一种面向不同类型负载的多租户资源优化调度方法与流程
本发明涉及一种多租户资源管理技术,特别涉及一种面向不同类型负载的多租户资源优化调度方法。
背景技术:
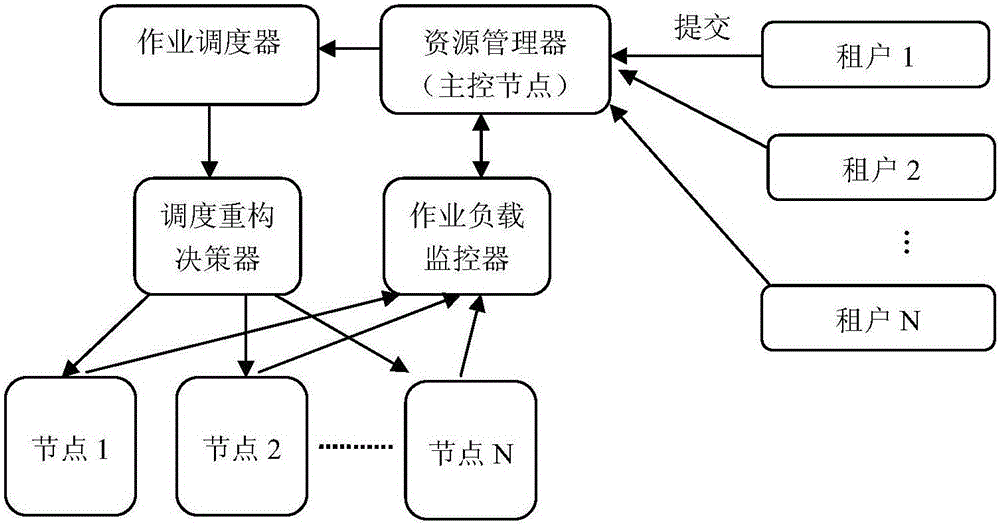
:近年来,网络信息技术突飞猛进,海量的数字化信息与人们获取所需信息能力之间的矛盾日益突出。另一方面,MapReduce、Dryad和Spark等分布式计算框架的应用使得用户在容忍的时间内从海量资料库中找到正确的信息成为可能。传统的Web多租户系统需要处理复杂的业务逻辑、因而也需要保障较高的数据一致性级别、支持复杂的数据查询。与之相反,基于大数据平台的多租户系统往往具有数据量非常大、不要求严格的一致性、只支持简单的查询、支持可用资源的动态扩展的特点。大数据平台对用户提供的是存储和计算的应用服务,平台具有开源Hadoop框架强大的资源管理和任务调度的支持,有较好的负载均衡机制,同时在其上还可以方便的部署搭建许多强大的大数据处理组件,如:Hive、Spark、Storm等,这为多应用共享集群资源提供了无可比拟的优势,然而采用共享应用实例的架构意味着需要支持较高的租户密度以及较低的管理成本和维护成本,实现大数据平台的多租户架构面临着数据本地化、按需扩展、性能优化等方面的挑战。多租户共享集群是Hadoop框架下应用的典型场景,然而资源的共享使得作业之间存在竞争性,导致可计算资源包含某一作业待处理数据的可能性降低,带来较低的数据本地化程度,因而需要经常从远地拷贝数据,由此带来的占用网络带宽、计算效率低下等问题非常突出。基于Hadoop框架的云计算平台中,由于计算资源所需要的数据处于不同的物理位置,需要迁移数据,即数据本地化问题。由于只有当数据和计算任务处于同一节点时,计算效率才能够得到保证,因此数据的本地化程度是决定Hadoop框架下云计算效率的重要因素。如何提高数据本地化程度,节省网络带宽资源,提高任务的执行效率,保证用户作业服务质量的同时维护集群整体吞吐率是应用多用户共享式集群需要解决的核心问题。为了解决数据本地化问题,核心思想是采用移动计算而非移动数据,即把计算任务迁移到距离数据更近的位置。基于上述思想,美国的MateiZaharia等学者在公平调度器的基础上提出了延迟调度算法,其核心思想是:允许就绪作业在一定时间内放弃若干次调度机会,直至时间超时或者该作业存在计算任务的待处理数据距离计算资源较近,则接受当前调度资源,否则放弃。张博钰等人对延迟调度算法进行进一步的研究,给出了延迟调度算法延迟间隔选择的一个较为理想的方案。陶永才等人则在延迟调度的基础上充分考虑集群的负载均衡,提出基于负载均衡的动态延迟调度机制DDS(DynamicDelayScheduling),上述研究均表明采用延迟调度算法的公平调度器可以很好的做到作业调度中公平性和效率之间的均衡。美国MohammadHammoud等学者针对数据本地优化设计了一种Reduce作业调度器LARTS,将节点网络位置和Reducer’spartitions大小作为调度器的决策条件,大幅度地提高了集群的效率。类似的,美国ShadiIbrahim等学者也提出了一个本地感知算法,不过它是通过改变partition函数的hash算法来实现的,XiangpingBu等人提出了一种适用于MapReduce的虚拟集群本地感知调度算法,为MapReduce程序减轻干扰的同时保持数据的本地化。虽然最近几年在多租户资源管理方向已经开展了不少研究工作,然而,目前基于大数据平台的多租户资源优化调度研究主要是针对资源公平性的调度。同时,现有的延迟调度算法多是基于固定的等待时间,而且没有充分考虑作业的不同负载类型。假设作业的大部分数据集中在某个节点或者集群中少数数据节点上,可能出现计算任务也同样集中在集群中某一节点或部分节点上,从而导致作业较低的并行效率以及较长的响应时间。因此,针对作业的不同负载类型进行多租户资源优化调度是多租户资源管理领域亟待解决的重要问题。技术实现要素:鉴于上述现有技术存在的不足,本发明目的是提供一种面向不同类型负载的多租户资源优化调度方法,能根据作业不同负载类型判断是否进行延迟调度,重新构造目标计算节点以提高作业并行效果,保持较高比例的本地化调度,减轻网络I/O负载,提高作业的执行效率。为了实现上述目的,本发明至少采用如下技术方案之一。一种面向不同类型负载的多租户资源优化调度方法,其特征在于包括以下步骤:第一步骤:使用多租户系统的租户提交作业到作业队列中;第二步骤:采集作业负载信息发送到资源管理器;第三步骤:资源管理器根据作业负载信息分别得到Map-shuffle阶段数据读写率和磁盘I/O带宽大小,通过比较两者之间大小关系判定作业不同负载类型,将类型信息发送给作业调度器;第四步骤:作业调度器根据不同负载类型确定作业的调度方式;如果是计算密集型作业则直接在当前节点调度执行,如果是I/O密集型作业则执行延迟调度;汇总调度决策信息发送给调度重构决策器;第五步骤:调度重构决策器根据决策信息重构目标计算节点,得到最终调度结果并执行作业调度;第六步骤:当有新的用户提交作业,重复执行以上第一至第五步骤。进一步地,所述第一步骤中,为满足多租户共享集群,资源管理器采用Hadoop现有公平调度器(FairScheduler)对资源进行初步划分。进一步地,所述第三步骤中,所述作业负载类型判定方法为:将分布式计算作业划分为Map、Shuffle、Reduce三个阶段,通过作业Map-Shuffle阶段的数据读写率和磁盘I/O带宽的大小对比关系来区分作业的负载类型;设MID、MOD、SOD、SID分别为Map读取数据大小、Map写入数据大小、Shuffle写入数据大小和shuffle读取数据大小,设置适当的Map数据转换率为ρ,则有关系式MOD=ρ*MID,又由于shuffle写入数据即为Map写入数据,因此有SOD=MOD,再设节点上同时运行的任务数为n,该阶段的完成时间为MCT,计算可得作业的数据读写率如下:如磁盘I/O带宽大小为DIOR,有判定关系为:(1)当MIOR<DIOR时,则该作业为计算密集型;(2)当MIOR≥DIOR时,则该作业为I/O密集型。进一步地,所述第四步骤中,所述延迟调度的方法为:如果作业无法在当前节点启动一个本地任务的话,暂时将它跳过而接着去调度其他满足本地化要求的作业;设置时间阈值t1和t2,t1<t2,如果作业被跳过的时间累加超过阈值t1,那么调度器将允许它在当前节点启动一个rack_local的任务,即任务执行所需的数据可以不在这个节点上,但要在和这个节点同属于一个机架内的另一个节点上;当这个作业被跳过的时间累加超过更长的时间阈值t2以后,调度器将允许这个作业在任何节点上启动任务以保证公平性。进一步地,所述第五步骤中,所述重构目标计算节点的方法为:设为第M个机器上第i个任务的计算代价,假设单个节点上任务之间为串行关系,则表示第M个机器上执行完该作业所有串行任务的时间,选取最早完成时间Tmin,统计每个节点在时间Tmin内可运行任务的个数,记为某作业在该节点的计算容量;将计算容量分为本地化任务容量L和迁移任务容量M,分别表示可计算本地化任务的数量与可计算迁移任务的数量;重构目标计算节点,每个节点根据本地化容量的大小选取本地化任务,优先选择I/O密集型任务,被选取的任务将该节点作为自己的目标计算节点,若此时作业还有剩余未被分配的任务,则剩余任务作为迁移任务依次分配至迁移容量不为零的节点。本发明与现有的多租户资源优化调度方法相比,具有如下优点:(1)提出了面向不同类型负载的多租户资源优化调度方法,通过采集作业负载信息,以每个作业Map-Shuffle阶段的数据读写率和磁盘带宽的大小对比关系为依据,区分不同负载类型,根据作业的不同负载类型判断是否进行延迟调度,实现资源本地化的同时,进一步提高系统的吞吐率。(2)提出的重构资源优化调度方法,尽可能保持作业本地化的同时使计算任务分散到集群中各个节点,充分利用集群资源,以实现分布式负载均衡。(3)提出的重新构造目标计算节点同样考虑作业的不同负载类型,优先本地化I/O密集型作业,增加了作业的并行程度,减少了作业的响应时间。相比其他多租户资源优化调度算法具有更高的资源利用率。附图说明图1为实例中面向不同类型负载的多租户资源优化调度方法的流程图。图2为面向不同类型负载的多租户资源优化调度方法的实施示意图。具体实施方式下面结合附图对本发明作进一步的详细描述,但本发明的实施和保护范围不限于此,需指出的是,以下若有未特别详细说明之处,均是本领域技术人员可参照现有技术实现的。如图1所示,为本实例的流程图,使用系统的租户提交作业到作业等待队列中;作业负载监控器收集作业负载信息,如Map-shuffle阶段读写数据大小、读写完成时间、磁盘I/O带宽等信息,发送给资源管理器;资源管理器根据作业Map-Shuffle阶段的数据读写率和磁盘I/O带宽的大小对比关系判定作业不同负载类型,具体判断方法为:根据作业负载信息计算作业的数据读写率MIOR,根据作业负载监控器反馈信息得到磁盘I/O带宽大小为DIOR,有判定关系为:(1)当MIOR<DIOR时,则该作业为计算密集型;(2)当MIOR≥DIOR时,则该作业为I/O密集型;将类型信息发送给作业调度器;作业调度器根据作业的不同负载类型确定作业的调度方式,如果是计算密集型作业则直接在当前节点调度执行,如果是I/O密集型作业则执行延迟调度;汇总调度决策信息发送给调度重构决策器。调度重构决策器根据决策信息重构目标计算节点,每个节点根据本地化容量的大小选取本地化任务,优先选择I/O密集型任务,被选取的任务将该节点作为自己的目标计算节点,若此时作业还有剩余未被分配的任务,则剩余任务作为迁移任务依次分配至迁移容量不为零的节点,得到最终调度决策结果并执行作业调度;当有新的用户提交作业,重复执行以上步骤,直到系统终止运行。如图2所示,给出了面向不同类型负载的多租户资源优化调度方法的一种实施方式,该调度系统由作业I/O监控器、主控节点、资源管理器、作业调度器、调度重构决策器和计算节点组成,其中作业I/O监控器负责对每个作业调度前需要进行数据读写的等待时间进行统计和收集,并将信息反馈给资源管理器;主控节点和资源管理器负责接收租户提交作业的请求、全局资源管理和分配,它根据作业进行I/O读写的等待时间,区分作业的不同负载类型,将作业的负载类型信息发送给作业调度器;作业调度器根据作业的不同负载类型信息,确定作业的调度方式,将系统中资源分配给各个正在运行的作业;调度重构决策器对作业调度器的调度结果进行重新构造,考虑不同负载类型信息,面对计算密集型任务可以优先调度它到本地机架上的其他节点执行,I/O密集型任务则优先调度到具有节点本地性的节点上执行,尽可能保持作业本地化的同时使计算任务分散到集群中各个节点,获得最终的资源优化调度结果并执行作业调度。计算节点是普通的物理PC机,这些物理服务器可以是异构的,包括物理服务器的物理资源(CPU、内存等)大小、体系结构、能耗等不同。实例为了验证面向不同类型负载的多租户资源优化调度方法的有效性,我们模拟使用提出的调度方法,分析比较优化后作业响应时间和集群吞吐率。现选取四台在同一机架上的普通PC机搭建Hadoop集群,一台机器作为主控节点,另外三台作为从节点(计算节点),假设每个计算节点只有一个资源槽,在任何时刻某个节点只存在一个任务处于运行状态,节点上的任务之间是完全串行的关系,所以任务在某个节点上运行时间可以直接累加。先通过建立数学模型分析根据不同负载类型判断是否进行延迟调度的有效性。假设一个任务在非本地节点运行比在本地节点运行多耗费D秒,把作业请求的到达近似为一个泊松分布,每次出现请求节点满足任务数据本地性的时间间隔为t秒,提交节点本地性任务的等待时间为w,因此延迟调度对响应时间影响的预期增益可表示如下:(1-e-w/t)(D-t)(2)因为(1-e-w/t)恒大于零,所以要想获得正的增益只需要满足D>t。如果作业为计算密集型,显然有D趋近于0,所以本方法采取直接调度而非延迟等待。相反的,对于I/O密集型作业通常采取延迟等待,通过设定合理的时间阈值t1和t2可以很大程度的缩短作业响应时间。在很多作业运行且各个节点之间负载均衡时,当一个作业无法提交本地任务时队列后面的其他作业将有符合数据本地化要求的等待调度,所以等待调度对系统的吞吐率提高也是有利的。但是也有可能带来热点节点的竞争问题,假设作业的大部分数据集中在某个节点或者集群中少数数据节点上,可能出现计算任务也同样集中在集群中某一节点或部分节点上,多个调度队列中的作业都在等待同一个节点执行任务,从而导致作业较低的并行效率以及较长的响应时间。为了进一步提高系统的吞吐率,调度重构决策器对调度计划进行重新构造,根据作业的不同负载类型进行不同的调度策略,针对计算密集型任务可以优先调度它到本地机架上的其他节点执行,I/O密集型任务则优先调度到具有节点本地性的节点上执行,尽可能保持作业本地化的同时使计算任务分散到集群中各个节点,从而减少任务间对热点节点的竞争。现有两个租户同时提交作业,通过作业负载监控器反馈信息,根据作业负载类型判断方法判定作业Job-1为I/O密集型、作业Job-2为计算密集型,每个作业由4个任务组成,作业的待处理数据相同,但是待处理数据分片分布在3个计算节点上,数据分片在各个节点的分布情况如表1所示:表1数据分片在三个计算节点的分布情况节点Job-1Job-2Node-142Node-202Node-300其中I/O密集型作业Job-1的4个数据分片都在节点1上,计算密集型作业Job-2有2个数据分片在节点1上,2个数据分片在节点2上。<i,j>序列对表示编号i任务的待处理数据在第j节点上,即Job-1的数据分布为{<1,1>,<2,1>,<3,1>,<4,1>},Job-2的数据分布为{<1,1>,<2,1>,<3,2>,<4,2>}。由此重构目标计算节点,选取作业最早完成时间Tmin,然后统计每个节点在时间Tmin内可运行任务的个数,记为各个节点的计算容量如表2所示:表2各个节点的计算容量节点本地化任务容量L迁移任务容量MNode-140Node-222Node-304每个节点根据本地化容量的大小选取本地化任务,在节点1上优先选择调度I/O密集型作业Job-1,被选取的任务将该节点作为自己的目标计算节点,即分配Job-1本地化任务{<1,1>,<2,1>,<3,1>,<4,1>},分配Job-2本地化任务{<3,2>,<4,2>};节点2和节点3存在迁移任务容量,由于三个节点都在同一机架上,所以Job-2剩余的未分配任务1、2可选取节点3作为目标计算节点。重构的目标计算节点为{<1,3>,<2,3>,<3,2>,<4,2>}。通过上面的多租户调度实例可以验证,优化后的资源调度方案节省了2个时间单位,显然可以降低作业响应时间并提高系统的吞吐率。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1