一种面向对象的分类规则集自动构建方法与流程
本发明涉及图像处理和计算机视觉领域,尤其涉及一种基于图像分割后根据对象域中对象特征属性的分类规则集确定方法,即一种面向对象的分类规则集自动构建方法。
背景技术:
在面向对象分类过程中,通过对图像中相邻同质像元进行合并而形成图像对象,虽然丢失了部分像素信息,但同时获得了大量基于对象的光谱、形状、纹理等特征,利用大量的基于对象特征进行分类,能够有效的避免基于像元分类的椒盐效应,同时提高信息提取的精度。
规则集的建立是面向对象分类的关键技术,该方法易于理解,运行时间短,可移植性较强,同时能够实现目标类型的单独提取,优势明显,但也有不足,在基于规则的信息提取中,面对上百种基于对象的特征,目前多依靠经验选择目标类型的特征,然后通过反复试验的方法来手动确定阈值,在该过程中:①难以确定有效的分类特征②难以确定有效的分类阈值③难以确定不同地物和不同特征的提取顺序和难度。
针对上述规则集建立过程中的难点,本发明提出基于典型样本的特征预选,子类型特征分离度和阈值计算,以及在各个子类构建规则的基础上,对规则进行分层分类优化等实现规则集的自动确定方法,是当前面向对象规则集构建的重要趋势。
技术实现要素:
本发明的目的在于提供一种面向对象的分类规则集自动构建方法,即基于图像分割后根据对象域中对象特征属性的分类规则集确定方法。
包括如下步骤:
步骤(1)输入待分类图像对象样本特征集;
步骤(2)计算所有样本两两特征的相关性指数Ri,j,并分别求解各子类样本特征值的内部差异指数Stdi;
步骤(3)根据研究需求,对步骤(2)所得Ri,j和Stdi设定阈值,以去除部分冗余特征;
步骤(4)利用J-M距离和高斯概率分布公式计算各子类间分离度J和分离阈值Th,然后计算各非目标子类的NT值,对NT值为1的非目标子类建立规则进行掩膜去除;
步骤(5)利用步骤(4)确定的各子类间的分离度和分离阈值,计算各目标子类的T值,对T值为1的目标子类建立规则进行掩膜提取;
步骤(6)依据步骤(4)确定的剩余各子类间的分离度和分离阈值,计算各子类规则的分离度均值RJM,对RJM值最高的子类建立规则优先进行掩膜提取。
步骤(7)在步骤(6)提取子类后更新剩余子类数量,再次执行步骤(6),直至提取到所有子类。
步骤(8)建立规则合并所有目标子类,并将所有建立的规则合并为规则集。
上述技术方案中,步骤(2)所述的相关性指数和内部差异指数如下:
其中,K表示所有样本的总数,表示特征集中第l个样本的第i个特征,表示所有样本中第i个特征的均值。
步骤(4)所述的J-M距离和高斯概率分布计算公式如下:
J=2(1-e-B)
其中
其中,m1和m2表示两个子类的某特征均值,σ1和σ2表示两个子类的某特征标准差,n1和n2表示两个类别的样本数。
所述的NT值和T值计算如下:
NT=1/t
T=1/nt
其中,t为与目标子类有关的规则数目,nt为与非目标子类有关的规则数目,对NT值为1的非目标子类建立规则进行掩膜去除,对T值为1的目标子类建立规则进行掩膜提取。
所述的分离度均值RJM计算如下:
其中,如果计算的为目标子类RJM,n表示所有规则数量,Jn(k)表示第n条规则里第k个特征对应的J-M距离,m、p、q表示第n条规则里子类的数目;如果计算的为非目标子类RJM,n表示与目标子类有关的规则数量,Jn(k)表示第n条与目标子类有关的规则里第k个与目标子类有关的特征对应的J-M距离,m、p、q表示第n条规则里非目标子类的数目。
本发明的面向对象的分类规则集自动构建方法,是基于典型样本的特征预选,子类型特征分离度和阈值计算,以及在各个子类构建规则的基础上,对规则进行分层分类优化等实现规则集的自动确定方法,无需依赖于经验及反复试验,是当前面向对象规则集构建的重要趋势。
附图说明
图1为本发明中图像分类规则集确定方法的过程图;
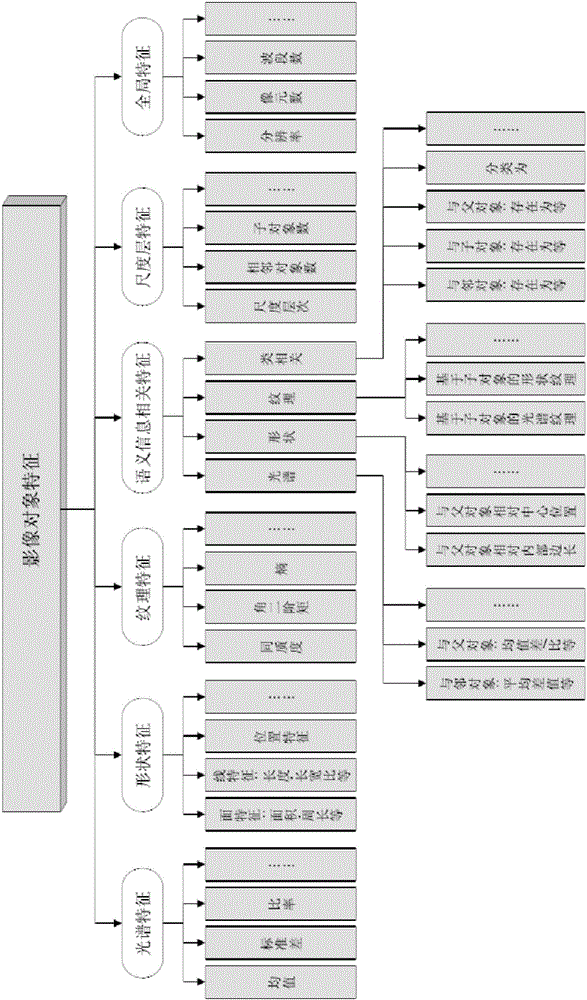
图2为待分类对象样本的特征类型示意图。
具体实施方式
下面结合附图及示例详细描述本发明,本发明的目的和方法将变得更加明显。
示例说明:如需构建的规则集为植被地类提取规则集,则目标地类为植被,非目标地类为非植被,目标子类为草地,林地和农田,非目标子类为水体、建筑物、道路、裸地等,本发明的构建方法流程如图1所示,具体为:
1)输入各目标子类样本图像对象的特征集,特征集可包含的特征如图2所示。
2)特征预选
1.计算所有样本两两特征的相关性指数Ri,j(一致性),并分别求解各子类样本特征值的内部差异指数Stdi,计算公式如下:
其中,K表示所有样本的总数,表示特征集中第l个样本的第i个特征,表示所有样本中第i个特征的均值。
2.根据图像及具体需求确定相关性系数和各子类方差设定阈值,建议选择在相关性较高的特征中去除内部差异较小的特征。如考虑到草地、林地和农田的特征较为接近,在阈值设定时选择相关性系数为0.95的两个特征中内部差异指数较低的特征作为冗余特征去除。
3)计算各子类间各特征分离度与分类阈值
对每个特征,均利用J-M距离和高斯概率分布公式计算各子类间分离度J和分离阈值Th,计算过程如下:
J=2(1-e-B)
其中
其中,m1和m2表示两个子类的该特征均值,σ1和σ2表示两个子类的该特征标准差,n1和n2表示两个类别的样本数。
根据两两子类间最大分离度对应的特征及阈值建立区分规则,可以对目标子类与其它所有子类分别构建规则以实现子类的提取,若目标子类与多个其它子类间最大分离度对应的特征一致,则可以使用一条规则进行区分。
4)非目标子类规则优选
计算各非目标子类的NT值,对NT值为1的非目标子类建立规则进行掩膜去除,NT值计算如下:
NT=1/t
其中,t为与目标子类有关的规则数目;
比如:计算水体的NT值,根据步骤3)中所得各子类间各特征分离度和分离阈值,其中若水体与各目标子类(草地、林地和农田)最大分离度对应的特征一致,则t=1,若对应特征有n个,则t=n。
5)目标子类规则优选
计算各目标子类的T值,对T值为1的目标子类建立规则进行掩膜提取,T值计算如下:
T=1/nt
其中,nt为与非目标子类有关的规则数目;
比如:计算草地的T值,根据步骤3)中所得各子类间各特征分离度和分离阈值,其中若草地与各非目标子类(水体、建筑物、道路和裸地)最大分离度对应的特征一致,则nt=1,若对应特征有n个,则nt=n。
6)剩余子类提取规则优选
计算各子类规则的分离度均值RJM,对RJM值最高的子类建立规则优先进行掩膜提取,RJM值计算如下:
其中,如果计算的为目标子类RJM,n表示所有规则数量,Jn(k)表示第n条规则里第k个特征对应的J-M距离,m、p、q表示第n条规则里子类的数目;如果计算的为非目标子类RJM,n表示与目标子类有关的规则数量,Jn(k)表示第n条与目标子类有关的规则里第k个与目标子类有关的特征对应的J-M距离,m、p、q表示第n条规则里非目标子类的数目。
比如:计算目标子类草地RJM,若剩余子类为水体,农田,林地,最大分离度对应特征分别为c1,c1,c2,分离度为s1,s2,s3,则由于水体和农田最大分离度对应特征一致,故建立的规则数n=2,J1(1)=s1,J1(2)=s2,J2(1)=s3,m=2,p=1。
计算非目标子类水体RJM,若剩余子类为道路,农田,林地,最大分离度对应特征分别为c1,c2,c3,分离度为s1,s2,s3,则由于道路为非目标子类,故建立的规则数n=2,J1(1)=s2,J2(1)=s3,m=1,p=1。
7)剩余子类提取规则排序
在步骤6)提取子类后更新剩余子类数量,再次执行步骤6),直至提取到所有子类。
8)目标类型提取
建立规则合并所有目标子类,并将所有建立的规则合并为规则集。
上述的对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!