一种基于粒子群优化算法对支持向量机的优化方法与流程
本发明涉及计算机人工智能
技术领域:
,特别涉及一种基于粒子群优化算法对支持向量机算法的优化方法。
背景技术:
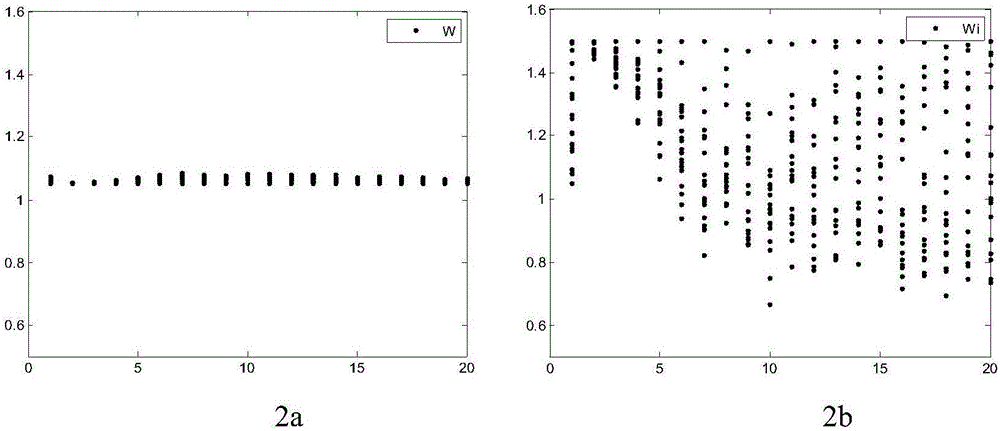
:粒子群优化算法(ParticleSwarmOptimization,简称PSO),是一种通过模拟自然界中生物群体(如蚂蚁、鸟和蜜蜂)的智能行为的群智能算法。在粒子群算法模型中,每一个优化问题的可行解看作一个粒子,每一个粒子的自身状态都由一组位置向量和速度向量描述,分别表示问题的可行解和它在D维搜索空间中的运动方向。粒子通过自身经验和不断学习发现它的邻居最优解和群体最优解,实现位置改变。原始的粒子群算法是没有惯性权重w,Shi和Eberhart首先提出了含有惯性权重w的粒子群算法,并指出一个较大的惯性权重w使粒子的速度有较大的增加,有利于粒子去探索新的未知空间;一个较小的惯性权重w使粒子的速度有较小的改变,有利于粒子局部搜索。在实现本发明的过程中,发明人发现现有技术的粒子群算法至少存在如下问题:由于较大惯性权重w能够增加全局探索能力,较小的惯性权重w能够增加局部搜索能力,如果想要获得全局探索能力和局部搜索能力这两者的平衡,就需要惯性权重w能够自适应的改变。然而,现有技术中的惯性权重w在PSO算法执行过程中是固定值或根据迭代次数改变,但这些现有技术中的惯性权重w不能根据种群的信息进行自适应调节,这样便不能使得全局探索能力和局部搜索能力得到较好的平衡。另外,惯性权重w是固定值的机制使得PSO算法容易陷入局部最优解、容易早熟收敛。支持向量机(SupportVectorMachine,简称SVM),是在统计学习基础上发展起来的新一代学习算法,该算法在理论基础上有较强的优势,近年来支持向量机在文本分类、图像分类、生物信息学、模式识别、系统控制、生产调度、计算机工程和数据挖掘等方面得到了广泛应用。支持向量机根据Vapnik的结构风险最小化原则,尽量提高学习机的泛化能力,即由有限训练样本得到的决策规则,对独立的测试集仍能够得到小的误差。此外,支持向量机算法是一个凸二次优化问题,能够保证找到的极值解就是全局最优解。这些特点使支持向量机成为一种优秀的学习算法。在实现本发明的过程中,发明人发现现有技术的SVM算法至少存在如下问题:在SVM分类模型中,C为SVM分类模型中的一个参数,表示对分类错误的容忍度或者对分类错误的惩罚力度,C越大表示惩罚越大,越不能容忍错误,容易造成过拟合,C越小与之相反,容易造成欠拟合。g为径向基核函数(RadialBasisFunction)半径,它影响数据映射到新的特征空间后的分布,g越大,支持向量越少,g值越小,支持向量越多,而支持向量的个数影响训练与预测的速度。所以参数C和g对算法的性能都有影响,合理设置参数C和g能提高分类器的分类准确率和分类器的训练与预测速度,而现有的方法对这两个参数优化的能力有限,会造成参数设置的不合理,从而导致SVM分类模型的分类准确率不高。技术实现要素:本发明的目的是采用改进的粒子群算法优化SVM分类模型中的C和g两个参数,使得这两个参数取得最优值,实现提高SVM算法的分类准确率,进而促进支持向量机算法在模式识别、系统控制、生产调度、计算机工程以及电子通信领域更加广泛的应用。根据本发明实施例的一个方面,提供了一种基于粒子群的优化算法对支持向量机的优化方法,包括:步骤S1,对粒子群的各参数进行初始化,所述参数包括粒子群的种群规模、迭代次数、搜索空间维度、搜索范围的最大值、搜索范围的最小值,粒子群中每个粒子的速度、位置、自我学习因子和社会学习因子;步骤S2,将初始化后的每个粒子的位置初始值带入适应度函数,得到每个粒子的适应度;步骤S3,根据每个粒子的适应度,计算每个粒子的个体最优位置、个体最优适应度以及粒子群的种群最优位置、种群最优适应度;步骤S4,基于种群最优适应度和个体最优适应度计算惯性权重;步骤S5,基于惯性权重、自我学习因子、社会学习因子、每个粒子的个体最优位置和粒子群的种群最优位置,更新每个粒子的速度和位置;步骤S6,计算每个粒子在当前迭代次数时的个体最优适应度与前一次迭代次数时的个体最优适应度的比值,将所述比值与预定阈值进行比较,若所述某个粒子比值小于预定阈值,则判定该粒子搜索成功;步骤S7,计算搜索成功的粒子的位置到所述种群最优位置的欧氏距离,并对所有搜索成功的粒子所对应的欧氏距离取平均值,得到距离阈值;步骤S8,判断每个粒子的位置到所述种群最优位置的欧氏距离是否小于所述距离阈值,若是,则对距离阈值内的部分粒子进行变异操作;步骤S9,判断当前迭代次数是否小于设定的迭代次数,若否,则执行步骤S10;步骤S10,输出粒子群在当前的种群最优位置,并将所述种群最优位置映射为支持向量机中的惩罚因子C和径向基核函数半径g;步骤S11,根据所述惩罚因子C和径向基核函数半径g对支持向量机进行训练。本发明实施例的有益效果:本发明实施例一方面根据粒子适应度调节惯性权重w,从而实现了惯性权重w的自适应调整,增加了惯性权重的多样性,更好的平衡PSO算法全局探索能力和局部搜索能力,另一方面,通过利用搜索成功的粒子计算出的阈值作为变异的条件,能更好地控制粒子变异的时机,粒子经过变异后,粒子跳出局部最优解的能力得到提升,更有利于寻找参数C和g的最优值,最终有助于提高SVM算法的分类准确率。附图说明图1是本发明基于粒子群的优化算法对支持向量机的优化方法流程图;图2是本发明的使用粒子个体最优适应度平均值和个体最优适应度惯性权重分布图;图2a是使用粒子个体最优适应度平均值取得的惯性权重值;图2b所是使用粒子个体最优适应度时所取得的惯性权重值;图3是本发明的粒子群未确定变异粒子的示意图;图4是本发明的粒子群已确定变异粒子的示意图;图5是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类准确率与分类时间上的结果对比图;图5a是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类准确率的结果对比图;图5b是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类时间的结果对比图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。图1是本发明基于粒子群的优化算法对支持向量机的优化方法的第一实施例的流程图。如图1所示,一种基于粒子群的优化算法对支持向量机的优化方法,包括以下步骤S1至S10:步骤S1,对粒子群的各参数进行初始化,所述参数包括粒子群的种群规模、迭代次数、搜索空间维度、搜索范围的最大值、搜索范围的最小值,粒子群中每个粒子的速度、位置、自我学习因子和社会学习因子。在对粒子群的各参数进行初始化之前,需要设定粒子群的各项参数,设定种群规模为s(即该粒子群中包括s个粒子)、最大迭代次数为T、搜索空间维度为D、搜索范围的最小值为popmin、搜索范围的最大值为popmax,设定粒子群中每个粒子的速度为v、位置为x、社会学习因子c1、自我学习因子为c2。其中设定粒子群中每个粒子的速度为v,还包括,设定最大速度为Vmax、最小速度为Vmin。在以上参数设定完成后,开始对粒子群进行初始化,所谓初始化,即对以上各项参数进行赋值,使得每个参数获得初始值。在此需要说明的是,对粒子群进行初始化包括对粒子群中的每个粒子的速度和位置进行赋值时赋予的是随机值。具体地,基于下式(1)对每个粒子的速度进行初始化;基于下式(2)对每个粒子的位置进行初始化,其中,rand()为区间[0,1]之间的随机数。v=rand()式(1)x=200·rand()-100式(2)步骤S2,将初始化后的每个粒子的位置初始值带入适应度函数,得到每个粒子的适应度。基于每个粒子,将其在粒子群初始化后得到的位置的初始值带入适应度函数,得到每个粒子的适应度。具体地,粒子群在初始化后,每个粒子得到的一个初始位置(即位置的初始值)。把这些位置的初始值映射为支持向量机(SVM分类模型)中的惩罚因子C和径向基核函数半径g,根据惩罚因子C和径向基核函数半径g对支持向量机进行训练,基于式(3)得到适应度。其中,n为训练集样本总数,r为分类正确的样本数目,F为适应度。在粒子群算法对支持向量机的优化中,适应度F为训练完毕的SVM分类模型对训练集的分类准确率,分类准确率越大说明分类效果越好。达到设定的迭代次数后输出适应度(在这里就是分类准确率)最大的那一组对应的种群最优位置,并把种群最优位置映射为参数C和g,则粒子群对SVM的参数C和g寻优完毕。步骤S3,根据每个粒子的适应度,计算每个粒子的个体最优位置、个体最优适应度以及粒子群的种群最优位置、种群最优适应度。其中,在粒子群算法对支持向量机的优化中,粒子群算法中的适应度就是SVM分类模型(支持向量机)对训练集的分类准确率,所以个体最优适应度为每个粒子在整个迭代过程中得到的适应度最大的值;种群最优适应度为粒子群中所有粒子在整个迭代过程中的个体最优适应度中的最大值;个体最优位置为个体最优适应度的粒子所对应的位置;种群最优位置为种群最优适应度的粒子所对应的位置。需要说明的是,粒子群中的所有粒子在迭代的过程中,每迭代一次,每个搜索空间维度中的粒子的位置都会改变一次。对于种群规模为s、迭代次数为t、搜索空间维度为D的粒子群来说,如果粒子迭代了一次,那么对于每个粒子,会有D个位置值,把这D个位置值带入到适应度函数中得到该粒子在本次迭代的适应度。如果粒子迭代了t次,则将粒子在每次迭代中的位置值代入适应度函数中,则得到t个适应度。从这t个适应度中选择值最大的作为该粒子在整个迭代过程中的个体最优适应度,该个体最优适应度对应的位置即为该粒子的个体最优位置。每个粒子的个体最优适应度确定后,再比较s个粒子的个体最优适应度,从中选择值最大的作为该粒子群的种群最优适应度,该种群最优适应度对应的位置即为该粒子群的种群最优位置。步骤S4,基于种群最优适应度和个体最优适应度得到惯性权重。具体地,将种群最优适应度和个体最优适应度代入式(4)进行计算,得到惯性权重。其中,i表征的是粒子为第i个,t表征迭代至t次,w表征惯性权重,wi(t)表征第i个粒子迭代至t次时的惯性权重值,fitness(gbest)(t)表征粒子群迭代至t次时的种群最优适应度,fitness(pbest)i(t)表征第i个粒子迭代至t次时的个体最优适应度。图2是粒子群20个粒子迭代20次的惯性权重在平面坐标系中的分布图。其中,横轴表示迭代次数,纵轴表示粒子惯性权重值,图2a是使用粒子个体最优适应度平均值fitness(pbest)average取得的惯性权重值,图2b所是使用粒子个体最优适应度fitness(pbest)i时所取得的惯性权重值。如图2a所示,惯性权重高度集中,几乎所有的粒子对应相同的惯性权重值。如图2b所示,对应每次迭代,粒子的惯性权重分布范围较广,在(0.5,1.5)之间。因此可以看出,使用粒子个体最优适应度fitness(pbest)i相比使用粒子个体最优适应度平均值fitness(pbest)average,取得的惯性权重值更加具有多样性,这样可以保证粒子在全局搜索和局部搜索都有分工,从而使得算法在全局探索能力和局部搜索能力之间获得了有效的平衡。步骤S5,基于惯性权重、自我学习因子、社会学习因子、每个粒子的个体最优位置和粒子群的种群最优位置,更新每个粒子的速度和位置。基于惯性权重、自我学习因子、社会学习因子、每个粒子的个体最优位置和粒子群的种群最优位置进行计算,得到每个粒子的速度和位置的更新值,并将初始化后的每个粒子的速度和位置的初始值替换为所述更新值。具体地,步骤S5包括以下步骤S51-S52:步骤S51,将惯性权重、自我学习因子、社会学习因子、每个粒子的个体最优位置和粒子群的种群最优位置代入式(5)进行计算,得到粒子更新后的速度。vij(t+1)=wvij(t)+c1r1[pbestij(t)-xij(t)]+c2r2[gbestj(t)-xij(t)]式(5)步骤S52,将惯性权重、自我学习因子、社会学习因子、每个粒子的个体最优位置和粒子群的种群最优位置代入式(6)进行计算,得到粒子更新后的位置。xij(t+1)=xij(t)+vij(t+1)式(6)其中,i表征的是粒子为第i个,j表征的是粒子的第j维度,x表征粒子的位置,t表征迭代至t次,w表征惯性权重,vij(t)表征第i个粒子迭代到第t次时在第j维空间的速度,vij(t+1)表征第i个粒子迭代到第t+1次时在第j维空间的速度,xij(t)表征第i个粒子迭代到第t次时在第j维空间的位置,xij(t+1)表征第i个粒子迭代到第t+1次时在第j维空间的位置,pbestij(t)表征第i个粒子迭代到第t次时在第j维空间的个体最优位置,gbestj(t)表征粒子群迭代到第t次时粒子群在第j维空间的种群最优位置,c1为社会学习因子,c2为自我学习因子,r1和r2为区间[0,1]中的随机数。步骤S6,计算每个粒子在当前迭代次数时的个体最优适应度与前一次迭代次数时的个体最优适应度的比值,将所述比值与预定阈值进行比较,若所述某个粒子比值小于预定阈值,则判定该粒子搜索成功。具体地,设定预定阈值为1,若某个粒子在当前迭代次数时的个体最优适应度与前一次迭代次数时的个体最优适应度的比值小于1,则判断该粒子搜索成功,若某个粒子在当前迭代次数时的个体最优适应度与前一次迭代次数时的个体最优适应度的比值等于1,则判断该粒子搜索失败。进一步,可以设置粒子搜索成功的表征值为1,粒子搜索失败的表征值为0,基于下式(8)判断每个粒子是否搜索成功。其中,SS(i,t)=1表示第i个粒子搜索成功,SS(i,t)=0表示第i个粒子搜索失败。表示第i个粒子迭代至t次时的个体最优适应度,为第个i粒子迭代至t-1次时的个体最优适应度。步骤S7,计算搜索成功的粒子的位置到所述种群最优位置的欧氏距离,并对所有搜索成功的粒子所对应的欧氏距离取平均值,得到距离阈值。由于步骤S6中判断出了每个粒子是否搜索成功,依据每个粒子的判断结果,就能统计出该粒子群中所有搜索成功的粒子的数量,基于该粒子群中所有搜索成功的粒子的数量能够计算出该粒子群的搜索成功率。具体地,基于下式(9)计算搜索成功的粒子中第i个粒子的位置到种群最优位置的欧氏距离:其中,disti表征第i个粒子的位置到种群最优位置的欧氏距离,gbestj表征第j维的种群最优位置,xij表征第i个粒子的第j维的位置,D表征搜索空间维度。基于下式(10)计算所有搜索成功的粒子到种群最优位置的欧氏距离的平均值:其中,distaverage表征平均值(即距离阈值);m表征搜索成功的粒子的个数。步骤S8,判断每个粒子的位置到种群最优位置的欧氏距离是否小于所述距离阈值,若是,则对距离阈值内的部分粒子进行变异操作。基于下式(11)判断每个粒子的位置到种群最优位置的欧氏距离是否小于距离阈值。其中,disti表征第i个粒子的位置到种群最优位置的欧氏距离,muti表示判断结果。若muti=1表示该粒子落入距离阈值内,muti=0表示该粒子没有落入距离阈值内。需要说明的是,在确定粒子是否落入距离阈值内之后,进行变异操作时并不是对落入距离阈值内的所有粒子进行变异操作,因为距离阈值内的所有粒子中有可能存在最优位置,所以变异的时候需要选择部分粒子变异,保留一部分粒子维持原样。所述部分粒子为一半的粒子或三分之一的粒子。“一半”“三分之一”是一个经验值,也可以选其他值,在本发明的一个优选实施例中,对距离阈值内的一半粒子进行变异操作。对距离阈值内的部分粒子基于式(7)进行变异操作,得到所述部分粒子中每个粒子在变异后的位置。pop(i)=(popmax-popmin)·rand()+popmin(7)其中,pop(i)表征第i个粒子在变异后的位置,popmax表征粒子群的搜索范围的最大值,popmin表征粒子群的搜索范围的最小值,rand()为区间[0,1]内的随机数。图3是粒子群未确定变异粒子示意图。如图3所示,图中黑色小实心点代表粒子,带有圆圈的实心点代表当前搜索到的种群最优位置。图4是粒子群已经确定变异粒子的示意图。如图4所示,图中黑色小实心点代表粒子,带有圆圈的实心点代表当前搜索到的种群最优位置,distaverage为距离阈值。步骤S9,判断当前迭代次数是否小于设定的迭代次数,若否,则执行步骤S10。步骤S10,输出粒子群在当前的种群最优位置,并将所述种群最优位置映射为支持向量机(SVM分类模型)中的惩罚因子C和径向基核函数半径g。步骤S11,根据所述惩罚因子C和径向基核函数半径g对支持向量机进行训练。进一步,所述的方法,其中,在步骤S11,根据所述惩罚因子C和径向基核函数半径g对支持向量机进行训练之后,还包括:得到当前迭代次数时的每个粒子的适应度,并返回步骤S3。训练完毕后,得到每个粒子的适应度,并将所述适应度代入步骤S3。C在支持向量机中为惩罚因子,表征对分类错误的容忍度。g在支持向量机中表征径向基核函数(RadialBasisFunction)的半径。以下通过实验数据来说明本发明的有益效果。首先通过实验数据说明本发明中对粒子群进行优化的算法的有益效果(为了表述方便,以下简称AIWPSO算法)。发明人在实验中使用了以下表1所示的11个测试函数来测试现有技术中五种粒子群改进算法(CPSO算法、RPSO算法、LDPSO算法、NLDPSO算法、APSO算法)与本发明的AIWPSO算法对测试函数的寻优情况。这11个测试函数包括单峰函数、多峰函数。表1表1所示的11个函数的相关信息如以下表2所示。其中,表2中的全局最优值为测试函数能取到的最小值,以上各种算法(CPSO算法、RPSO算法、LDPSO算法、NLDPSO算法、APSO算法、AIWPSO算法)对测试函数的寻优结果若越接近全局最优值,表明算法的寻优精度越高。测试函数名称搜索空间维度搜索范围全局最优位置全局最优值f1Sphere30[-100,100]D[0,…,0]D0f2SchwefelP2.2230[-10,10]D[0,…,0]D0f3Rosenbrock30[-30,30]D[1,…,1]D0f4NoisyQuadric30[-1.28,1.28]D[0,…,0]D0f5Rastrigin30[-5.12,5.12]D[0,…,0]D0f6Griewank30[-600,600]D[0,…,0]D0f7Ackley30[-32,32]D[0,…,0]D0f8Rotatedhyperellipsoid30[-100,100]D[0,…,0]D0f9RotatedRastrigin30[-5,5]D[0,…,0]D0f10RotatedGriewank30[-600,600]D[0,…,0]D0f11ShiftedRotatedRastrigin30[-600,600]D[0,…,0]D-330表2为了减少随机误差带来的影响,本次实验中对现有技术中五种粒子群改进算法(CPSO算法、RPSO算法、LDPSO算法、NLDPSO算法、APSO算法)与本发明的AIWPSO算法均使用相同的测试函数独立运行30次,各个算法寻优结果的最小值、平均值、标准差如下表3所示。表3如表3所示,其中,Min表示通过对算法独立运行30次后取结果中的最小值,在本次测试中,结果越接近表2中的全局最优值表示算法寻优精度越高;Mean表示对算法独立运行30次后对这30个结果取平均值;SD表示这30个结果的标准差,标准差体现了算法的稳定性,标准差越小说明算法越稳定。基于本发明的AIWPSO算法与现有技术中的五种粒子群改进算法(CPSO算法、RPSO算法、LDPSO算法、NLDPSO算法、APSO算法)相比,基于本发明的AIWPSO算法对测试函数的寻优结果的最小值更接近表2中对应函数的全局最优值,且寻优结果的标准差更小,因此本发明的AIWPSO算法寻优精度高、算法性能稳定。以下通过实验数据证明发明的AIWPSO算法提高SVM分类模型的分类准确率。本实验采用UCI机器学习库(UCIMachineLearningRepository:http://archive.ics.uci.edu/ml/)中的数据集评估不同的分类模型。UCI机器学习库是加州大学欧文分校(UniversityofCaliforniaIrvine)提出的用于机器学习的数据库,UCI数据集是一个常用的标准测试数据集。其中,本发明中用到的数据集包括心脏病数据集(Statlog)、糖尿病数据集(Diabetes)、胸外科数据集(ThoracicSurgery)、乳腺癌数据集(BreastCancer)、肝脏疾病数据集(LiverDisorders)共5个数据集,以上5个数据集的具体信息参见以下表4。数据集名称样本容量特征数目分类数目训练集数目测试集数目心脏病数据集270102150120糖尿病数据集76852500268胸外科数据集47092300170乳腺癌数据集69992500199肝脏疾病数据集34542200145表4原始数据集信息中,包含性别、年龄这两个特征,在分类识别中不作为分类特征指标。对于数据集中的其他特征信息,本实验使用了统计检验方法对特征指标的可区分性进行判别,通过统计检验,组间存在显著性差异的分类指标才能作为分类特征。通过实验比较了基于原始粒子群算法对SVM分类模型的优化方法(简称PSO-SVM)和本发明的基于AIWPSO算法对SVM分类模型的优化方法(简称AIWPSO-SVM)的分类准确率和分类时间。正常人的特征标签为1,患者的特征标签为2。实验平台为联想M490PC,32位Windows7操作系统,英特尔酷睿i5三代处理器,CPU的计算频率为2.50GHz,运行内存为4GB,软件版本为MATLABR2013b。采用LIBSVM工具包测试。实验结果如图5所示。图5是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类准确率与分类时间上的结果对比图。其中,图5a是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类准确率的结果对比图。图5b是本发明的基于AIWPSO算法对SVM分类模型的优化方法与现有技术中基于原始粒子群算法对SVM分类模型的优化方法在分类时间的结果对比图。如图5a、5b所示,横轴上的Statlog、Diabetes、ThoracicSurgery、BreastCancer、LiverDisorders分别表示本发明中用到的5个数据集(依次对应心脏病数据集、糖尿病数据集、胸外科数据集、乳腺癌数据集、肝脏疾病数据集),其中带阴影的部分是现有技术中基于原始粒子群算法对SVM分类模型的优化方法,没有阴影的部分是本发明基于AIWPSO算法对SVM分类模型的优化方法。图5a中的纵轴为分类准确率轴,图5b中的纵轴为分类时间轴(单位:秒)。从图5a、图5b中可以得出:1,就分类准确率而言:基于本发明的AIWPSO算法比现有技术中基于原始粒子群算法优化SVM分类模型的分类准确率高;2,就算法运行时间而言:本发明的AIWPSO算法相对于现有技术中基于原始的粒子群算法虽然运行时间较长,但差别不大。所以,本发明在没有损失太长时间的基础上明显提高了SVM分类模型的分类准确率。应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1