分钟长的音乐;然后将前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
接着在前景音乐时间内检测人的面部动作,获得在前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;最后将背景音乐数据进行持续播放,并将每个脸部动作数据与其对应的一小节时间长度的前景音乐数据进行匹配,与背景音乐结合,生成新的音乐。
本发明基于脸部动作识别的音乐数据处理方法,可以设置不同的场景信息,不同的场景信息有不同的需求,需要在规定时间内按照场景信息中不同的需求完成,如果不同的场景信息与不同脸部动作匹配,则可以实现不同的动作,进而实现各种人与场景的互动。
本发明基于脸部动作识别的音乐数据处理方法,采用了基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
具体地,步骤S2之后,还包括:
将背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应唯一一小节前景音乐;
根据目标脸部动作数据,获得在每小节开始的前后一拍时间内的脸部动作数据;
将脸部动作数据与目标脸部动作数据进行匹配判定,进行一小节前景音乐播放的选取:
当脸部动作数据与目标脸部动作数据匹配,播放一小节前景音乐,一小节前景音乐为与目标脸部动作数据唯一对应的前景音乐;
当脸部动作数据与目标脸部动作数据不匹配,不播放脸部动作数据对应的一小节前景音乐。
具体地,设置多小节的前景音乐,每小节前景音乐对应唯一一个脸部动作,对应的在第一个脸部动作与第一个目标脸部动作匹配成功后,进行下一个脸部动作与下一个目标脸部动作的匹配,这样可以根据不同的目标脸部动作,实现前景音乐的连续播放。
具体地,步骤S2之后,还包括:
将背景音乐数据进行持续播放,获得虚拟场景数据,虚拟场景数据为向人面部中各个部位移动物体的虚拟场景数据;
根据向人面部中各个部位移动物体的虚拟场景数据,获得对应的脸部动作数据,对应的脸部动作数据的获取在移动物体到达人面部中的部位之前;
将脸部动作数据与虚拟场景数据进行匹配判定,进行虚拟场景数据中对应移动物体的处理:
当脸部动作数据与虚拟场景数据匹配,将虚拟场景数据中对应移动物体移除;
当脸部动作数据与虚拟场景数据不匹配,对虚拟场景数据中对应移动物体不作处理;
在每小节开始的后一拍时间后,没有对应的脸部动作与目标脸部动作数据匹配,将虚拟场景数据中对应移动物体移除。
结合AR技术,于真实场景中对应人脸面部位置设置不同的虚拟物品向人脸移动,在虚拟物品移动到人脸面部位置上之时间点前后一拍时间为时间界限,对应做出每个虚拟物品对应的消除动作,人所做的脸部动作与消除动作匹配成功后,接着做下一个动作,增加了趣味性,同时匹配成功或失败会有不同的音效和动画。经过一段时间后,匹配时间缩短,匹配消除动作速度会加快。
具体地,将虚拟场景数据中对应移动物体移除之后,包括:
获得虚拟场景数据中对应移动物体移除的效果数据;
根据虚拟场景数据中对应移动物体移除的效果数据,对与虚拟场景数据匹配的脸部动作数据进行评价,得到评价结果。
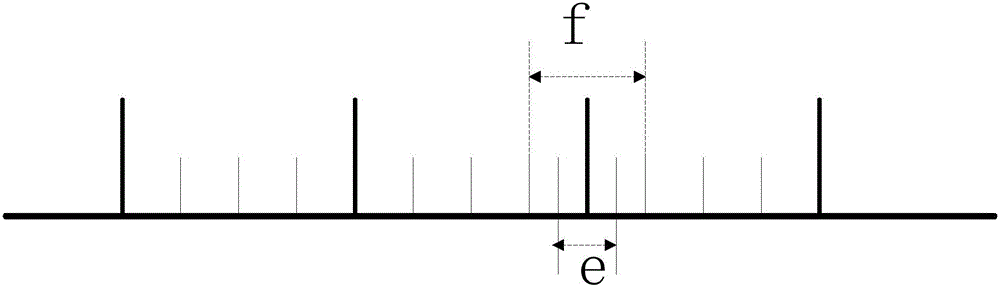
如图2所示,横轴为时间轴,左边代表较早的时间、右边代表较晚的时间。较粗长的纵轴为小节分隔点,较细短的代表拍点的分隔点。在此图例中,驱动范围为每小节开始的前两拍皆为正确驱动,以每小节开始前一拍前后0.5拍为完美驱动,如图2中,e显示的部份,e的前后0.5拍为普通驱动,如f显示的部份。完美、普通的驱动时间及范围皆可自由替换。以此方法来做对虚拟场景数据匹配脸部动作数据的评价标准。
具体地,通过人脸关键点识别和模糊控制理论进行脸部动作的识别。
本发明中,基于上述的音乐数据处理,是以人脸关键点识别为基础,建立一可靠之脸部追踪系统,最后结合模糊控制理论精确识别脸部动作:眨眼、斗鸡眼、挑眉、皱眉、皱鼻、伸舌、嘟嘴、张嘴、歪嘴、舔唇、抿唇、点头、头部左右旋转、头部上下旋转等等。其中人脸关键点识别技术为公知的现有技术,在此不做过多叙述。
具体地,还包括:
将背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应一小节前景音乐,前景音乐分为第一前景音乐和第二前景音乐,第一前景音乐与背景音乐匹配播放,第二前景音乐与背景音乐不匹配播放;
根据目标脸部动作数据,获得在每小节开始的前后一拍时间内的脸部动作数据;
将脸部动作数据与目标脸部动作数据进行匹配判定,进行目标脸部动作数据对应一小节前景音乐的播放选取:
当脸部动作数据与目标脸部动作数据匹配,播放目标脸部动作数据对应一小节前景音乐,且一小节前景音乐为与目标脸部动作数据对应的第一前景音乐;
当脸部动作数据与目标脸部动作数据不匹配,播放目标脸部动作数据对应一小节前景音乐,且一小节前景音乐为与目标脸部动作数据对应的第二前景音乐。
在脸部动作数据与目标动作数据匹配目标脸部动作数据成功匹配后,对应播放该目标脸部动作对应的一小节前景音乐,并且,第一前景音乐与背景音乐相匹配和谐的播放,反之,如果用户做出的脸部动作数据与目标脸部动作数据不匹配,则对应播放目标脸部动作对应的第二前景音乐,第二前景音乐与背景音乐是不相匹配和谐播放的,这样通过播放音乐的不同就可判断出用户做出的脸部动作数据是否与目标脸部动作数据匹配成功,提高了用户体验。
具体地,第一前景音乐可设置为表示成功的音乐,第二前景音乐可设置成表示失败的前景音乐,这样使音乐更有区别性。
如图3所示,横轴为时间轴,左边代表较早的时间、右边代表较晚的时间。较粗长的纵轴为小节分隔点,较细短的代表拍点的分隔点。以图3中的例子,c的范围为一小节,d的范围为一拍。a为侦测时间点,图3中代表在每小节开始的前后一拍为侦测时间点,任何在此时间点做的脸部动作会被侦测到。b为作用范围,通常以一小节为单位,在此图中代表在此小节的前后一拍范围内做表情,皆会驱动此小节做出反馈。每小节几拍、侦测时间点及作用范围皆可自由替换。
本发明一种基于脸部动作识别的音乐数据处理方法,基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,即通过人脸不动作的识别,与对应场景的音乐数据进行匹配,实现音乐的创作,音乐的播放及场景中对应虚拟物品的消除,以动画的方式展现在用户眼前,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
实施例二
图4示出了本发明第二实施例所提供的一种基于脸部动作识别的音乐数据处理系统的示意图;如图4所示,本发明实施例二提供了一种基于脸部动作识别的音乐数据处理系统10,包括:
音乐数据获取模块101,用于获得背景音乐数据和前景音乐数据,背景音乐数据和前景音乐数据分别为一段数秒钟至数分钟长的音乐;
音乐数据处理模块102,用于将前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
脸部动作获取模块103,用于在前景音乐时间内检测人的面部动作,获得在前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;
音乐创作模块104,用于将背景音乐数据进行持续播放,并将每个脸部动作数据与其对应的一小节时间长度的前景音乐数据进行匹配,与背景音乐结合,生成新的音乐。
本发明的技术方案为:先通过音乐数据获取模块101,获得背景音乐数据和前景音乐数据,背景音乐数据和前景音乐数据分别为一段数秒钟至数分钟长的音乐;然后通过音乐数据处理模块102,将前景音乐数据按节拍分成多段小节,每小节包含多个拍子;
接着通过脸部动作获取模块103,在前景音乐时间内检测人的面部动作,获得在前景音乐时间内的多个脸部动作数据,每个脸部动作对应一小节时间长度的前景音乐数据;最后通过音乐创作模块104,将背景音乐数据进行持续播放,并将每个脸部动作数据与其对应的一小节时间长度的前景音乐数据进行匹配,与背景音乐结合,生成新的音乐。
本发明一种基于脸部动作识别的音乐数据处理系统10,采用了基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
具体地,音乐数据处理模块102之后,还包括音乐选择播放模块,用于:
将背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应唯一一小节前景音乐;
根据目标脸部动作数据,获得在每小节开始的前后一拍时间内的脸部动作数据;
将脸部动作数据与目标脸部动作数据进行匹配判定,进行一小节前景音乐播放的选取:
当脸部动作数据与目标脸部动作数据匹配,播放一小节前景音乐,一小节前景音乐为与目标脸部动作数据唯一对应的前景音乐;
当脸部动作数据与目标脸部动作数据不匹配,不播放脸部动作数据对应的一小节前景音乐。
具体地,音乐数据处理模块102之后,还包括音乐虚拟场景模块,用于:
将背景音乐数据进行持续播放,获得虚拟场景数据,虚拟场景数据为向人面部中各个部位移动物体的虚拟场景数据;
根据向人面部中各个部位移动物体的虚拟场景数据,获得对应的脸部动作数据,对应的脸部动作数据的获取在移动物体到达人面部中的部位之前;
将脸部动作数据与虚拟场景数据进行匹配判定,进行虚拟场景数据中对应移动物体的处理:
当脸部动作数据与虚拟场景数据匹配,将虚拟场景数据中对应移动物体移除;
当脸部动作数据与虚拟场景数据不匹配,对虚拟场景数据中对应移动物体不作处理;
在每小节开始的后一拍时间后,没有对应的脸部动作与目标脸部动作数据匹配,将虚拟场景数据中对应移动物体移除。
具体地,音乐虚拟场景模块104中,包括效果评价子模块,在将虚拟场景数据中对应移动物体移除之后,效果评价子模块用于:
获得虚拟场景数据中对应移动物体移除的效果数据;
根据虚拟场景数据中对应移动物体移除的效果数据,对与虚拟场景数据匹配的脸部动作数据进行评价,得到评价结果。
具体地,还包括脸部动作识别模块100,用于通过人脸关键点识别和模糊控制理论进行脸部动作的识别。
具体地,还包括音乐选择播放模块,用于:
将背景音乐数据进行持续播放,获得目标脸部动作数据,目标脸部动作数据对应一小节前景音乐,前景音乐分为第一前景音乐和第二前景音乐,第一前景音乐与背景音乐匹配播放,第二前景音乐与背景音乐不匹配播放;
根据目标脸部动作数据,获得在每小节开始的前后一拍时间内的脸部动作数据;
将脸部动作数据与目标脸部动作数据进行匹配判定,进行目标脸部动作数据对应一小节前景音乐的播放选取:
当脸部动作数据与目标脸部动作数据匹配,播放目标脸部动作数据对应一小节前景音乐,且一小节前景音乐为与目标脸部动作数据对应的第一前景音乐;
当脸部动作数据与目标脸部动作数据不匹配,播放目标脸部动作数据对应一小节前景音乐,且一小节前景音乐为与目标脸部动作数据对应的第二前景音乐。
在脸部动作数据与目标动作数据匹配目标脸部动作数据成功匹配后,对应播放该目标脸部动作对应的一小节前景音乐,并且,第一前景音乐与背景音乐相匹配和谐的播放,反之,如果用户做出的脸部动作数据与目标脸部动作数据不匹配,则对应播放目标脸部动作对应的第二前景音乐,第二前景音乐与背景音乐是不相匹配和谐播放的,这样通过播放音乐的不同就可判断出用户做出的脸部动作数据是否与目标脸部动作数据匹配成功,提高了用户体验。
具体地,第一前景音乐可设置为表示成功的音乐,第二前景音乐可设置成表示失败的前景音乐,这样使音乐更有区别性。
本发明一种基于脸部动作识别的音乐数据处理系统,基于脸部关键点识别技术,将音乐数据和真实影像相结合的方式,实现人与相应场景的交互,即通过人脸部动作的识别,与对应场景的音乐数据进行匹配,实现音乐的创作,音乐的播放及场景中对应虚拟物品的消除,以动画的方式展现在用户眼前,不需要借助外部设置进行辅助,实现方式简单,提高了用户体验。
实施例三
结合本发明实施例一中的一种基于脸部动作识别的音乐数据处理方法,及实施例二中的一种基于脸部动作识别的音乐数据处理系统,结合具体的游戏场景进行说明。
场景一
乐曲创作:背景音乐持续播放,而每个脸部动作对应到一段一小节时间长度的前景音乐,在每小节开始的前后一拍时间内侦测到的脸部动作,皆会驱动该小节播放对应的前景音乐。比如设置一系列脸部动作,眨眼、挑眉、皱眉、皱鼻等,然后识别人的脸部动作,根据识别的脸部动作的不同,对应的播放不同的音乐,每次播放的小节音乐组成不同的音乐,使用户根据自己的心情创做不同的音乐。
场景二
音乐游戏:背景音乐及前景音乐为一段数分钟的音乐,背景音乐持续播放,游戏依然以小节为单位,每小节会由游戏随机产生指定脸部动作,玩家必须在驱动时间内(每小节开始前后一拍时间)完成指定脸部动作,该小节的前景音乐会持续播放;若有多于一个前景音乐,亦可能在做了正确表情越多次后将音乐叠加上去。将动感音乐与人脸动作结合,使游戏更有挑战性和趣味性。
场景三
AR节奏游戏:背景音乐持续播放,画面上会有不同物品有节奏性的往脸上各个部位移动,玩家必须在物品移动到该部位时,做对应的表情移除该物品。例如:蚊子往眼睛飞过去,必须在蚊子到达眼睛时眨眼将它杀掉。成功(分为完美、普通)或失败会有不同的音效、动画及计分。经过一段时间后,节奏速度会加快,增加游戏困难度。
直接利用摄像头取得的影像作脸部动作识别来操作游戏,并能实时与真实脸部影像结合产生有趣的动画效果。此操作方式不需另外购买设备,即可实时、准确地分辨脸部动作;且不需要四肢的操作方式,亦可造福行动不便的人,让他们也能享受到游戏的乐趣。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!